






一、for循环
很多情况下都需要程序执行重复的任务,如将数组中的元素累加起来。C++中的for循环可以轻松地完成这种任务。
#include <iostream>
using namespace std;
int main()
{
int i;
for(i=0;i<5;i++) cout<<"C++ knows loops"<<endl;
cout<<"C++ knows when to stop."<<endl;
return 0;
} 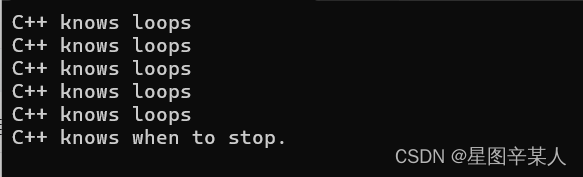
该循环首先将整数变量i设置为0:
i=0;
这是循环的初始化部分。然后,循环测试部分检查i是否小于5:
i<5;
如果确实小于5,则程序将执行接下来的语句——循环体:
cout<<"C++ knows loops"<<endl;
然后,程序使用循环更新部分将i加1:
i++;
这里使用了++运算符——递增运算符,它将操作数的值加1。递增运算符并不仅限于用于for循环,可以使用i++;来替换语句i=i+1;。将i加1后,便结束了循环的第一个周期。
接下来,循环开始了新的周期,将新的i值与5进行比较。由于新值也小于5,因此循环打印另一行,然后再次将i加1,从而结束这一周期。这样又进入了新的一轮测试、执行语句和更新i的值。这一过程将一直进行下去,直到循环将i更新为5为止。这样,接下来的测试失败,程序将接着执行循环后的语句。
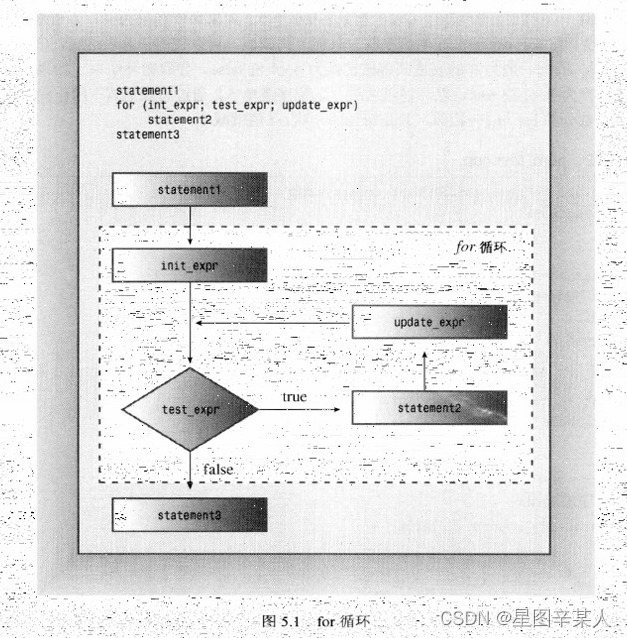
1.for循环的组成部分
for 循环为执行重复的操作提供了循序渐进的步骤。for 循环的组成部分完成下面这些步骤:
- 设置初始值。
- 执行测试,看看循环是否应当继续进行。
- 执行循环操作。
- 更新用于测试的值。
初始化、测试和更新操作构成了控制部分,这些操作由括号括起。其中每部分都是一个表达式,彼此由分号隔开。控制部分后面的语句叫作循环体,只要测试表达式为true,它便被执行:
for (initialization; test-expression; update-expression)
body
C++语法将整个for看作一条语句,虽然循环体可以包含一条或多条语句。包含多条语句时,需要使用复合语句或代码块。循环只执行一次初始化。通常,程序使用该表达式将变量设置为起始值,然后用该变量计算循环周期。
test-expression(测试表达式)决定循环体是否被执行。通常,这个表达式是关系表达式,即对两个值进行比较。如果比较结果为真,则程序将执行循环体。实际上,C++并没有将test-expression的值限制为只能为真或假。可以使用任意表达式,C++将把结果强制转换为bool类型。因此,值为0的表达式将被转换为bool值false,导致循环结束。如果表达式的值为非零,则被强制转换为bool值true,循环将继续进行。i--与i++相似,只是每使用一次,i值就减1。
#include <iostream>
using namespace std;
int main()
{
cout<<"Enter the starting countdown value: ";
int limit,i;
cin>>limit;
for(i=limit;i;i--) cout<<"i = "<<i<<endl;
cout<<"Done now that i = "<<i<<endl;
return 0;
} 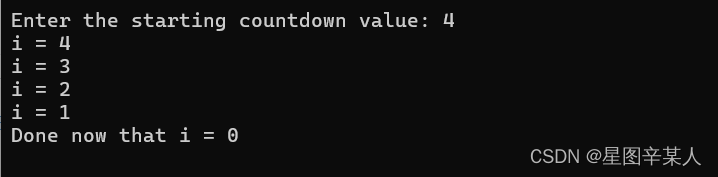
循环在i变为0后结束。在引入bool类型之前,如果关系表达式为true,则被判定为1;如果为false,则被判定为0。然而,C++添加了bool类型后,关系表达式就判定为bool字面值 true和false,而不是1和0了。这种变化不会导致不兼容的问题,因为C++程序在需要整数值的地方将把true和false分别转换为1和0;而在需要bool值的地方将把0转换为false,非0转换为true。
for 循环是入口条件循环。这意味着在每轮循环之前,都将计算测试表达式的值,当测试表达式为false,,将不会执行循环体。这种在循环之前进行检查的方式可避免程序遇到麻烦。
update-expression(更新表达式)在每轮循环结束时执行,此时循环体已经执行完毕。通常,它用来对跟踪循环轮次的变量的值进行增减。然而,它可以是任何有效的C++表达式,还可以是其他控制表达式。
for 语句看上去有些像函数调用,因为它使用一个后面跟一对括号的名称。然而,for是一个C++关键字,因此编译器不会将for视为一个函数,这还将防止将函数命名为for。
C++常用的方式是,在for和括号之间加上一个空格,而省略函数名与括号之间的空格。对于其他控制语句(如if和while),处理方式与for相似。这样从视觉上强化了控制语句和函数调用之间的区别。另外,常见的做法是缩进for语句体,使它看上去比较显著。
(1)表达式和语句
for语句的控制部分使用3个表达式。由于其自身强加的句法限制,C++成为非常具有表现力的语言。任何值或任何有效的值和运算符的组合都是表达式。在C++中,每个表达式都有值。通常值是很明显的。有时值不这么明显,C++将赋值表达式的值定义为左侧成员的值。
然而,C++虽然允许这样做,但并不意味着应鼓励这种做法。
允许存在上述语句,原则上也允许编写如下的语句:
x=y=z=0;
这种方法可以快速地将若干个变量设置为相同的值。优先级表表明,赋值运算符是从右向左结合的,因此首先将0赋给z,然后将z=0赋给y,依此类推。
#include <iostream>
using namespace std;
int main()
{
int x;
cout << "The expression x = 100 has the value ";
cout << (x = 100) << endl;
cout << "Now x = " << x << endl;
cout << "The expression x < 3 has the value ";
cout << (x < 3) << endl;
cout << "The expression x > 3 has the value ";
cout << (x > 3) << endl;
cout.setf(ios_base :: boolalpha); //a newer C++ feature
cout << "The expression x < 3 has-the value ";
cout << (x < 3) << endl;
cout << "The expression x > 3-has the value ";
cout << (x > 3) <<endl;
return 0;
} 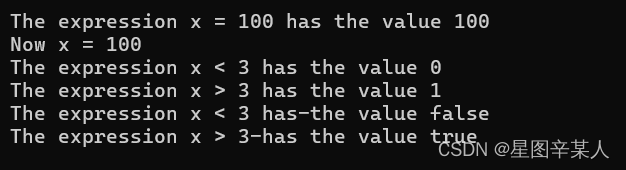
<<运算符的优先级比表达式中的运算符高,所以注意使用括号。通常,cout 在显示bool值之前将它们转换为int,但cout.setf(ios :: boolalpha)函数调用设置了一个标记,该标记命令cout 显示true和false,而不是1和0。C++表达式是值或值与运算符的组合,每个C++表达式都有值。
为判定表达式x=100,C++必须将100赋给x。当判定表达式的值这种操作改变了内存中数据的值时,我们说表达式有副作用(side effect)。因此,判定赋值表达式会带来这样的副作用,即修改被赋值者的值。并不是所有的表达式都有副作用。
从表达式到语句的转变,只要加分号即可。更准确地说,这是一种表达式语句。只要加上分号,所有的表达式都可以成为语句,但不一定有编程意义。编译器允许这样的语句,但它没有完成任何有用的工作。程序仅仅是计算和,而没有使用得到的结果,然后便进入下一条语句。
(2)非表达式和语句
对任何表达式加上分号都可以成为语句,但是从语句中删除分号,并不一定能将它转换为表达式。就我们目前使用的语句而言,返回语句、声明语句和for语句都不满足“语句=表达式+分号”这种模式。
(3)修改规则
C++在C循环的基础上添加了一项特性,要求对for循环句法做一些微妙的调整,即可以在for 循环的初始化部分中声明变量。由于声明不是表达式,这种曾经是非法的行为最初是通过定义一种新的表达式,叫做声明语句表达式来合法化的,声明语句表达式不带分号声明,只能出现在for语句中。这种调整已经被取消了,代之以将for语句的句法修改成新形式。
for的旧格式为
for (expression; expression; expression)
statement
for的新格式
for (for-init-statement condition; expression)
statementfor-init-statement为一条语句,所以有自己的分号。这种变量只存在于for语句中,当程序离开循环后,这种变量将消失。但有些较老的C++实现遵循老规则,对于这种for内声明将将i视为在前面就声明了,因此,在for外也可以使用。
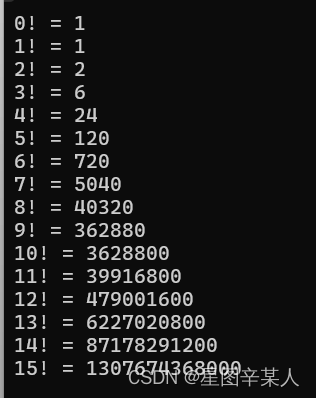
2.回到for循环
#include <iostream>
using namespace std;
int main()
{
long long a[16];
a[0]=a[1]=1;
for(int i=2;i<16;i++) a[i]=i*a[i-1]; //计算并存储
for(int i=0;i<16;i++) cout<<i<<"! = "<<a[i]<<endl; //循环输出
return 0;
} 
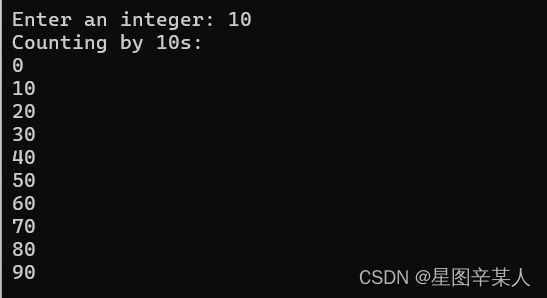
3.修改步长
#include <iostream>
using namespace std;
int main()
{
cout << "Enter an integer: ";
int by;
cin >> by;
cout << "Counting by " << by << "s: \n";
for (int i = 0; i < 100; i = i + by) cout << i << endl;
return 0;
} 
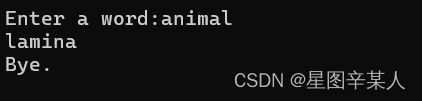
4.使用for循环访问字符串
#include <iostream>
using namespace std;
int main()
{
cout << "Enter a word:";
string word;
cin >> word;
// display letters in reverse order
for (int i = word.size() - 1; i >=0; i -- ) cout << word [i];
cout << "\nBye.\n";
return 0;
} 
5.递增运算符(++)和递减运算符(--)
前缀版本和后缀版本对操作数的影响相同,但作用时间不同。
#include <iostream>
using namespace std;
int main()
{
int a = 20;
int b = 20;
cout << "a = " << a << "; b = " << b << "\n";
cout << "a++ = " << a++ << "; ++b = " << ++b << "\n";
cout << "a = " << a << "; b = " << b << "\n";
return 0;
} 
粗略地讲,a++意味着使用a的当前值计算表达式,然后将a的值加1;而++b的意思是先将b的值加1,然后使用新的值来计算表达式。不要在同一条语句对同一个值递增或递减多次。问题在于,规则“使用后修改”和“修改后使用”可能会变得模糊不清。
x = 2 * x++ * (3 - ++x);
对这种语句,C++没有定义正确的行为,不同的系统有不同的结果。
6.副作用和顺序点
副作用指的是在计算表达式时对某些东西(如存储在变量中的值)进行了修改;顺序点是程序执行过程中的一个点,在这里,进入下一步之前将确保对所有的副作用都进行了评估。在C++中,语句中的分号就是一个顺序点,这意味着程序处理下一条语句之前,赋值运算符、递增运算符和递减运算符执行的所有修改都必须完成。另外,任何完整的表达式末尾都是一个顺序点。
完整表达式的定义为:不是另一个更大表达式的子表达式。完整表达式的例子有:表达式语句中的表达式部分以及用作while循环中检测条件的表达式。顺序点有助于阐明后缀递增何时进行。
7.前缀格式和后缀格式
如果变量被用于某些目的(如用作函数参数或给变量赋值),使用前缀格式和后缀格式的结果将
不同。然而,如果递增表达式的值没有被使用,使用前缀格式和后缀格式没有任何区别。表达式的值未被使用,因此只存在副作用。
然而,虽然选择使用前缀格式还是后缀格式对程序的行为没有影响,但执行速度可能有细微的差别。对于内置类型和当代的编译器而言,这看似不是什么问题。然而,C++允许针对类定义这些运算符,一般对于类而言,前缀版本的效率比后缀版本高。
总之,对于内置类型,采用哪种格式不会有差别;但对于用户定义的类型,如果有用户定义的递增和递减运算符,则前缀格式的效率更高。
8.递增/递减运算符和指针
可以将递增运算符用于指针和基本变量。将递增运算符用于指针,将把指针的值增加其指向的数据类型占用的字节数,这种规则适用于对指针递增和递减。可以结合使用这些运算符和*运算符来修改指针指向的值。将*和++同时用于指针时,运算结果取决于运算符的位置和优先级。前缀递增、前缀递减和解除引用运算符的优先级相同,以从右到左的方式进行结合。后缀递增和后缀递减的优先级相同,但比前缀运算符的优先级高,这两个运算符以从左到右的方式进行结合。
前缀运算符的从右到左结合规则意味着*++pt的含义如下:现将++应用于pt(因为++位于*的右边),然后将*应用于被递增后的pt。另一方面,++*pt意味着先取得pt指向的值,然后将这个值加1。
*pt++中的后缀运算符++的优先级更高,这意味着将运算符用于pt,而不是*pt,因此对指针递增。然而后缀运算符意味着将对原来的地址而不是递增后的新地址解除引用。
9.组合赋值运算符
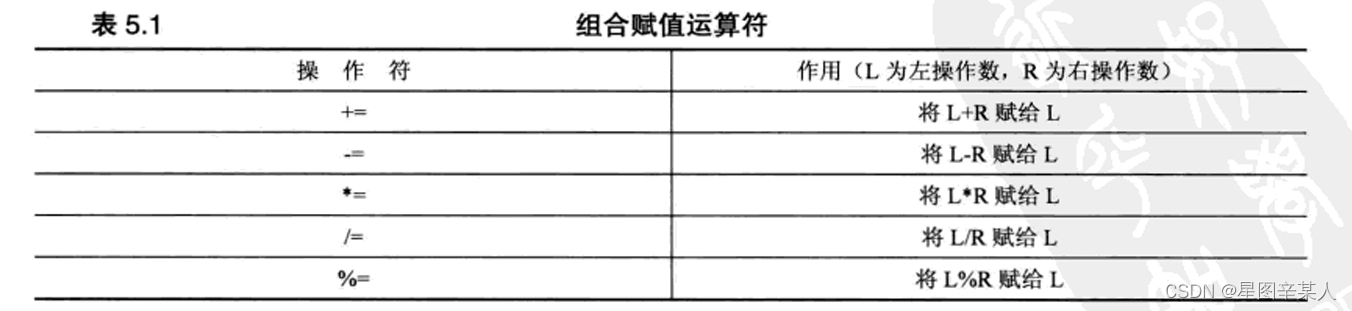
10.复合语句
用两个花括号来构造一条复合语句(代码块)。代码块由一对花括号和它们包含的语句组成,被视为一条语句,从而满足for句法的要求。
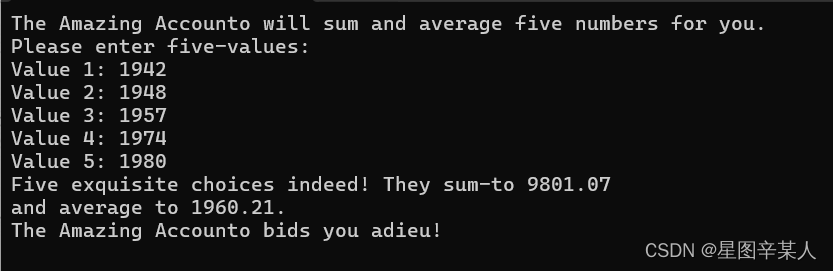
#include <iostream>
using namespace std;
int main() {
cout << "The Amazing Accounto will sum and average ";
cout << "five numbers for you. \n";
cout << "Please enter five-values:\n";
double number;
double sum = 0.07;
for (int i = 1; i <= 5; i++)
{
cout << "Value " << i << ": ";
cin >> number;
sum += number;
}
cout << "Five exquisite choices indeed! ";
cout << "They sum-to " << sum << endl;
cout << "and average to " << sum / 5 << ". \n";
cout << "The Amazing Accounto bids you adieu! \n";
return 0;
}
复合语句还有一种有趣的特性。如果在语句块中定义一个新的变量,则仅当程序执行该语句块中
的语句时,该变量才存在。执行完该语句块后,变量将被释放。
如果在一个语句块中声明一个变量,而外部语句块中也有一个这种名称的变量,在声明位置到内部语句块结束的范围之内,新变量将隐藏旧变量;然后就变量再次可见。
#include <iostream>
using namespace std;
int main()
{
int x=20;
{
int x=10;
cout<<x<<endl;
cout<<&x<<endl;
}
cout<<x<<endl;
cout<<&x<<endl;
return 0;
}
11.其他语法技巧——逗号运算符
语句块允许把两条或更多条语句放到按C++句法只能放一条语句的地方。逗号运算符对表达式完成同样的任务,允许将两个表达式放到C++句法只允许放一个表达式的地方。
例如for循环的更新部分可以使用i++,j--
逗号并不总是逗号运算符。
例如,可以在声明语句中将两个变量分开int i=0,j=0;
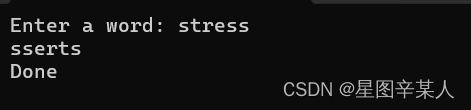
#include <iostream>
using namespace std;
int main()
{
cout << "Enter a word: ";
string word;
cin >> word;
char temp;
int i, j;
for (j = 0, i = word.size() - 1; j < i; -- i, ++j)
{
temp = word[i];
word[i] = word[j];
word[j] = temp;
}
cout<< word << "\nDone\n";
return 0;
}
在C++中,逗号有两种主要的用途:作为逗号运算符和作为列表分隔符。
逗号运算符(Comma Operator):
逗号运算符在C++中用于将两个或多个表达式分隔开,并顺序地计算这些表达式,即它是一个顺序点。逗号运算符的求值顺序是从左到右。逗号运算符的返回值是其右侧操作数的值。如果右侧没有操作数,则返回值未定义。
列表分隔符:
逗号在C++中经常用作列表分隔符,例如在函数参数列表、初始化列表、for循环的初始化部分等。
12.关系运算符
C++提供了6种关系运算符来对数字进行比较。由于字符用其ASCII码表示,因此也可以将这些运算符用于字符。不能将它们用于C-风格字符串,但可用于string类对象。对于所有的关系表达式,如果比较结果为真,则其值将为true,否则为false,因此可将其用作循环测试表达式。老式实现认为结果为true的关系表达式的值为1,而结果为false的关系表达式为0。关系运算符的优先级比算术运算符的优先级低。

13.C-风格字符串的比较
假设要知道字符数组中的字符串是不是mate。如果word是数组名,下面的测试可能并不能像我们预想的那样:
word == "mate";
数组名是数组的地址。同样,用引号括起的字符串常量也是其地址。因此,上面的关系表达
式不是判断两个字符串是否相同,而是查看它们是否存储在相同的地址上。虽然它们包含相同的字符,但它们的地址一般不相同。
由于C++将C-风格字符串视为地址,因此如果使用关系运算符来比较它们,将无法得到满意的结果。应使用C-风格字符串库中的strcmp()函数来比较。
int strcmp(const char *str1, const char *str2);
该函数接受两个字符串地址作为参数,这意味着参数可以是指针、字符串常量或字符数组名。
它会按照字典顺序逐个字符比较两个字符串,并返回以下值之一:
- 如果 str1 小于 str2,则返回一个负数值。
- 如果 str1 等于 str2,则返回 0。
- 如果 str1 大于 str2,则返回一个正数值。
strcmp() 函数会比较字符串直到遇到字符串结束符 '\0',或者其中一个字符串的字符不相等为止。这意味着,strcmp() 不仅可以判断两个字符串是否完全相等,还可以告诉你哪个字符串在字典顺序上排在前面,且不会因为数组的大小而受影响。需要注意的是,strcmp() 函数对大小写敏感,因此在比较字符串时会考虑字符的大小写情况。
虽然不能用关系运算符来比较字符串,但却可以用它们来比较字符,因为字符实际上是整型。
for (ch = 'a'; ch <= 'z' ; ch++)
cout << ch;
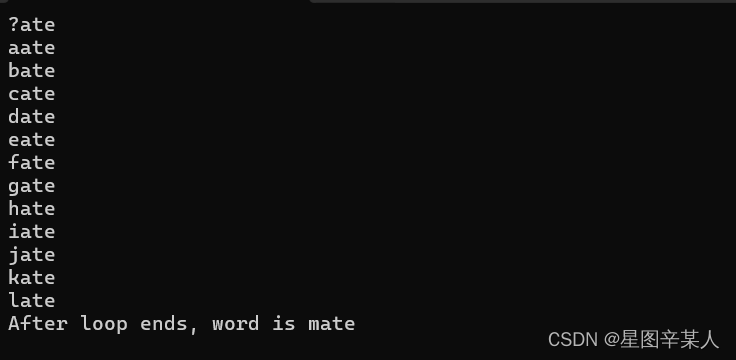
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char word[5] = "?ate";
for (char ch = 'a'; strcmp(word, "mate"); ch++)
{
cout << word << endl;
word [0] = ch;
}
cout << "After loop ends, word is " << word << endl;
return 0;
}
14.比较string类字符串
如果使用string类字符串而不是C-风格字符串,比较起来将简单些,因为类设计让您能够使用关系运算符进行比较。这之所以可行,是因为类函数重载(重新定义)了这些运算符。
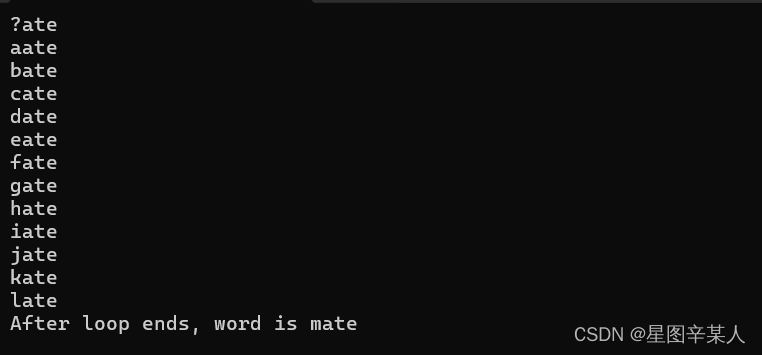
#include <iostream>
#include <string>
using namespace std;
int main()
{
string word = "?ate";
for (char ch = 'a'; word!="mate"; ch++)
{
cout << word << endl;
word [0] = ch;
}
cout << "After loop ends, word is " << word << endl;
return 0;
}
string:类重载运算符 != 的方法使我们能够在下述条件下使用它:至少有一个操作数为string对象,另一个操作数可以是string对象,也可以是C-风格字符串。
此循环不是计数循环,对于这种测试,C++程序通常使用while循环。
二、while循环
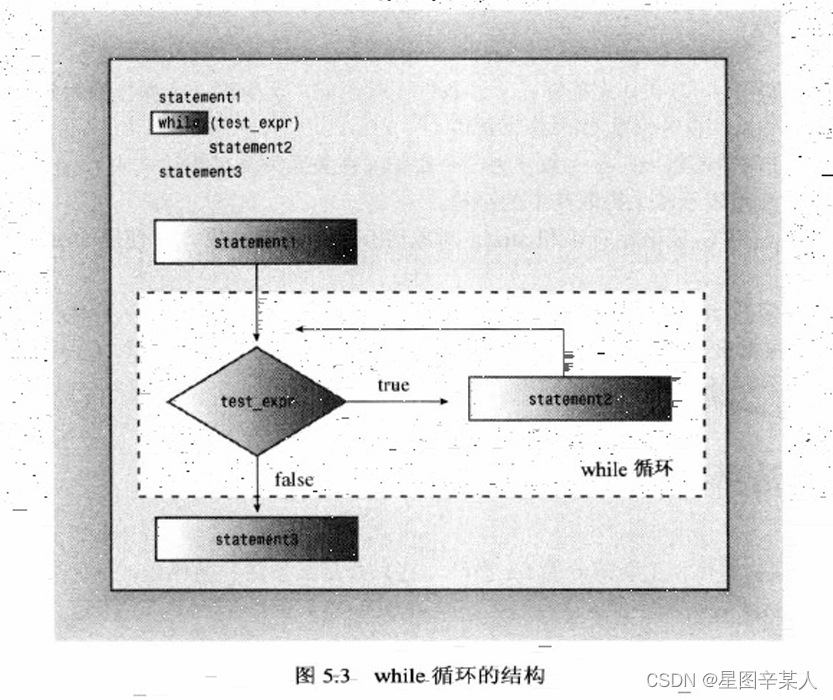
while循环是没有初始化和更新部分的for循环,它只有测试条件和循环体:
while (test-condition)
body
首先,程序计算圆括号内的测试条作(test-condition)表达式。如果该表达式为true,则执行循环体中的语句。与for 循环一样,循环体也由一条语句或两个花括号定义的语句块组成。执行完循环体后,程序返回测试条件,对它进行重新评估。如果该条件为非零,则再次执行循环体。测试和执行将一直进行下去,直到测试条件为false为止。和for 循环一样,while 循环也是一种入口条件循环。因此,如果测试条件一开始便为false,则程序将不会执行循环体。
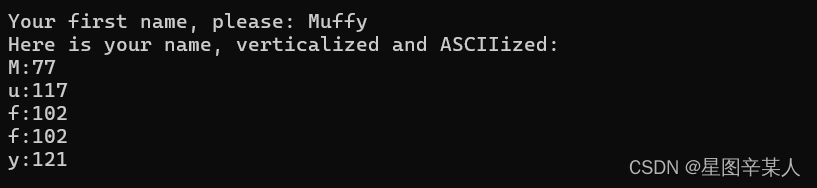
#include <iostream>
const int ArSize = 20;
using namespace std;
int main()
{
char name [ArSize];
cout << "Your first name, please: ";
cin >> name;
cout << "Here is your name, verticalized and ASCIIized: \n";
int i =0;
while (name [i] != '\0')
{
cout << name[i] <<":"<<int (name [i]) << endl;
i++;
}
return 0;
}
1.for和while循环
在C++中,for和while循环本质上是相同的。
for (init-expression; test-expression; update-expression)
{
statement (s);
}
等效于
init-expression;
while (test-expression){
statement (s);
update-expression;}
for和while循环之间有三个区别:
- for循环省略测试条件时,默认为true,而while省略测试条件时,默认为false;
- 其次,在for循环中,可使用初始化语句声明一个局部变量,但在while循环中不能这样做;
- 当两者里面的循环体都有continue时,对于for循环,它会结束当次循环,执行迭代表达式,再进行测试看是否进入下次循环,而while循环会直接结束当次循环,直接进行测试部分。因此,for循环的迭代部分在continue之后,而while的迭代部分在continue之前。
通常,程序员使用for循环来为循环计数,因此在预知循环次数时,可以使用for。在无法预先知道循环将执行的次数时,程序员常使用while循环。
2.循环指导原则
- 指定循环终止条件;
- 在首次测试之前,初始化条件;
- 在条件被再次测试之前,更新条件。
3.等待一段时间:编写延时循环
while循环可用于延时循环。一种用于个人计算机的早期技术是,让计算机进行计数,以等待一段时间:
long wait=0;
while(wait<10000)
wait++;
这种方法的问题是,当计算机处理器的速度发生变化时,必须修改计数限制。例如。有些为IBM PC编写的游戏在速度更快的机器上运行时,其速度将快得无法控制;另外,有些编译器可能修改上述代码,将wait设置为10000,从而跳过该循环。更好的方法是让系统时钟来完成这种工作。
ANSI C和C++库中有一个名为clock()的函数有助于完成这样的工作。这个函数返回程序开始执行后所用的系统时间。这有两个复杂的问题:首先,clock()返回时间的单位不一定是秒;其次,该函数的返回类型在某些系统上可能是long,在另一些系统上可能是unsigned long或其他类型。
但头文件ctime提供了这些问题的解决方案。首先,它定义了一个符号常量CLOCKS_PER_SEC,该常量等于每秒钟包含的系统时间单位数。因此,将系统时间除以这个值,可以得到秒数。或者将秒数乘以CLOCKS_PER_SEC,可以得到以系统时间单位为单位的时间。其次,ctime将clock_t 作为 clock()返回类型的别名,这意味着可以将变量声明为clock_t类型,编译器将把它转换为 long、unsigned int或适合系统的其他类型。
#include <iostream>
#include <ctime>
using namespace std;
int main()
{
cout << "Enter the delay time, in seconds:";
float secs;
cin >> secs;
clock_t delay = secs * CLOCKS_PER_SEC;
cout << "starting\n";
clock_t start = clock ();
while (clock()-start<delay)
cout << "done\n";
return 0;
}
4.类型别名
C++为类型建立别名的方式有两种。一种是使用预处理器:
#define typename endname;
//在预处理器编译时将typename替换为endname,而typename就成为了endname的别名
第二种方法是使用C++(和C)的关键字typedef来创建别名:
typedef endname typename;
如果要将typename作为某种类型的别名,可以声明typename,如同将typename声明为这种类型的变量那样,然后在声明的前面加上关键字typedef。
例如,要让byte_pointer成为char指针的别名,可将byte_pointer声明为char指针,然后在前面加上typedef:
typedef char * byte_pointer;
也可以使用#define,不过声明一系列变量时,这种方法不适用。
例如,请看下面的代码:
#define FLOAT_POINTER float *
FLOAT_POINTER pa,pb;
预处理器置换将该声明转换为:
float* pa,pb;
其中只有pa是指针,而pb是float类型。
typedef方法不会有这样的问题。它能够处理更复杂的类型别名,这使得与使用#define相比,使用typedef是一种更佳的选择而有时候,这也是唯一的选择。注意,typedef不会创建新类型,而只是为已有的类型建立一个新名称。
三、do while循环
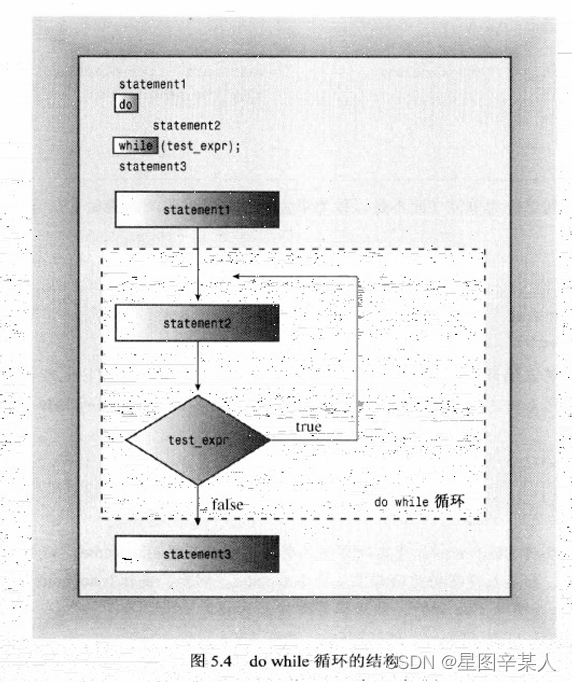
do while不同于另外两种循环,因为它是出口条件循环。这意味着这种循环将首先执行循环体,然后再判定测试表达式,决定是否应继续执行循环。如果条件为false,则循环终止;否则。进入新一轮的执行和测试。这样的循环通常至少执行一次,因为其程序流必须经过循环体后才能到达测试条件。
下面是其句法:
do
body
while (test-expression);
#include <iostream>
using namespace std;
int main()
{
int n;
cout << "Enter numbers in the range 1-10 to find";
cout << "my favorite number\n";
do
{
cin >>n;
}while(n!=7);
cout << "Yes, 7 is my favorite. \n" ;
return 0;
}

四、基于范围的for循环(C++11)
C++11新增了一种循环:基于范围的for循环。这简化了一种常见的循环任务:对数组(或容器类,如vector和array)的每个元素执行相同的操作。
如下例:
double prices [5] = {4.99, 10.99, 6.87, 7.99, 8.49};
for (double x : prices)
cout << x << std: : endl ;其中,x最初表示数组prices的第一个元素。显示第一个元素后,不断执行循环,而x依次表示数组的其他元素。因此,上述代码显示全部5个元素,每个元素占据一行。总之,该循环显示数组中的每个值。类似于python的for···in···,都是实现的可迭代自增。
要修改数组的元素,需要使用不同的循环变量语法:
for (double &x : prices)
x = x * 0.80;
符号&表明x是一个引用变量,这种声明让接下来的代码能够修改数组的内容,而第一种语法不能。还可结合使用基于范围的for循环和初始化列表:
for (int x: {3,5,2,8,6})
cout << x << " " ;
cout << '\n';
五、循环和文本输入
循环完成的一项最常见、最重要的任务:逐字符地读取来自文件或键盘的文本。
1.使用原始的cin输入
使用循环来读取来自键盘的文本输入,则必须知道何时停止读取。一种方法是选择某个特殊字符,有时被称为哨兵字符,将其作为停止标记。
#include <iostream>
using namespace std;
int main()
{
char ch;
int count = 0;
cout << "Enter characters; enter # to-quit:\n";
cin >>ch;
while (ch != '#')
{
cout << ch;
++count ;
cin >> ch;
}
cout << endl << count << " characters read\n";
return 0;
}

程序说明
该程序在循环之前读取第一个输入字符,这样循环可以测试第一个字符。这很重要,因为第一个字符可能是#。由于程序使用的是入口条件循环,因此在这种情况下,能够正确地跳过整个循环。由于前面已经将变量count设置为0,因此count的值也是正确的。
注意,该循环设计遵循了前面指出的几条指导原则。结束循环的条件是最后读取的一个字符是#。该条件是通过在循环之前读取一个字符进行初始化的,而通过循环体结尾读取下一个字符进行更新。
cin对前导空白的处理?
当使用cin读取字符时,它会读取并忽略前导的空白字符,包括空格、换行符、制表符等,直到遇到第一个非空白字符。因此,该程序中cin相当于每次都是单独调用,就会将那些空格忽略掉。
更为复杂的是,发送给cin的输入被缓冲。这意味着只有在用户按下回车键后,他输入的内容才会被发送给程序。这就是在运行该程序时,可以在#后面输入字符的原因。按下回车键后,整个字符序列将被发送给程序,但程序在遇到#字符后将结束对输入的处理。
2.使用cin.get(char)进行补救
通常,逐个字符读取输入的程序需要检查每个字符,包括空格、制表符和换行符。cin 所属的istream类中包含一个叫做cin.get(ch)的成员函数,它读取输入中的下一个字符(即使它是空格),并将其赋给变量ch。
#include <iostream>
using namespace std;
int main()
{
char ch;
int count = 0;
cout << "Enter characters; enter # to-quit:\n";
cin.get(ch);
while (ch != '#')
{
cout << ch;
++count ;
cin.get(ch);
}
cout << endl << count << " characters read\n";
return 0;
}
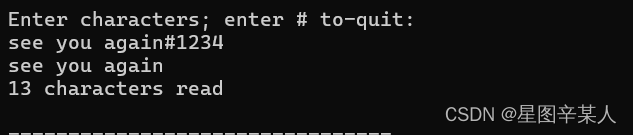
现在,该程序回显了每个字符,并将全部字符计算在内,其中包括空格。输入仍被缓冲,因此输入的字符个数仍可能比最终到达程序的要多。
接下来看看这个函数的奇特之处,C语言中想要使用函数改变变量的值,需要将地址传进去;但在C++中,只需要将函数参数声明为引用,就可以使用函数改变变量的值。头文件iostream将cin.get(ch)的参数声明为引用类型,因此该函数可以修改其参数的值。
3.使用哪一个cin.get()
cin.get()的一个版本接受两个参数:数组名(字符串(char*类型)的地址)和ArSize(int类型的整数)。还有一个版本是不接受任何参数的cin.get()。上面我们还使用了一个接受一个参数的cin.get(ch)。
在C语言中,如果函数接受char指针和int参数,则使用该函数时,不能只传递一个参数。但在C++中,可以这样做,因为该语言支持被称为函数重载的OOP特性。函数重载允许创建多个同名函数,条件是它们的参数列表不同。
例如,如果在C++中使用cin.get(name,ArSize),则编译器将找到使用char*和int作为参数cin.get()版本;如果使用cin.get(ch),则编译器将使用接受一个char参数的版本;如果没有提供参数,则编译器将使用不接受任何参数的cin.get()版本。
函数重载允许对多个相关的函数使用相同的名称,这些函数以不同方式或针对不同类型执行相同的基本任务。
4.文件尾条件
使用#等符号作为输入结束的标志有时不太好,因为这些符号可能是合法输入的一部分。如果输入来自于文件,则可以使用一种功能更强大的技术,检测文件尾(EOF)。C++输入工具和操作系统协同工作,来检测文件尾并将这种信息告知程序。
读取文件中的信息似乎同cin和键盘输入没什么关系,但其实存在两个相关的地方。首先,很多操作系统(包括Unix、Linux和Windows命令提示符模式)都支持重定向,允许用文件替换键盘输入。
例如,假设在Windows中有一个名为gofish.exe的可执行程序和一个名为fishtale的文本文件,则可以在命令提示符模式下输入下面的命令:
gofish <fishtale
这样,程序将从fishtale文件而不是键盘获取输入。<符号是Unix和Windows命令提示符模式的重定向运算符。
其次,很多操作系统都允许通过键盘来模拟文件尾条件。在Unix中,可以在行首按下Ctrl+D来实现;在Windows命令提示符模式下,可以在任意位置按Ctrl+Z和Enter。有些C++实现支持类似的行为,即使底层操作系统并不支持。键盘输入的EOF概念实际上是命令行环境遗留下来的。
总之,很多PC编程环境都将Ctrl+Z视为模拟的EOF,但具体细节(必须在行首还是可以在任何位置,是否必须按下回车键等)各不相同。
如果编程环境能够检测EOF,可以在程序中使用重定向的文件,也可以使用键盘输入,并在键盘输入中模拟EOF。有些系统不支持来自键盘的模拟EOF;有些系统对其支持不完善。cin.get()可以用来锁住屏幕,直到可以读取为止,但是这种方法在这里并不适用,因为检测EOF时将关闭对输入的进一步读取。然而,可以计时循环来使屏幕在一段时间内是可见的,也可使用cin.clear()来重置输入流。
检测到EOF后,cin将两位(eofbit和failbit)都设置为1。可以通过成员函数eof()来查看eofbit是否被设置;如果检测到EOF,则cin.eof()将返回bool值true,否则返回false。同样,如果eofbit或failbit被设置为1,则fail()成员函数返回true,否则返回false。注意,eof()和fail()方法报告最近读取的结果;也就是说,它们在事后报告,而不是预先报告。因此应将cin.eof()或cin.fail()测试放在读取后,下个程序中的设计体现了这一点。它使用的是fail(),而不是eof(),因为前者可用于更多的实现中。
#include <iostream>
using namespace std;
int main()
{
char ch;
int count = 0;
cout << "Enter characters; enter # to-quit:\n";
cin.get(ch);
while (cin.fail()==false)
{
cout << ch;
++count ;
cin.get(ch);
}
cout << endl << count << " characters read\n";
return 0;
}
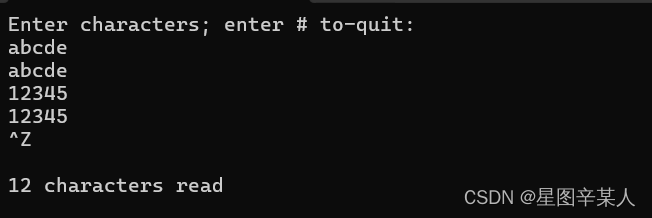
这里在Windows11系统上运行该程序,因此可以按下Ctrl+Z和回车键来模拟EOF条件,在Unix和类Unix(包括Linux和Cygwin)系统中,用户应按Ctrl+Z组合键将程序挂起,而命令fg恢复执行程序。
通过使用重定向,可以用该程序来显示文本文件,并报告它包含的字符数。

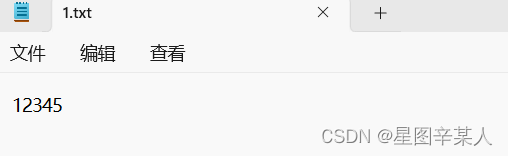
(1)EOF结束输入
cin方法检测到EOF时,将设置cin对象中一个指示EOF条件的标记。设置这个标记后,cin将不读取输入,再次调用cin也不管用。对于文件输入,程序不应读取超出文件尾的内容。然而,对于键盘输入,有可能使用模拟EOF来结束循环,但稍后要读取其他输入。cin.clear()方法可能清除EOF标记,使输入继续进行。不过在有些系统中,按Ctrl+Z实际上将结束输入和输出,而cin.clear()将无法恢复输入和输出。
(2)常见的字符输入做法
每次读取一个字符,直到遇到EOF的输入循环的基本设计如下:
cin.get (ch);
while (cin.fail() == false)
{
cin.get (ch);
}
使用!运算符可以实现false和true的转换,因此可以简化为
while (!cin.fail())
方法cin.get(char)的返回值是一个cin对象。然而,istream类提供了一个可以将istream对象(如cin)转换为bool值的函数;当cin出现在需要bool值的地方时,该转换函数将被调用。另外,如果最后一次读取成功了,则转换得到的bool值为true;否则为false。
因此,可以简化为
while (cin)
这比!cin.fail()或!cin.eof()更通用,因为它可以检测到其他失败原因,如磁盘故障。
最后,由于cin.get(char)的返回值为cin,因此可以将循环简化为:
while(cin.get(ch))
{
...
}
这样,cin.get(char)只被调用一次,而不是两次。为判断循环测试条件,程序必须首先调用cin.get(ch)。如果成功,则将值放入ch中。然后,程序获得函数调用的返回值,即cin。接下来,程序对cin进行bool转换,如果输入成功,则结果为true,否则为false。三条指导原则(确定结束条件、对条件进行初始化以及更新条件)全部被放在循环测试条件中。
5.另一个cin.get()版本
C语言中的字符I/O函数——getchar()和putchar(),仍然适用,只要像在C语言中那样包含头文件stdio.h或新的cstdio即可。也可以使用istream和ostream类中类似功能的成员函数。
不接受任何参数的cin.get()成员函数返回输入中的下一个字符。
ch = cin.get();
该函数的工作方式与C语言中的getchar()相似,将字符编码作为int值返回;而cin.get(ch)返回一个对象,而不是读取的字符。同样,可以使用cout.put()函数来显示字符:
cout.put (ch);
该函数的工作方式类似C语言中的putchar(),只不过其参数类型为char,而不是int,但传入字符的ASCII码值也是有效的,因为char实际上就是一种整数。
最初,put()成员只有一个原型put(char)。可以传递一个int参数给它,该参数将被强制转换为char。C++标准还要求只有一个原型。然而,有些C++实现都提供了3个原型:put(char)、put(signed char)和put(unsigned char)。在这些实现中,给put()传递一个int参数将导致错误消息,因为转换int的方式不止一种。使用显式强制类型转换的原型(如cin.put(char(ch)))可使用int参数。
为成功地使用cin.get(),需要知道其如何处理EOF条件。当该函数到达EOF时,将没有可返回的字符。相反,cin.get()将返回一个用符号常量EOF表示的特殊值。该常量是在头文件iostream中定义的。EOF 值必须不同于任何有效的字符值,以便程序将EOF与常规字符区分开。通常,EOF被定义为值-1,因为没有ASCII码为-1的字符,但并不需要知道实际的值,而只需在程序中使用EOF即可。
char ch;
cin.get (ch) ;
while (cin.fail() == false)
{
cout << ch;
++count ;
cin.get (ch);
}可以使用int ch,并用cin.get()代替 cin.get(char),用cout.put()代替 cout,用EOF 测试代替 cin.fail()测试:
int ch;
ch=cin.get() ;
while (ch!=EOF)
{
cout.put(ch);
++count ;
ch=cin.get() ;
}如果ch是一个字符,则循环将显示它。如果ch为EOF,则循环将结束。EOF不表示输入中的字符,而是指出没有字符。
由于EOF表示的不是有效字符编码,因此可能不与char类型兼容。例如,在有些系统中,char类型是没有符号的,因此char变量不可能为EOF值(-1)。由于这种原因,如果使用cin.get()(没有参数)并测试EOF,则必须将返回值赋给int变量,而不是char变量。另外,如果将ch的类型声明为int,而不是char,则必须在显示ch时将其强制转换为char类型,这也是为了防止char无法赋值为-1而导致程序无法结束。
#include <iostream>
using namespace std;
int main()
{
int ch;
int count=0;
while ((ch=cin.get())!=EOF)
{
cout.put(char(ch));
++count ;
}
return 0;
}

使用字符参数的版本更符合对象方式,因为其返回值是istream对象。这意味着可以将它们拼接起来。
例如,下面的代码将输入中的下一个字符读入到ch1中,并将接下来的一个字符读入到ch2中:cin.get(ch1).get (ch2);
这是可行的,因为函数调用cin.get(ch1)返回一个cin对象,然后便可以通过该对象调用get(ch2)。
get()的主要用途是能够将stdio.h的getchar()和 putchar()函数转换为iostream的cin.get()和cout.put()方法。只要用头文件iostream替换stdio.h,并用作用相似的方法替换所有的getchar()和putchar()即可。
六、嵌套循环和二维数组
声明格式为
typename a[n_row][n_col];
n_row为行数,n_col为列数。
for(int i=0;i<n_row;i++)
{
for(int j=0;j<n_col;j++)
{
cout<<a[i][j]<<'\t';
}
cout<<endl;
}
该程序可以打印数组所有内容。
1.初始化二维数组
创建二维数组时,可以初始化其所有元素。这项技术建立在一维数组初始化技术的基础之上:提供由逗号分隔的用花括号括起的值列表。对于二维数组来说,由于每个元素本身就是一个数组,因此可以使用与一维数组类似的格式来初始化每一个元素。因此,初始化由一系列逗号分隔的一维数组初始化(用花括号括起)组成:
int a[2][3] =
{
{1,2,3},
{4,5,6}
}
2.使用二维数组、
#include <iostream>
using namespace std;
const int n_city=2;
const int year=3;
int main()
{
const char* city[n_city]={"New York","New Gribble"};
int a[year][n_city]=
{
{1,2},
{3,4},
{5,6}
};
for(int i=0;i<n_city;i++)
{
cout<<city[i]<<'\t';
for(int j=0;j<year;j++)
{
cout<<a[i][j]<<" ";
}
cout<<endl;
}
return 0;
}

在输出中使用制表符比使用空格可使数据排列更有规则。然而,制表符设置不相同,因此输出的外观将随系统而异。同样也可以使用char数组的数组来代替字符串指针数组,但这样需要做出最大长度的限制,而且还可能造成空间浪费。所以,从存储空间的角度说,使用指针数组更为经济;然而,如果要修改其中的任何一个字符串,则二维数组是更好的选择。这两种方法使用相同的初始化列表,显示字符串的for循环代码页相同。另外,还可以使用string对象数组,而不是字符串指针数组。只需要将char*换为string即可。

















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









