 Self-RAG:用反思减少大模型幻觉
Self-RAG:用反思减少大模型幻觉




在大模型应用日益普及的今天,幻觉(Hallucination) 问题始终是阻碍其在关键场景落地的核心障碍。用户问一个问题,模型信口开河、编造事实,轻则误导决策,重则引发安全事故。
如何让大模型“言之有据”?自纠正 RAG(Self-RAG) 应运而生——它不是简单地检索+生成,而是引入了反思机制,让模型在生成答案后“自我审查”:我是不是胡说了?我有没有忠实引用上下文?
本文将深入剖析 Self-RAG 的核心思想、反思模块设计、实现路径与工程考量,帮助 AI 安全工程师与可信 AI 研究者构建更可靠、更可信的生成系统。
一、为什么需要 Self-RAG?
传统 RAG(Retrieval-Augmented Generation)通过检索外部知识库增强生成内容的准确性,但其流程是单向线性的:检索 → 生成。一旦检索结果不相关或模型忽略上下文,错误答案就会直接输出,毫无纠错能力。
而 Self-RAG 的核心突破在于:在生成后增加“反思”环节,形成“检索 → 生成 → 自我验证 →(必要时)重新检索/拒绝回答”的闭环。这种机制显著提升了生成内容的忠实度(Faithfulness),有效抑制幻觉。
二、Self-RAG 的核心思想:生成后的自我验证
Self-RAG 的关键在于一个朴素但强大的问题:“我是否引用了上下文?”
模型在生成答案后,会立即启动一个“Critic”模块,判断当前回答是否基于检索到的文档。如果判断为“否”或“不确定”,则触发“Reflector”模块,决定是重新检索、修正答案,还是直接拒绝回答(例如返回“无法从资料中确认”)。
这种设计模仿了人类的元认知(Metacognition) 能力——不仅思考问题,还思考“我的思考是否合理”。
三、反思模块设计:Critic 与 Reflector
Self-RAG 的反思机制由两个核心组件构成:
1. Critic(评判者)
Critic 的任务是评估生成答案是否忠实于检索结果。它不关心答案是否“正确”,而只关心是否“有据可依”。
实现方式主要有两种:
- 基于 LLM 的自评:通过精心设计的 Prompt,让同一个 LLM 判断答案与上下文的一致性。例如:
给定以下参考资料和回答,请判断该回答是否完全基于参考资料,未引入外部信息或主观臆断。仅回答“是”或“否”。
参考资料:[检索到的文本]
回答:[模型生成的答案]
- 训练专用二分类模型:使用标注数据(答案-上下文对是否忠实)训练一个轻量级分类器。该模型推理快、成本低,适合高并发场景。
2. Reflector(反思者)
当 Critic 判定答案不可信时,Reflector 负责决策下一步动作:
- 重新检索:调整查询关键词或扩大检索范围,获取更相关文档;
- 修正生成:基于原上下文重新生成更保守、更忠实的答案;
- 拒绝回答:若多次验证失败,则返回安全兜底语句,避免传播错误信息。
四、工程实现:如何落地 Self-RAG?
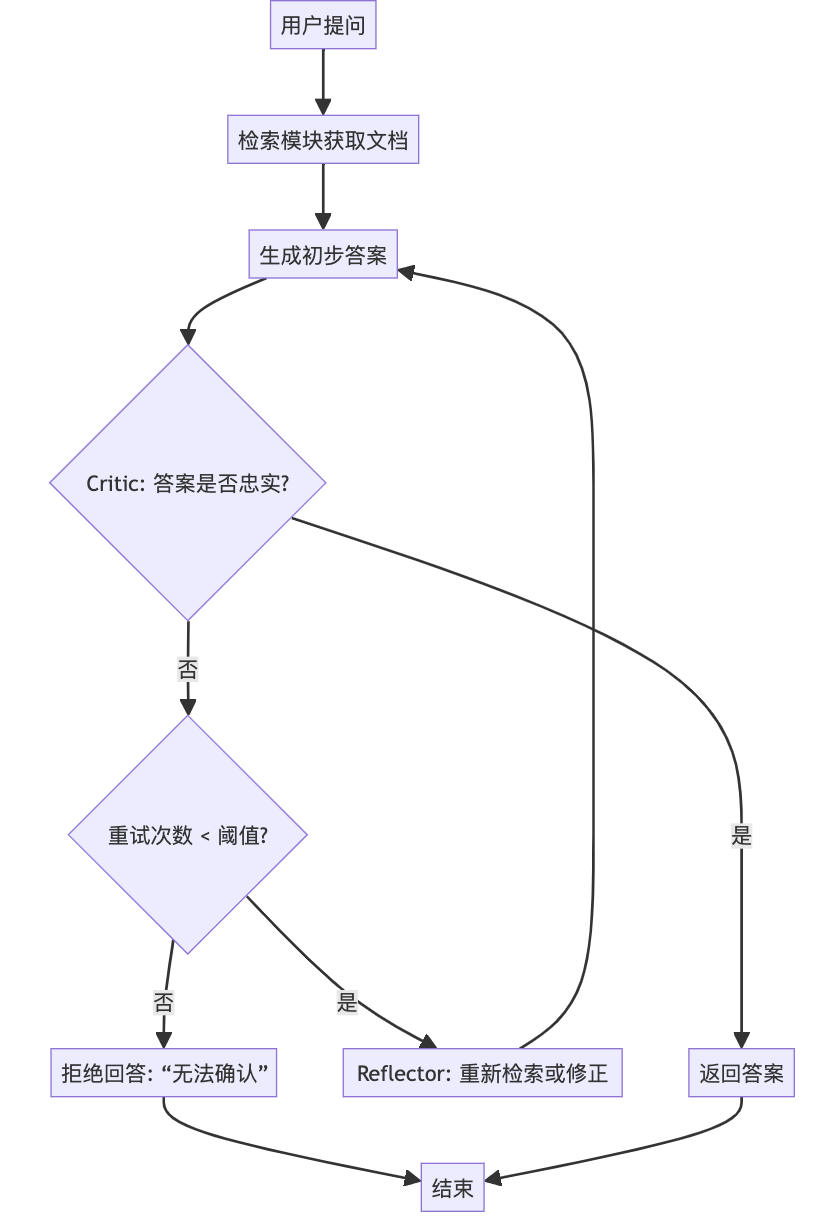
在实际系统中,Self-RAG 的控制流可表示如下:
用户提问 ↓检索模块(Retriever)获取 Top-K 文档 ↓生成模块(Generator)基于文档生成初步答案 ↓Critic 模块评估答案的忠实度 ↓是否通过验证? ——否——→ Reflector 决策(重检/修正/拒绝) ↓ 是返回最终答案
为更直观展示流程,下图描述了 Self-RAG 的完整控制逻辑:
五、关键技术挑战与应对策略
1. 反思开销控制
每次生成后都调用 LLM 做 Critic 会显著增加延迟与成本。解决方案包括:
- 混合策略:对高风险问题(如医疗、金融)启用 Self-RAG,低风险问题使用普通 RAG;
- 轻量 Critic 模型:训练小型分类器替代 LLM 自评,推理速度提升 5–10 倍;
- 缓存机制:对相同查询-上下文对缓存 Critic 结果,避免重复计算。
2. 避免无限循环
若 Reflector 不断触发重检但始终无法通过验证,系统可能陷入死循环。必须设置最大重试次数(如 2–3 次),超限后强制拒绝回答。
此外,可引入多样性检索策略(如语义+关键词混合检索),避免每次重检返回相同结果。
六、效果与优势:幻觉率显著下降
多项研究表明,Self-RAG 能将幻觉率降低 30%–60%,尤其在事实密集型任务(如问答、摘要、客服)中表现突出。
更重要的是,它提升了系统的可解释性与可控性:当答案被拒绝时,系统可记录“Critic 失败原因”,为后续优化提供数据闭环。
七、适用场景与读者价值
Self-RAG 特别适合以下场景:
- 企业知识库问答:确保员工获取的信息准确无误;
- 医疗/法律咨询辅助:避免模型编造法规或诊疗建议;
- AI Agent 决策链:在自主行动前验证信息可靠性;
- 可信 AI 系统构建:满足合规性与审计要求。
对于 AI 安全工程师,Self-RAG 提供了一种低成本、高效益的幻觉防御机制;对于 可信 AI 研究者,它展示了如何通过架构设计而非单纯依赖模型能力来提升系统鲁棒性。
八、结语:让大模型学会“三思而后言”
Self-RAG 的本质,是赋予大模型一种自我监督的能力。它不再是一个“有问必答”的黑盒,而是一个会“反思”、会“认错”、会“拒绝”的可信伙伴。
在追求更强生成能力的同时,我们更需要构建更负责任的 AI 系统。Self-RAG 正是这一理念的优秀实践——不是让模型更聪明,而是让它更诚实。
未来,随着 Critic 模型的精细化、Reflector 策略的智能化,Self-RAG 有望成为 RAG 系统的标准组件,为可信 AI 落地铺平道路。
技术永远服务于信任。而信任,始于对幻觉的零容忍。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









