






基于 RAG 和 LangChain 的 PDF 问答系统——ChatPDF
概述
这篇文章用来介绍如何使用 RAG 技术与 LangChain 框架创建一个基于 PDF 文件的问答系统。本文所选的 PDF 文件是之前在阿里云百炼构建私有知识问答应用中所用的《中国肝病诊疗管理规范》。
注:运行程序需要科学地上网。
一、创建 Conda 环境与工程文件
1.1. 创建 Conda 环境
使用 Conda 的具体步骤在“Conda安装、环境创建及使用”有详细介绍,以下为简要概括:
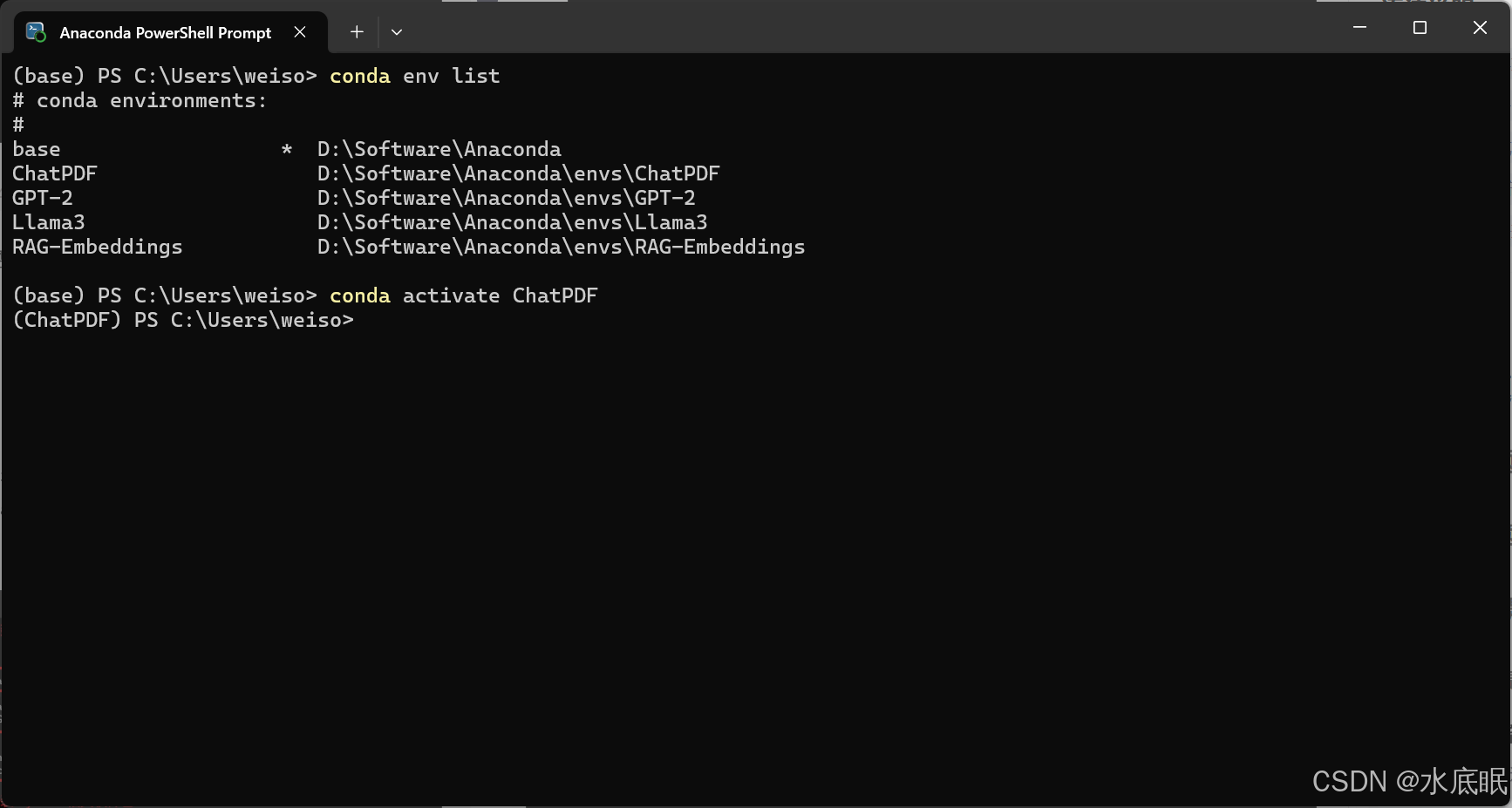
- 使用 Conda create --name ChatPDF python=3.10 创建一个名为 ChatPDF 的环境;

- 使用 conda env list 查看环境是否创建成功;使用 conda activate ChatPDF 激活该环境;
1.2. 安装软件包
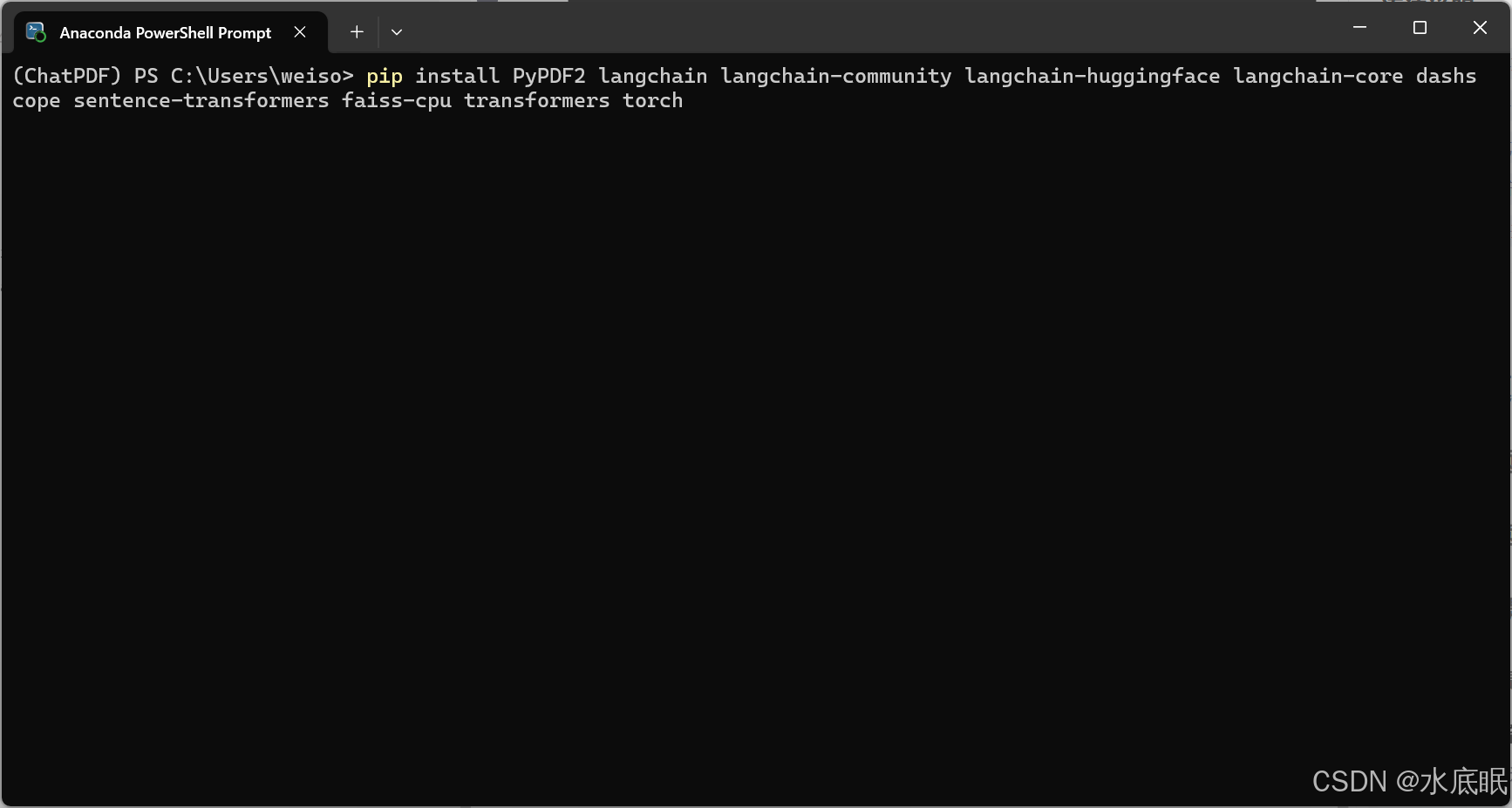
- 安装 Python 相关软件包:
pip install PyPDF2 langchain langchain-community langchain-huggingface langchain-core dashscope sentence-transformers faiss-cpu transformers torch
1.3. 创建 Python 工程文件
- 打开 PyCharm,然后根据下图所示方式创建工程;如果不知道如何创建,请见Conda安装、环境创建及使用一文;

二、编写 Python 程序
2.1. 配置文件
- 首先配置环境文件.env,获取千问的 DASHSCOPE_API_KEY 与 DASHSCOPE_BASE_URL,如下:

- 如果不了解获取方式可查看阿里云百炼构建私有知识问答应用(五、其他调用方法——API调用);
- 上图所示的 OpenAI_API_KEY 和 VOLCENGINE_API_KEY 分别是 OpenAI 和火山引擎的接口,不必管他;
- 在文件夹中保存需要对话的 PDF 文件,然后就可以编写程序了;

2.2. 编写程序
- 程序全部内容如下:
from PyPDF2 import PdfReader # 用来读取 PDF 文件的内容。
from langchain.text_splitter import RecursiveCharacterTextSplitter # 用于拆分出合适大小的文本块。
from langchain_community.vectorstores import FAISS # 用于存储和检索向量。
from langchain_huggingface import HuggingFaceEmbeddings # 用于获取文本的嵌入向量。
from langchain_core.documents import Document # 用于管理、操作和转换文档。
from dashscope import Generation # 用于文本生成。
# 定义 QwenPDFQA 类,用于后续 PDF 文件加载与问答等。
class QwenPDFQA:
def __init__(self, pdf_path):
# 1. PDF加载与处理
self.pdf_path = pdf_path # 加载 PDF 文件的路径。
try:
self.documents = self._load_pdf()
except Exception as e:
print(f"加载PDF文件时出错: {e}") # 捕获可能出现的异常。
self.documents = []
# 2. 文本分割
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每个分割后的文本块的最大字符数为 1000。
chunk_overlap=200 # 相邻文本块之间的重叠字符数为 200,避免在分割处丢失信息,确保文本的连贯性。
)
self.texts = self.text_splitter.split_documents(self.documents) # 对每个文档进行分割。
if not self.texts:
print("文本分割后没有得到有效的文本块,请检查PDF文件内容。")
return
# 3. 创建本地向量库
self.embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2" # 指定使用的模型名称。
)
self.db = FAISS.from_documents(self.texts, self.embeddings) # 文本向量化。
# 4. 初始化通义千问客户端
self.qianfan = Generation
# 读取指定路径的 PDF 文件,提取每一页的有效文本内容,并将其封装成 Document 对象。
def _load_pdf(self):
try:
with open(self.pdf_path, 'rb') as file:
reader = PdfReader(file) # 读取 PDF 文件的内容。
documents = []
for page in reader.pages: # 遍历 PDF 文件的每一页。
text = page.extract_text() # 从当前页面中提取文本内容
if text.strip(): # 检查该页面是否包含有效文本。
# 创建 Document 对象
doc = Document(page_content=text, metadata={"source": self.pdf_path})
documents.append(doc)
return documents
except FileNotFoundError:
print(f"文件 {self.pdf_path} 未找到。")
return []
except Exception as e:
print(f"读取PDF文件时出错: {e}")
return []
# 在本地向量库中进行向量相似度搜索,根据用户输入的问题查找最相关的文本块,并将文本块的内容拼接成字符串
def _retrieve_context(self, query, k=3):
# 向量检索相关文本块
try:
docs = self.db.similarity_search(query, k=k)
return "\n\n".join([doc.page_content for doc in docs])
except Exception as e:
print(f"向量检索时出错: {e}")
return ""
# 根据用户的查询进行问答,设置检索的上下文、问题,以及大模型限制生成文本的最大 token 数量,
def ask(self, query, max_tokens=2000):
# 检索上下文
context = self._retrieve_context(query)
# 构造通义千问的 prompt 模板
prompt = f"""
你是一个专业的文档助手,请基于以下上下文信息回答问题:
[上下文开始]
{context}
[上下文结束]
问题:{query}
请用中文给出详细回答,如果无法从上下文得到答案,请说明。
"""
# 调用通义千问 API
try:
response = self.qianfan.call(
model="qwen-max", # 指定要使用的大语言模型为 qwen-max。
prompt=prompt, # 将之前构建的提示词模板传入大模型。
max_tokens=max_tokens # 限制模型生成的文本最大 token 数量。
)
return {
"question": query, # 记录用户提出的原始问题。
"answer": response.output.text, # 从 API 返回结果中提取模型生成的答案文本。
"context": context # 记录之前检索到的与问题相关的上下文信息。
}
except Exception as e:
print(f"调用API时出错: {e}")
return {
"question": query,
"answer": "调用API时出错,请稍后再试。",
"context": context
}
# 启用 PDF 问答系统
if __name__ == "__main__":
# 初始化问答系统
qa_system = QwenPDFQA(r"C:\Users\weiso\Desktop\AI\ChatPDF\1.pdf")
if hasattr(qa_system, 'db'):
# 提问
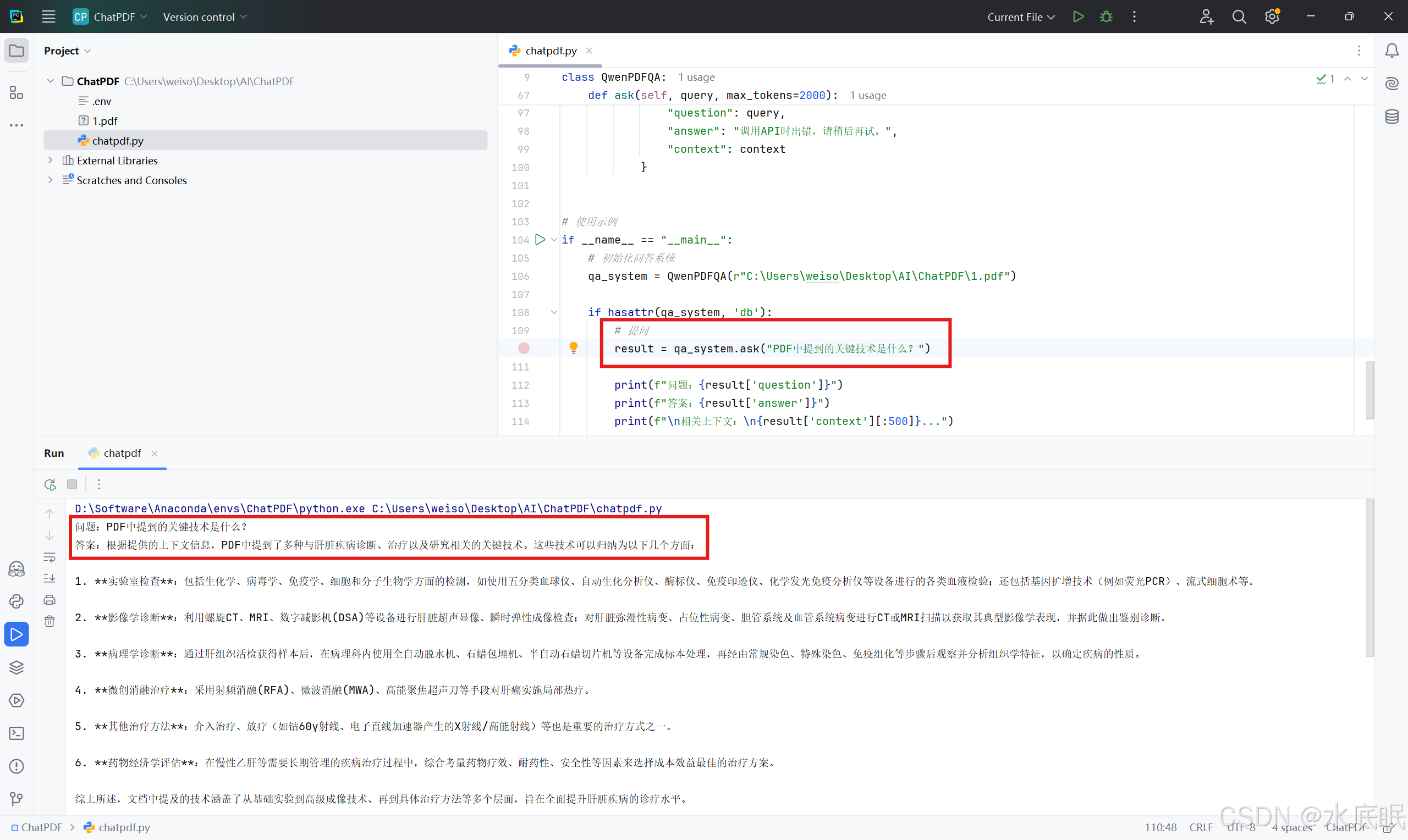
result = qa_system.ask("PDF中提到的关键技术是什么?")
print(f"问题:{result['question']}")
print(f"答案:{result['answer']}")
print(f"\n相关上下文:\n{result['context'][:500]}...")
- 向程序提问:PDF中提到的关键技术是什么? 程序有如下图所示回复:
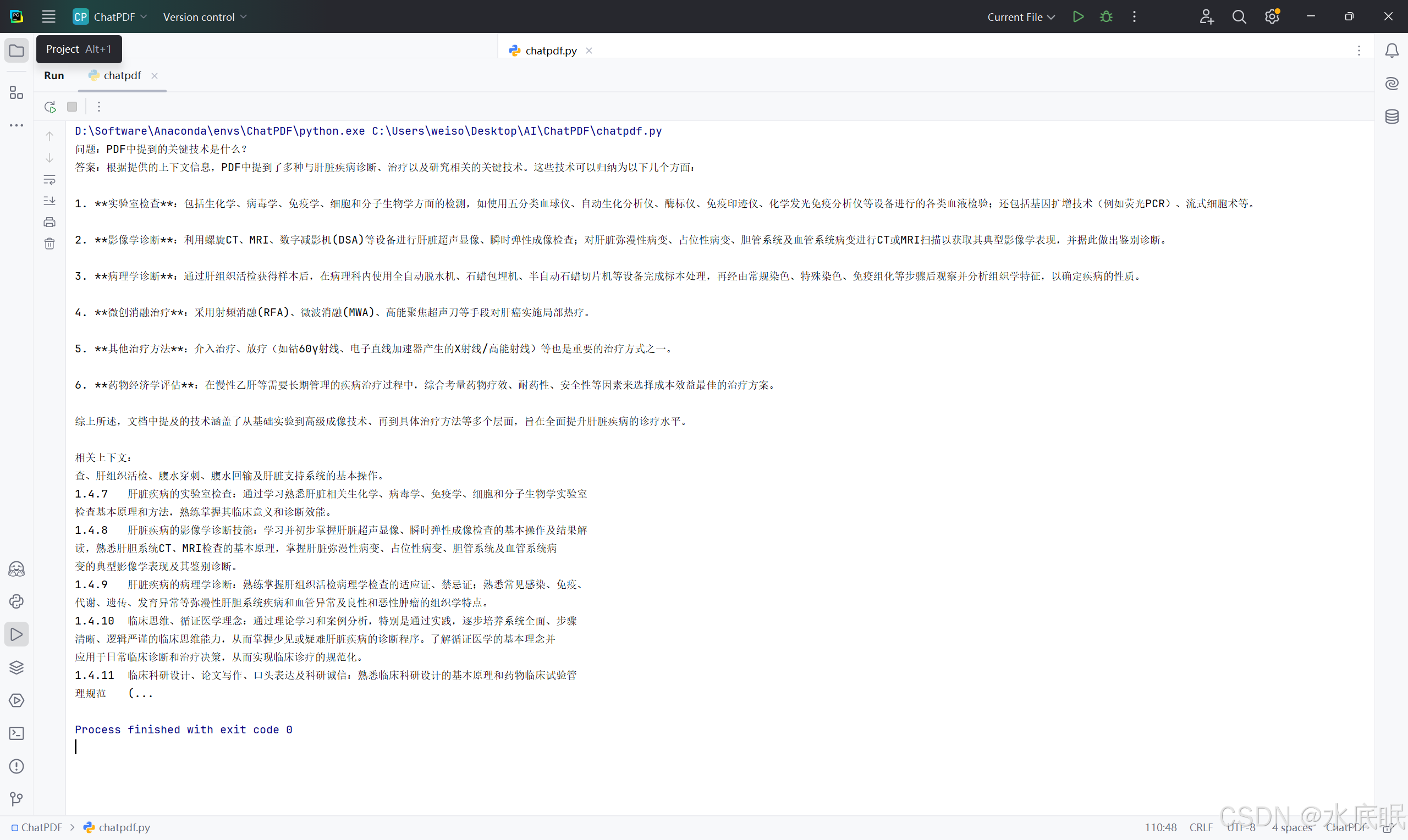
- 换个问题:实验室检查技术有什么? 程序有如下图所示回复:

三、库说明
from PyPDF2 import PdfReader # 用来读取 PDF 文件的内容。
from langchain.text_splitter import RecursiveCharacterTextSplitter # 用于拆分出合适大小的文本块。
from langchain_community.vectorstores import FAISS # 用于存储和检索向量。
from langchain_huggingface import HuggingFaceEmbeddings # 用于获取文本的嵌入向量。
from langchain_core.documents import Document # 用于管理、操作和转换文档。
from dashscope import Generation # 用于文本生成。
- PyPDF2:一个用于处理 PDF 文件的 Python 库。PdfReader 类可以用来读取 PDF 文件的内容。
- langchain:一个用于开发基于大语言模型(LLM)应用的框架。
- text_splitter:用于将长文本拆分成较小文本块的工具。
- RecursiveCharacterTextSplitter:作为文本拆分方法的具体实现,会按指定字符递归拆分文本,优先按较长分隔符拆分,拆分出合适大小的文本块,便于后续处理。
- langchain_community: LangChain 社区贡献代码的集合。社区开发者在其中提供了各种工具、组件和扩展功能,以此来增强 LangChain 框架的能力和可扩展性。
- vectorstores:langchain_community 中的一个模块,集成了多种不同类型的向量数据库,如 FAISS、Pinecone、Chroma 等。
- FAISS:是一个高效的向量数据库,用于存储和检索向量。
- langchain_huggingface:LangChain 框架中与 Hugging Face 集成的组件,为使用 Hugging Face 的模型和工具提供了方便的接口。
- HuggingFaceEmbeddings:用于从 Hugging Face 模型中获取文本的嵌入向量。它还能结合其他 LangChain 组件,实现文档向量化存储、检索等功能。
- langchain_core : LangChain 框架中的核心基础库,它定义了 LangChain 整个生态系统中通用的基础概念、接口和数据结构。
- document:负责处理文档相关的功能和数据结构,提供了一系列工具和类,用于管理、操作和转换文档,比如文本分割、嵌入向量生成、存储到向量数据库等。
- dashscope:阿里云提供的一个 AI 开发平台。
- Generation:可以用于调用平台上的大语言模型进行文本生成。

















 1200
1200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









