






group by:子句主要用于根据字段进行分组
having子句:选择行,与where子句类似,不同的是where子句用来在from子句之后选择行,而having子句用来在group by子句之后选择行。
我所用的数据库有三张表
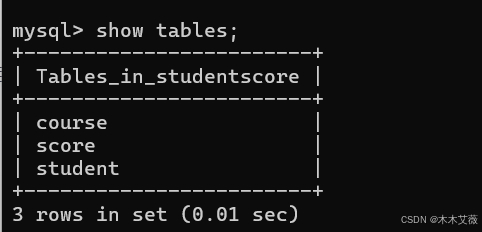
course表
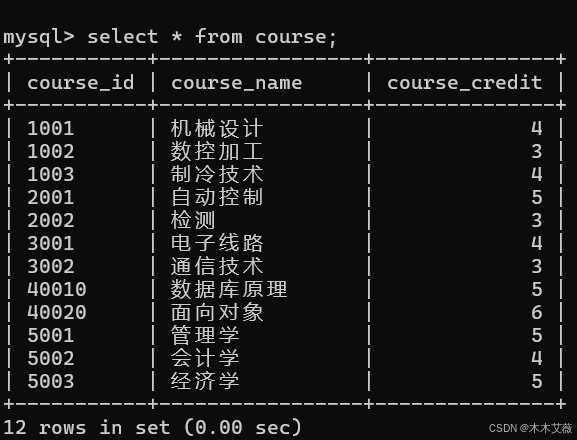
score表
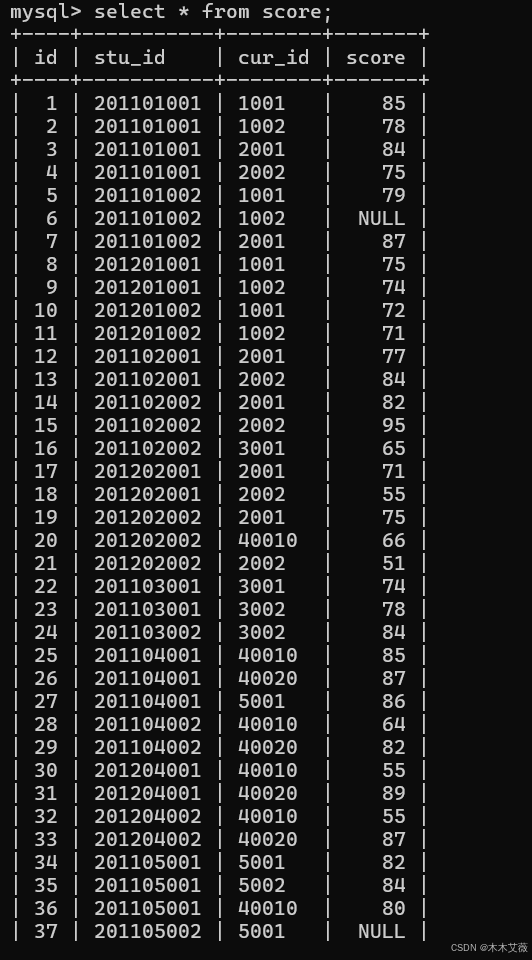
student表
 检索数据
检索数据
问题1.查询男,女生人数
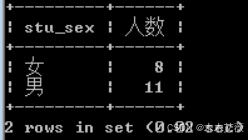
解:查询student表
语句: select distinct(stu_sex),count(stu_sex) as '人数' from student group by stu_sex;
 补充:distinct消除重复行,as 别名
补充:distinct消除重复行,as 别名
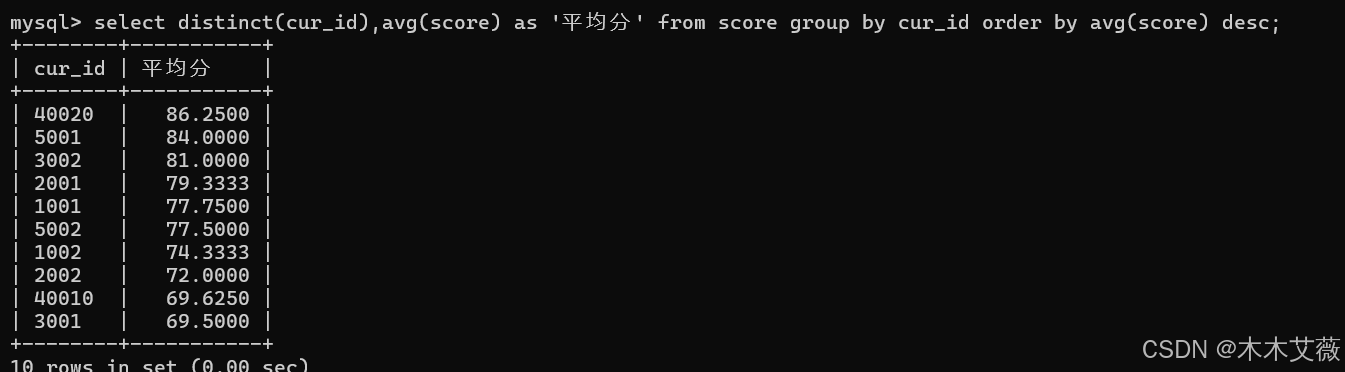
问题2:查询每门课程的平均分,并按照降序排列
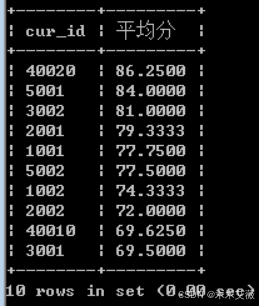
解:查询score表
语句:select distinct(cur_id),avg(score) as '平均分' from score group by cur_id order by avg(score) desc;
问题3:查询学生的出生年份,及该年份的学生数
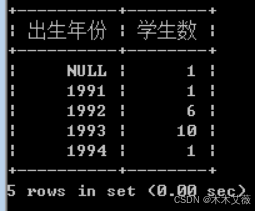
解:查询student表
语句:select year(stu_birthday) as '出生年份',count(*) as '学生人数' from student group by year(stu_birthday) order by year(stu_birthday);

问题4:查询选修课程门数超过3(含3)门的学生学号、平均分。
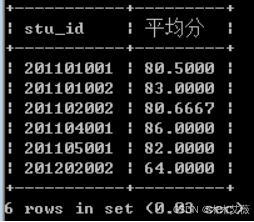
解:查询score表
语句:select distinct(stu_id),avg(score) from score group by cur_id having cur_id>=3 order by avg(score) desc;

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









