






建立一个springboot项目可以在网址输入start.spring.io,可以在这个网站直接添加依赖,或者之后通过pom.xml文件引入 这里先引入一个web依赖即可,用idea打开文件夹,再点开external spring可以看见下载的依赖,可以看见tomcat服务器已经内置在springboot中了
首先看启动的代码,即主路径下面的application,目的是启动springboot框架托管的IOC容器(通过JVM,即java虚拟机),而不是直接启动IOC容器中托管的一个一个类,所以诸如SpringApplication.run(DemoAppApplication.class, args);的代码是为了启动IOC容器
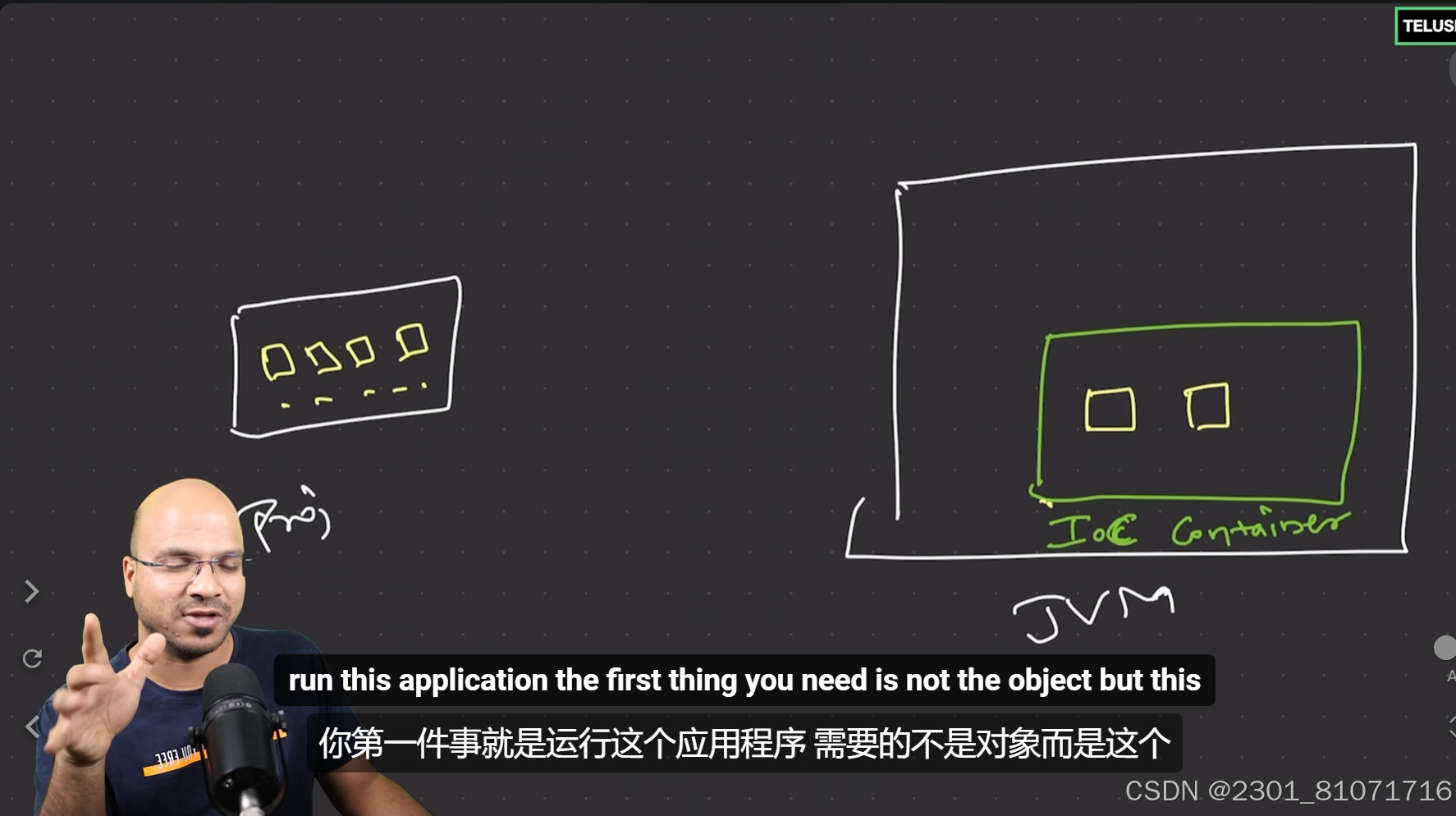
对比1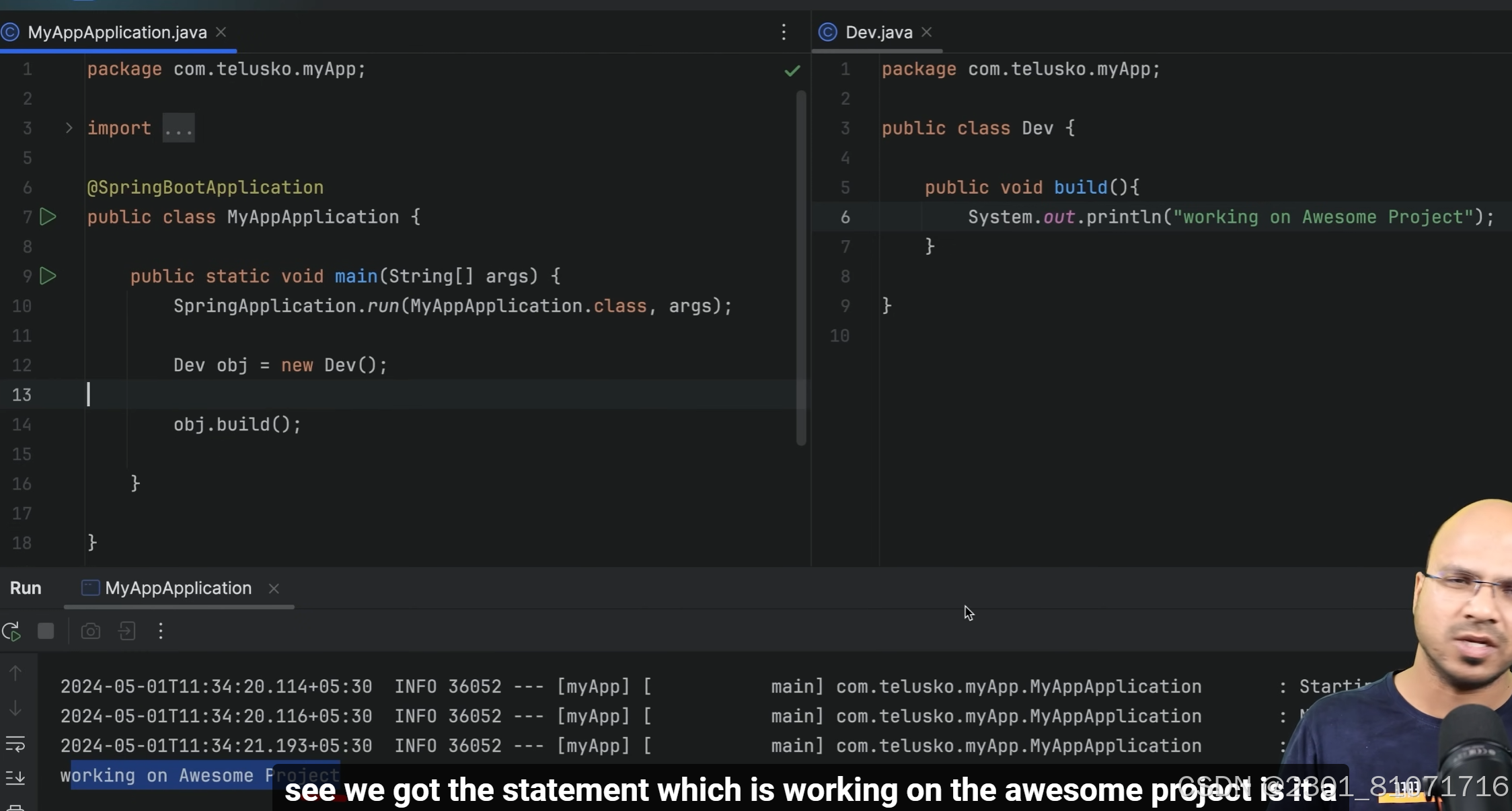

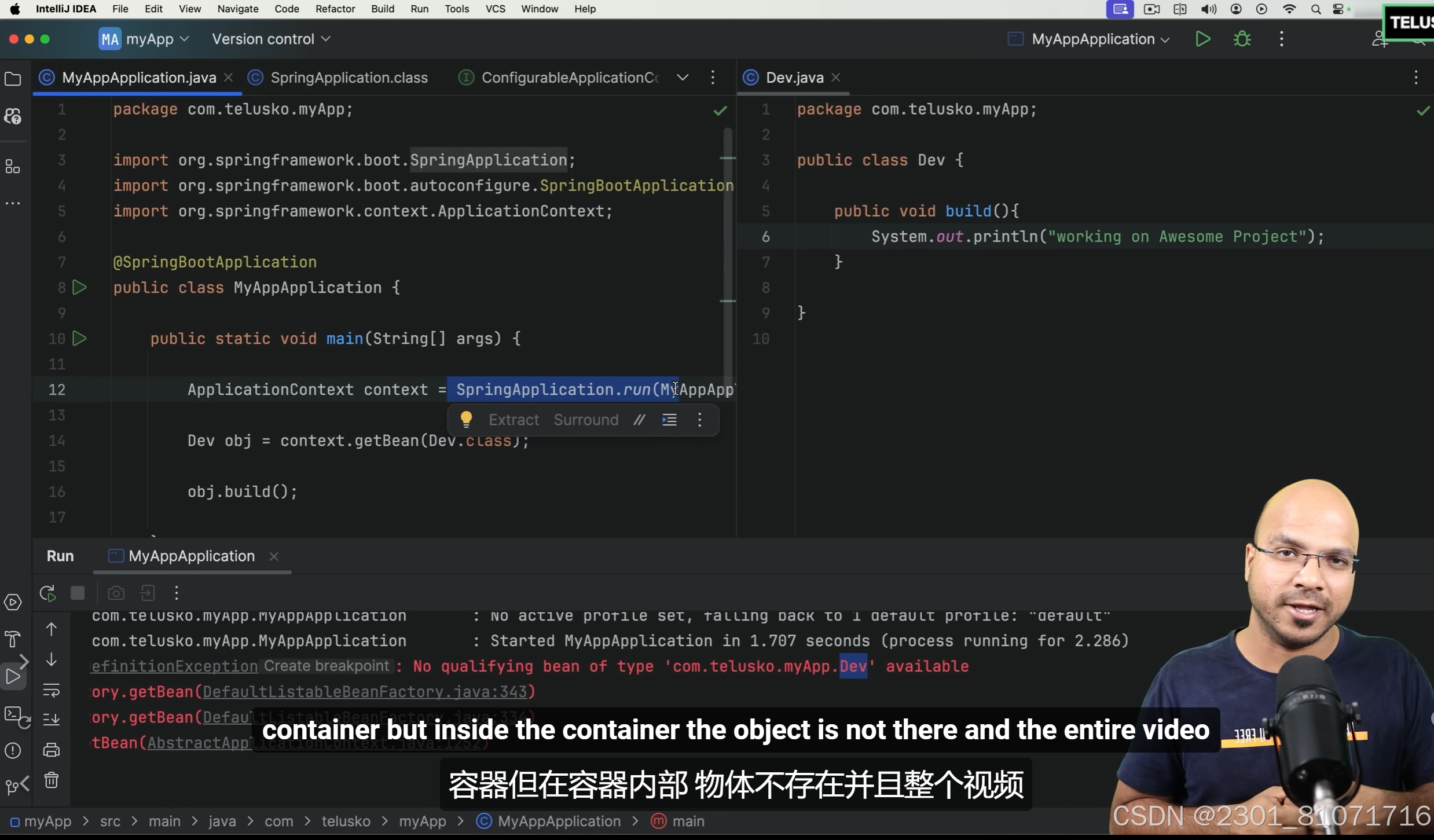
第三张图想要从容器中取出,但是因为没有依赖注入,所以报了一个容器内部没有这个bean的错误,因为IOC容器没有管理这个对象(Spring默认不会创建对象,默认不会管理对象)

在Dev类上面加上@Component就能让IOC容器管理该类了,如图4
接下来说一下如果Dev类中要引入其他的类(这个与上面不同,这个不是在启动类中调用IOC容器了),怎么将这个其他的类管理而不是用new创建一个新对象
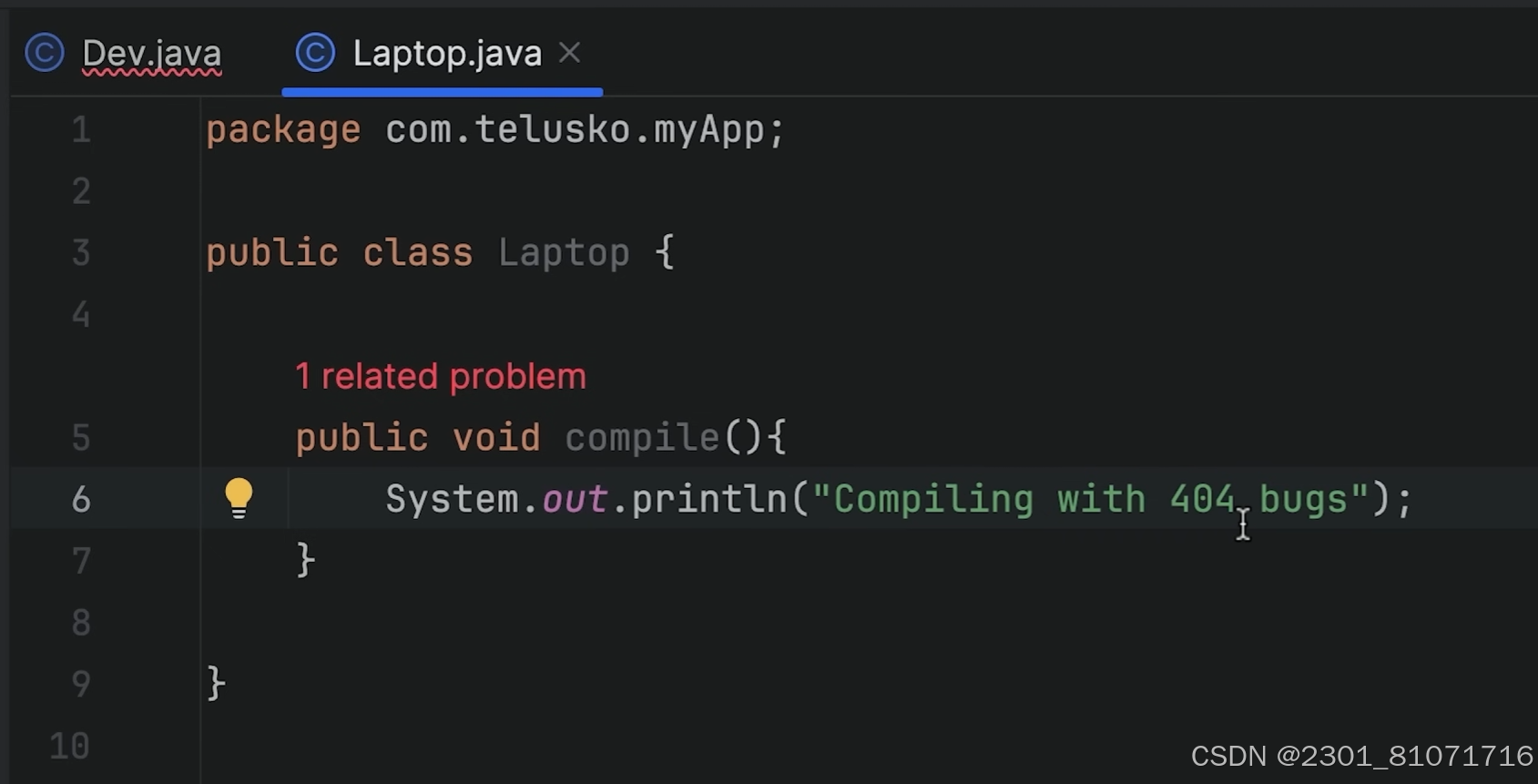
现在我的developer(即Dev类)需要compile,所以需要一个电脑,现在创建一个Laptop类和一个Desktop类,如果不用IOC容器管理或者不依赖注入,就会像下面的图一样创建对象
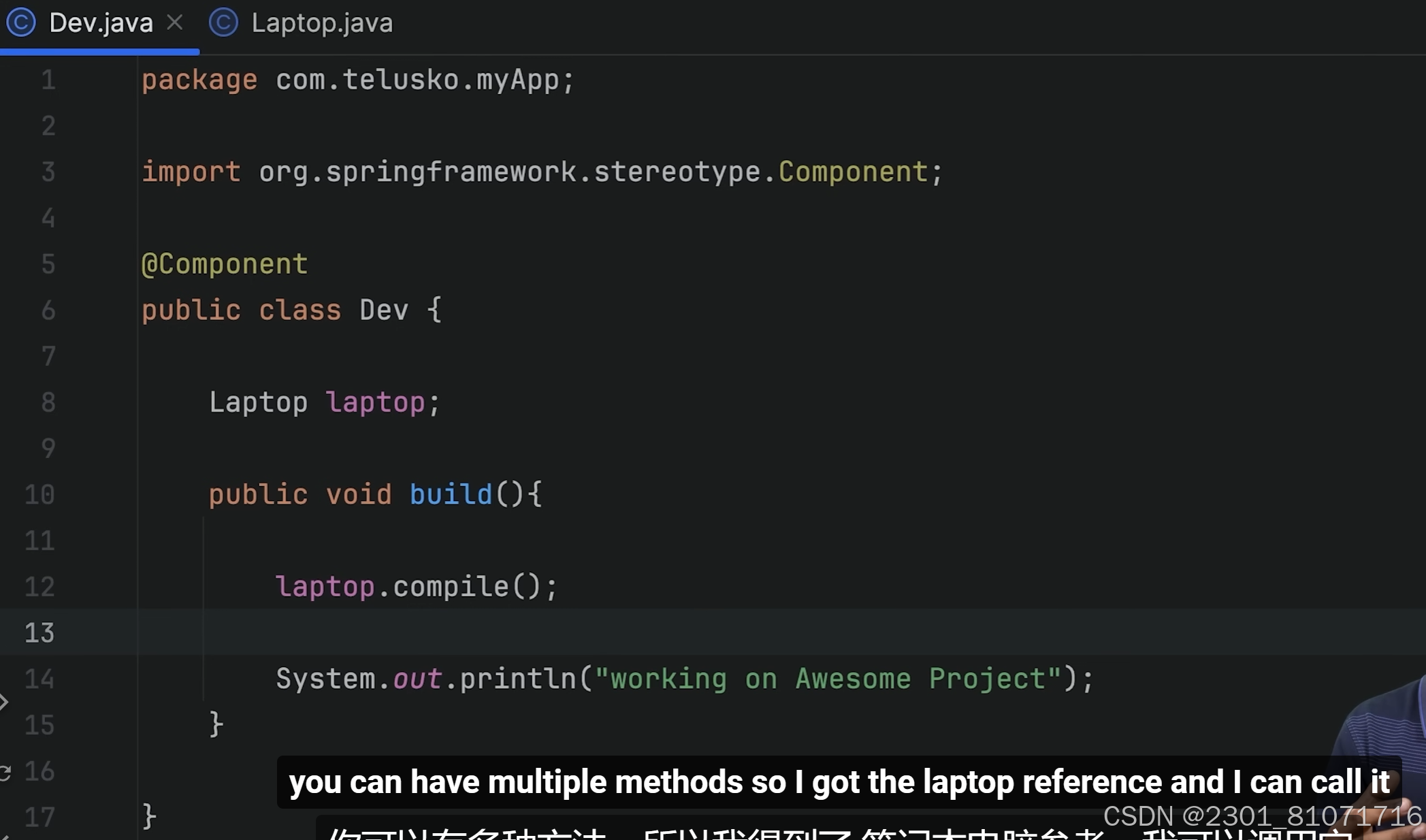
但是这个会有错误,如图,因为默认会赋值Laptop laptop = null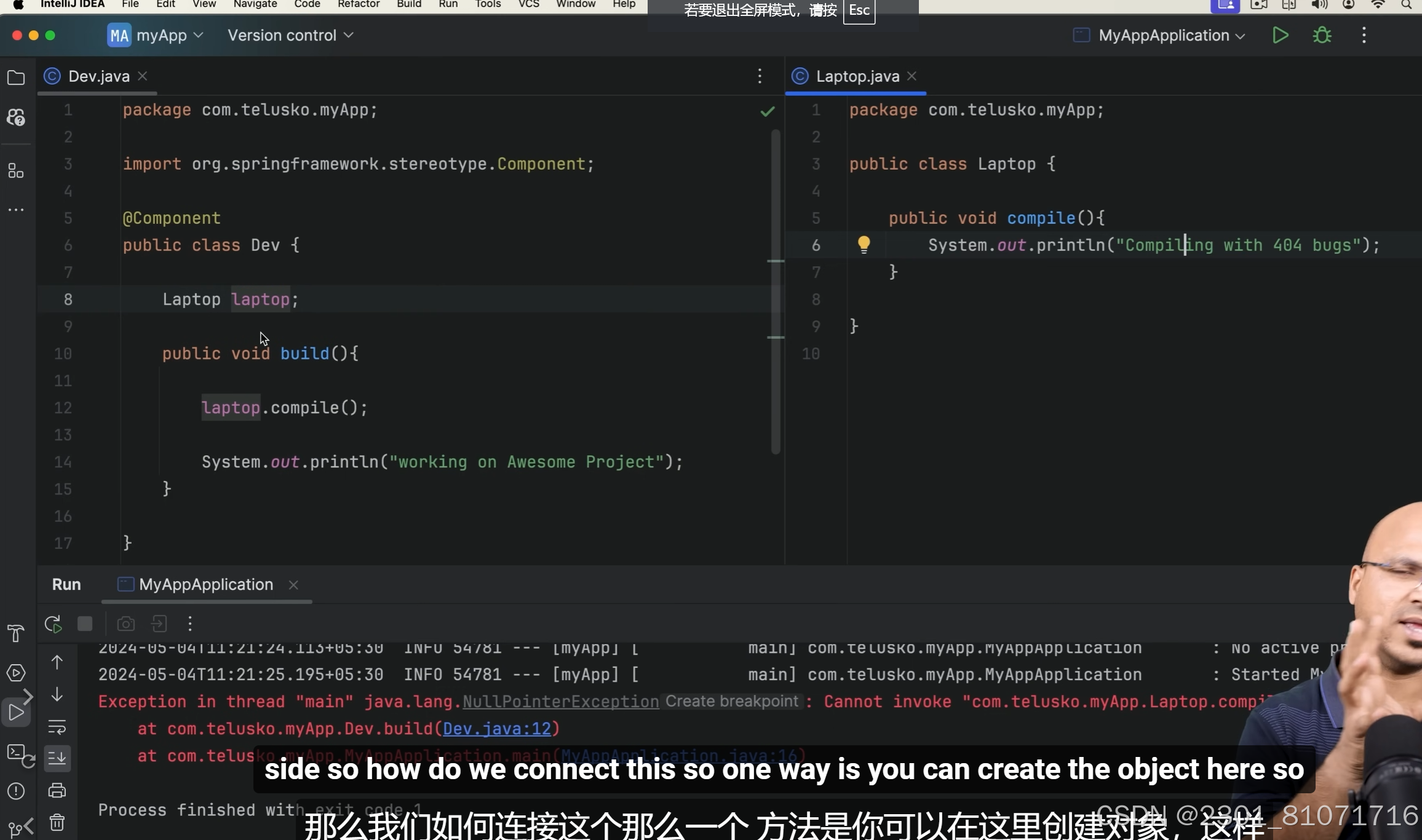
所以需要new一个laptop,如图,这样就可以正确运行了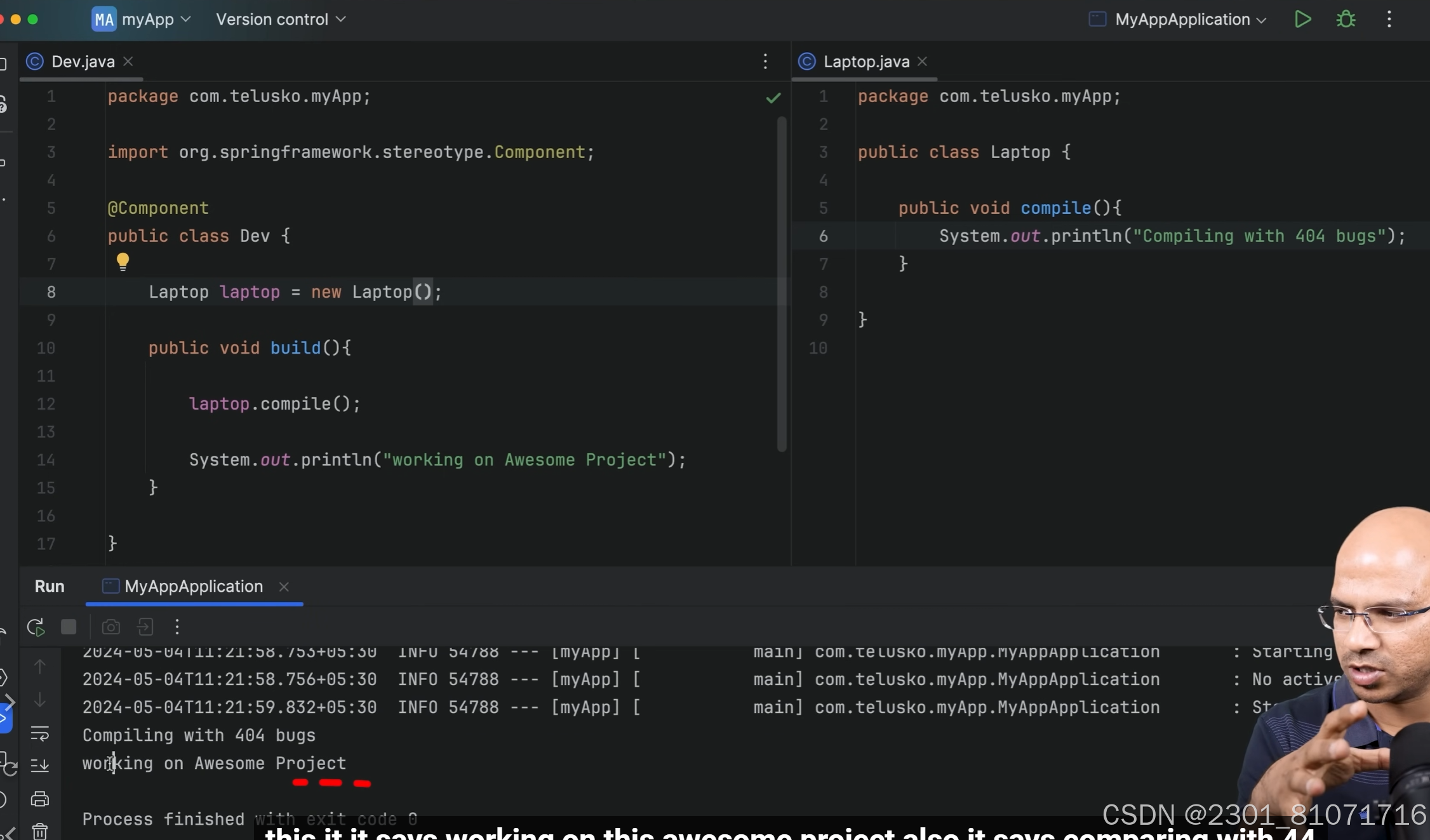
但是这不是我们想要的,因为Dev不想单独创建Laptop的对象,但是如果在Laptop上面加上@component,则只有IOC容器知道和管理Laptop,但是Dev仍然不知道,虽然可以用启动类的IOC容器获得的方法调用Laptop,但是很明显不好。解决方法如下图,这里有了@Autowired,使得在幕后将这些容器管理的类有了联系,注意Laptop上面仍然要有@Component,通过这个没有new关键字也可以使用bean了,这个依赖注入的方式叫field injection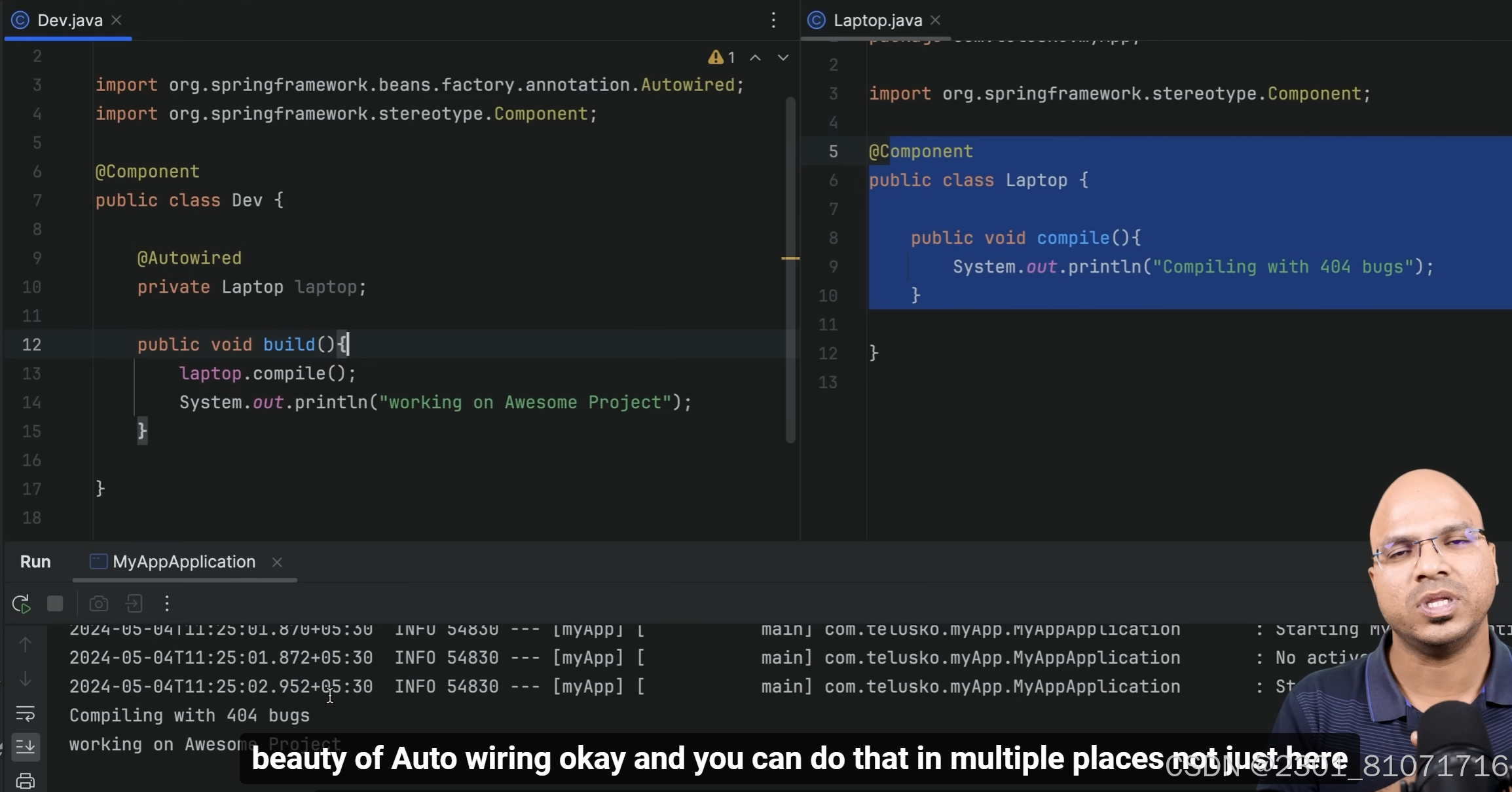
第二种依赖注入的方式是constructor injection,如下图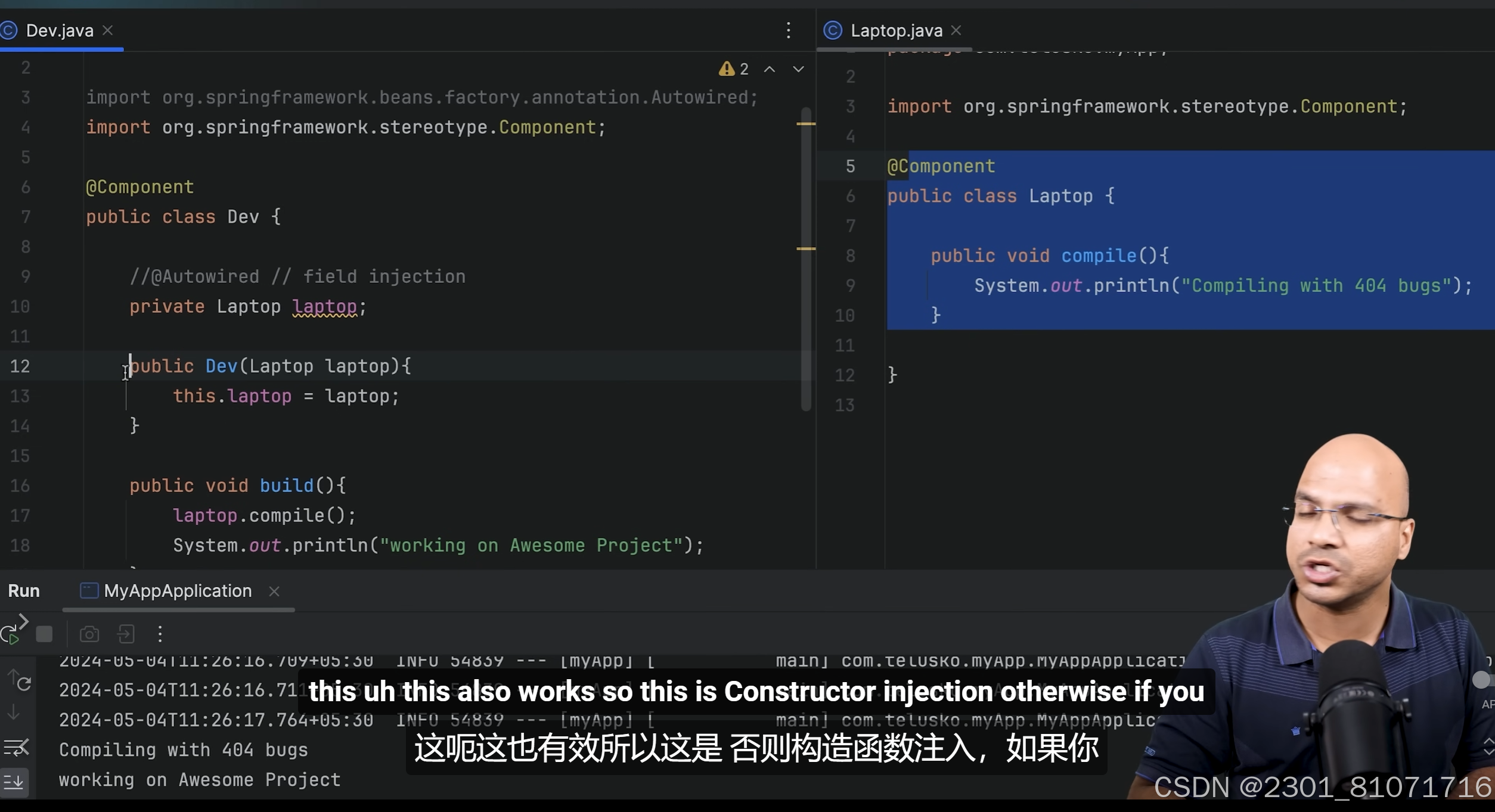 第三种是setter injection,注意这里的set函数上面要加@Autowired注解
第三种是setter injection,注意这里的set函数上面要加@Autowired注解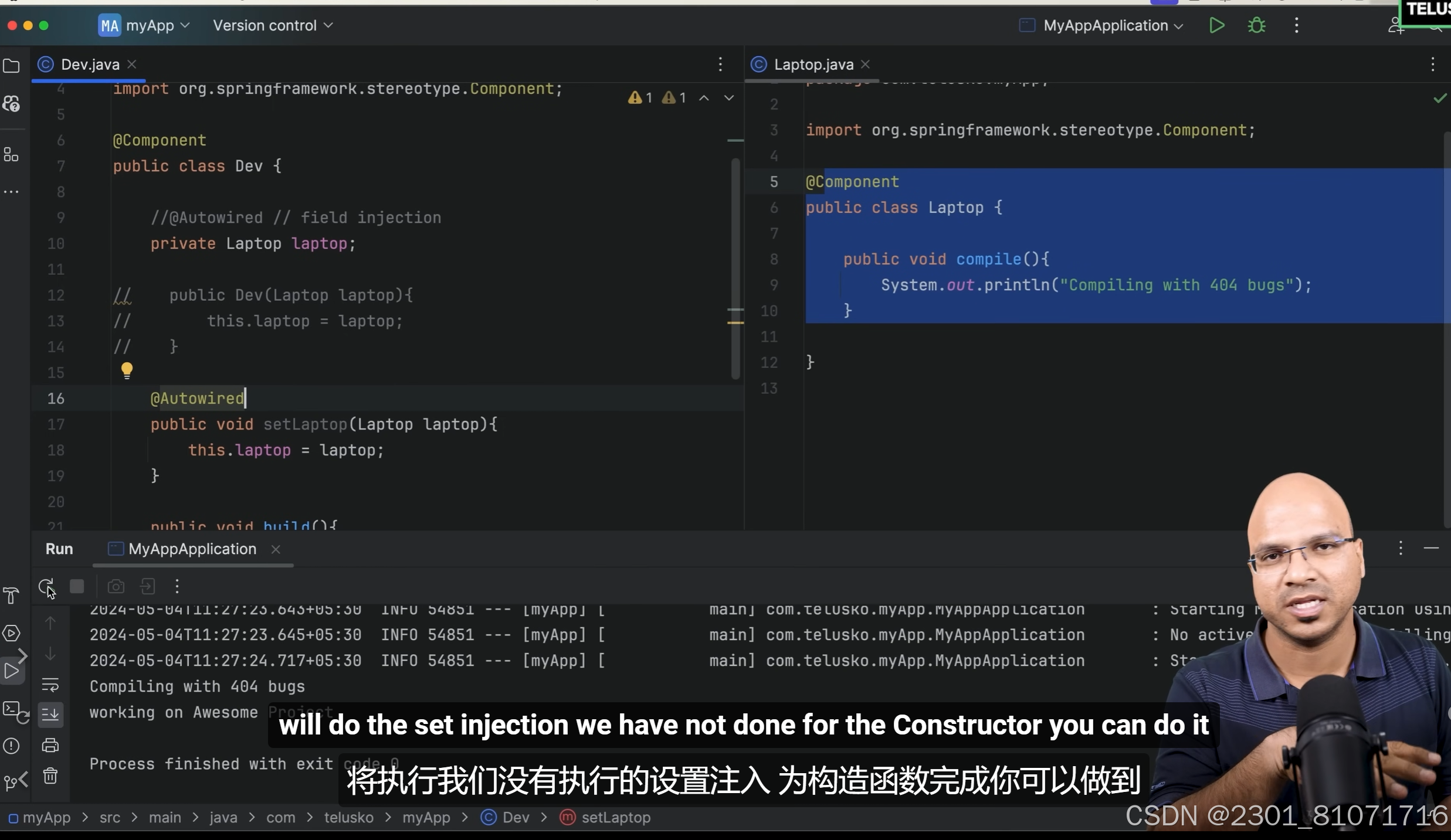
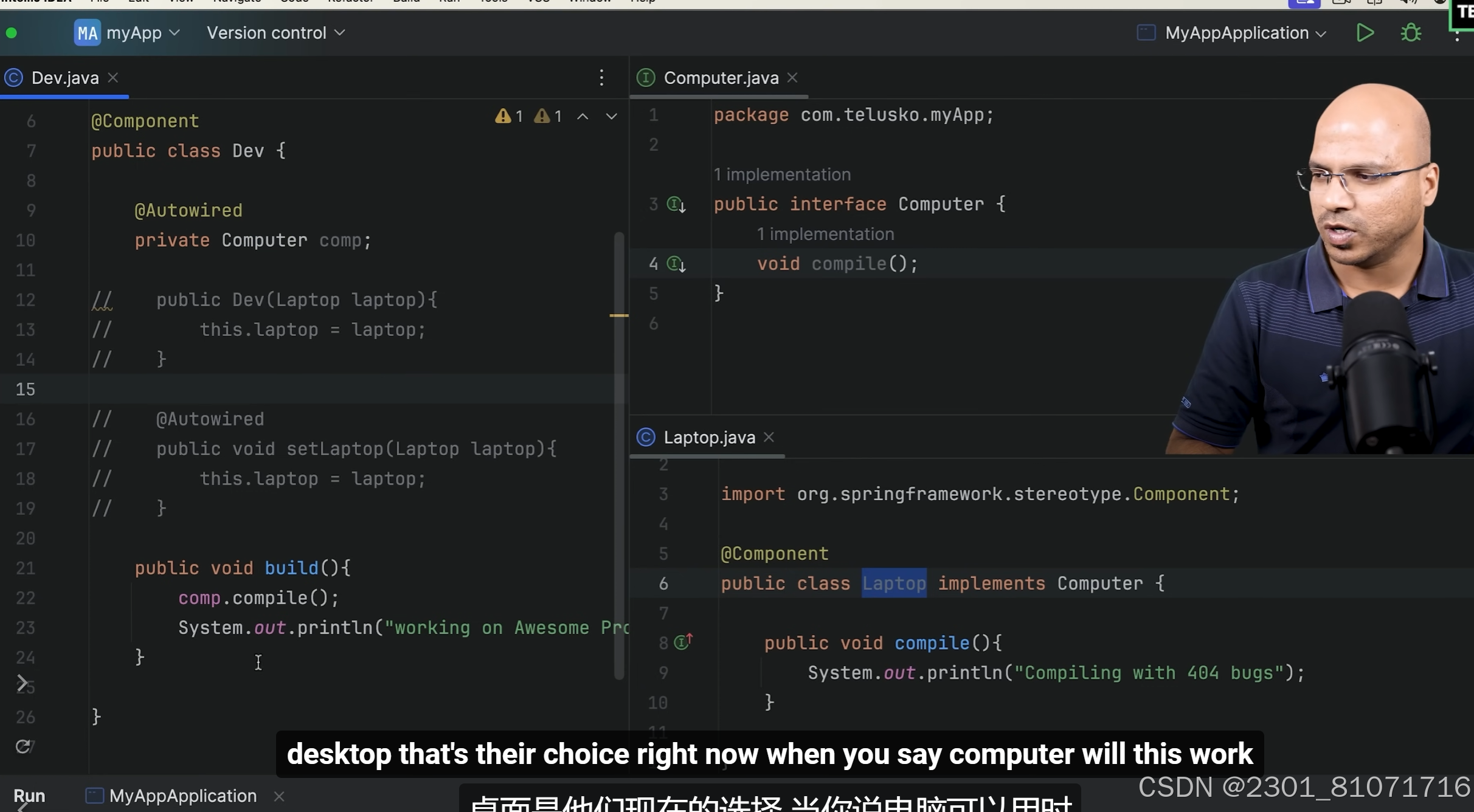
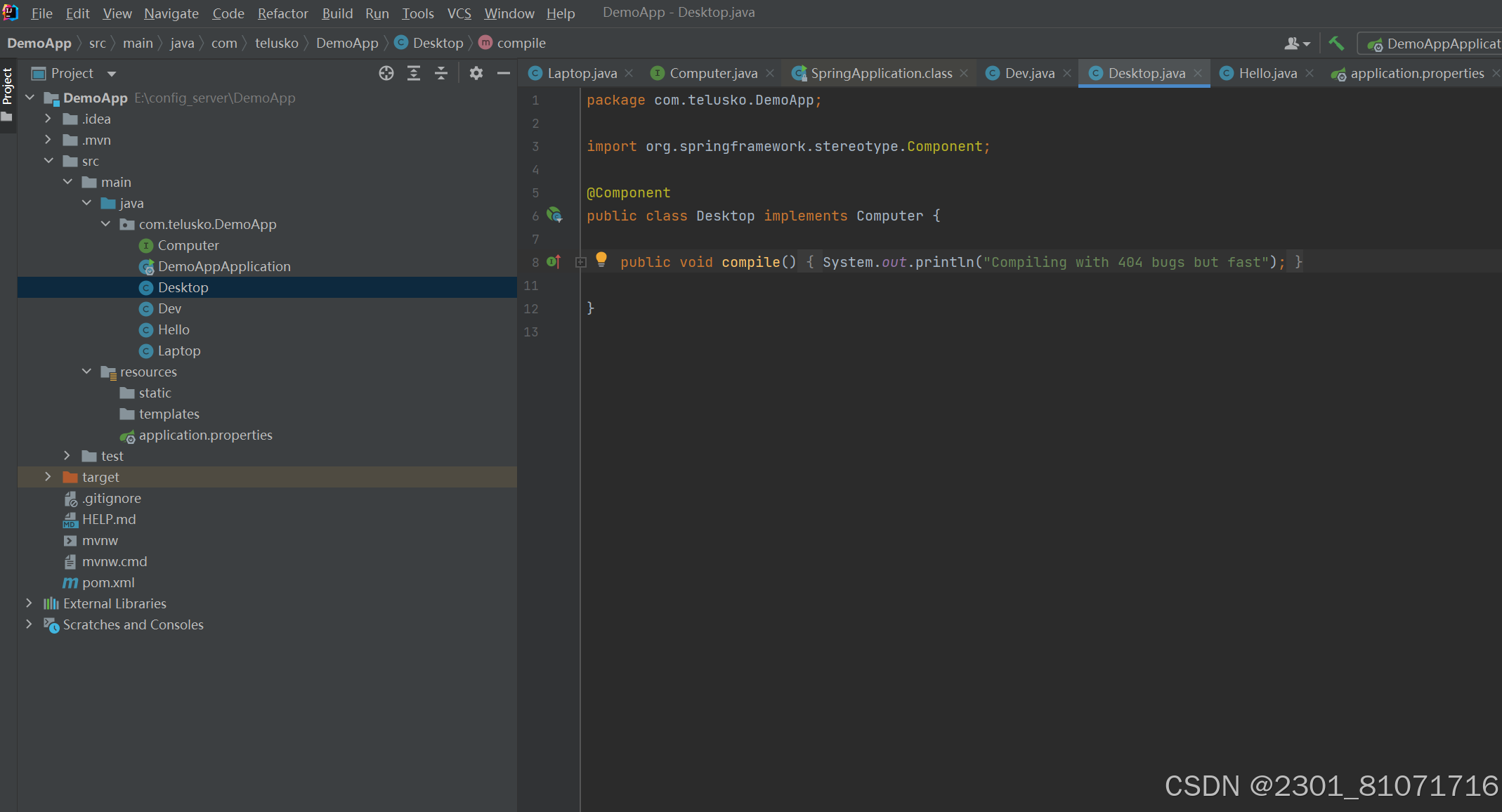
接下来为了解耦合,需要定义一个接口Computer,因为Laptop和Desktop都可implement Computer类,注意Dev中的private Computer comp的comp是按类型索引的,所以只有一个implement Computer的Laptop是可以运行成功的,但是如果还有一个Desktop,如下下图,则方法一是只将Laptop或者Desktop的某一个上面加上@Component(则另一个不会被注册),但是治标不治本,第二种方法是在某一个上面加上@Primary,不能两个都加,第三种方法是在Autowired上面加@Qualifier("laptop")或者@Qualifier("desktop"),注意这里的Qualifier里面的是类的小写形式
IOC(inversion of control):
控制反转,即在传统的程序设计中,一个类可能会直接创建它依赖的其他类的实例。而在 IoC 容器中,类的实例(即对象)是由容器创建并管理的,而不是由类自身创建。在 Spring 框架中,IoC 容器负责管理 Spring 应用上下文中的 Bean(即 Spring 管理的对象)的生命周期和依赖关系。开发者可以通过 pom.xml 配置文件、注解(如 @Autowired、@Component 等)或 Java 配置类来声明 Bean 和它们的依赖关系。
IOC通过DI(dependency injection)去实现,即依赖注入,springboot中的依赖注入有三种方式:field injection,constructor injection,setter injection,这些在上面已经具体解释过了
MVC是一种软件设计模式,用于实现用户界面与业务逻辑的分离。MVC代表模型(Model)、视图(View)和控制器(Controller),这三个组件共同协作,使得应用程序的结构更加清晰,更易于维护和扩展。model数据库,repo之类的,view函数(service),controller路由,引到某个service。结构差不多如下图
现在开始介绍springboot的具体web应用:
首先打开上面的网站,添加web和devtools的依赖,devtools的作用是livereload,即每次都会实时加载,方便调试,如果需要添加数据库,还需要加上数据库的driver。
对于controller来说,如果注释是@Controller,return "hello" 会错误,如下图,因为@Controller返回的是一个页面,但是改为@RestController就可以了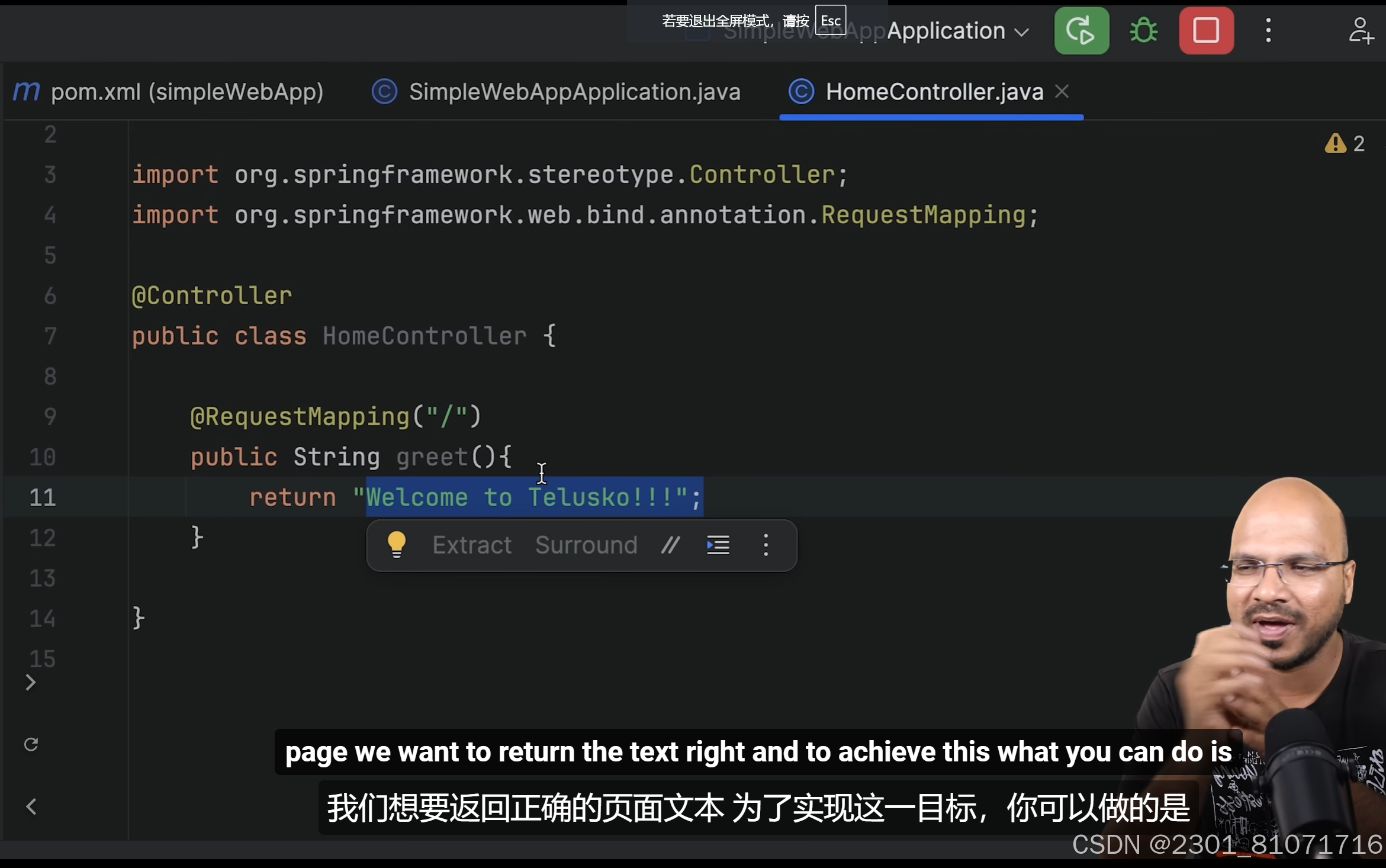
REST全称如图
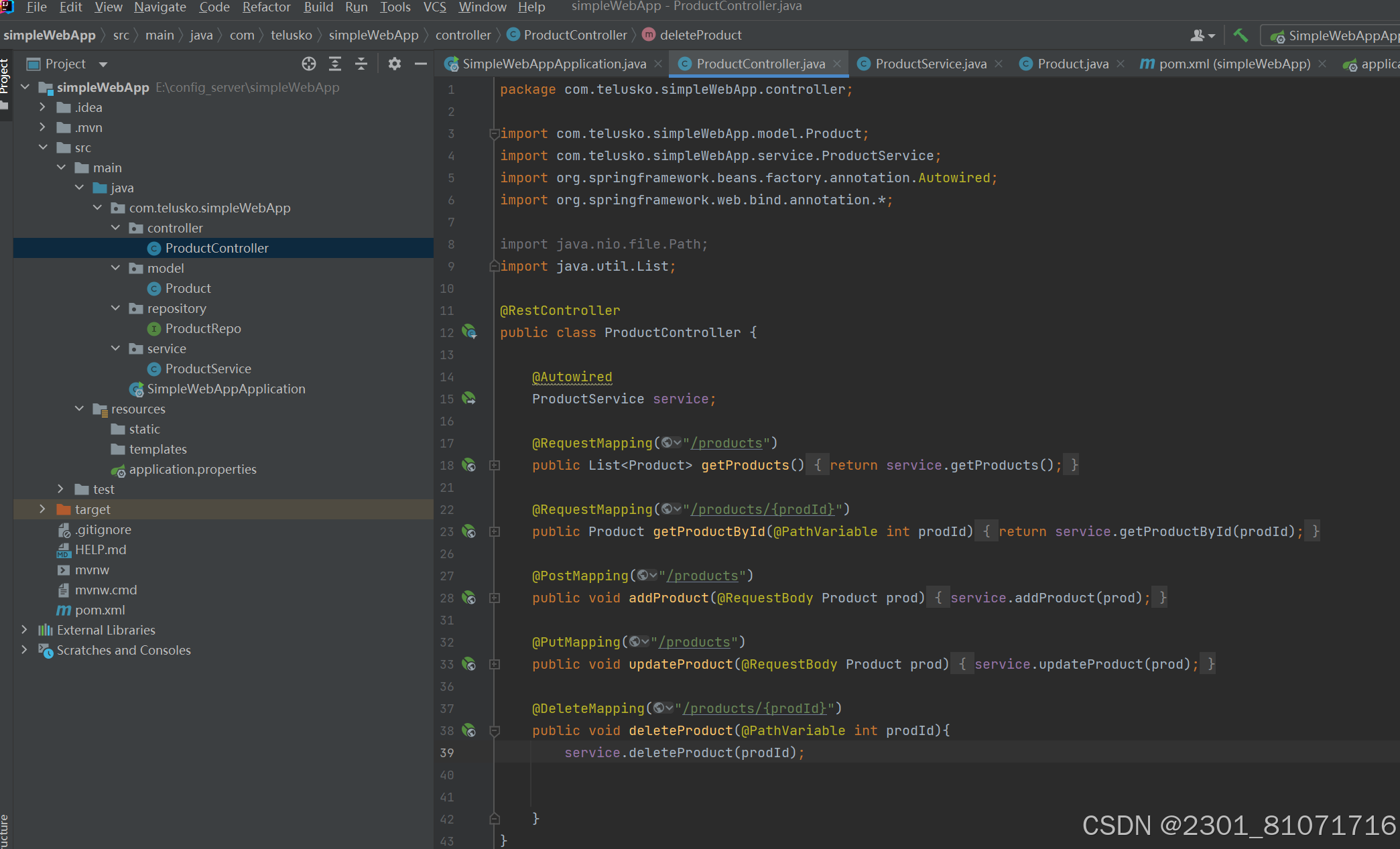
如果返回hello而不是一个页面还有第二种方法,如图,加上@RespondBody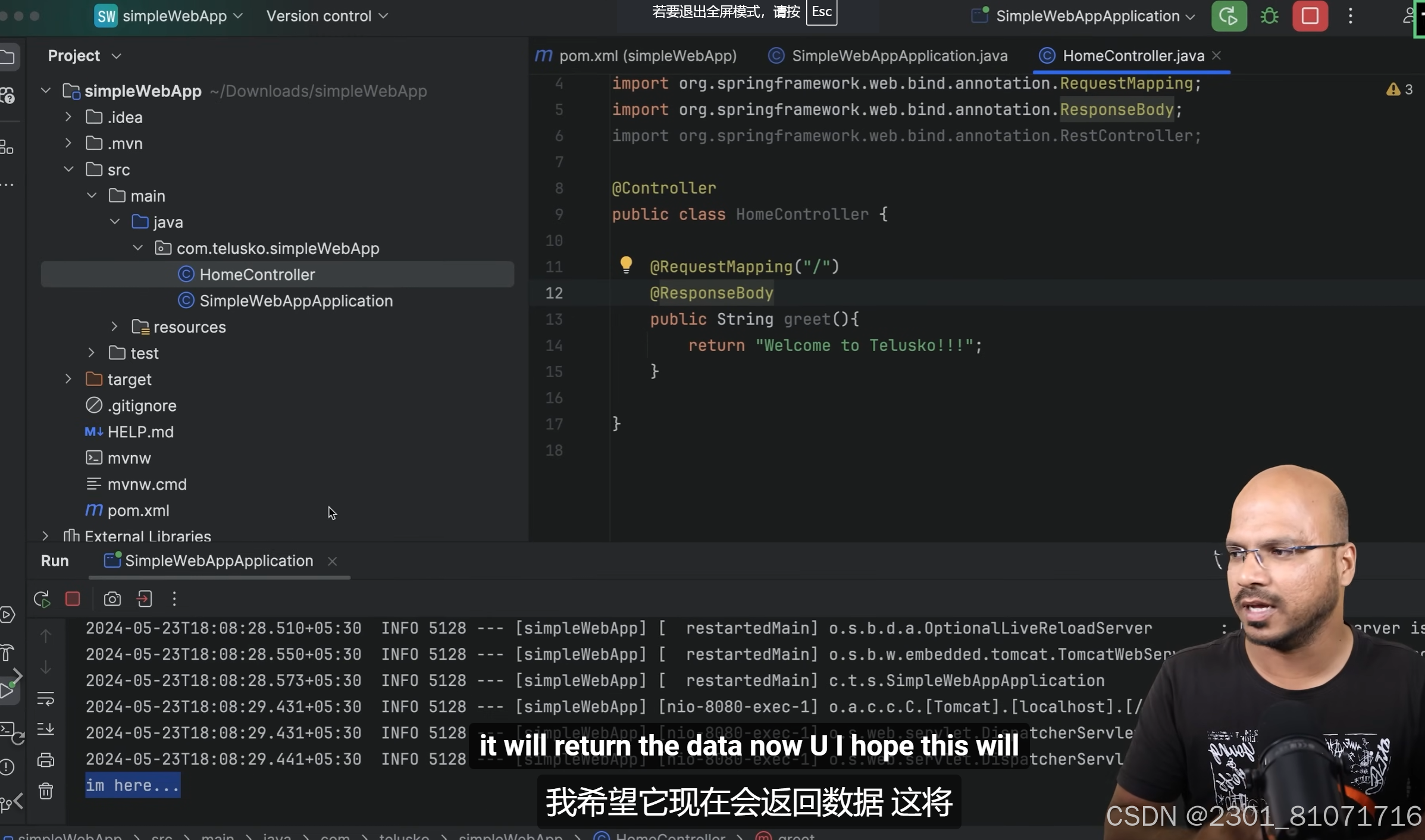 依赖lombok是用来写表中的表头的,比如上面的model中的product类,在一开始学时,这个的service层可以直接硬编码,直接创建现有的数据,如下图,方便入门
依赖lombok是用来写表中的表头的,比如上面的model中的product类,在一开始学时,这个的service层可以直接硬编码,直接创建现有的数据,如下图,方便入门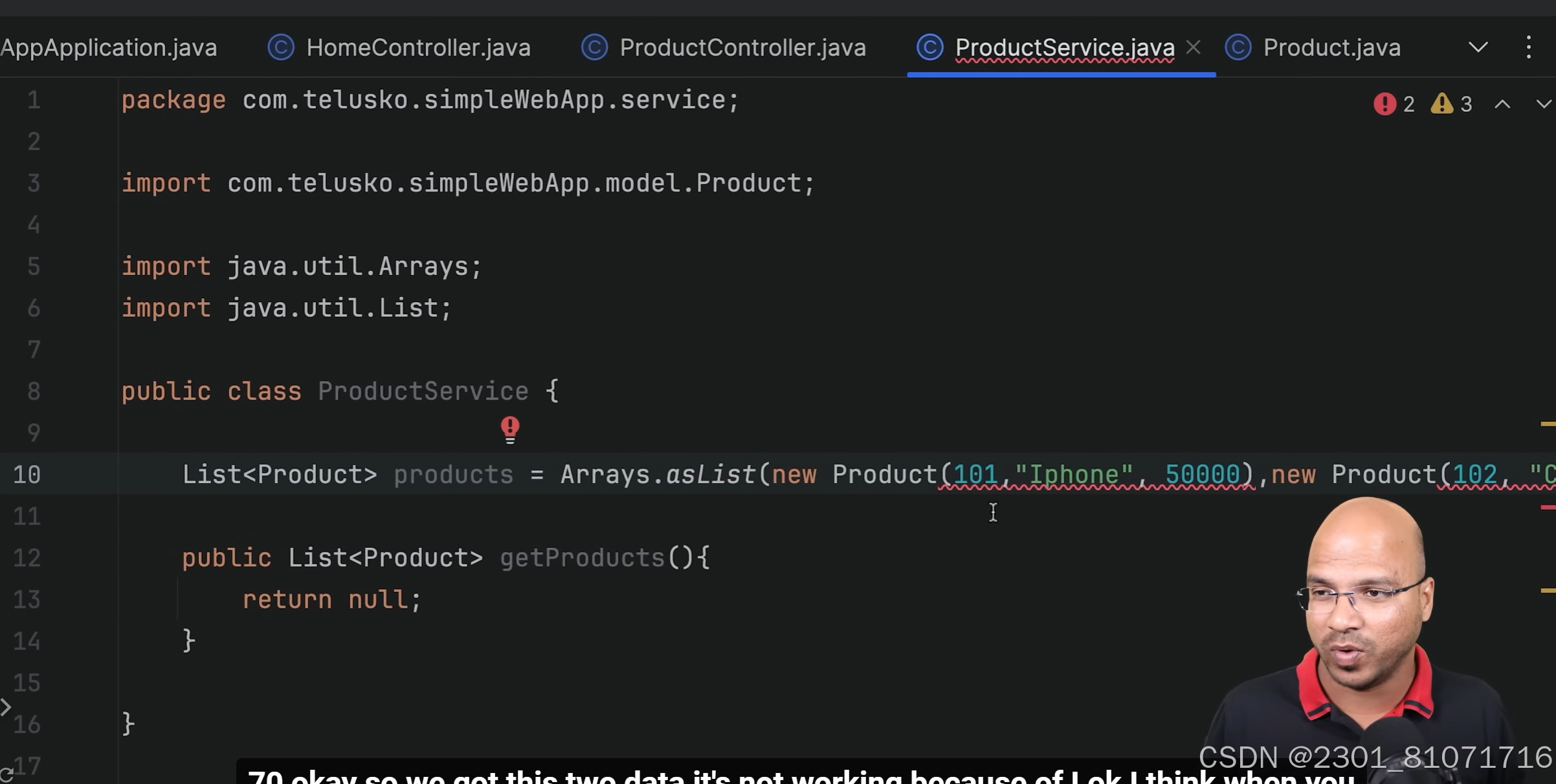
`@RequestMapping` 是 Spring MVC 中的一个注解,用于将 HTTP 请求映射到特定的处理方法上。它本身并不限制请求的方法类型,而是可以用于处理不同类型的 HTTP 请求,包括 GET、POST、PUT、DELETE 等。
当你使用 `@RequestMapping` 注解时,可以通过 `method` 属性来指定具体支持哪些 HTTP 方法。如果不指定 `method` 属性,那么默认情况下 `@RequestMapping` 会映射到所有的 HTTP 方法。
例如:
- 仅处理 GET 请求:
```java
@RequestMapping(value = "/example", method = RequestMethod.GET)
public String getExample() {
// 处理 GET 请求
}
```
- 仅处理 POST 请求:
```java
@RequestMapping(value = "/example", method = RequestMethod.POST)
public String postExample() {
// 处理 POST 请求
}
```
- 处理 GET 和 POST 请求:
```java
@RequestMapping(value = "/example", method = {RequestMethod.GET, RequestMethod.POST})
public String getOrPostExample() {
// 同时处理 GET 和 POST 请求
}
```
- 处理所有请求:
```java
@RequestMapping(value = "/example")
public String handleAllRequests() {
// 处理所有类型的 HTTP 请求
}
```
因此,`@RequestMapping` 本身并不是特定于 GET 方法的,它可以根据你的配置来处理不同类型的 HTTP 请求。如下图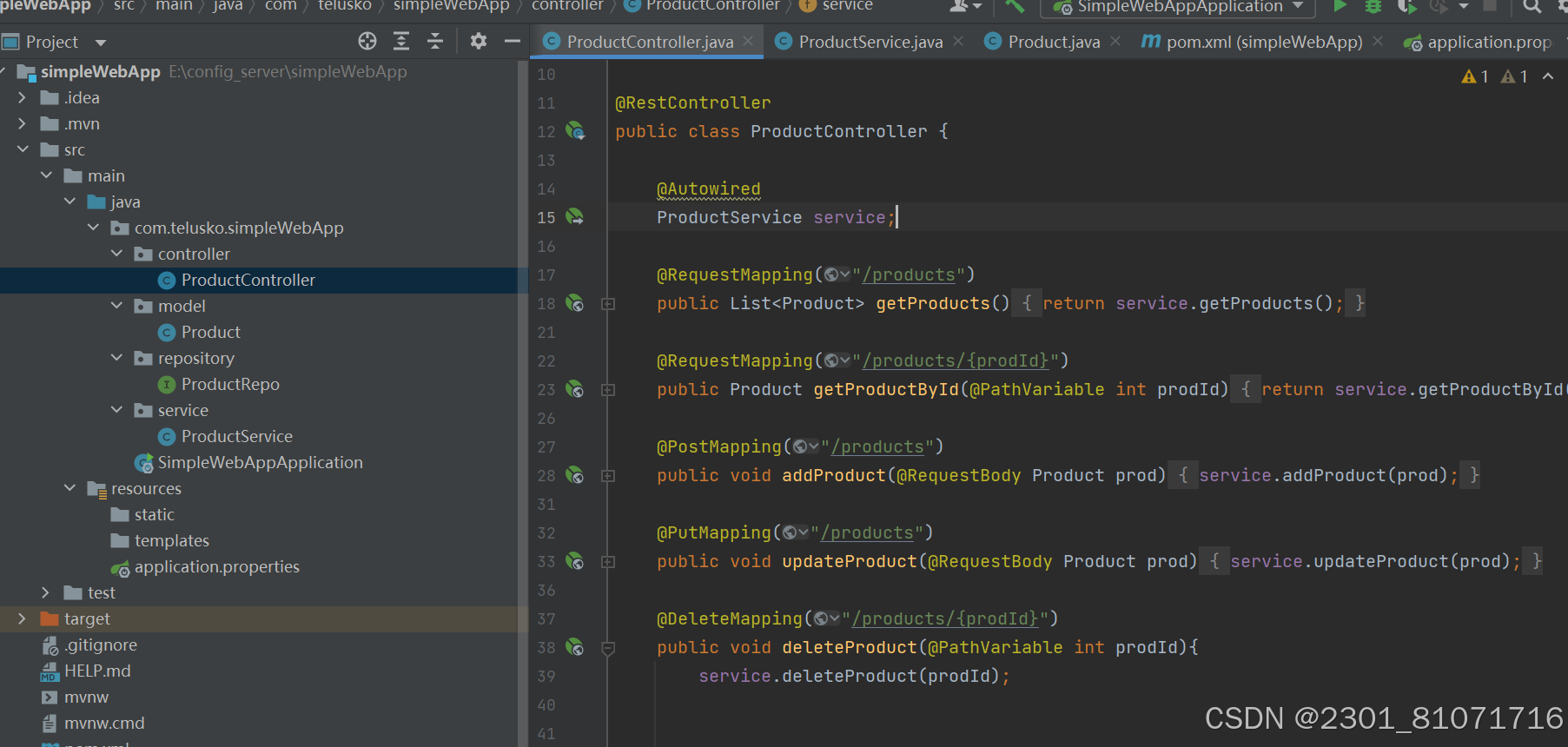
在Spring MVC框架中,`@RequestBody`和`@PathVariable`是两个非常重要的注解,它们用于处理HTTP请求中的不同部分:
1. **@RequestBody**:
- `@RequestBody`注解用于将客户端请求的Body部分(请求体)绑定到Controller中的方法参数上。这通常用于处理POST或PUT请求,这些请求的Body中包含了要发送给服务器的数据。
- 当你的方法参数是一个对象时,Spring MVC会自动将请求体中的JSON或XML数据转换成该对象。
- 例如,如果你有一个JSON格式的请求体,你可以使用`@RequestBody`注解将这个JSON映射到一个Java对象上:
```java
@PostMapping("/users")
public ResponseEntity<User> createUser(@RequestBody User user) {
// 处理用户创建逻辑
}
```
- 在这个例子中,`User`对象将被填充请求体中的数据。
2. **@PathVariable**:
- `@PathVariable`注解用于从URL模板中提取变量值,并将其作为参数传递给Controller中的方法。
- 这通常用于RESTful API设计中,当你需要根据URL路径中的特定部分来处理请求时。
- 例如,如果你有一个URL模板`/users/{userId}`,你可以使用`@PathVariable`来获取`userId`的值:
```java
@GetMapping("/users/{userId}")
public ResponseEntity<User> getUserById(@PathVariable Long userId) {
// 根据userId查找用户
}
```
- 在这个例子中,如果请求的URL是`/users/123`,那么`userId`的值将是`123`。
总结:
- `@RequestBody`用于读取请求体中的数据,并将其转换为Java对象。
- `@PathVariable`用于从URL路径中提取变量值,并将其作为参数传递给Controller方法。
这两个注解是Spring MVC处理HTTP请求的两个不同方面的工具,它们使得开发人员能够更灵活地处理不同类型的数据和请求。
下面开始说关于model层即数据库的知识:
首先连接数据库要用JDBC,即java database connectivity,但是之后server层如果要查询数据库的话,需要sql语句,即CRUD(create,read,update,delete),所以现在有一个ORM,即object relational mapping,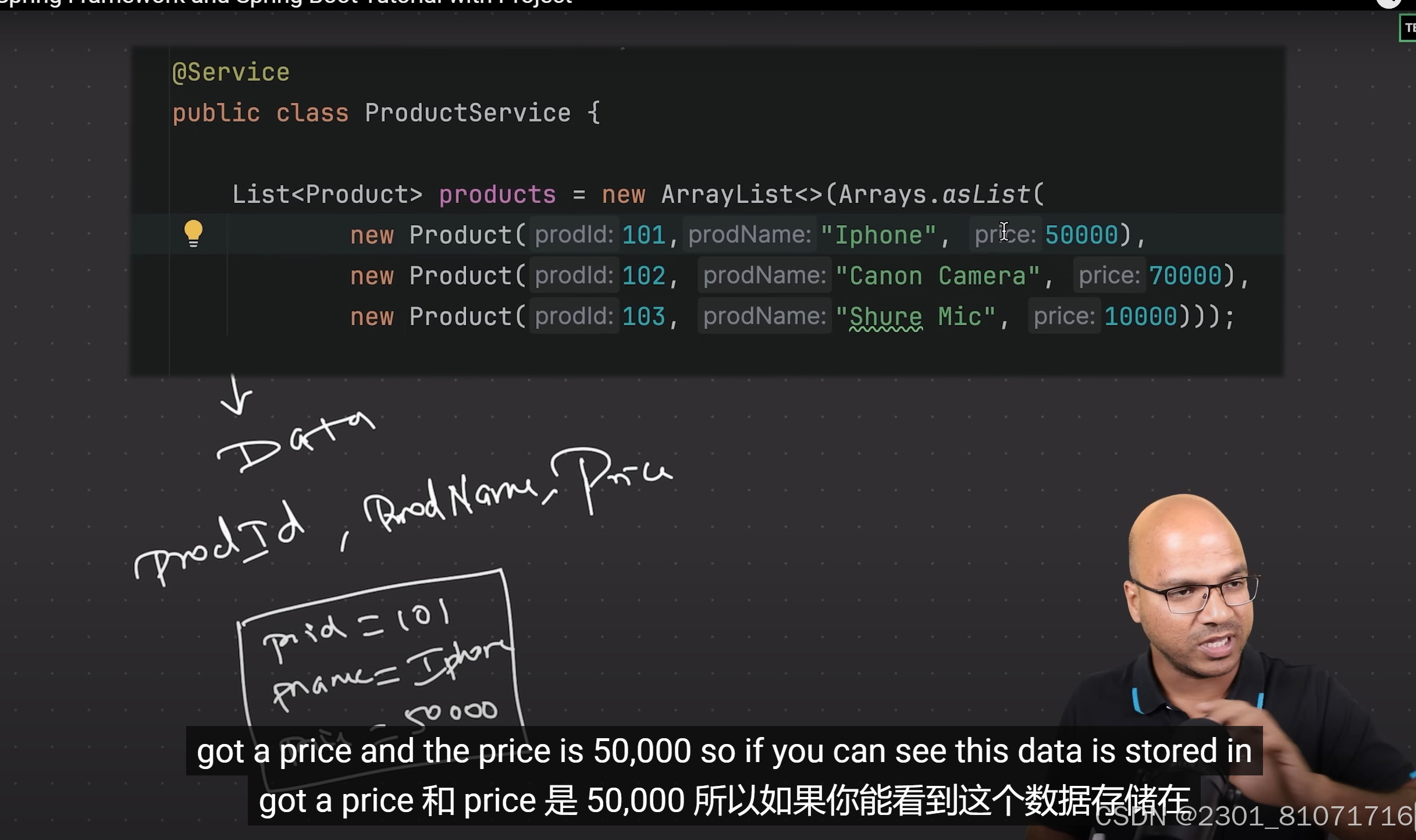
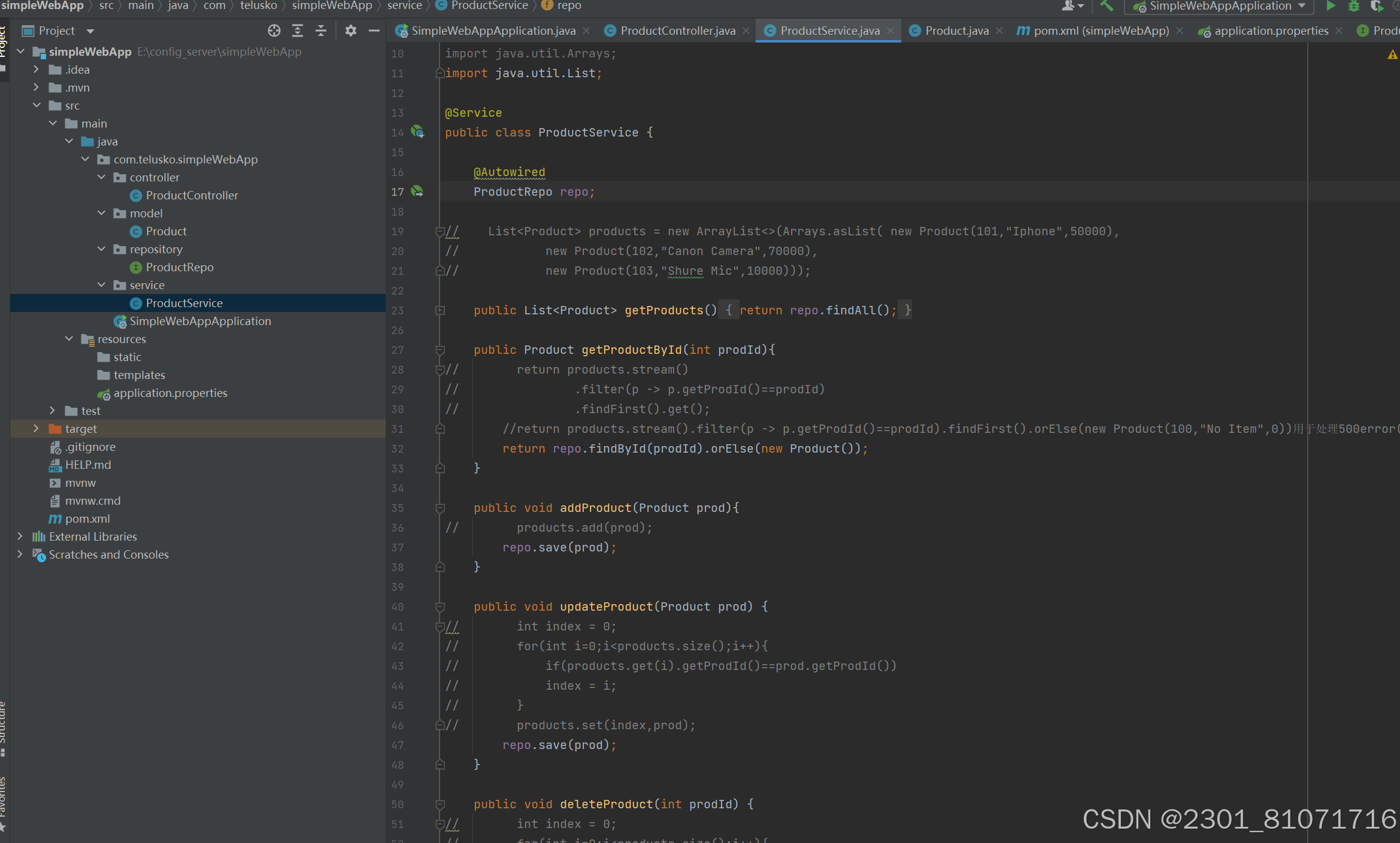
 左边是java中的class,右边是数据库中的表,二者映射由JPA,Hibemate等ORM tool来实现,比如说如果用了JAP,需要添加JPA依赖,JPA的代码放在了repository中,或者说repo中(这个类是一个接口),如下图,并且在这上面要加@Repository,之后extends了JpaRepository,里面的参数第一个是java中class的名字,第二个是Integer,这样之后在下下图中的service层中注册了这个repo后就能用了
左边是java中的class,右边是数据库中的表,二者映射由JPA,Hibemate等ORM tool来实现,比如说如果用了JAP,需要添加JPA依赖,JPA的代码放在了repository中,或者说repo中(这个类是一个接口),如下图,并且在这上面要加@Repository,之后extends了JpaRepository,里面的参数第一个是java中class的名字,第二个是Integer,这样之后在下下图中的service层中注册了这个repo后就能用了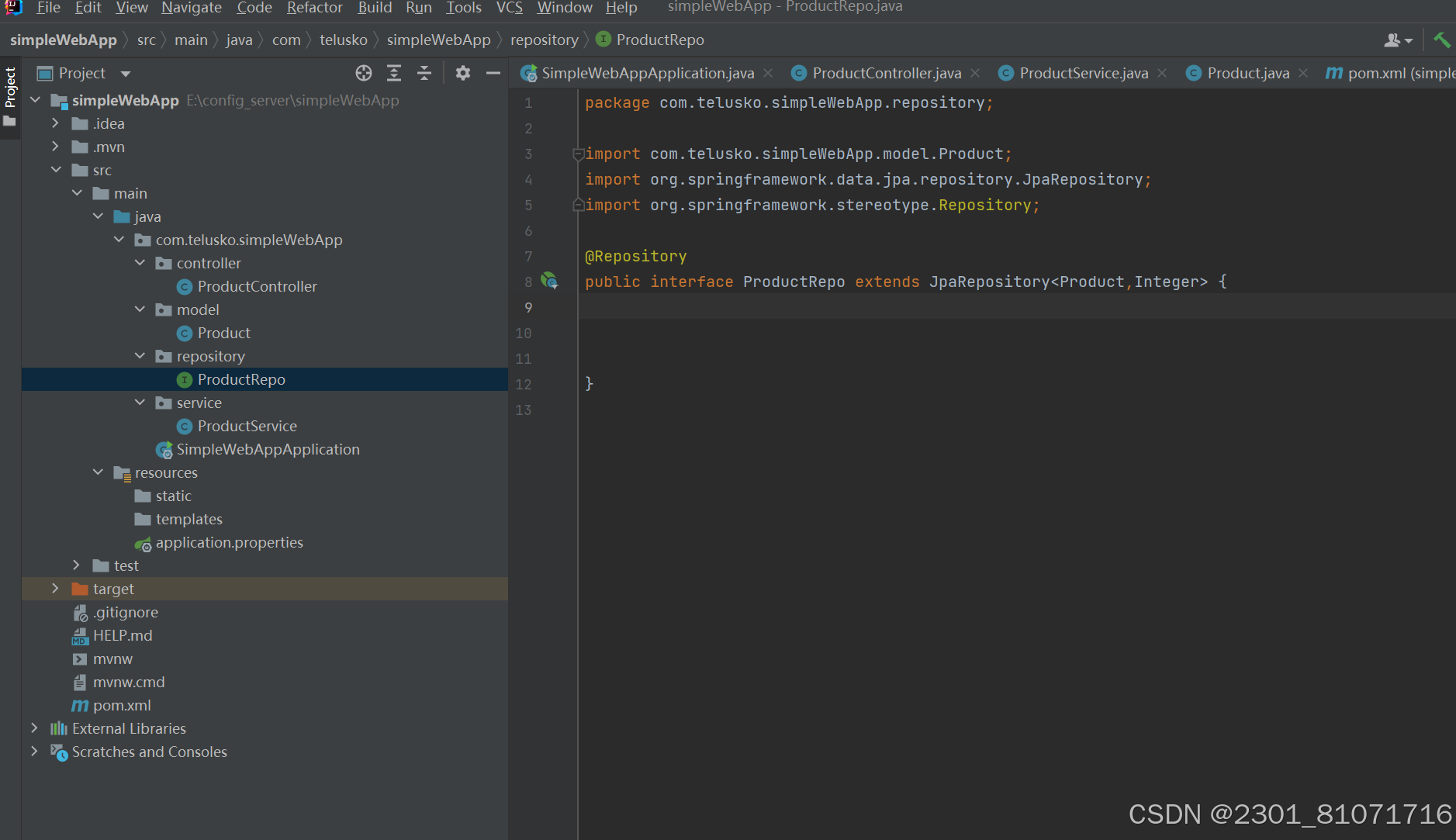
 之后是对JPA的灵魂之问及解答:
之后是对JPA的灵魂之问及解答:
问题1:图1中使用了jpa,然后定义了一个接口并且继承了一个接口,但是图二中直接16,17行直接注册了这个接口,在我之前学的知识中,不是只有一个类可以用@Autowired注册吗,为什么这个可以用接口,并且接口不是抽象方法嘛,不是需要自己创建一个类来实现这个接口中的抽象方法嘛,但是为什么也没有一个类去实现这个接口?
解答1:
在Spring框架中,`@Autowired` 注解通常用于自动注入依赖项,但它可以应用于类、接口或者具体的实现。当你在Spring中使用接口并使用`@Autowired` 注解时,Spring会查找实现了该接口的bean,并将其注入到使用该注解的地方。
在你的例子中,`ProductRepo` 是一个接口,它继承了 `JpaRepository<Product, Integer>`。`JpaRepository` 是Spring Data JPA提供的一个接口,它已经提供了许多CRUD(创建、读取、更新、删除)操作的实现。因此,你不需要自己实现这个接口的所有方法,Spring Data JPA会自动为你提供一个实现。
在Spring中,当你使用`@Autowired` 注解在一个接口上时,Spring会寻找实现了这个接口的bean。在这个例子中,Spring Data JPA会自动创建一个实现了`ProductRepo`接口的代理类,这个代理类会实现`JpaRepository`接口中定义的所有方法。这就是为什么你不需要显式地创建一个类来实现`ProductRepo`接口。
总结来说,Spring Data JPA的`JpaRepository`接口是一个特殊的接口,Spring框架会自动为你提供这个接口的实现,所以你可以直接在服务层中使用`@Autowired`来注入这个接口,而不需要自己实现它。这是Spring Data JPA提供的一个便利特性,它简化了数据访问层的开发。
问题2:那你说JpaRepository 是Spring Data JPA提供的一个接口,它已经提供了许多CRUD(创建、读取、更新、删除)操作的实现。既然提供了操作的实现,为什么还把他设计为接口,直接设计成类不完事了?难道说是因为定义接口之后我们可以自主修改其中的方法吗?
解答2:
`JpaRepository` 设计为接口而不是具体类的原因有几个:
1. **扩展性**:作为接口,`JpaRepository` 允许开发者根据需要扩展或自定义数据访问层的行为。虽然Spring Data JPA提供了许多通用的CRUD操作,但有时候开发者可能需要一些特定的查询或行为,这时候可以通过实现接口或创建自定义的查询方法来实现。
2. **解耦**:接口提供了一种解耦的方式,使得数据访问层与业务逻辑层之间的依赖关系更加清晰。业务逻辑层只需要知道`JpaRepository`接口,而不需要关心具体的实现细节。
3. **测试性**:使用接口可以更容易地进行单元测试。你可以为`JpaRepository`接口创建模拟(mock)实现,这样就可以在不依赖数据库的情况下测试业务逻辑层。
4. **多实现**:在某些情况下,你可能需要为不同类型的数据源或存储提供不同的实现。通过定义接口,你可以为每种数据源提供一个实现,而业务逻辑层仍然使用相同的接口。
5. **Spring Data JPA的约定优于配置原则**:Spring Data JPA鼓励通过方法命名约定来定义查询,而不是通过编写具体的SQL语句。这种约定允许Spring Data JPA自动生成查询,减少了样板代码,提高了开发效率。
6. **泛型支持**:`JpaRepository` 接口使用泛型,这使得它可以为不同的实体类型提供CRUD操作,而不需要为每种实体类型创建单独的接口或类。
总的来说,将`JpaRepository`设计为接口而不是具体类,是为了提供更大的灵活性和可扩展性,同时遵循Spring框架的约定优于配置原则,简化开发过程。
问题3:但是如果设计成类的话,直接extends这个类不也可以修改其中的逻辑吗
解答3:
确实,如果`JpaRepository`被设计成一个具体类,你可以通过继承这个类并重写其中的方法来修改逻辑。但是,将`JpaRepository`设计为接口而不是具体类,有几个关键的优势:
1. **避免继承限制**:在面向对象编程中,继承是一种强大的机制,但它也有其局限性。每个Java类只能继承自一个父类。如果`JpaRepository`是一个类,那么开发者就不能同时继承其他类。而接口允许多重继承,一个类可以实现多个接口。
2. **更灵活的实现**:接口允许Spring Data JPA为不同的实体类型提供不同的实现,而不需要修改原始的`JpaRepository`类。这种灵活性在处理复杂的数据访问需求时尤其有用。
3. **非侵入式**:使用接口而不是继承可以减少对Spring Data JPA的依赖。如果你的类继承了一个具体的类,那么它就与这个类紧密耦合。如果将来需要更换数据访问技术,你可能需要重写整个类。而使用接口,你只需要提供一个新的实现即可。
4. **更清晰的契约**:接口定义了一组方法,这些方法代表了数据访问层应该提供的功能。这为开发者提供了一个清晰的契约,而不需要关心实现细节。
5. **更容易的扩展**:如果需要添加新的方法到数据访问层,你只需要在接口中添加新的方法,然后提供一个实现。这比修改一个具体的类要简单得多。
6. **更好的测试性**:使用接口可以更容易地创建模拟对象(mocks)进行单元测试,而不需要实际的数据访问逻辑。
总的来说,虽然继承可以提供修改逻辑的能力,但接口提供了更多的灵活性和扩展性,这在现代软件开发中是非常重要的。Spring Data JPA的设计哲学是提供一种声明式的数据访问方式,而不是强制开发者使用特定的实现,这正是通过接口而不是具体类来实现的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









