






一、绪论
1.功能
通过用户输入的一个网址,该程序可以不重复地打印出这个网址中涉及到的一系列其他网址信息
2.预备知识
1.java的基础语法
2.java文本IO及异常处理
二、代码实现
1.代码思路
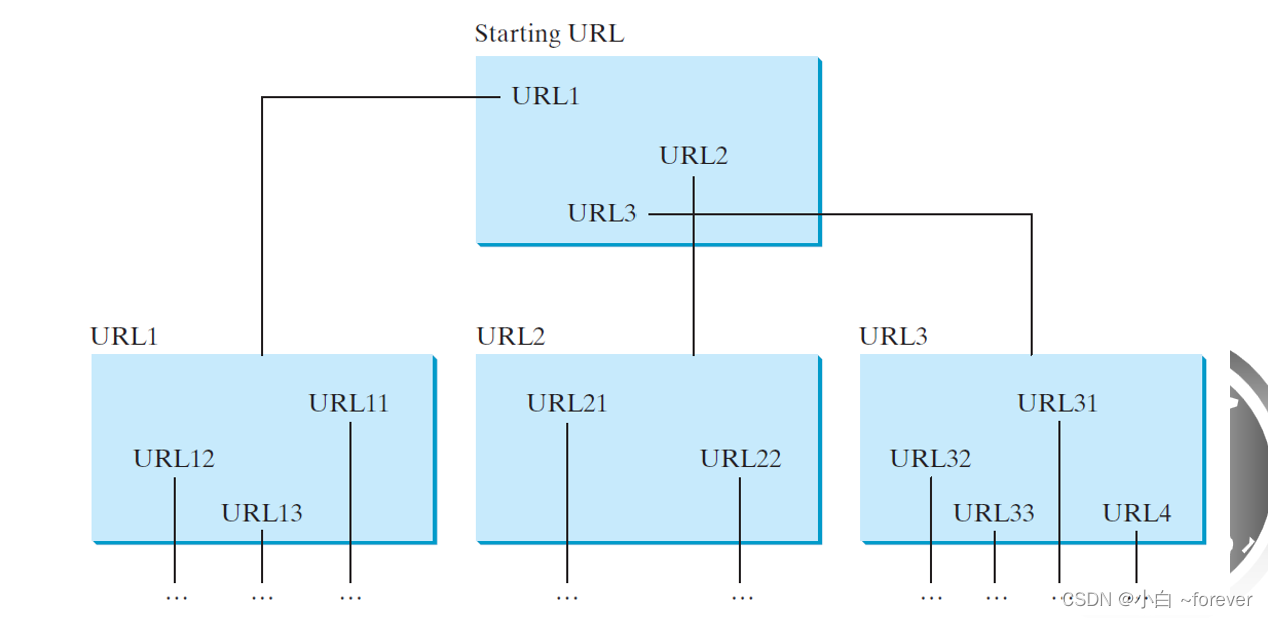
创建两个数组,一个数组存取已经访问过的网址,一个数组存取准备访问地网址,大概的思想和BFS差不多(也可以理解和树地层序遍历思想差不多),先访问一个网址涉及到的所有网址,并将他们添加到待访问地数组中,循环遍历所有网址(在这里我们设计让他访问了100个网址就停止访问)
2.具体代码
Ⅰ.爬虫入口(如何从用户输入的网址抵达其他网址)
static void WebCraw(String url) throws IOException {
waiting.add(new URL(url));
while(!waiting.isEmpty()&&travelled.size()!=100) //当网页不存在网址或已经访问了100个网址时停止访问
{
URL cur= waiting.get(0);
waiting.remove(0); //取出待爬取中的第一个网址进行爬取
System.out.println(cur); //将其打印出来
travelled.add(cur);
try( InputStream inputStream= cur.openStream();
Scanner scanner=new Scanner(inputStream)) {
while (scanner.hasNext()) {
String str = scanner.nextLine();
WebOperate(str);
}
}
catch (UnknownHostException ex) //可能无法访问
{
System.out.println("UnknownHostException");
}
catch (IOException ex)
{
System.out.println("IOException");
}
catch (IllegalArgumentException ex)
{
System.out.println("IllegalArgumentException");
}
}
}
Ⅱ.单网址的爬取处理
static void WebOperate(String str) throws MalformedURLException {
int begin=str.indexOf("https://");
if(begin!=-1&&str.substring(begin).contains("\"")) //要保证后面有双引号
{ //网址以https://开始,以”结束
int end = str.substring(begin).indexOf("\"") + begin; //注意此处要从找到https://之后开始找
String site = str.substring(begin, end);
URL url = new URL(site);
if (!travelled.contains(url)) {
waiting.add(url); //将扫描到的网址添加到待访问数组中去
}
if (end<str.length() - 1) WebOperate(str.substring(end + 1)); //继续访问没访问完的这行数据
}
}Ⅲ.主函数(让用户输入要爬取的网址)
public static void main(String []args) throws IOException
{
travelled.clear(); //初始化两个数组
waiting.clear();
System.out.println("请输入要爬取的网址:");
Scanner input=new Scanner(System.in);
String url=input.nextLine();
WebCraw(url);
}3.完整代码
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.UnknownHostException;
import java.util.ArrayList;
import java.util.Scanner;
public class WebCrawler {
static ArrayList<URL> travelled=new ArrayList<>();
static ArrayList<URL> waiting=new ArrayList<>();
static void WebOperate(String str) throws MalformedURLException {
int begin=str.indexOf("https://");
if(begin!=-1&&str.substring(begin).contains("\"")) //要保证后面有双引号
{ //网址以https://开始,以”结束
int end = str.substring(begin).indexOf("\"") + begin; //注意此处要从找到https://之后开始找
String site = str.substring(begin, end);
URL url = new URL(site);
if (!travelled.contains(url)) {
waiting.add(url); //将扫描到的网址添加到待访问数组中去
}
if (end<str.length() - 1) WebOperate(str.substring(end + 1)); //继续访问没访问完的这行数据
}
}
static void WebCraw(String url) {
waiting.add(new URL(url));
while(!waiting.isEmpty()&&travelled.size()!=100) //当网页不存在网址或已经访问了100个网址时停止访问
{
URL cur= waiting.get(0);
waiting.remove(0); //取出待爬取中的第一个网址进行爬取
System.out.println(cur); //将其打印出来
travelled.add(cur);
try( InputStream inputStream= cur.openStream();
Scanner scanner=new Scanner(inputStream)) {
while (scanner.hasNext()) {
String str = scanner.nextLine();
WebOperate(str);
}
}
catch (UnknownHostException ex) //可能无法访问
{
System.out.println("UnknownHostException");
}
catch (IOException ex)
{
System.out.println("IOException");
}
catch (IllegalArgumentException ex)
{
System.out.println("IllegalArgumentException");
}
}
}
public static void main(String []args) throws IOException
{
travelled.clear(); //初始化两个数组
waiting.clear();
System.out.println("请输入要爬取的网址:");
Scanner input=new Scanner(System.in);
String url=input.nextLine();
WebCraw(url);
}
}
4.结果展示
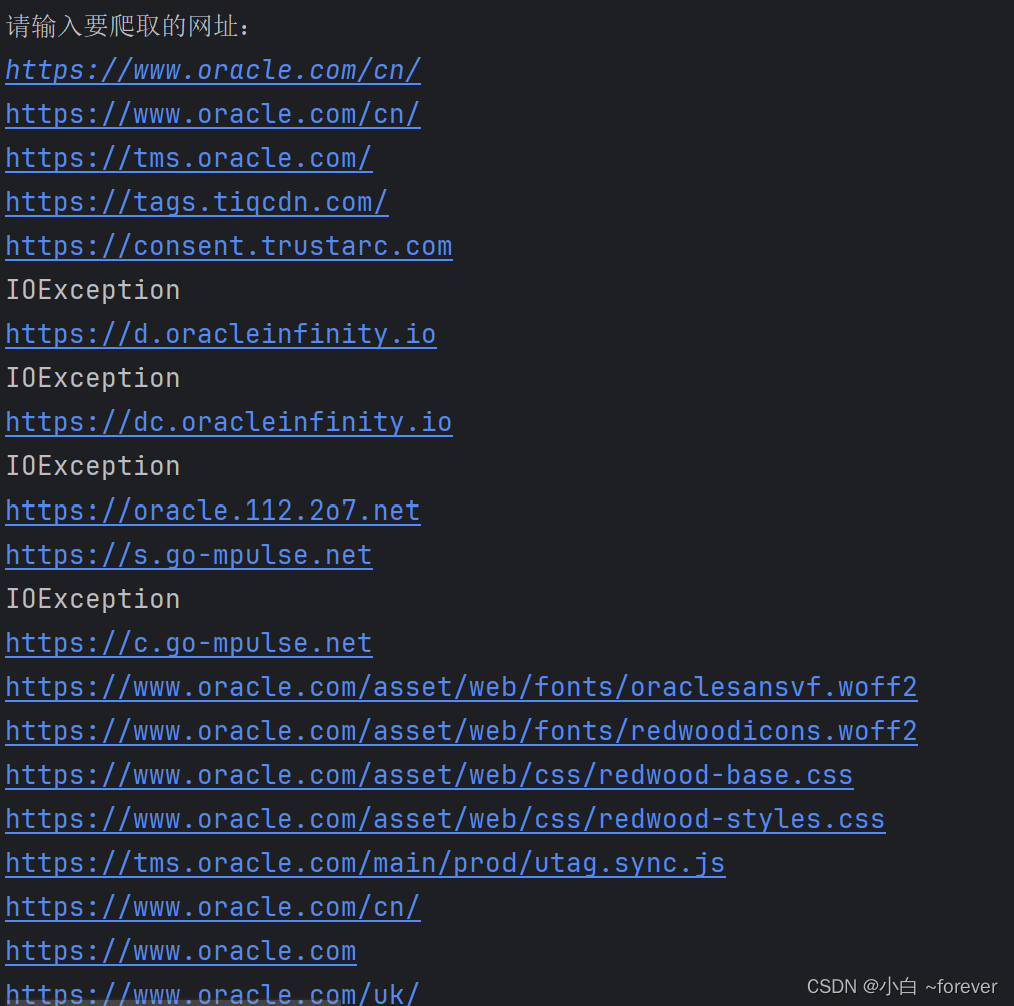
下面还有许多,就不截完了😀
三、总结
当然这只是最最最简单的一个实现,可以看到在程序中我们连捕捉到的异常都没有进行处理,只是将其打印了出来,还有性能等其他方面都还差很远,这只是一个简单的尝试和体验,理解大概的算法思路😀


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









