



我们都知道进程、线程的执行,都是需要用CPU去跑去处理的。那么,在后台同时开了很多个进程的时候,CPU忙过不来怎么办?谁先执行、谁后执行咋规定的?
看过小林大佬花的图的都知道下面这张图,是多级反馈队列调度器,也就是兼顾了优先级和公平性的一版调度算法。
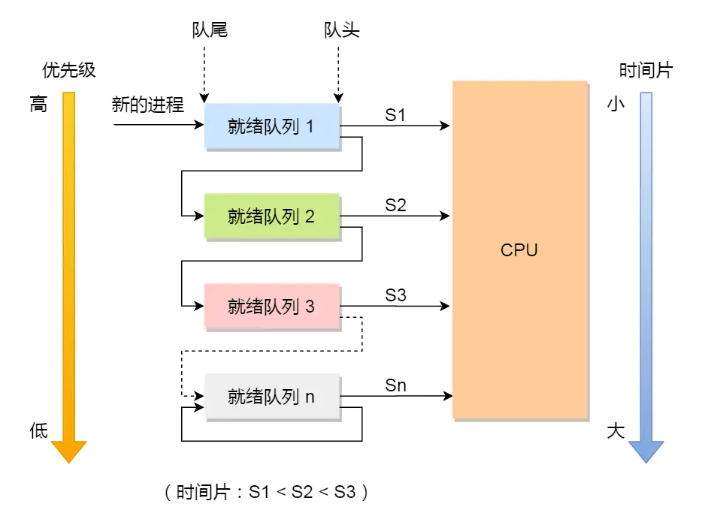
那么,Linux是采用什么调度器呢,也是多级反馈队列调度算法吗?
先说结论:
跟多级反馈队列调度算法有点相似,但是不是。Linux采用的 完全公平调度器 通过 虚拟运行时间 + 红黑树管理 ,实现近似公平的CPU分配
完全公平调度器 的核心思想
是什么?
-
抛弃时间片轮转:传统调度器依赖固定时间片分配,而完全公平调度器通过虚拟运行时(vruntime)动态计算进程的CPU使用权。
-
公平性定义:所有可运行进程的
vruntime应尽可能接近,即每个进程获得"公平"的CPU时间。
为什么需要?
-
解决传统调度器的交互式进程响应延迟问题(如桌面环境卡顿)。
-
避免静态优先级分配导致的不公平性(如低优先级进程饥饿)。
完全公平调度器 的关键实现机制
虚拟运行时(vruntime)
-
计算公式:
vruntime = 实际运行时间 × (NICE_0_LOAD / 进程权重)
-
NICE_0_LOAD:也就是nice值,默认是0。 -
进程权重:由进程的
nice值映射而来的值。 -
看不懂这俩参数?其实简单来说,就是vruntime 与运行时间、nice_0_load成正比,和权重成反比;而vruntime越低,是会越先执行的。
-
作用: 这样设计,能确保设置了高优先级(也就是低nice值)的进程,它的
vruntime增长更慢,从而获得更多CPU时间。即权衡了时间分配避免饿死,又让高优先级的能尽量先执行到。
红黑树管理
-
数据结构:所有可运行进程按
vruntime排序,存储在红黑树中。 -
调度选择:每次选择
vruntime最小的进程(即最左侧节点)运行。 -
时间复杂度:插入/删除操作为
O(log n),高效支持大规模进程调度。
时间分配
-
调度周期:默认6ms(根据进程数动态调整)。
-
进程时间片:
-
时间片 = (调度周期 × 进程权重) / 总权重 -
例如:若只有A、B进程,且 进程A权重 是 进程B权重 的2倍,则A的时间片也是B的2倍。
抢占与唤醒(时间都给你占完了,我花什么?什么时候轮到我!!!!!!!!!!)
-
抢占条件:当运行进程的
vruntime超过红黑树中最左侧进程的vruntime+ 设置的阈值 时,触发抢占。 -
交互式优化:新唤醒的交互式进程(如GUI)会被临时赋予更小的
vruntime,优先执行。
完全公平调度器的实际效果
优势
| 特性 | 表现 |
| 公平性 | 所有进程的CPU时间比例严格按权重分配(如nice=0的进程永远占50% CPU)。 |
| 低延迟 | 交互式进程(如浏览器)即使在高负载下也能快速响应(得益于动态vruntime)。 |
| 高吞吐量 |
批处理任务(如编译)能充分利用CPU,避免频繁切换的开销。 |
性能数据
-
交互式任务响应时间:比传统调度器缩短30%~50%。
-
多核扩展性:红黑树结构支持数千个进程的高效调度。
对比传统调度器
| 特性 | 完全公平调度器 | 传统调度器 |
| 公平性 | 动态权重分配,严格公平 | 静态优先级,可能饥饿低优先级任务 |
| 复杂度 | 红黑树维护(O(log n)) | 固定时间片队列 |
| 适用场景 | 通用场景(服务器、桌面) | 早期内核(2.6.23前) |
总结
Linux的完全公平调度器通过虚拟运行时和红黑树管理实现了理论上的完全公平,同时通过动态调整兼顾了交互式任务的低延迟和批处理任务的高吞吐量。


















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











