



一、大模型涌现的“思维链”
🚀 最近,AI 大厂的开发大神们👨💻和高校的 NLP 研究人员🎓,都在热议如何让大模型实现“涌现”的魔法!✨
🔮 “涌现”是什么?简单来说,就是当大模型达到某个规模时,性能瞬间飙升,展现出让人眼前一亮的超凡能力💥,比如语言理解🗣、内容生成📝、逻辑推理🧠等。一般来说,这个“魔法点”大约在模型参数从 100亿(10B)🔢到 1000亿(100B)💎之间。
💸 但别误会,光砸钱💰和碰运气🎲,把模型做得超级大,并不能保证AI真的“显灵”哦!
🔍 强大的逻辑推理,就像大语言模型的“智能魔法棒”🧙,仿佛赋予了AI人的意识。而这一切的关键,就在于一个神奇的技术——思维链(Chain of Thought,CoT)🔄。
🚦 回顾一下那些类 GPT 应用的“翻车现场”😅,你会发现大多是数学算术题📚、逻辑思考题🧩等需要精确推理的问题。而思维链正是这些问题的“克星”!虽然现在很多企业和机构都在训练大语言模型🏢,但能真正掌握并应用思维链的却少之又少👀。
🔑 所以,解锁思维链技术,是大语言模型实现“涌现”的必经之路!只有这样,大模型才能在激烈的“大炼模型”竞赛中脱颖而出🏆,展现出真正的智慧🌟。
📝 接下来,本文将为你详细介绍 CoT 这一神奇技术,让我们一起探索如何让大模型拥有真正的智慧吧!🚀
二、思维链的开山之作
📚 《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》这篇论文,无疑是思维链(CoT)技术的奠基之作🏆。与之前的大语言模型相比,它带来了三大革命性的突破:
-
💡 常识推理能力超越人类:过去的语言模型在许多挑战性任务上都难以企及人类水平,然而,采用思维链提示的大语言模型在 Bench Hard (BBH) 评测基准的 23 个任务中,有 17 个任务的表现都超越了人类基线🚀。例如,在常识推理中,对身体和互动的理解尤为重要,而在运动理解方面,思维链的表现甚至超过了运动爱好者(95% vs 84%),这简直是不可思议的飞跃!🏆
-
🔢 数学逻辑推理能力大幅提升:语言模型在算术推理任务上一直是个难题,但思维链技术让大语言模型的逻辑推理能力有了质的飞跃。MultiArith 和 GSM8K 这两个数据集,正是测试语言模型解决数学问题的能力。应用了思维链提示后,PaLM 这个大语言模型在性能上比传统提示学习方法提高了惊人的 300%!在 MultiArith 和 GSM8K 上的表现不仅大幅提升,甚至超越了有监督学习的最优表现。这意味着,大语言模型现在也能轻松应对那些需要精确、分步骤计算的复杂数学问题了!🧮
-
🔍 大语言模型更具可解释性,更加可信:我们知道,超大规模的无监督深度学习模型往往像是一个“黑盒”,推理决策链难以捉摸,这使得模型结果的可信度大打折扣。然而,思维链技术通过将逻辑推理问题分解为多个步骤来逐步进行,生成的结果具有更加清晰的逻辑链路,提供了一定的可解释性,让我们能够了解答案是如何得出的。Jason Wei 提出的思维链技术,无疑是大语言模型迈向更广阔世界的必要条件。🔐
思维链效果如此显著,那么 Jason Wei 提出的 CoT 到底是一项什么样的技术呢?接下来,让我们一起深入探索其中的细节吧!🔍
三、Cot的技术细节
下面是论文展示的效果:
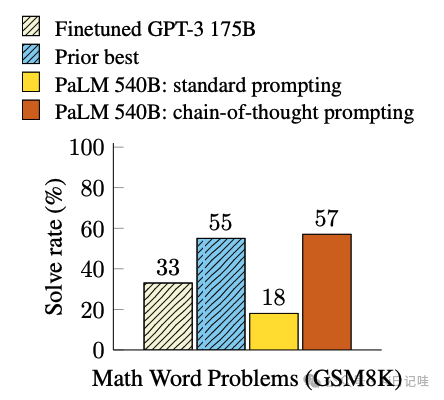
🔍 经过深入研究,不难发现,在解决数学问题的战场上,🚀 PaLM 这个拥有540B参数的超级LLM(大型语言模型)在CoT(Chain of Thought)的助力下,其表现竟达到了传统prompting方法的🚀300%以上,甚至超越了此前有监督学习的巅峰表现!💥
🤯 这听起来简直不可思议,但CoT方法其实相当直观且易于理解。🤔 CoT提示技术,是最近研发的一种高效策略,它鼓励大语言模型在回答时详细解释其推理过程。💡 思维链的核心理念是,通过展示少量的例子并附带详细的推理过程,让大语言模型在接收新的提示时,也能遵循这一模式,展示出清晰、准确的推理路径。🔄 这种推理的透明度不仅提升了模型的可靠性,更往往能引导出更为精准的结果。🎯
以一个数学题为例:
问:罗杰有5个网球。他又买了两盒网球,每盒有3个网球,他现在有多少个网球?
答:答案是11
问:食堂有23个苹果,如果他们用掉了20个后又买了6个,他们现在有多少个苹果?
答:答案是27(错误)
可以看到模型无法做出正确的回答。但如果说,我们给模型一些关于解题的思路,就像我们数学考试,都会把解题过程写出来再最终得出答案,不然无法得分。CoT 做的就是这件事,示例如下:
问:罗杰有5个网球。他又买了两盒网球,每盒有3个网球,他现在有多少个网球
答:罗杰一开始有5个网球,2盒3个网球,一共就是2*3=6个网球。5+6=11。答案是11。
问:食堂有23个苹果,如果他们用掉了20个后又买了6个,他们现在有多少个苹果?
答:食堂原来有23个苹果,他们用掉20个,所以还有23-20=3个。他们又买了6个,所以现在有6+3=9个。答案是9。(正确)
可以看到,类似的算术题,思维链提示会在给出答案之前,还会自动给出推理步骤:
“罗杰先有5个球,2盒3个网球等于6个,5 + 6 = 11”“食堂原来有23个苹果,用了20个,23-20=3;又买了6个苹果,3+6=9”
🚀 揭秘CoT的神奇之处!在实现中,CoT巧妙地修改了每个示例的target,而source则保持不变。原本的答案(a)已被替换为理由®加上答案(a),这样你在右侧看到的内容,完全由模型自动生成,不再是单一的答案(a),而是理由®与答案(a)的组合🔄。
💡 简单来说,语言模型在将复杂的语义直接转化为方程时面临挑战,因为这需要更为复杂的思考过程。但有了CoT,模型可以通过一系列中间步骤,逐步推理问题的每个部分,让答案更加准确🔍。
🧠 思维链提示(CoT)的魔力在于,它能够将一个复杂的多步骤推理问题,巧妙地分解成多个中间步骤。这不仅为模型分配了更多的计算量,生成了更多的token,还使得求解过程更加可解释和准确。通过将答案拼接在一起,模型能够更全面、更系统地解决问题💪。
📜 论文中作者还强调了CoT的诸多优势,其中最为突出的是它能够将多步推理问题分解出多个中间步骤,并使得LLM(大型语言模型)的输出更加可解释,这无疑为人工智能领域带来了新的启示和突破🚀。
四、Zero-Shot-Cot
🚀 零样本思维链(Zero Shot Chain of Thought,简称Zero-shot-CoT)🔍是对传统CoT prompting的进阶研究,它引入了一种革命性的零样本提示方式!💡
💡 神奇的是,只需在问题末尾轻轻加上“Let’s think step by step”这几个字,大语言模型便能像人类一样,逐步展开思考,生成一个完整的思维链来解答问题。🤖
🔍 从这个精心编织的思维链中,我们能够提取出更加精准、更加符合逻辑的答案,仿佛拥有了一位无所不能的“思维导师”!🌟
问:一个杂耍演员可以玩杂耍16个球。一半的球是高尔夫球,其中一半的高尔夫球是蓝色的。蓝色高尔夫球有多少个?让我们一步步思考(Let’s think step by step)
答:一共有16个球,一半的球是高尔夫球,这意味着8个高尔夫球。一半的高尔夫球是蓝色的,意味着有4个蓝色的高尔夫球。
🔄 实际上,Zero-shot-CoT 是一个完整的流程,或称为一个“pipeline”。简单来说,就是通过一个提示(prompt)——“Let’s think step by step”——让大型语言模型(LLM)尽量展现其思考过程。💭
接下来,模型会生成一系列的“rationale”(理由),这些理由是对问题的详细思考和分析。🔍
然后,这些生成的“rationale”和原始问题会被巧妙地拼接在一起,形成一个新的输入。🧩
最后,为了得到答案,我们会再配合一个指向答案的提示,如“The answer is ”,从而激励模型基于之前的思考和分析,生成最终的答案。🎯
从技术上讲,完整的零样本思维链(Zero-shot-CoT)过程涉及两个独立的提示/补全步骤,每一步都紧密相连,共同构成了这个高效的解决方案。🚀
作者还做了解释,说明这句“Let’s think step by step”是经过验证的,比如对比下面的其它的 instruction,尤其那些不相关的和误导的,效果就非常差,说明大模型真的是在理解这句 instruction 的意思。
五、自洽性Cot(Self-consistency)
🚀 这篇文章是CoT(Chain of Thought)方法问世后迅速跟进的重要工作,标志着CoT系列改进的一大步,于2022年3月在arxiv上发布。📅
🌟 该研究几乎沿用了CoT完全相同的数据集和设置,但主要改进在于引入了多数投票(majority vote)机制,这一创新显著提升了思维链方法的性能。📈
💡 文章提出的方法名为“自洽性”(Self-consistency),是对CoT的巧妙补充。它不仅仅生成一个思路链,而是生成多个思路链,并通过多数投票的方式,选取最受欢迎的答案作为最终答案。🗳️
👀 在下面的图中,左侧的提示采用了少样本思维链范例的编写方式。通过这一提示,模型能够独立生成多个思维链,并从每个思维链中提取答案。最终,通过“边缘化推理路径”的方式,计算并得出多数答案作为最终答案。📊
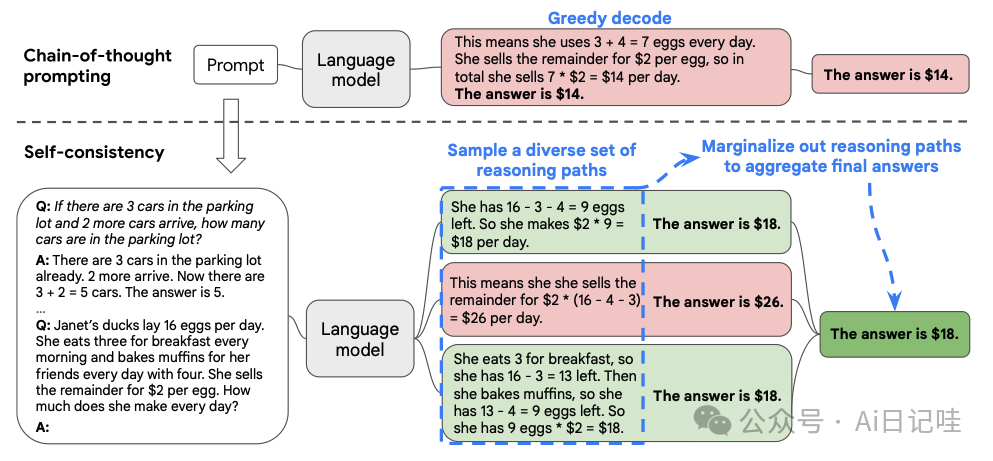
实验效果:

🔍 相较于单路径的CoT(Single-path in the figure),Self-Consistency 方法显著提升了效果!📈
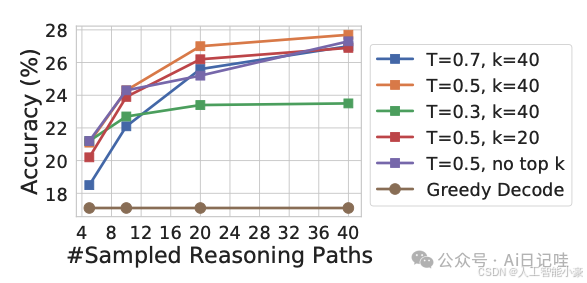
🌟 更为有趣的是,随着我们增加采样个数(即Sampled Reasoning Paths,与图3.1中的“采样不同的推理路径”相对应),效果也呈现出持续优化的趋势。🚀
🎛️ 在LaMDA-137B模型中,我们可以巧妙地利用热度(temperature)和Top-k参数来控制采样方法,以获得不同的效果。具体效果如何呢?让我们一起来看看下面的图吧!👀👇
六、Cot的局限性
🤔 前面聊了这么多,思维链真的能让大语言模型无敌了吗?它能否媲美人类的智慧呢?
😌 别急,思维链虽然强大,但仍有其局限,这也是大语言模型普遍面临的挑战。
🔍 首先,思维链需要在大规模模型中才能显现其潜力。就像Jason Wei等人的研究所示,当PaLM模型扩展到540B参数时,与思维链结合才展现出卓越性能。而对于小型模型,思维链的效果并不显著。谷歌大脑的研究人员认为,策略问题需要深厚的世界知识,而小型模型因参数不足难以记忆这些知识,所以难以产生准确的推理步骤。
📈 然而,实际产业中应用的模型规模往往受限。思维链虽然强大,但拆解更多步骤、消耗更多计算资源,使得很多研究机构和企业难以承担175B参数以上的大模型。因此,探索如何在较小模型中应用思维链,降低实际应用的成本,成为了一个重要课题。
🌐 其次,思维链的应用领域有限。目前,它主要在数学问题以及一些常识推理基准上表现出色。但在其他任务,如机器翻译上,其效果仍需进一步评估。而且,相关研究用到的模型或数据集往往半公开或不公开,使得其效果难以被复现和验证。因此,思维链的效果仍需进一步探索。
📚 此外,即使有思维链提示,大语言模型在数学问题上仍可能出现错误。例如,Jason Wei等人的论文中就展示了大语言模型在简单计算中的错误,如6 * 13 = 68(正确答案应为78)。这说明大语言模型虽然能通过思维链进行更精细的推理,但并未真正理解数学逻辑。对于有精确要求的任务,仍需探索新的技术。
💡 总结来说,思维链确实增强了大语言模型的能力,但逻辑推理仍是其弱项。我们期待未来有更多突破,让大语言模型更加智能和全面!
七、参考资料
-
https://www.zhihu.com/tardis/zm/art/629087587?source_id=1003
-
https://arxiv.org/pdf/2201.11903
-
https://arxiv.org/pdf/2203.11171
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 1098
1098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









