







《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门,即可获取!
累加器是Spark中仅有通过关联操作进行累加的变量, 因此能够有效地支持并行计算, 它们能够用于计数(如MapReduce)和求和。 Spark原生支持数值类型的累加器, 不过开发人员能够定义新的类型。如果在创建累加器时指定了名称, 可以通过Spark的UI监控界面中进行查看, 这种方式能够帮助理解作业所构成的调度阶段执行过程。
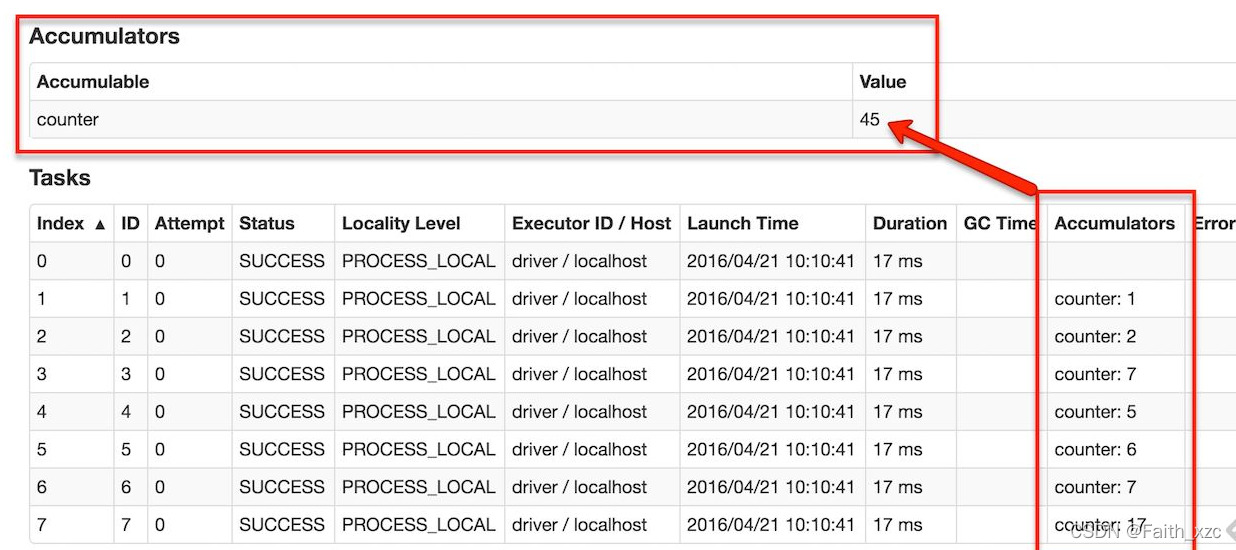
通过调用SparkContext.accumulator(v)方法初始化累加器变量V,在集群中的任务能够使用加法或者"+="操作符进行累加操作(在Scala和Python中)。然而, 它们不能在应用程序中读取这些值, 只能由Driver程序通过读方法获取这些累加器的值。
下面代码演示如何把一个数组的元素追加到累加器中:
scala> val accum = sc.accumulator (0, “My Accumulator”)
accum: spark.Accumulator[Int] = 0
scala> Sc.parallelize(Array(l, 2, 3, 4)).foreach(x => accum += x)
…
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
scala> accum.value
res2: Int = 10
尽管上面的例子使用Spark原生所支持的累加器Int类型,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









