







一.前言
HashMap和Hashtable是Java学习以及数据结构学习中十分重要的一部分,虽然如今Hashtable的应用广泛性不及HashMap,但HashMap和Hashtable的区别与联系是很多大厂面试中经常考察的问题。下面,我们就基于源码详细聊一聊两者的联系和区别。
二.HashMap和Hashtable的联系
- HashMap和Hashtable都实现了Map、Cloneable(可克隆化)、Serializable(可序列化)三个接口
- HashMap和Hashtable存储的都是键值对
- HashMap和Hashtable中元素的key都不能重复,若要添加元素的key重复,则新添加的value会将原来的value覆盖
- HashMap和Hashtable都实现了增删改查等方法
- HashMap和Hashtable都属于散列表结构
三.HashMap和Hashtable的区别
- HashMap和Hashtable产生时间不同
Hashtable产生时间早于HashMap,Hashtable产生于JDK1.0,而HashMap产生于JDK1.2 - HashMap和Hashtable的父类不相同
虽然我们上面提到了Hashtable和HashMap都实现了相同的三个接口,但两者的继承父类并不同,Hashtable的继承父类是Dictionary(已经被废弃的类),而HashMap的继承父类是AbstractMap - HashMap和Hashtable的底层不同
在JDK1.8及其之后,HashMap底层是数组+链表+红黑树(哈希表+红黑树),而Hashtable底层是数组+链表(哈希表)
补充:
HashMap链表转红黑树的条件:
当数组长度大于等于64(MIN_TREEIFY_CAPACITY)同时链表长度超过8(TREEIFY_THRESHOLD)时,通过底层调用treeifyBin()函数和treeify()函数将链表转化为红黑树。
HashMap链表转红黑树的原因:
遍历链表,时间复杂度为O(n),由于红黑树为自平衡树,即通过红黑树查询某个元素的时间复杂度为O(log(n))。若链表元素个数不是很多,O(n)和O(log(n))的差距不是很明显,但随着链表元素的增加,O(log(n))的时间复杂度明显优于O(n),所以此时会将链表转化为红黑树。
- HashMap和Hashtable的初始容量不同
HashMap在第一次添加元素时开辟table数组空间,无参构造初始容量为16,有参构造初始容量为大于等于给定容量的最小的2的幂次;而Hashtable在构造方法中开辟table数组空间,无参构造初始容量为11,有参构造初始容量可以为在int范围内的任何正整数
无参构造HashMap,table数组为空,默认加载因子(loadFactor)为0.75,而在第一次使用put()方法添加元素时,才会开辟数组空间,初始容量为16
putVal()方法:
resize()方法:



无参构造Hashtable,在构造方法中table数组已经开辟数组空间,且默认table初始容量为11,加载因子(loadFactor)为0.75


有参构造HashMap:在输入参数合法的情况下(否则抛出异常),table数组为空,加载因子(loadFactor)为第二个参数(可不写,默认为0.75),在第一次使用put()方法添加元素时,才创建table数组,初始容量为大于等于第一个参数initialCapacity的最小的2的幂次
说初始容量为大于等于第一个参数initialCapacity的最小的2的幂次而不是参数initialCapacity本身大小的原因:tableSizeFor()方法
resize()方法(putval()方法调用):



有参构造Hashtable:构造方法中table数组已经创建,在输入参数合法的情况下(否则抛出异常),table数组初始容量为第一个参数initialCapacity,加载因子(loadFactor)为第二个参数(可不写,默认为0.75)

- HashMap和Hashtable的扩容方式不同
当数组容量达到阈值时,HashMap扩容为原数组长度的2倍(这里暂时不考虑红黑树的情况),Hashtable扩容为原数组的2倍+1补充:对loadFactor(加载因子)的解释:
加载因子的作用是用来计算阈值 th=table数组容量*加载因子,当数组容量达到阈值后,数组开始扩容。根据泊松分布算法,当加载因子为0.75时,一方面可以减少哈希冲突,另一方面也避免了不必要的内存浪费。
HashMap:



Hashtable:


5. 对null值的插入
HashMap中存放key和value都可以为null,而Hashtable存放key和value都不能为空(会抛出NullPointerException异常)
对于Hashtable中value不能为null的原因基于Hashtable源码

对于Hashtable中key不能为null的原因:由于空指针不能调用任何方法,而当Hashtable计算hash值时直接调用key.hashCode()方法,若key为null则会抛出空指针异常,而HashMap在计算hash值时会判断key是否为0,因此HashMap中key可以存放null值
HashMap:

Hashtable:

-
在高并发下线程安全性不同
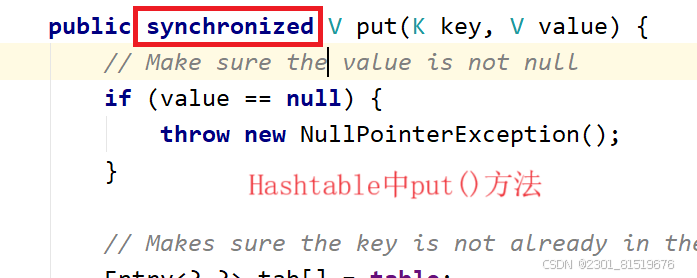
HashMap在高并发下线程不安全,而Hashtable在高并发下线程安全
原因:HashMap中方法未被synchronized修饰,Hashtable中方法被synchronized修饰

-
hash值的计算方式不同
HashMap中hash值计算方式:(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16)
key的hashCoad值高16异或低16位
Hashtable中hash值计算方式:key.hashCode()
key的hashCoad值 -
新添加元素插入数组位置的计算方式不同
HashMap中index计算方式:(n - 1) & hash
table数组长度-1单位与hash值
Hashtable中index计算方式:(hash & 0x7FFFFFFF) % tab.length
hash值单位与int最大值,再对table数组长度取余 -
插入元素的方式不同
HashMap插入元素采用的是尾插法,而Hashtable插入元素采用的是头插法
HashMap:

Hashtable:

四.总结
HashMap和Hashtable之间的联系和区别是很多大厂面试经常考察的问题,以上只是小编自己总结的一些内容,如有什么错误或遗漏,欢迎大家及时指出和补充。最后,用一句名言当作文章的结尾,送给大家!
学习知识要善于思考,思考,再思。我就是靠这个方法成为科学家的。——爱因斯坦

















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









