






1. RPC协议设计
1.1. 协议的概念和作用
协议的定义:
在 RPC 中,协议指的是一种用于通信双方解析数据格式的应用层协议。它定义了:
- 数据的结构和顺序;
- 如何将消息打包、拆包;
- 如何识别请求的边界;
- 如何处理不同类型的请求和序列化方式。
协议的核心目标:让二进制数据能被正确解释,确保通信语义一致。
协议的作用:
1. 划分消息边界(最重要):
-
- 防止 TCP 粘包或拆包导致的数据解析错误;
- 类似于“标点符号”,帮助接收方“断句”。
2. 提供元信息用于解析:
-
- 指示使用了哪种序列化方式;
- 指明消息类型(请求/响应)、消息 ID、数据长度等。
3. 支持通信双方的协商与兼容性:
-
- 协议应提供字段使服务端知道如何还原数据(如使用了 JSON、Protobuf 等);
- 可以用于识别是否为新版本协议。
1.2. 设计RPC协议
基本结构:协议 = 协议头 + 协议体
|
部分 |
描述 |
|
协议头 |
固定长度或结构,存储:数据长度、序列化方式、消息类型等元信息 |
|
协议体 |
变长,存储:请求方法名、参数值、扩展字段等业务数据 |
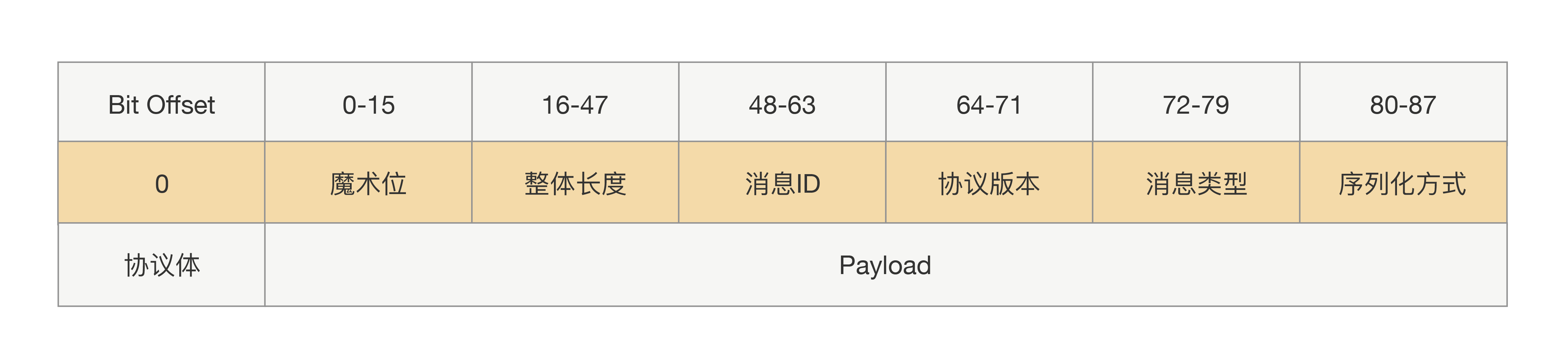
示例设计:
固定协议头结构示例(定长协议):
|
字段 |
说明 |
|
magic number |
协议标识,用于识别协议合法性 |
|
length(4字节) |
协议体数据长度 |
|
serialize_type |
序列化方式(JSON/Proto) |
|
message_type |
请求/响应 |
|
request_id |
请求唯一标识 |
|
... |
可加更多字段 |
协议体(不定长):
- 方法名(如
getUser) - 参数(如
userId=123) - 扩展属性(如 traceId)
1.3. 设计可扩展且向后兼容的协议
为何不能简单用定长协议?
- 扩展困难:协议头一旦定长,就无法再添加字段。
- 兼容性差:老版本无法识别新字段可能导致解码失败或语义错误。
可扩展协议设计策略:
1. 加入“协议头长度”字段:
-
- 在最前面预留固定长度字段表示整个协议头的长度;
- 支持协议头字段变更或扩展,不影响协议体读取。
2. 字段具备“自描述性”或键值对格式:
-
- 如:字段编码 + 字段长度 + 字段内容;
- 不依赖固定顺序,易于添加新字段、忽略未知字段。
3. 关键字段前置 + 可选字段后置:
-
- 让服务方先读取关键字段(如请求类型、超时时间)进行初步处理;
- 可选字段(如日志 traceId)可按需读取。
4. 协议体延后反序列化(按需解码):
-
- 如收到过期请求时,只读取超时时间字段直接返回,不反序列化参数,提高性能。
整体协议就变成了三部分内容:固定部分、协议头内容、协议体内容,前 两部分我们还是可以统称为“协议头”,具体协议如下:
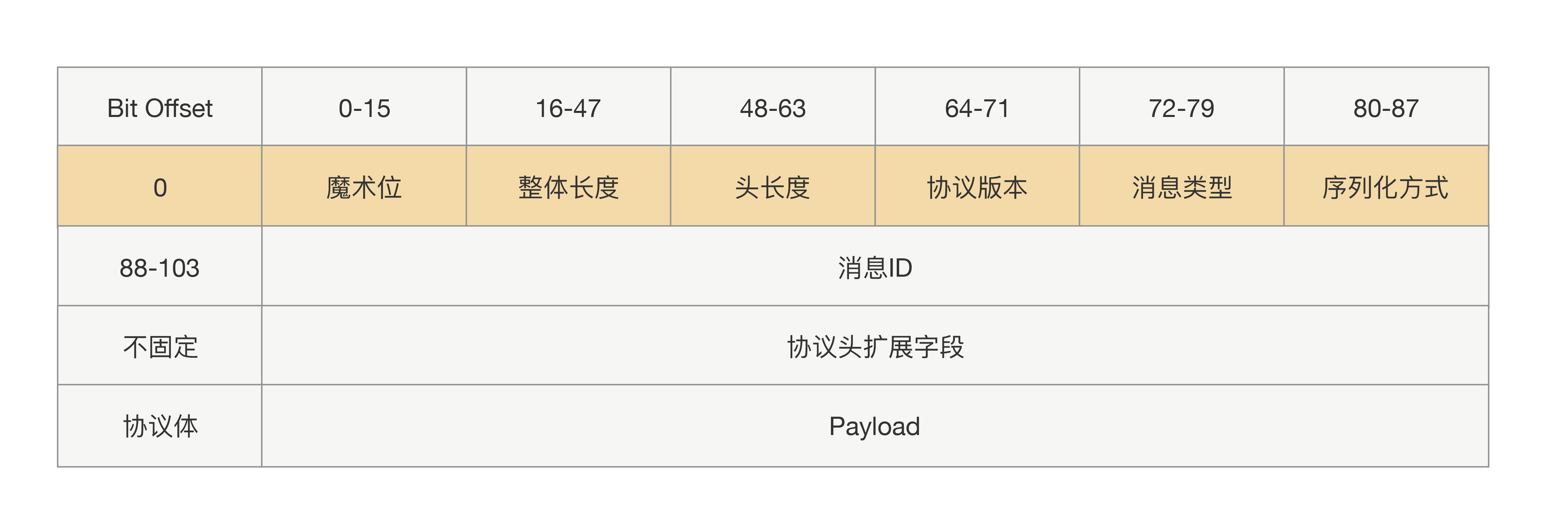
举例:
┌──────────────────────────────┐
│ 固定头部(Fixed) │ ← 例如:4 字节,表示协议头的长度(Header Length)
├──────────────────────────────┤
│ 可扩展协议头(Header) │ ← 可变字段:序列化方式、消息类型、超时时间、版本号、TraceID 等
│ ┌────────────────────────┐ │
│ │ [字段ID][长度][值] │ │
│ │ [字段ID][长度][值] │ │
│ │ ... │ │
│ └────────────────────────┘ │
├──────────────────────────────┤
│ 协议体(Body) │ ← 经过序列化的实际业务内容,如方法名 + 参数
│ ┌────────────────────────┐ │
│ │ { "method": "getUser", │ │
│ │ "param": { "id":1 } }│ │ ← JSON / Protobuf / 自定义格式
│ └────────────────────────┘ │
└──────────────────────────────┘
————————————————内容示例——————————————————
[Header Length] = 40
[Header] =
[FieldID=1][Len=1][Value=1] // 1:序列化方式 = JSON
[FieldID=2][Len=1][Value=0] // 2:消息类型 = 请求
[FieldID=3][Len=4][Value=1000] // 3:超时时间 = 1000ms
[FieldID=4][Len=8][Value=trace-1234] // 4:TraceID
[Body] = {"method": "getUser", "param": {"id":1}}
2. RPC序列化
2.1. 序列化的概念
序列化的定义:
序列化(Serialization) 是将对象(Object)转换为可传输的字节流或字符串的过程,以便在网络上传输或持久化存储。
反序列化(Deserialization) 则是将字节流或字符串还原为原始对象的过程。
- 序列化使得跨语言、跨平台通信成为可能。
- 是 RPC 调用过程中的必要环节 —— 请求和响应都需序列化。
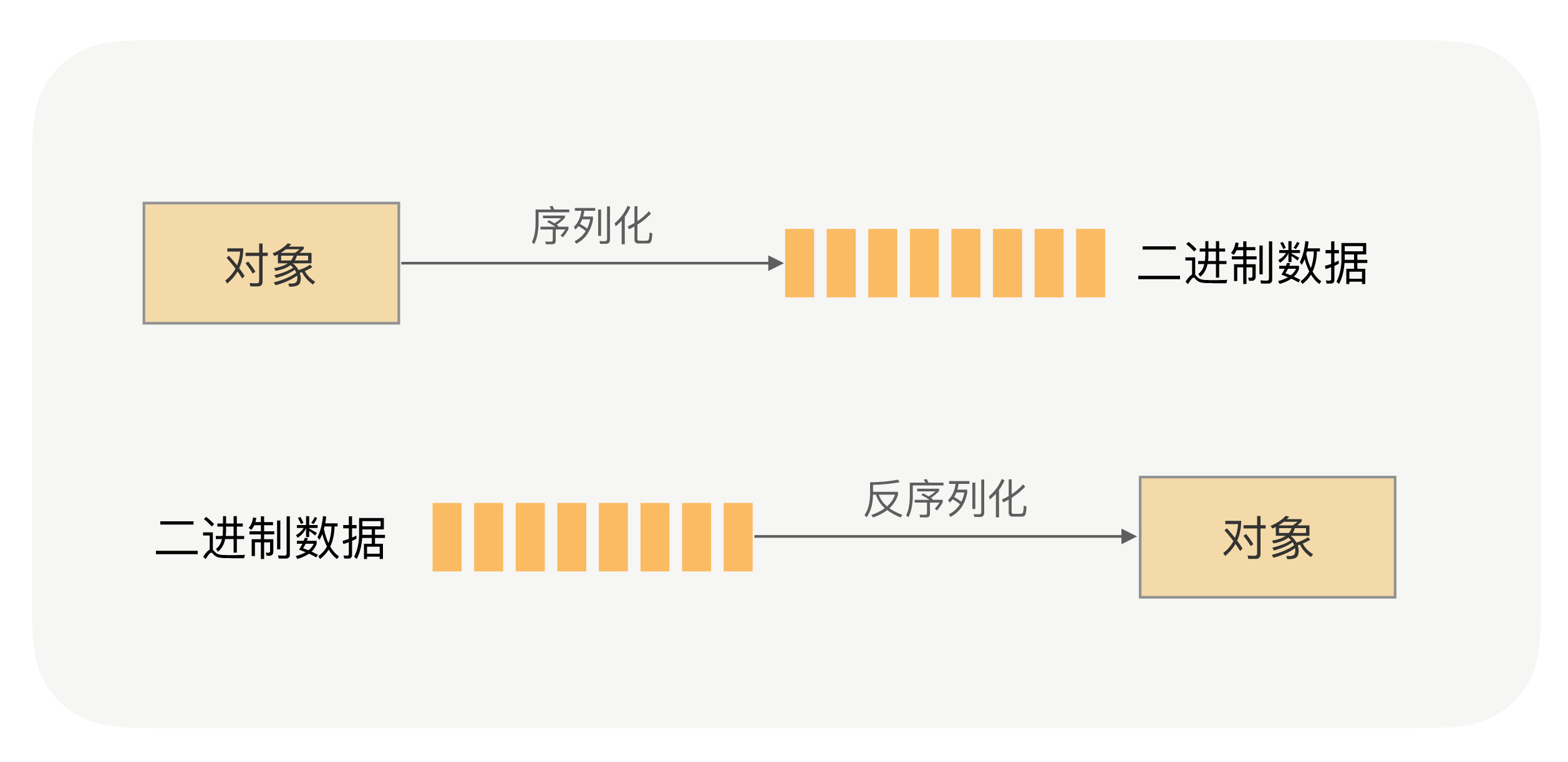
为什么 RPC 框架必须用序列化?
RPC 远程调用流程中,调用者和服务提供者运行在不同进程或主机中,二者通过网络交互请求和响应数据,对象需要转成可传输格式(序列化),再反序列化成本地对象。
示例流程:
- 客户端对象 → 序列化为字节流 → 通过网络传输
- 服务端收到字节流 → 反序列化为对象 → 调用方法 → 处理结果 → 序列化响应 → 返回 → 客户端反序列化
2.2. 常见序列化协议
|
序列化协议 |
数据体积 |
序列化速度 |
反序列化速度 |
可读性 |
跨语言支持 |
特点 |
|
JDK 原生 |
大 |
一般 |
一般 |
否 |
差 |
不需要引入依赖;Java专用 |
|
JSON |
大 |
快 |
快 |
是 |
好 |
人类可读性强,调试方便 |
|
Hessian2 |
中 |
快 |
快 |
否 |
一般 |
二进制协议,适合 RPC |
|
Protobuf |
小 |
非常快 |
非常快 |
否 |
非常好 |
需要定义 |
|
Kryo |
小 |
快 |
快 |
否 |
差 |
Java领域高性能方案,需注册类 |
性能总结:
- 最高性能:Protobuf > Hessian2 ≈ Kryo
- 调试友好:JSON
- 兼容性高:JSON、Protobuf
- 适用于 Java 项目快速开发:JDK、Kryo
2.3. RPC框架中序列化的选择
序列化协议选型依据:
|
选择维度 |
说明 |
|
性能需求 |
高并发场景倾向使用 Protobuf、Kryo |
|
跨语言支持 |
多语言通信首选 Protobuf 或 JSON |
|
调试与开发便利 |
JSON 可读性强、易于排查问题 |
|
协议复杂度 |
JDK 原生、JSON 实现简单;Protobuf/Hessian 需定义结构 |
|
安全性 |
避免使用存在反序列化漏洞的方案(如原生 JDK 序列化) |
|
版本兼容性 |
Protobuf/JSON 等支持字段可选、向后兼容处理 |
选择序列化协议的优先级:

虽然我们关心序列化的效率,但在 整个 RPC 调用链中,最耗时的往往是服务端的业务逻辑处理,因此序列化的性能并非唯一关键。稳定性优先 > 性能优化。
应用场景推荐:
|
场景 |
推荐协议 |
原因 |
|
内部 Java 服务通信 |
Kryo / Hessian2 |
高性能、不需跨语言 |
|
高性能微服务调用 |
Protobuf |
编解码效率高、结构清晰 |
|
Web/前后端通信 |
JSON |
易读、前端支持原生解析 |
|
快速本地原型开发 |
JDK 原生 |
免配置、上手快 |
RPC框架中,我们首选的还是 Hessian 与 Protobuf,因为他们在性能、时间开销、空间开销、通用性、 兼容性和安全性上,都满足了我们的要求。其中 Hessian 在使用上更加方便,在对象的兼 容性上更好;Protobuf 则更加高效,通用性上更有优势。
2.4. 使用RPC框架序列化时应注意的问题
1. 对象构造过于复杂
- 存在大量属性,并伴有多层对象嵌套或相互关联;
- 典型场景:A 对象持有 B,B 又聚合 C,C 又依赖多个对象;
- 影响:
-
- 性能开销大:序列化/反序列化需要遍历、复制大量结构;
- 易出错:嵌套层级深时,出错概率随之提升。
2. 对象体积过大
- 典型表现:一次 RPC 请求中传输一个 超大的 List 或 Map;
- 序列化后字节长度可达数 MB 或更高;
- 影响:
-
- CPU 与内存消耗剧增;
- 网络传输慢,极易导致超时;
- 整体 RPC 性能严重下降。
3. 使用序列化框架不支持的类
- 某些协议(如 Hessian)不支持某些类型:
-
- 如
LinkedHashMap、LinkedHashSet、Guava集合等;
- 如
- 建议使用原生且常见的集合类:
-
HashMap、ArrayList是首选。
4. 对象继承关系复杂
- 多层继承导致序列化框架遍历父类链,开销大,稳定性差;
- 越复杂的继承结构,越容易出问题;
- 建议使用扁平、无继承或组合优于继承的设计。
RPC 中入参和返回值的设计建议
|
编号 |
建议内容 |
|
1 |
对象尽量简单:属性不宜过多,避免依赖链复杂,高内聚低耦合 |
|
2 |
对象体积要小:避免大集合、大对象传输,控制数据字节大小 |
|
3 |
使用原生常用类:如 |
|
4 |
避免复杂继承结构:尽量使用 POJO,无继承或简单组合关系 |

















 579
579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









