






 本文详细解析了如何使用PyTorch实现生成多个锚框的过程,包括参数解析、偏移量设置、尺寸和比例计算,以及torch.cat(),torch.stack(),repeat_interleave()等函数的应用。重点在于理解机器视觉中锚框生成的核心算法和代码实现。
本文详细解析了如何使用PyTorch实现生成多个锚框的过程,包括参数解析、偏移量设置、尺寸和比例计算,以及torch.cat(),torch.stack(),repeat_interleave()等函数的应用。重点在于理解机器视觉中锚框生成的核心算法和代码实现。
生成多个锚框函数解析
前言
本代码是来自李沐老师的《动手学深度学习》里的第13章机器视觉里的锚框部分
链接: link,以下是关于13.4.1的生成多个锚框函数multibox_prior的理解:
完整代码
import torch
from PIL import Image
from torchvision import transforms
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
"""锚框创建函数"""
def build_boxes(data, sizes, ratios, device):
# data.shape=torch.Size([batch, channel, height, width])
# sizes:缩放比,ratios:宽高比
num_sizes, num_ratios = len(sizes), len(ratios)
num_boxes = num_sizes + num_ratios - 1 # 获取锚框数量
sizes, ratios = torch.tensor(sizes, device=device), torch.tensor(ratios, device=device)
data_height, data_width = data.shape[-2:] # 获取数据的长和宽
offset_h, offset_w = 0.5, 0.5 # 设置偏移量,将瞄框点设置在像素中间
step_h = 1.0 / data_height # 高度缩放比例
step_w = 1.0 / data_width # 宽度缩放比例
# 生成锚框的所有中心点
center_h = (torch.arange(data_height, device=device) + offset_h) * step_h # 锚框的高和宽的中心点
center_w = (torch.arange(data_width, device=device) + offset_w) * step_w
shift_y, shift_x = torch.meshgrid(center_h, center_w) # 把center_h和center_w坐标做成二维表格
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1) # 再把二维表格坐标reshape为一维
# 计算锚框宽和高
w = torch.cat((sizes * torch.sqrt(ratios[0]), sizes[0] * torch.sqrt(ratios[1:])))
h = torch.cat((sizes / torch.sqrt(ratios[0]), sizes[0] / torch.sqrt(ratios[1:])))
# 计算锚框的一半宽和高
half_w_h = torch.stack((-w, -h, w, h)).T.repeat(data_height * data_width, 1) / 2
# 生成锚框偏移后的x1,y1,x2,y2坐标
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y], dim=1).repeat_interleave(num_boxes, dim=0)
output = out_grid + half_w_h
# 返回值为(批量大小,锚框数量,4个坐标)
return output.unsqueeze(0)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
img = Image.open('../img/catdog.jpg')
img = transforms.ToTensor()(img) # 将图片转换为tensor类型
h, w = img.shape[1:]
X = torch.rand(size=(1, 3, h, w))
Y = build_boxes(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5], device= device)
print(Y.shape)
代码解析
我将代码分成多个部分进行解析
参数解析
def build_boxes(data, sizes, ratios, device):
# data.shape=torch.Size([batch, channel, height, width])
# sizes:缩放比,ratios:宽高比
num_sizes, num_ratios = len(sizes), len(ratios)
num_boxes = num_sizes + num_ratios - 1 # 获取锚框数量
sizes, ratios = torch.tensor(sizes, device=device), torch.tensor(ratios, device=device)
data_height, data_width = data.shape[-2:] # 获取数据的长和宽
data:传入tensor格式的图片数据,size为[批次,通道,高度,宽度]
sizes:缩放比,确定锚框的大小
ratios:高宽比,确定锚框的形状
device:使用GPU还是CPU
首先确定每个像素要生成的锚框数量:
设sizes=[0.75, 0.5, 0.25], ratios=ratios=[1, 2, 0.5],本来是应该有3x3=9种组合:
(s1, r1),(s1, r2),(s1, r3),(s2, r1),(s2, r2),(s2, r3),(s3, r1),(s3, r2),(s3, r3)
但是李沐老师为了简化计算,就只取了包含s1和r1的组合部分:
(s1, r1),(s1, r2),(s1, r3),(s2, r1),(s3, r1)
这样子就变成了3 + 3 -1 = 5种
定义num_boxes接收每个像素点生成的锚框个数
把sizes,ratios转换成tensor形式并传入设备
利用data.shape[-2:]获取数据的高度和宽度
设置偏移量与缩放比
offset_h, offset_w = 0.5, 0.5 # 设置偏移量,将瞄框点设置在像素中间
step_h = 1.0 / data_height # 高度缩放比例
step_w = 1.0 / data_width # 宽度缩放比例
为什么设置偏移量?
例如第一个初始瞄框坐标(0, 0)它并不在第一个像素点的中心,第一个像素点定义为长宽为1的正方形。如果要在像素点的正中心就要在初始瞄框坐标各个偏移0.5,那么就变成了(0.5,0.5),就实现了在像素点正中心。
为什么要设置高宽缩放比例?
进行归一化处理,因为前面的缩放比大于0小于1,对图片进行缩放,所以后续操作也要进行归一化处理,方便瞄框的缩小放大
生成锚框的所有中心点
# 生成锚框的所有中心点
center_h = (torch.arange(data_height, device=device) + offset_h) * step_h # 锚框的高和宽的中心点
center_w = (torch.arange(data_width, device=device) + offset_w) * step_w
shift_y, shift_x = torch.meshgrid(center_h, center_w) # 把center_h和center_w坐标做成二维表格
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1) # 再把二维表格坐标reshape为一维
利用torch.arange生成从0到data_height和data_width的序列,然后进行偏移量相加和归一化。
例如我定义一个data,定义长宽为10x10
获取data的长和宽

设置偏移量和缩放比例,生成对角中心点(这里生成的坐标都是图片对角线的坐标)

我们发现它们对应图片像素的坐标并不是一一对应的,而是产生对角线上的坐标。
所以需要torch.meshgrid(center_h, center_w)
我们导入pd方便查看
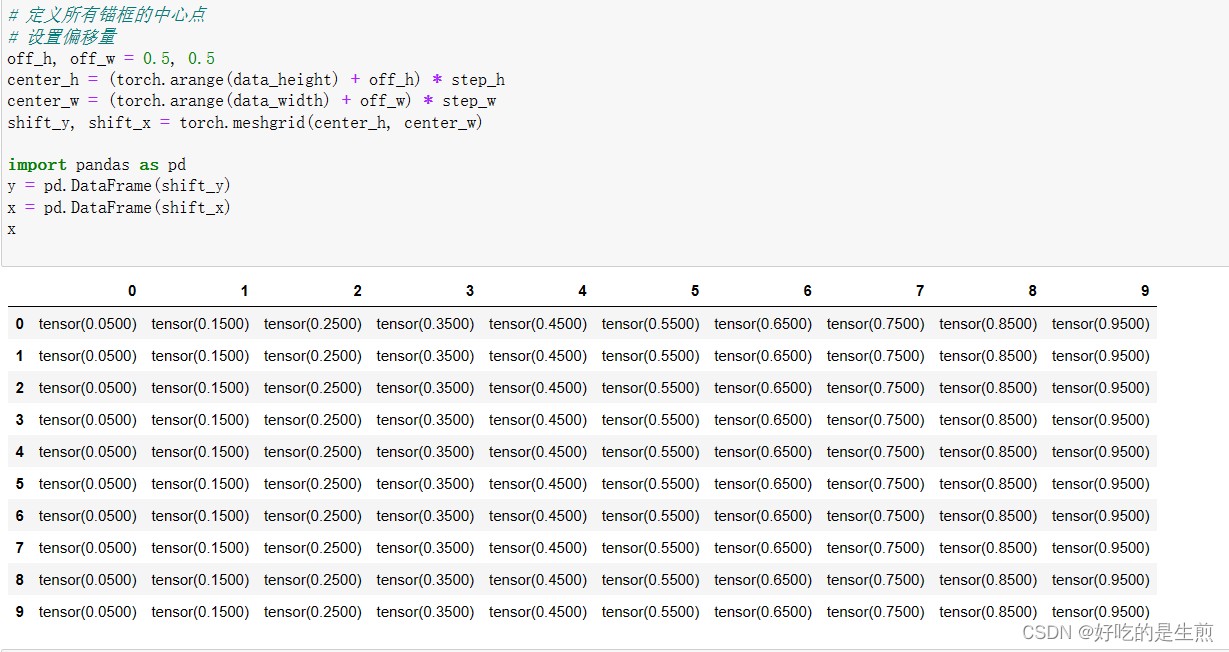
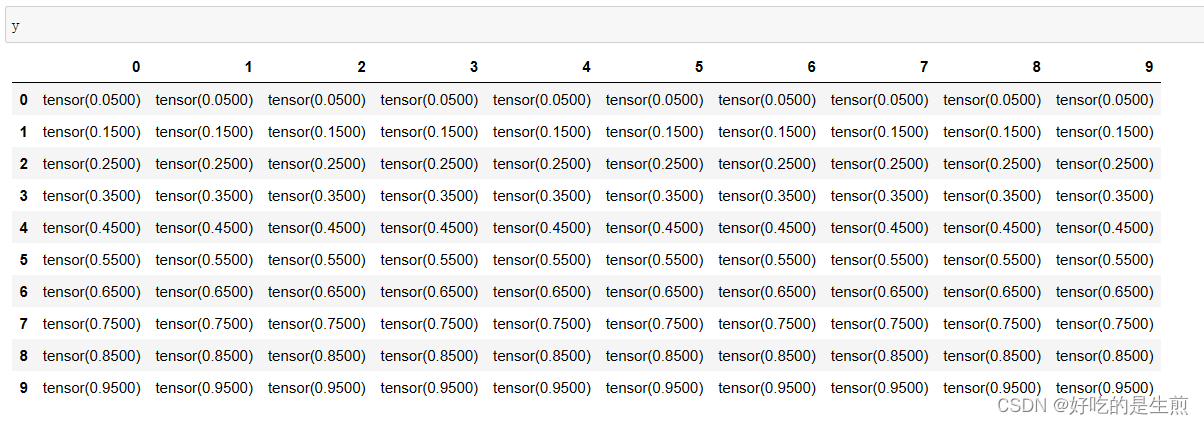
对应各个表格点就能发现他们能和我们像素点一一对应(利用广播机制)
最后把二维表格reshape为一维
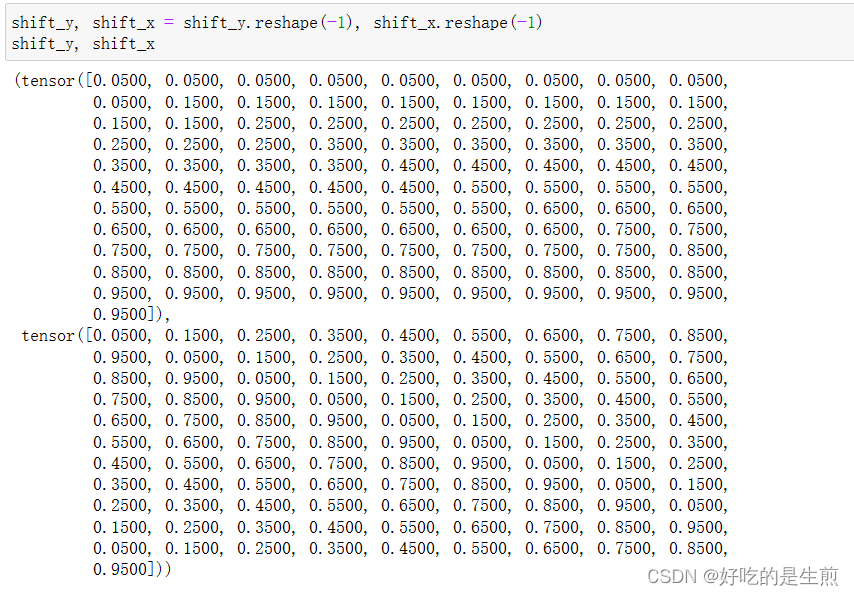
center_h, center_w就类比这个例子生成
计算锚框宽和高
w = torch.cat((sizes * torch.sqrt(ratios[0]), sizes[0] * torch.sqrt(ratios[1:])))
h = torch.cat((sizes / torch.sqrt(ratios[0]), sizes[0] / torch.sqrt(ratios[1:])))
这里是根据李沐老师所给出的锚框公式:
假设图像的高度为h,宽度为w,以图像的每个像素的中心生成不同形状的锚框,缩放比sizes,高宽比ratios。那么锚框的宽度和高度就可以分别表示为:
w
s
r
,
h
s
/
r
ws\sqrt{r} ,hs/\sqrt{r}
wsr,hs/r
而且前面提及到本来是可以生成 m * n 种锚框数量,但是李沐老师为了计算方便便只取s1和r1的组合
torch.cat()函数
下面我们将讲解torch.cat()函数:
我们简单定义两个一维矩阵
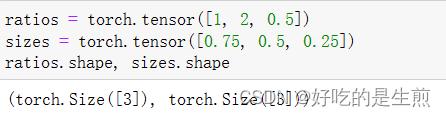
用torch.cat()函数将他们组合(函数里面还有个括号,不然报错)

我们发现两个函数组合还是一个一维的维度,但是长度变长,所以这个函数作用就是拼接
函数里面的参数:
sizes * torch.sqrt(ratios[0])
sizes表示s1,s2,s3,ratios[0]表示r1,这个式子表示(s1, r1)(s2, r1)(s3, r1)的组合相乘
sizes[0] * torch.sqrt(ratios[1:])
sizes[0]表示s1, ratios[1:]表示r2, r3,这个式子表示(s1, r2)(s1, r3)的组合相乘
刚好对应上面的只取s1和r1的组合,也对应了只有 m + n -1 种组合
tips:
李沐老师在处理w的时候后面还加上了 * data_height / data_width,其实我也不知道什么意思,但我感觉不加也是可以的
计算锚框的一半宽和高
half_w_h = torch.stack((-w, -h, w, h)).T.repeat(data_height * data_width, 1) / 2
torch.stack()函数
还是以sizes和ratios为例子:

我们发现与torch.cat()函数不同的是,它的维度变多了,本来两个一维组合变成二维的,而且我们还可以选择增加的维度在第几层

加在第1层发现,2跑到第二个维度上,默认是dim=0
torch.stack((-w, -h, w, h)).T
定位一个锚框需要知道它的两个坐标,左上和右下,根据像素中心点位置和锚框高宽我们即可确定:
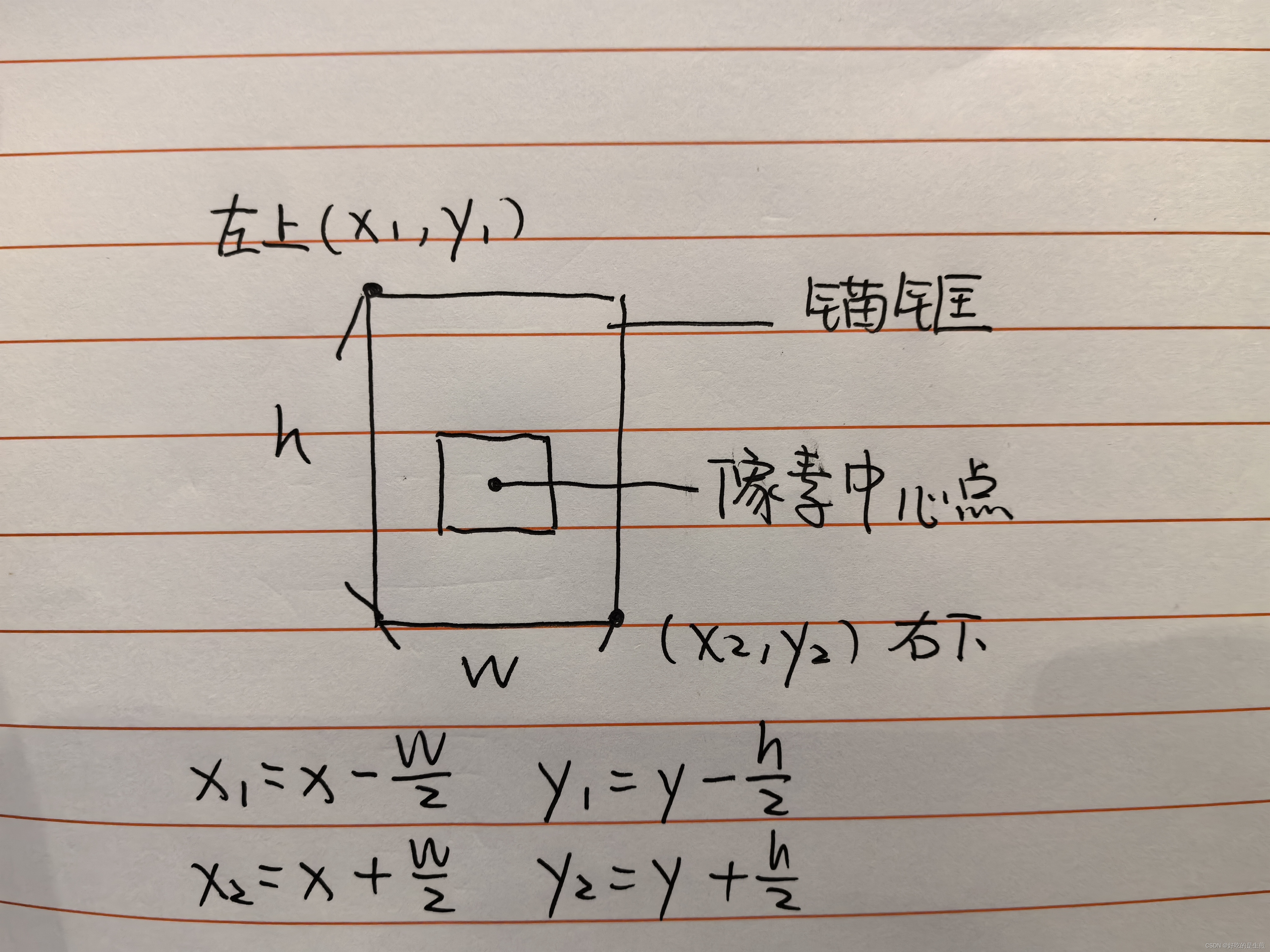
所以这个式子我们需要将-w,-h,w,h进行组合(后面还需要除以2)
本来的stack得到的是[4个坐标点, 一个像素点的锚框个数],我们把它规范化把4个坐标点放在第二个维度上所以需要转置
然后有多少个像素点就重复多少次
这里我假设重复3次,重复第一个维度
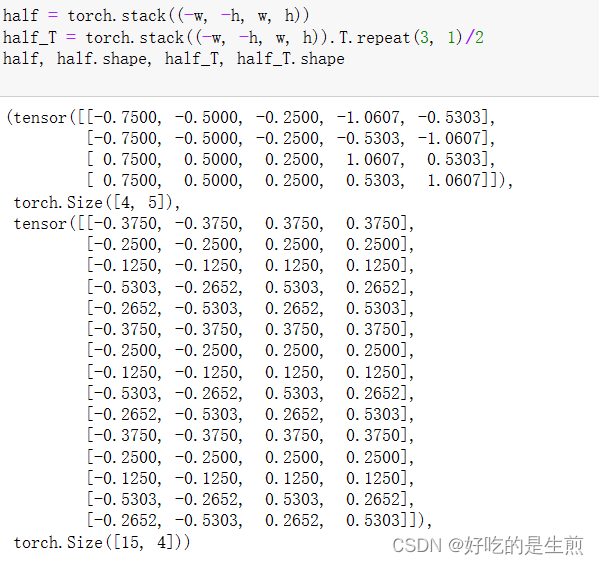
生成的shape就是[锚框个数, 四个需要计算的坐标]
生成锚框偏移后的x1,y1,x2,y2坐标
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y], dim=1).repeat_interleave(num_boxes, dim=0)
组合偏移后的x1, y1, x2, y2在第二层,对应上面的half_w_h
然后重复每个像素点生成的锚框数量
repeat_interleave()函数
比如这个例子
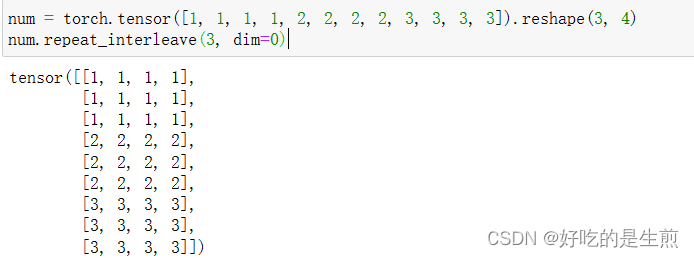
它是间隔dim=0层上然后重复和repeat不同,repeat是把所有层统一复制,而这个是间隔重复
最后我们再看看它的shape

与一般的锚框宽高对应
输出
output = out_grid + half_w_h
# 返回值为(批量大小,锚框数量,4个坐标)
return output.unsqueeze(0)
将他们相加,即可算出最后的x1,y1,x2,y2
最后用unsqueeze(0)再增加一个维度,表示批量大小
测试
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
img = Image.open('../img/catdog.jpg')
img = transforms.ToTensor()(img) # 将图片转换为tensor类型
h, w = img.shape[1:]
X = torch.rand(size=(1, 3, h, w))
Y = build_boxes(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5], device= device)
print(Y.shape)
将文件图片转换为tensor格式并获取图片的h, w
然后随机生成一个批次为1,3个通道,h,w的tensor数据(因为原来的图片转换后的格式为[3, h, w]并没有批量格式)
然后传入我们定义的函数看看最后生成的shape

ok,与李沐老师生成的shape也符合
这个警告我也不知道啥意思,知道的也欢迎解答

















 128
128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









