






课程:大厂必备数据结构与算法Java视频教程(上篇),java高级程序员必学的数据结构与算法_哔哩哔哩_bilibili
时长:上篇40h + 下篇38h
二分查找
前提:一个有序数组,升序或者降序。
基础版代码:
public static int binarySearch(int[] a, int target) {
int i = 0, j = a.length - 1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target < a[m]) { // 在左边
j = m - 1;
} else if (a[m] < target) { // 在右边
i = m + 1;
} else {
return m;
}
}
return -1;
}问题1:为什么是 i <= j 意味着区间内有未比较的元素,而不是 i < j ?
【注意:代码中j = a.length - 1】
答:i、j 它们指向的元素也会参与比较。
问题2:代码中 int m = (i + j) >>> 1 可不可以用 int m = (i + j) / 2 代替?
答:不可以。因为当m足够大的时候,会超过正整数的范围。java中把二进制数的最高位看作符号位。用无符号右移运算符解决这个问题。【结论:无符号位的二进制数右移一位,都可以看作除以2取整】
问题3:为什么代码中都用的是小于号(而不是大于号),它的好处是什么?
答:因为我们准备的数组是升序排列的,写成大于号会别扭。
改动版代码:
public static int binarySearch(int[] a, int target) {
int i = 0, j = a.length; //第1处改动
while (i < j) { //第2处改动
int m = (i + j) >>> 1;
if (target < a[m]) { // 在左边
j = m; //第3处改动
} else if (a[m] < target) { // 在右边
i = m + 1;
} else {
return m;
}
}
return -1;
}在改动版代码中:
- j 只作为边界,它指向的元素一定不是查找目标,一定不会参与比较,因此第3处改动中是 j = m, 而不是 j = m-1;
- while循环条件为什么改为了 i < j ,而不是 i <= j ?因为如果寻找的元素在数组中不存在时,会进入死循环。启发总结:由此可见,为了更好地掌握一种算法,就必须对算法中每个变量、指针背后的含义有更好的理解,否则只能死记硬背了。
- i、j 指针的含义?在基础版的二分查找中,它们不光是代表搜索的边界,而且i、j 指向的元素也有可能参与比较运算,因此,我们把这种边界称为左闭右闭的边界。在改动版中,i含义不变,j的含义变了,它指向的边界我们并不希望参与比较运算,它的边界是左闭右开的边界。
线性查找法与二分查找法对比:
二分查找法更优。详见截图笔记图4。
如何衡量一个算法的好坏?
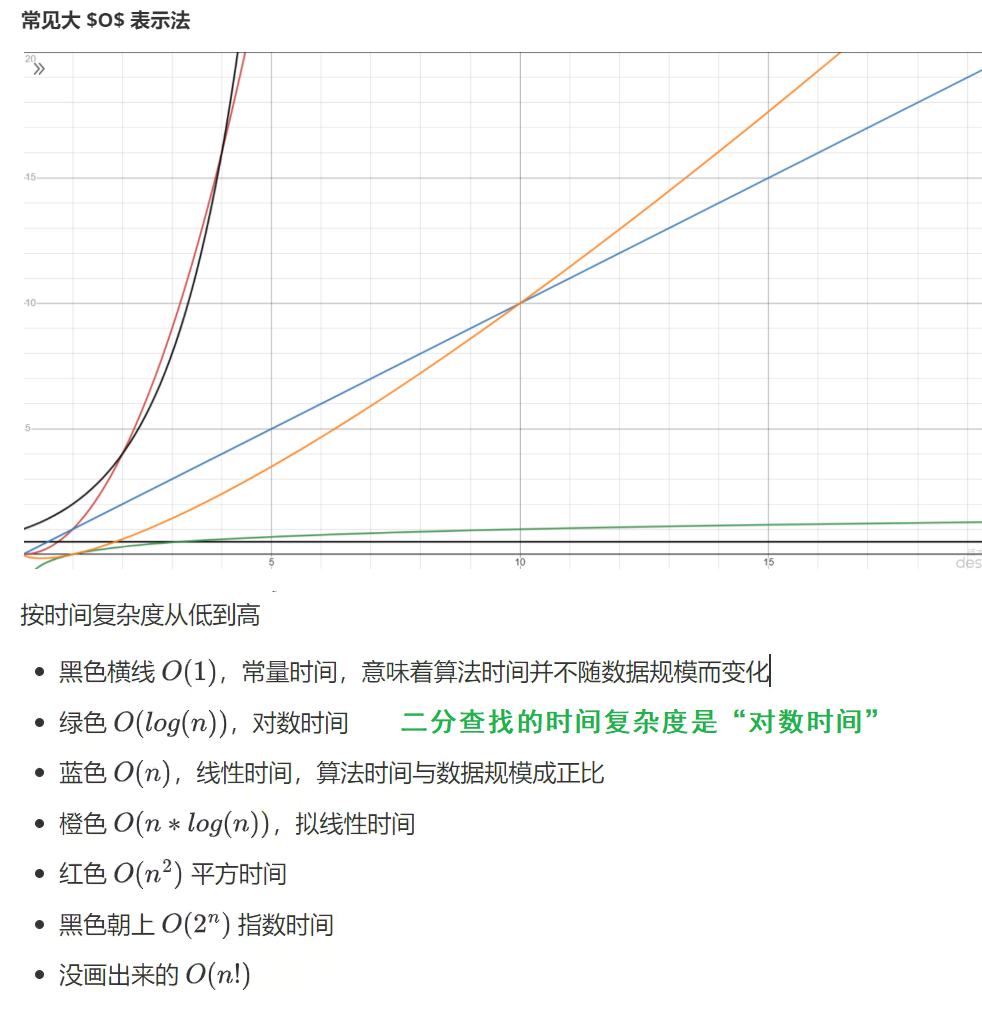
- 时间复杂度,常用大O表示法。
- 空间复杂度,一般也用大O表示法来衡量:一个算法执行随数据规模增大,而增长的额外空间成本。
public static int binarySearchBasic(int[] a, int target) { int i = 0, j = a.length - 1; // 设置指针和初值 while (i <= j) { // i~j 范围内有东西 int m = (i + j) >>> 1; if(target < a[m]) { // 目标在左边 j = m - 1; } else if (a[m] < target) { // 目标在右边 i = m + 1; } else { // 找到了 return m; } } return -1; }以上面二分查找法为例来说明空间复杂度:变量a和target都是原始数据,除了它们两个之外还有哪些空间占用?i、j、m三个指针各占用4个字节,共占用12个字节,不会随着数据量的变化而变化,占用的仅仅是常量的空间,故二分查找算法的空间复杂度为 O(1) 。
二分查找算法性能:

二分查找平衡版代码:
public static int binarySearchBalance(int[] a, int target) { int i = 0, j = a.length; while (1 < j - i) { int m = (i + j) >>> 1; if (target < a[m]) { j = m; } else { i = m; } } return (a[i] == target) ? i : -1; }
说明:平衡版代码时间复杂度的最好情况、最坏情况都可以用同一个函数 O(log(n)) 表示,于是就可以用另外一种表示了,即:Theta(log(n))

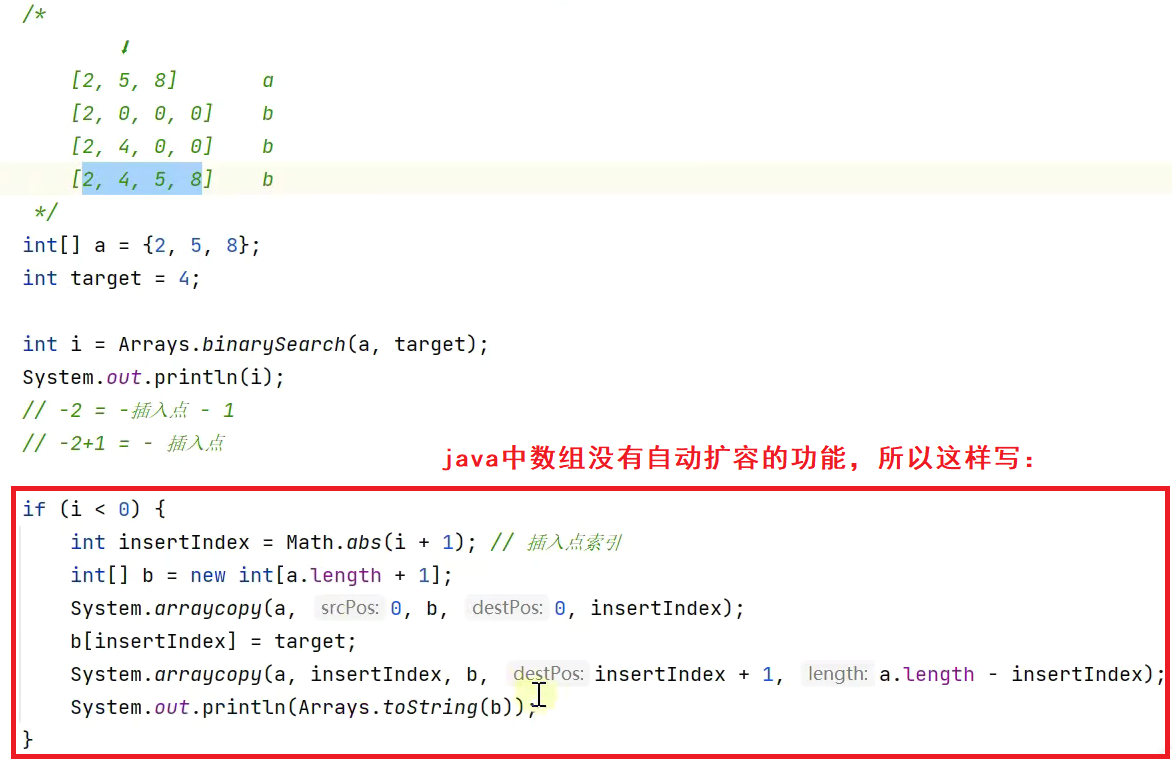
java中的二分查找在Arrays类中,代码如下:
private static int binarySearch0(int[] a, int fromIndex, int toIndex,
int key) {
int low = fromIndex;
int high = toIndex - 1;
while (low <= high) {
int mid = (low + high) >>> 1;
int midVal = a[mid];
if (midVal < key)
low = mid + 1;
else if (midVal > key)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); //表示不存在时,返回插入的索引位置减去1;为什么要减去1?因为java中0和-0是区分不开的
}
Leftmost 与 Rightmost
Leftmost:当数组中有重复元素时,返回最左侧元素的索引;
Rightmost:当数组中有重复元素时,返回最右侧元素的索引;
代码如下:
public static int binarySearchLeftmost1(int[] a, int target) {
int i = 0, j = a.length - 1;
int candidate = -1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m - 1;
} else if (a[m] < target) {
i = m + 1;
} else {
candidate = m; // 记录候选位置
j = m - 1; // 继续向左
}
}
return candidate;
}public static int binarySearchRightmost(int[] a, int target) {
int i = 0, j = a.length - 1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m - 1;
} else {
i = m + 1;
}
}
return i - 1;
}对于 Leftmost 与 Rightmost,可以返回一个比 -1 更有用的值,代码详见讲义。应用:排名、前任、后任、最近邻居、范围查找,详见讲义。
力扣三道练习题目:(题目及答案详见讲义)
- 二分查找-Leetcode 704
- 搜索插入位置-Leetcode 35
- 搜索开始结束位置-Leetcode 34
数据结构
依次学习的数据结构:数组、链表、
数组
定义、性能、随机访问:详见截图笔记图7。
java自带的数组长度是固定的,不能插入、删除元素,是静态数组。
java中实现好的动态数组是ArrayList。我们现在学的是数据结构的课程,所以我们自己去实现一个动态数组。
二维数组:
int rows = 1000000;
int columns = 14;
int[][] a = new int[rows][columns];先遍历行的效率高于先遍历列的效率,因为:
-
缓存是有限的,当新数据来了后,一些旧的缓存行数据就会被覆盖
-
如果不能充分利用缓存的数据,就会造成效率低下
链表
在计算机科学中,链表是数据元素的线性集合,其每个元素都指向下一个元素,元素存储上并不连续
In computer science, a linked list is a linear collection of data elements whose order is not given by their physical placement in memory. Instead, each element points to the next.
分类:单向链表、双向链表、循环链表
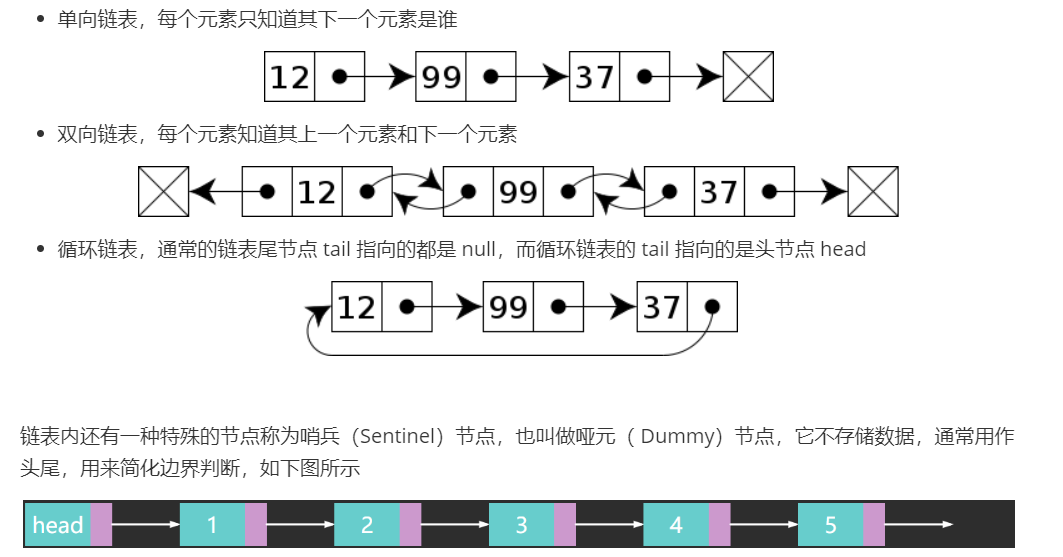
性能:
随机访问性能
根据 index 查找,时间复杂度 O(n)
插入或删除性能
起始位置:O(1)
结束位置:如果已知 tail 尾节点是 O(1),不知道 tail 尾节点是 O(n)
中间位置:根据 index 查找时间 + O(1)
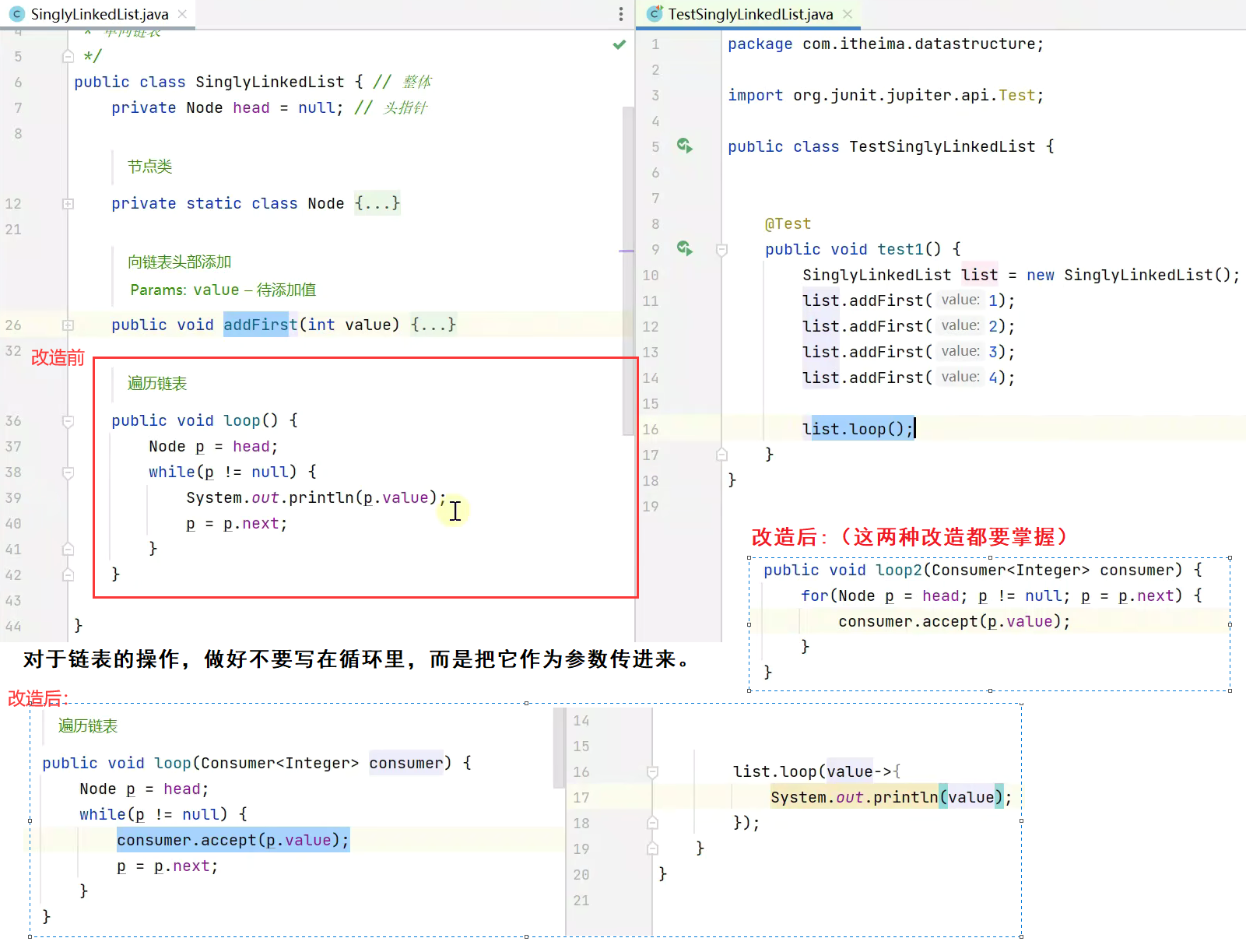
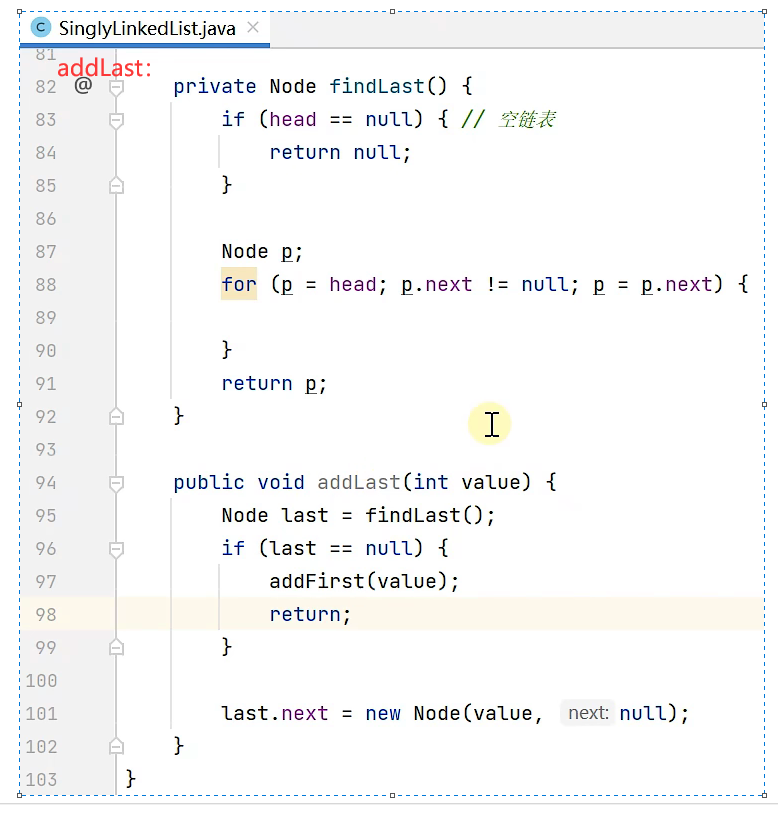
单向链表
addFirst、遍历、addLast、get、insert、remove、removeFirst、带哨兵。
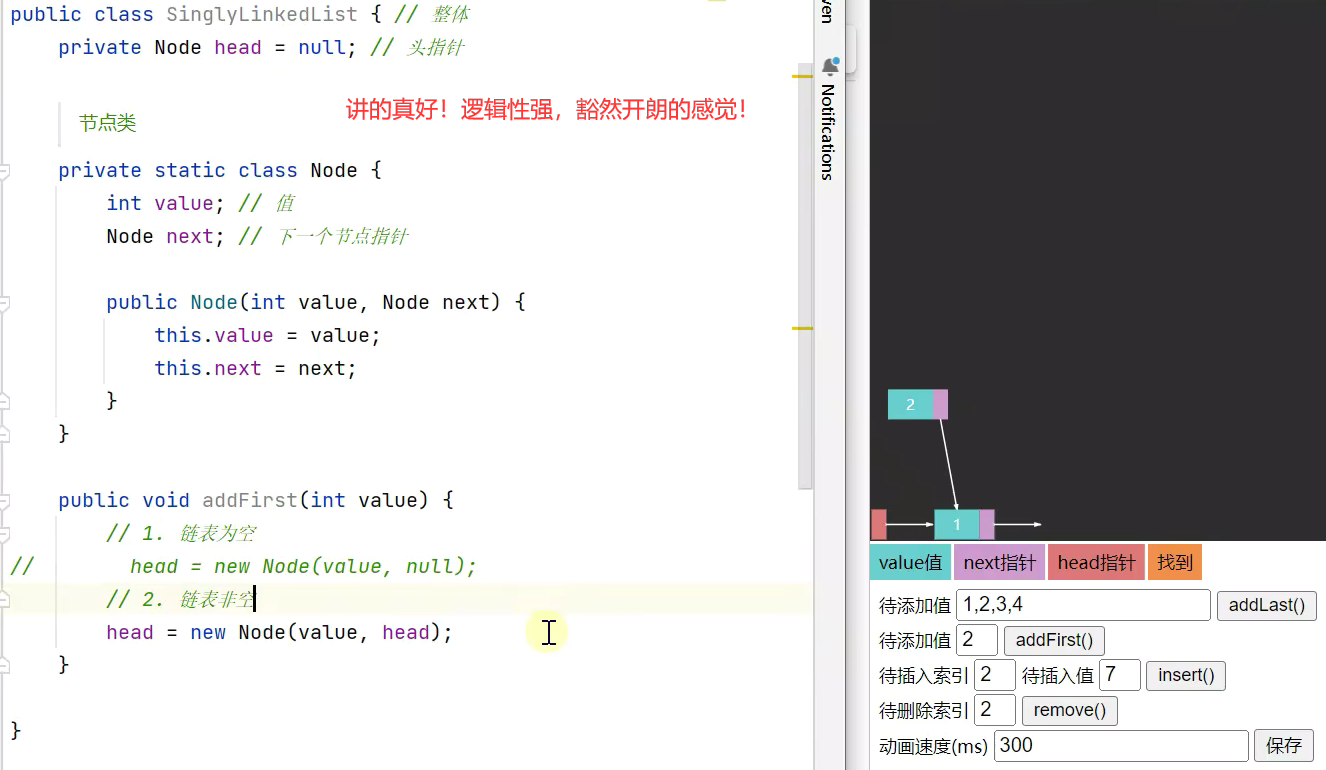
根据索引查询链表元素:链表是在遍历的过程中,逐渐知道它的索引是几。为什么不在链表Node节点对象上再加个属性去记录它的索引是几呢?因为在后期维护的过程中涉及到删除插入等操作会特别麻烦。

根据索引获取元素代码:
public class SinglyLinkedList {
// ...
private Node findNode(int index) {
int i = 0;
for (Node curr = this.head; curr != null; curr = curr.next, i++) {
if (index == i) {
return curr;
}
}
return null;
}
private IllegalArgumentException illegalIndex(int index) {
return new IllegalArgumentException(String.format("index [%d] 不合法%n", index));
}
public int get(int index) {
Node node = findNode(index);
if (node != null) {
return node.value;
}
throw illegalIndex(index);
}
}单向链表(带哨兵):
带哨兵的单向链表:用来简化代码的。观察之前单向链表的实现,发现每个方法内几乎都有判断是不是 head 这样的代码,能不能简化呢?
用一个不参与数据存储的特殊 Node 作为哨兵,它一般被称为哨兵或哑元,拥有哨兵节点的链表称为带头链表
public class SinglyLinkedListSentinel {
// ...
private Node head = new Node(Integer.MIN_VALUE, null);
}双向链表
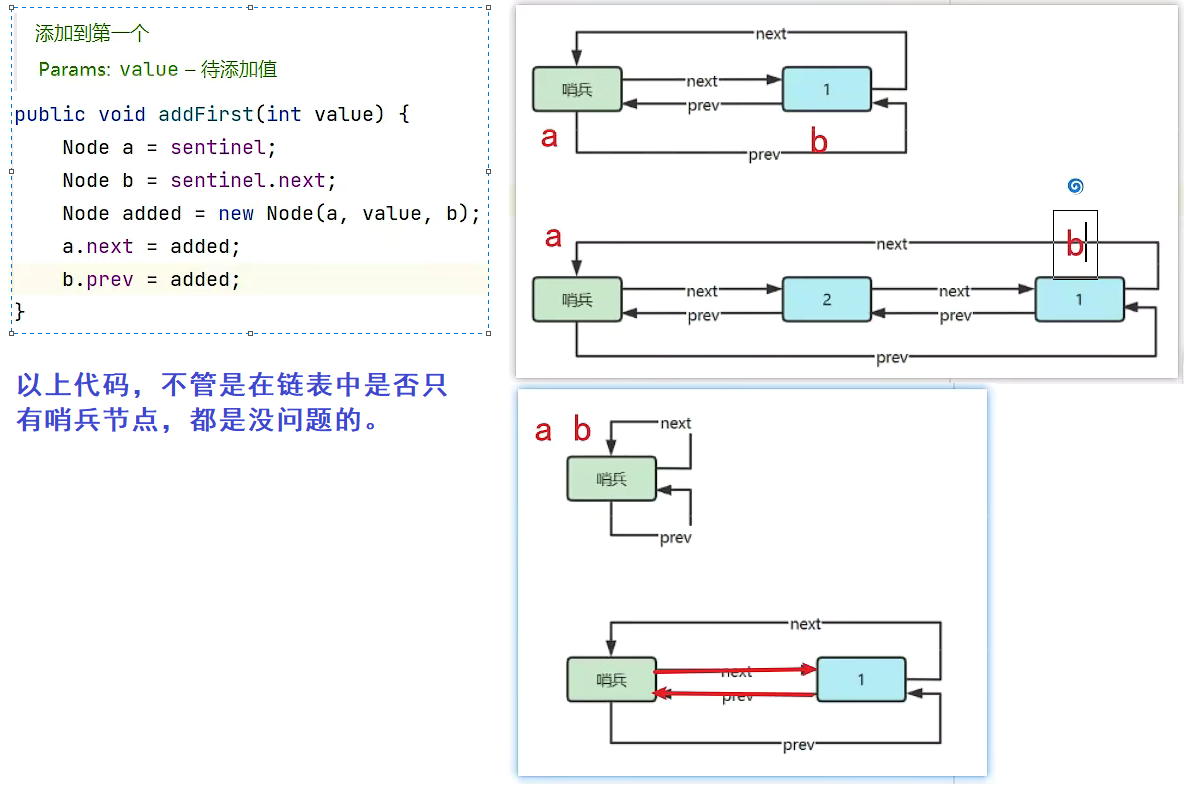
双向链表(带哨兵):
准备工作:
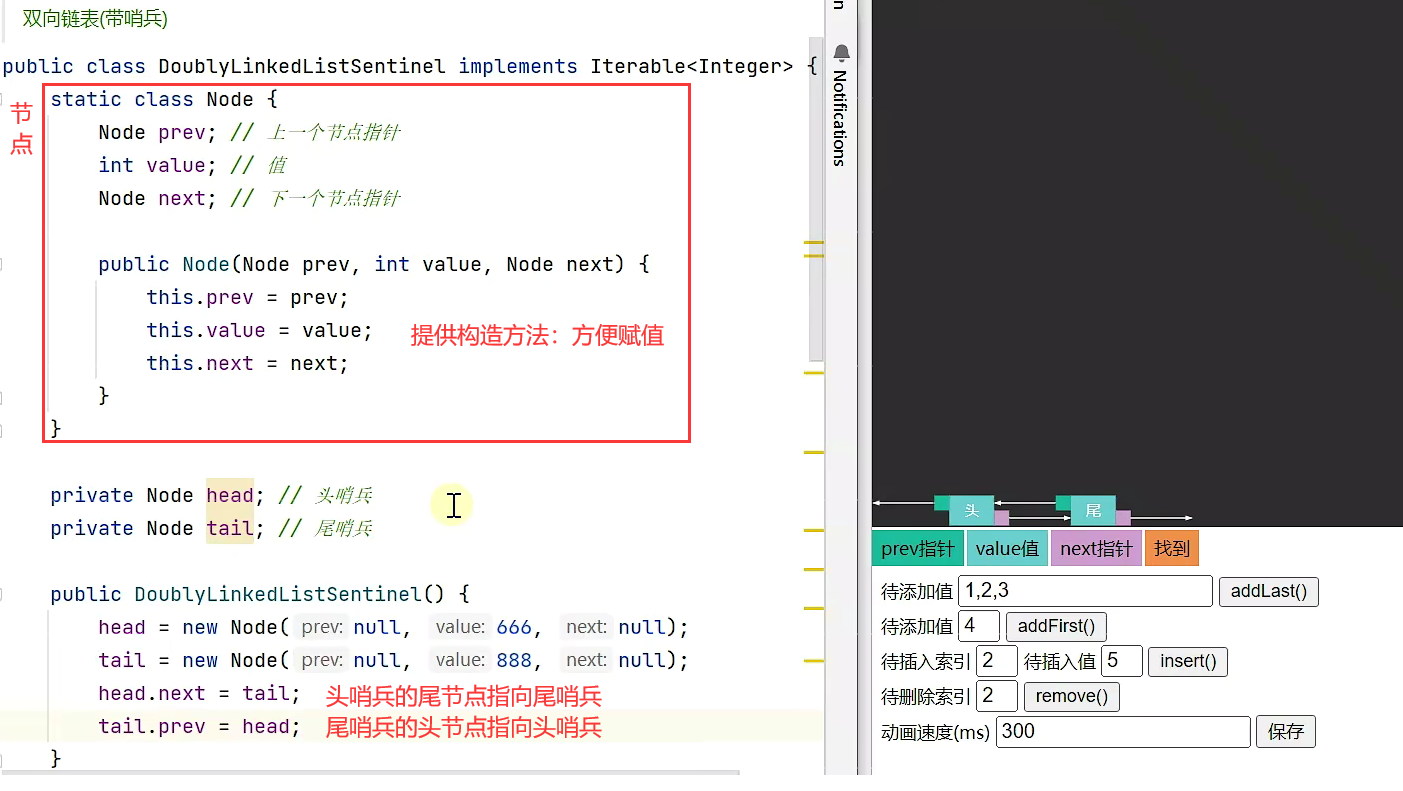
双向链表(带哨兵)与单向链表(带哨兵)的最大优势:在于操作最后节点的相关方法。具体解释:单向链表的相关方法,并没有记录最后一个节点是谁,于是得一个一个从头到尾去找,当找到最后一个节点的指针为 null 时,才表示找到了最后一个节点,才能进行相应的添加/删除等操作。对于双向链表来说,最后一个节点是已知的,通过尾哨兵节点的指针可以获得最后一个元素。

环形链表
环形链表(带哨兵)
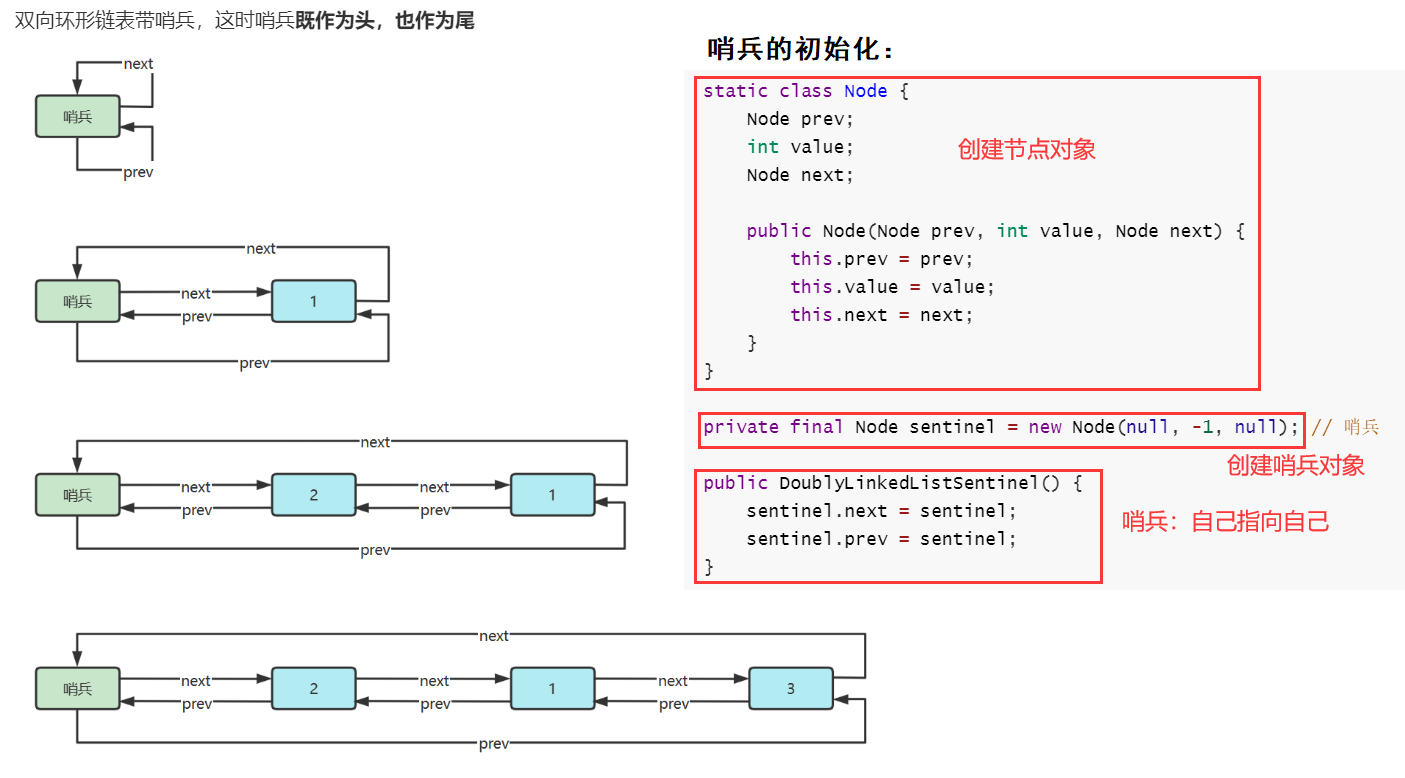
力扣刷题★★★
讲义上的题目:

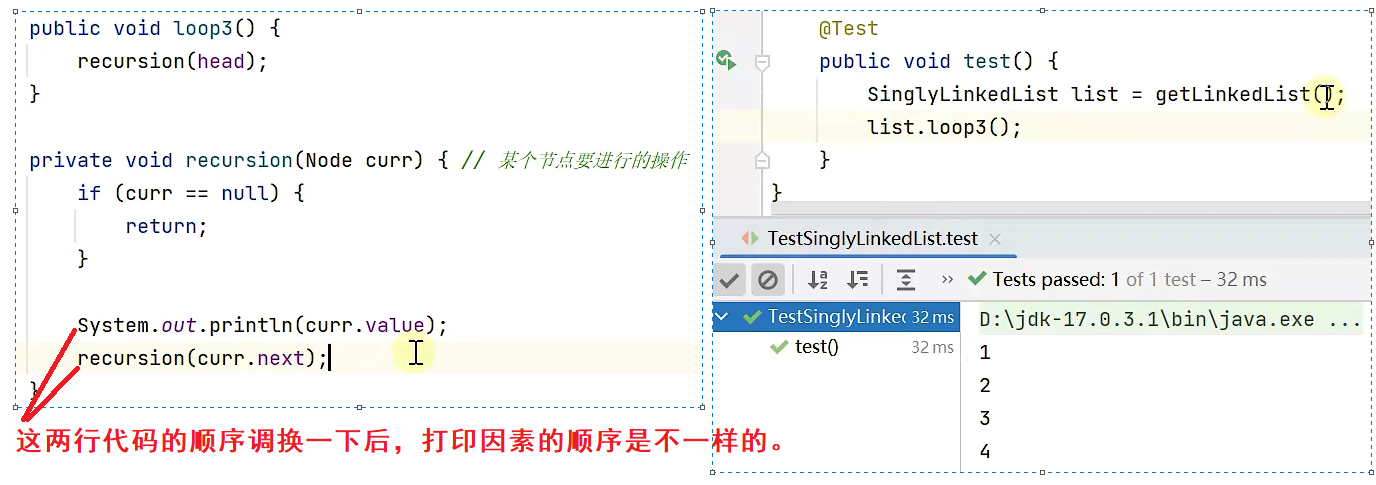
链表的递归遍历
前面讲了链表的几种遍历方式:while循环遍历、for循环遍历、迭代器遍历,此外,链表还有一种非常重要的遍历方式,即递归遍历。
上述代码也可以用接口式编程的Consumer简化,详见视频40。
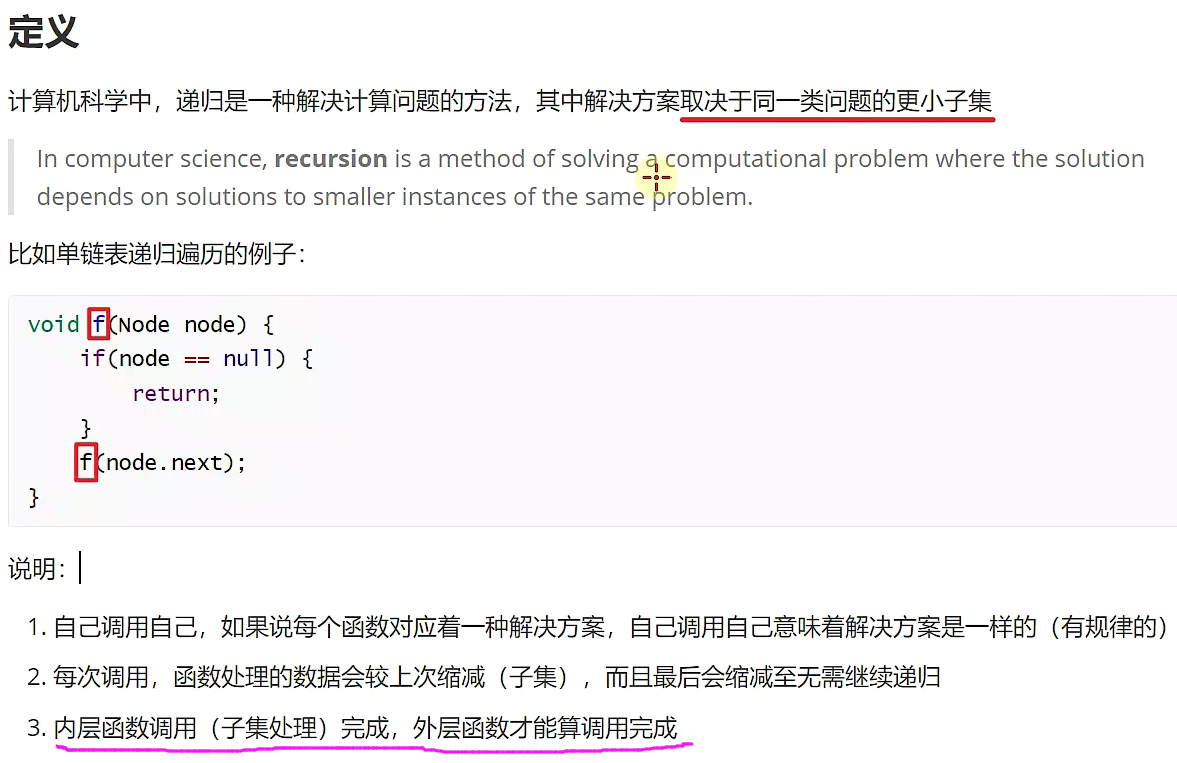
递归★★★


递归练习2:反向打印字符串(思路&代码见讲义图23)
其他递归练习题:见讲义和视频。

冒泡排序优化的原因:减少很多次不必要的递归。代码见截图笔记图26。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









