






目录
(一)位图
所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用 来判断某个数据存不存在的。
位图是一种用二进制位(0/1)存储数据的数据结构,每个位对应一个独立元素的状态(存在/不存在)。例如用第n位表示数字n是否存在,这种结构比传统数组节省3232倍内存(假设使用int类型存储)
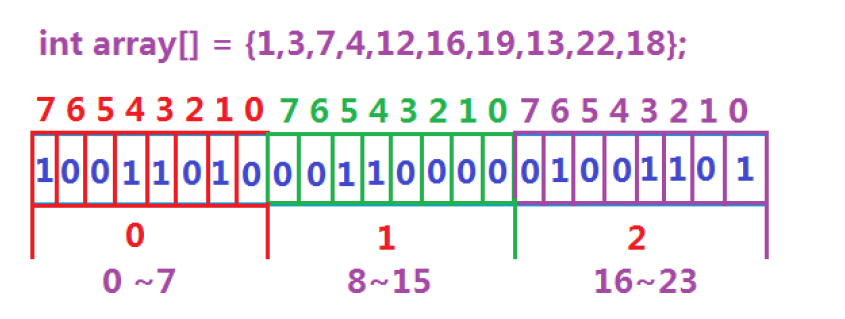
位图的模拟实现
1.位图的定义
//非类型模板参数 N, 控制位图的比特位个数
template<size_t N>
class bitset
{
public:
bitset()
{
_v.resize(N / 7 + 1);
}
void set(size_t value) //插入数据
void reset(size_t value) //删除数据
bool test(size_t value) //确认数据是否存在
private:
vector<int> _v;
};2.插入
当插入数据时,将数据对应的比特位状态改为 1。因为是使用int类型(32个bit),所以需要/32.
void set(size_t value)
{
size_t x = value / 32;
size_t y = value % 32;
_v[x] |= (1 << y);
}3.删除
当插入数据时,将数据对应的比特位状态改为 0
void reset(size_t value)
{
size_t x = value / 32;
size_t y = value % 32;
_v[x] &= (~(1 << y));
}4.查找
检查数据是否存在,存在则会true,不存在为false。
bool test(size_t value)
{
size_t x = value / 32;
size_t y = value % 32;
// 等于0则为false ,非0 为true
return _v[x] & (1 << y);
}(二)布隆过滤器
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概 率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
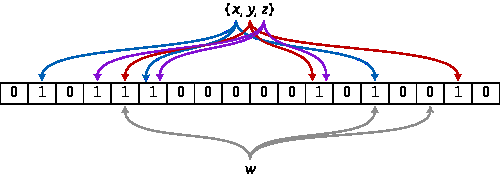
布隆过滤器的模拟实现
1.布隆过滤器定义
哈希函数
因为布隆过滤器大都针对字符串类型,所以这里的哈希函数也是针对string类
struct BKDRHash { size_t operator()(const string& s) { // BKDR size_t value = 0; for (auto ch : s) { value *= 31; value += ch; } return value; } }; struct APHash { size_t operator()(const string& s) { size_t hash = 0; for (long i = 0; i < s.size(); i++) { if ((i & 1) == 0) { hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3)); } else { hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5))); } } return hash; } }; struct DJBHash { size_t operator()(const string& s) { size_t hash = 5381; for (auto ch : s) { hash += (hash << 5) + ch; } return hash; } };
内部结构
//N为插入元素的个数, X 为布隆过滤器长度
template<size_t N, size_t X = 5, class type = string
, class HashFunc1 = BKDRHash, class HashFunc2 = APHash, class HashFunc3 = DJBHash>
class BloomFilter
{
public:
void set(const type& value)
bool test(const type& value)
private:
bitset<X* N> _bs;
};2.插入
布隆过滤器和位图差不多,只不过一个数据有多个映射(将一个元素用多个哈希函数映射到一个位图中)
void set(const type& value)
{
size_t hash1 = HashFunc1()(value) % (X * N);
size_t hash2 = HashFunc2()(value) % (X * N);
size_t hash3 = HashFunc3()(value) % (X * N);
_bs.set(hash1);
_bs.set(hash2);
_bs.set(hash3);
}3.查找
bool test(const type& value)
{
size_t hash1 = HashFunc1()(value) % (X * N);
size_t hash2 = HashFunc2()(value) % (X * N);
size_t hash3 = HashFunc3()(value) % (X * N);
return _bs.test(hash1) && _bs.test(hash2) && _bs.test(hash3);
}总结
一、位图
1. 概念与实现
位图通过每个比特位表示一个数据的存在性(0/1),适用于海量数据的快速存在性判断3。例如,40亿个整数(约16GB)用位图仅需约500MB内存。2. 应用场景
- 数据去重:如统计40亿整数中不重复的数字。
- 快速查询:判断IP是否在黑名单中。
- 排序:对有限范围的整数进行非比较排序
二、布隆过滤器(Bloom Filter)
1. 概念与实现
布隆过滤器通过k个哈希函数将元素映射到多个位,若所有对应位为1则“可能存在”,否则“一定不存在”。牺牲一定准确性换取极高的空间效率。2. 应用场景
- 缓存穿透防护:拦截不存在的数据请求,保护数据库。
- 分布式系统:减少节点间冗余数据传输。
- 爬虫URL去重:避免重复抓取已处理的页面。
3. 优缺点
- 优点:空间效率高,查询时间O(K)(K为哈希函数的个数),适合海量数据。
- 缺点:误判率随元素增加而上升,且不支持删除(除非引入计数布隆过滤器)。
三、对比
特性 位图 布隆过滤器 数据范围 适用于整数且范围较小 支持任意数据类型 误判率 无 有(可调整哈希函数数量优化) 删除支持 直接修改位即可 需额外结构(如计数位图) 典型场景 精确存在性判断 允许误判的存在性预筛 混合优化方案:结合位图与布隆过滤器,例如用位图处理高频数据,布隆过滤器处理低频数据,提升整体性能。

















 994
994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









