







最后
针对最近很多人都在面试,我这边也整理了相当多的面试专题资料,也有其他大厂的面经。希望可以帮助到大家。
最新整理面试题
上述的面试题答案都整理成文档笔记。也还整理了一些面试资料&最新2021收集的一些大厂的面试真题
最新整理电子书
最新整理大厂面试文档
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。

通过上面所述,如果我们选择驱动表的话,就要选择小表来做驱动表。否则大表做驱动表是要查询所有的,效率会低很多。当然,前提是"可以使用被驱动表的索引"
这里我们把sql语句改一下:
explain select * from t1 left join t2 on t1.a=t2.b;
复制代码
t2表的b字段是无索引的

结果就是两个表都要全表扫描,这里我们看到,Extra显示的是(Using where; Using join buffer (Block Nested Loop))
这个其实是MySQL对join不走索引全表扫描做了一个优化,简称BNL。
BNL流程:
-
把表t1的数据读入线程内存join_buffer中,这里我们是把整个表t1放入内存中。
-
扫描表t2,把表t2中的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回。
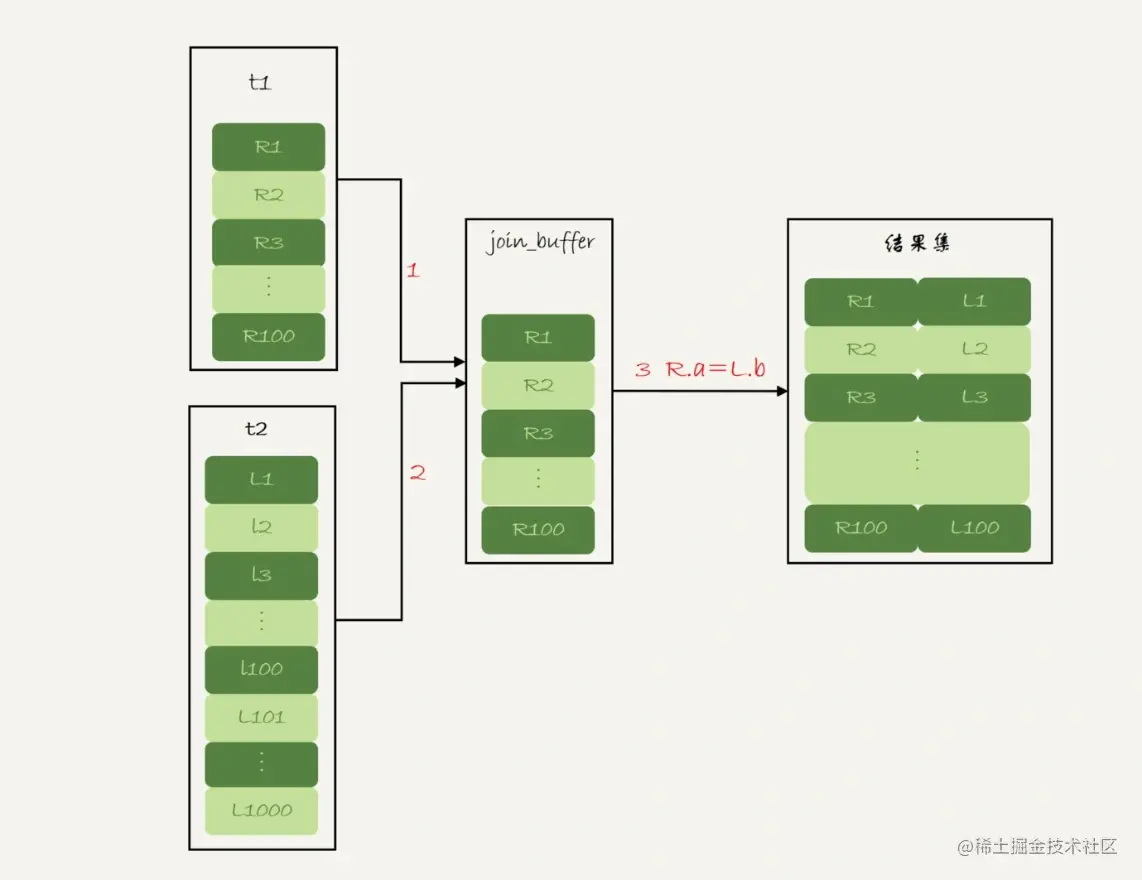
这里,我们两个表都是做的全表扫描,所以不管是哪个表做驱动表都是执行消耗都是一样的。
如果一个表的数据太大了,根本装不下所有数据的话,就采用分段放。也可以修改join_buffer_size。
针对于有索引的被驱动表,MySQL5.6版本开始增加了Batched Key Access(BKA)的新特性
对于多表join语句,当MySQL使用索引访问第一个join表的时候,使用join_buffer来收集第一个操作对象生成的相关列的值。BKA构建好key之后,通过MRR接口提交给引擎做查询。
BKA步骤:
-
将驱动表相关的列放入join_buffer中。
-
批量的将Key(索引键值)发送到MRR接口。
-
MRR通过收到的key,根据其对应的ROWID进行排序,然后再进行数据的读取操作。
这里来看,BKA和BNL其实是差不多的,主要区别就是BKA是针对被驱动表是走索引的情况下,索引是非主键索引的时候,按照索引字段进行排序,因此减少了随机IO,提高性能。
MRR
===
MySQL5.6版本开始支持的Multi-Range Read(MRR)优化。MRR目的是为了减少磁盘的随机访问,并且将随机访问转换为较为顺序的数据访问,MRR可适用于range,ref,eq_ref类型的查询
文末
我将这三次阿里面试的题目全部分专题整理出来,并附带上详细的答案解析,生成了一份PDF文档
- 第一个要分享给大家的就是算法和数据结构

- 第二个就是数据库的高频知识点与性能优化

- 第三个则是并发编程(72个知识点学习)

- 最后一个是各大JAVA架构专题的面试点+解析+我的一些学习的书籍资料
还有更多的Redis、MySQL、JVM、Kafka、微服务、Spring全家桶等学习笔记这里就不一一列举出来
sdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)收录**

















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









