







 本文档详细介绍了如何利用NeuronBlocks构建一个用于中文文本蕴含任务的深度学习模型,包括BiGRU编码层、注意力交互层、融合层等组件,并提供了训练、测试和推理的步骤。此外,还分享了相关的人工智能在线教程和书籍资源。
本文档详细介绍了如何利用NeuronBlocks构建一个用于中文文本蕴含任务的深度学习模型,包括BiGRU编码层、注意力交互层、融合层等组件,并提供了训练、测试和推理的步骤。此外,还分享了相关的人工智能在线教程和书籍资源。
模型构建
模型整体架构
针对中文文本蕴含任务,本案例实现的是经典的循环神经网络+注意力方法模型,循环神经网络为BiGRU,注意力方法为BIDAF。模型主要包含以下几个模块:嵌入层、BiGRU编码层、注意力交互层、融合层、组合和输出层。接下来会进行详细讲解如何利用NeuronBlocks以Json文件的形式构建这些模块。模型结构如下图所示,p指的是前提(premise),h指的假设(hypothesis)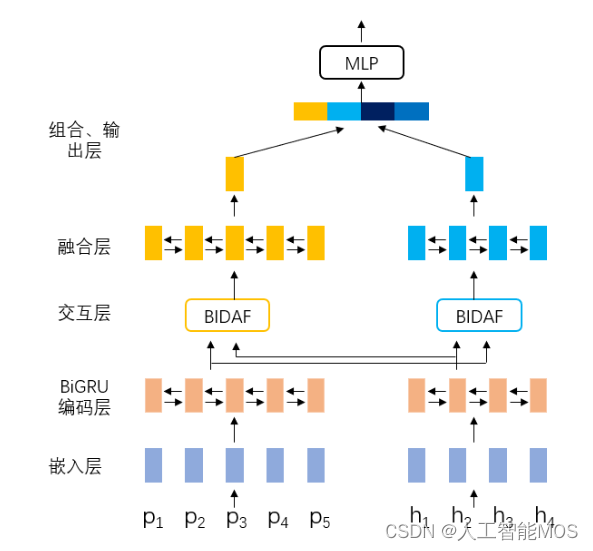
嵌入层
嵌入层主要是将文本分词后,利用词表查找功能转化为相应的词向量,为后续模型的输入做准备。该层中以Embedding定义,conf设置词向量参数,本案例中我们使用搜狗新闻预训练得到的词向量,所以dim应与保持预训练的维度保持一致设为300,cols输入文本分别为前提(premise)和假设(hypothesis)。
{
"layer": "Embedding",
"conf": {
"word": {
"cols": ["premise_text", "hypothesis_text"],
"dim": 300
}
}
}
BiGRU编码层
双向GRU对向量化后的premise和hypothesis进行编码,获得更高层的语义信息表示。
设置模型输入,例如premise_text经过向量化变为premise
"model_inputs": {
"premise": ["premise_text"],
"hypothesis": ["hypothesis_text"]
}
对premise和hypothesis进行dropout操作,可以设置dropout系数
{
"layer_id": "premise_dropout",
"layer": "Dropout",
"conf": {
"dropout": 0
},
"inputs": ["premise"]
},
{
"layer_id": "hypothesis_dropout",
"layer": "Dropout",
"conf": {
"dropout": 0
},
"inputs": ["hypothesis"]
},
利用BiGRU对dropout后的premise进行编码,此处可设置其隐藏层节点大小,层数,dropout系数等
{
"layer_id": "premise_bigru",
"layer": "BiGRU",
"conf": {
"hidden_dim": 128,
"dropout": 0.3,
"num_layers": 2
},
"inputs": ["premise_dropout"]
},
利用对premise编码的BiGRU对hypothesis再次编码,两者共享参数。
{
"layer_id": "hypothesis_bigru",
"layer": "premise_bigru",
"inputs": ["hypothesis_dropout"]
},
交互层
BiAttFlow注意力方法使premise和hypothesis进行交互,得到premise和hypothesis信息相互感知的上下文表征。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









