







在使用selenium之前必须搭建好环境,搭建环境可查看文章:自动化测试-selenium-优快云博客
目录
一、浏览器基本操作
1、导入Selenium模块
# 导入selenium模块
from selenium import webdriver2、打开网站
这里以百度为例
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get('https://www.baidu.com/')3、设置休眠
time.sleep(5)
from selenium import webdriver
import time
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get('https://www.baidu.com/')
# 强制等待5秒
time.sleep(5)4、页面刷新
browser.refresh()
from selenium import webdriver
import time
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get('https://www.baidu.com/')
# 刷新页面
browser.refresh()5、前进和后退
(1)后退:browser.back()
(2)前进:browser.forward()
from selenium import webdriver
import time
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
# 打开百度界面并等待2秒
browser.get('https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面并等待2秒
browser.get('https://www.taobao.com')
time.sleep(2)
# 后退到百度页面并等待2秒
browser.back()
time.sleep(2)
# 前进到淘宝页面并等待2秒
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()6、设置窗口大小
(1)全屏:browser.maximize_window()
(2)根据分辨率调整:browser.set_window_size(width, height)
from selenium import webdriver
import time
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get('https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500, 500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000, 800)
time.sleep(2)
# 关闭浏览器
browser.close()7、截屏
browser.get_screenshot_as_file('命名.png')
注意:这里截图的文件同当前文件在一个目录下
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 浏览器截图
browser.get_screenshot_as_file('百度.png')
# 关闭浏览器
browser.close()8、退出
browser.close()
from selenium import webdriver
import time
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
time.sleep(10)
# 关闭浏览器
browser.close()9、获取页面基础属性
通过selenium打开网页后,我们就能获取到页面的title标题,current_url网页地址,name浏览器名,page_source网页源码等内容
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 实例化
browser = webdriver.Chrome()
# 访问csdn首页
browser.get('https://www.youkuaiyun.com/')
# 浏览器标题
title = browser.title
print(title)
# 浏览器地址
url = browser.current_url
print(url)
# 浏览器名
name = browser.name
print(name)
# 浏览器源码
source = browser.page_source
print(source)
二、定位页面元素
1、 打开指定页面
以熟知的百度为例,进入首页,按【F12】进入开发者工具,红框中显示的就是页面的代码,我们要做的就是从代码中定位获取我们需要的元素
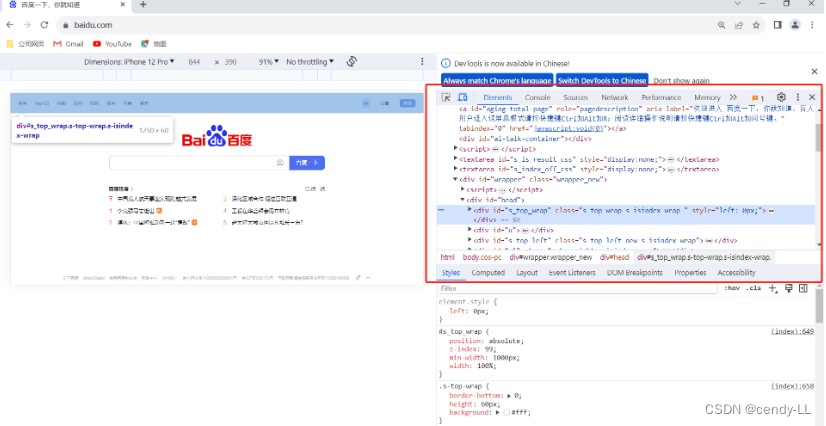
想要定位并获取页面中的信息,首先要使用 `webdriver` 打开指定页面,再去定位,即下述代码
from selenium import webdriver
# Chrome浏览器
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.maximize_window()
# 保持浏览器窗口打开,等待手动关闭
input("Press enter to exit...")下面来看看几种常见的页面元素定位方式。
注意:通过webdriver对象的find_element_by_xx(" ")(在selenium的4.0版本中此种用法即将弃用,不推荐使用),要使用通过webdriver模块中的By,以指定方式定位元素
2、 id 定位
(1)含义:id属性值与位置匹配的第一个元素将被返回
(2)写法:browser.find_element(By.ID, 'xx') ---能够帮助我们获取到id为xx的元素
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
# 访问csdn首页
browser.get('https://www.youkuaiyun.com/')
# 获取csdn首页id为toolbar-search-input的搜索框,并且输入python
browser.find_element(By.ID, 'toolbar-search-input').send_keys('Python')
# selenium4.0前版本写法
# browser.find_element_by_id('toolbar-search-input').send_keys('Python')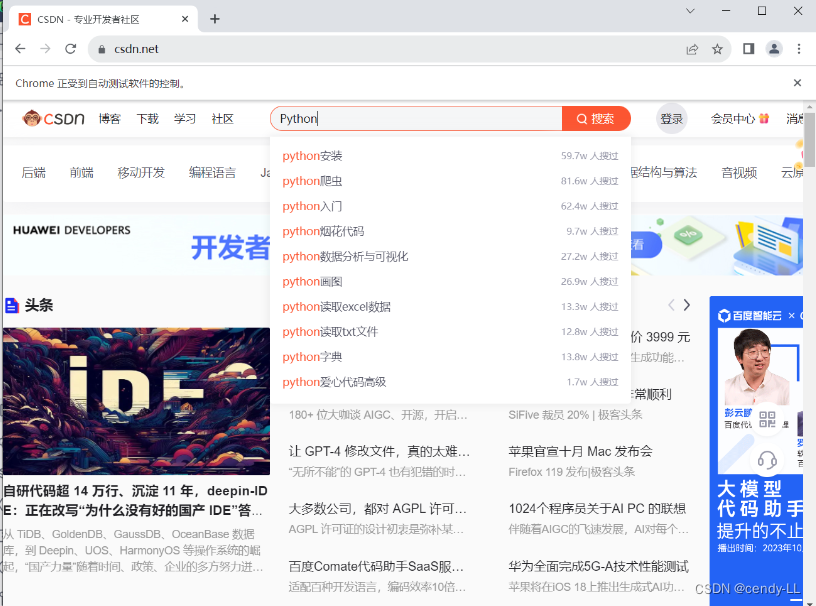
3、name 定位
(1)含义:名称属性值与位置匹配的第一个元素将被返回
(2)写法:browser.find_element(By.NAME, 'xx') ---能够帮助我们获取到name为xx的元素
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
# 访问百度首页
browser.get('https://www.baidu.com/')
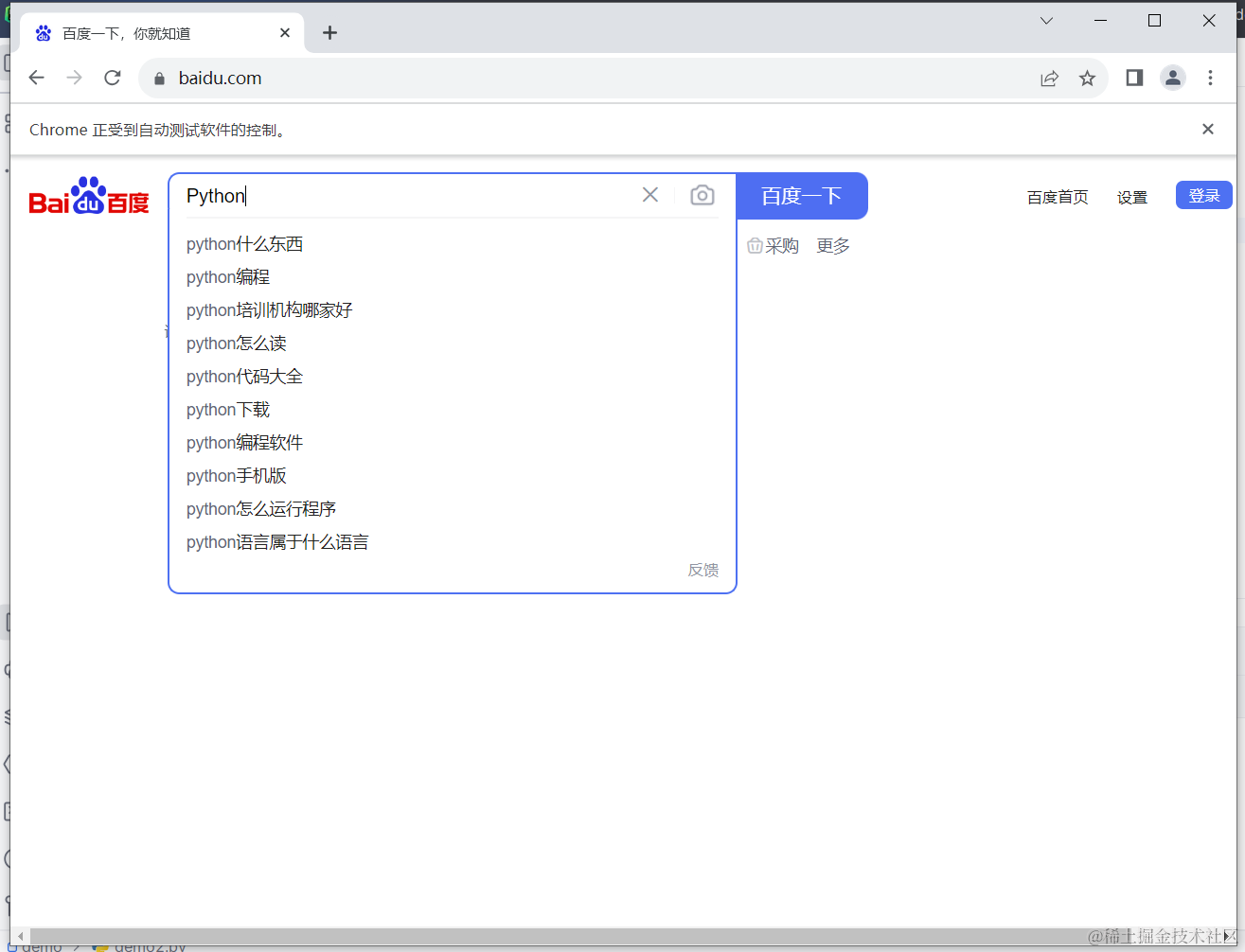
# 获取百度首页name为wd的搜索框,并且输入python
browser.find_element(By.NAME, 'wd').send_keys('Python')
time.sleep(5)
# selenium4.0前版本写法
# browser.find_element_by_name('wd').send_keys('Python')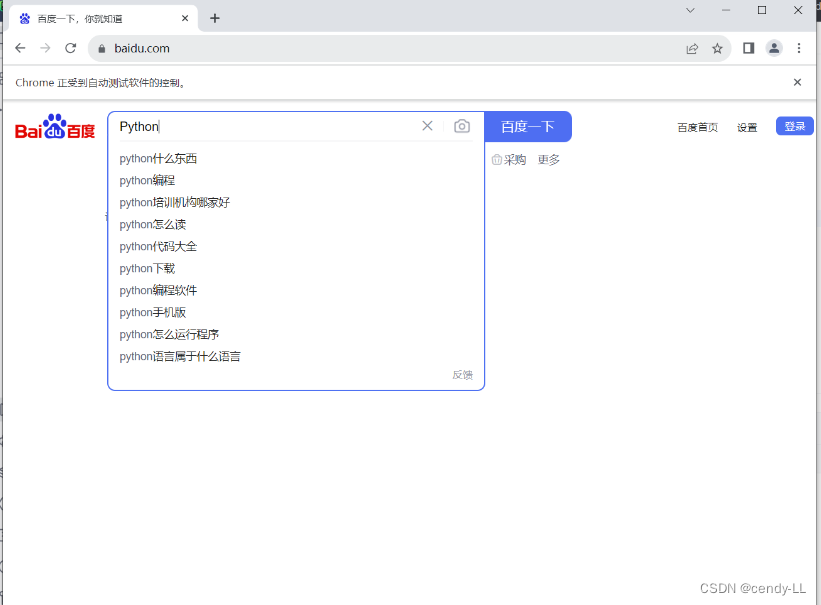
4、class 定位
(1)含义:具有匹配的类属性名称的第一个元素将被返回
(2)写法: browser.find_element(By.CLASS_NAME, 'xx') ---可以获取到网页中class名为xx的第一个元素
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
# 访问百度首页
browser.get('https://www.baidu.com/')
# 获取百度首页classname为s_ipt的搜索框,并且输入python
browser.find_element(By.CLASS_NAME, 's_ipt').send_keys('Python')
time.sleep(5)
# selenium4.0前版本写法
# browser.find_element_by_class_name('s_ipt').send_keys('Python')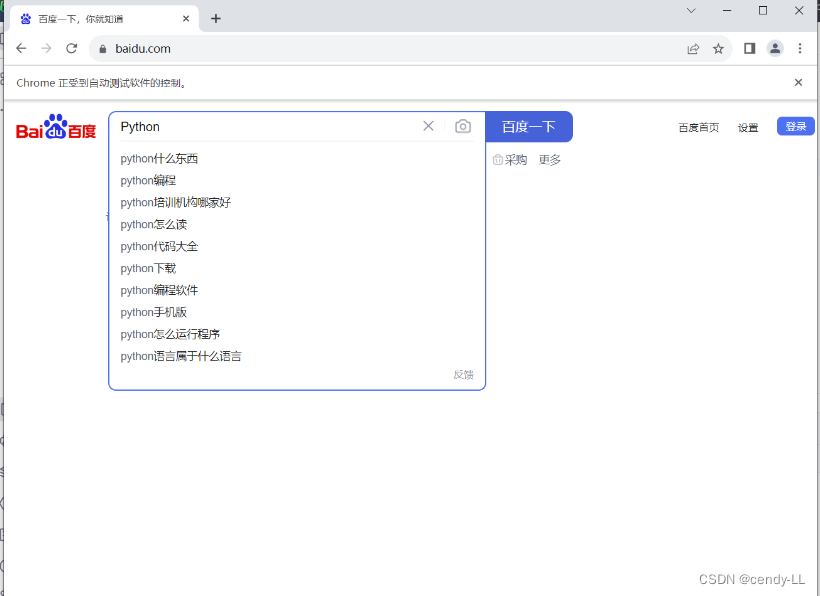
5、 tag 定位
(1)含义:具有给定标签名称的第一个元素将被返回
(2)写法:browser.find_element(By.TAG_NAME, 'xx')
(3)注意:每个元素都有tag(标签)属性,如搜索框的标签属性,input是输入,table是表格等等,我们查看百度首页的html代码,可以看到有相同的Tag,很明显相同的tag太多,一般很少用tag来做定位
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
# 访问csdn首页
browser.get('https://www.youkuaiyun.com/')
# 获取csdn首页tag为h3的文本内容
h = browser.find_element(By.TAG_NAME, 'h3').text
print(h)
# selenium4.0前版本写法
# browser.find_element_by_tag_name('h3').text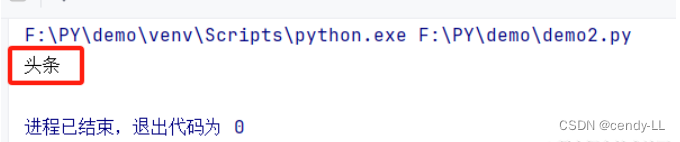
6、link 定位
(1)含义:链接文本值与位置匹配的第一个元素将被返回
(2)写法:browser.find_element(By.LINK_TEXT, 'xx')
(3)下面例子为获取到百度首页左上角的新闻链接并触发点击事件
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
# 访问百度首页
browser.get('https://www.baidu.com/')
# 获取百度首页link内容为新闻的链接,并点击
browser.find_element(By.LINK_TEXT, '新闻').click()
time.sleep(5)
# selenium4.0前版本写法
# browser.find_element_by_link_text('新闻').click()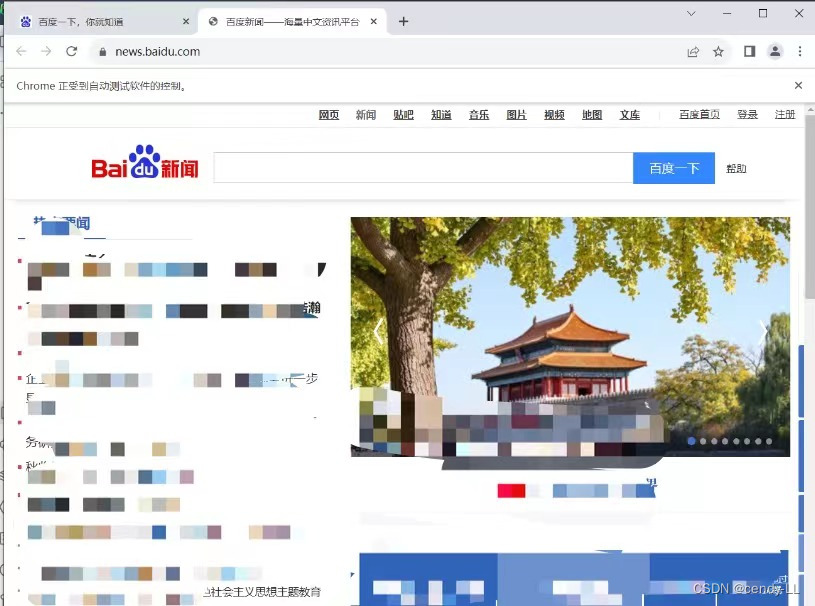
7、partial_link 定位
(1)含义:具有部分链接文本值与位置匹配的第一个元素将被返回
(2)相当于link定位的模糊搜索方法,一般一个链接文本都很长,要是全部都输入就太麻烦了,所以我们只需要输入关键词来进行匹配即可
(3)写法:browser.find_element(By.PARTIAL_LINK_TEXT, 'xx')
(4)下面例子是用csdn的首页“下载·课程”来做示例,我们只需要定位“课程”,然后触发点击
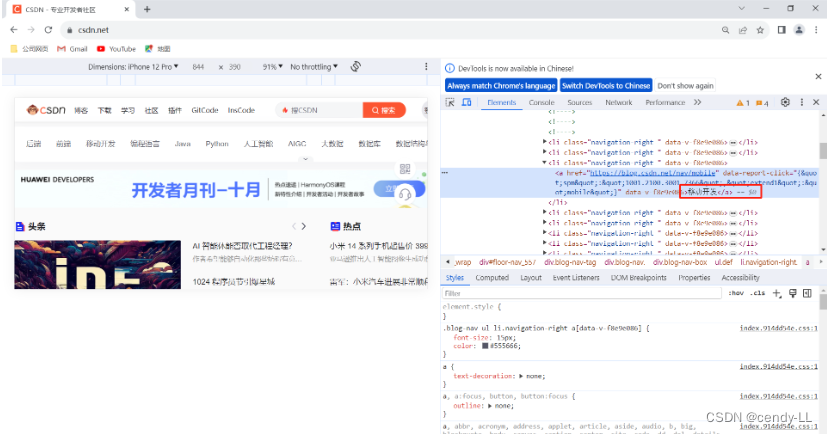
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
# 访问csdn首页
browser.get('https://www.youkuaiyun.com/')
# 获取csdn首页link内容为开发的模糊检索链接,并点击
browser.find_element(By.PARTIAL_LINK_TEXT, '开发').click()
time.sleep(5)
# selenium4.0前版本写法
# browser.find_element_by_partial_link_text('开发').click()
8、Xpath定位
(1)含义:xpath语法与位置匹配的第一个元素将被返回
(2)注意:前面介绍的id定位、name定位、tap定位、link定位都是比较理想化的定位方式,对于简单的网站来说使用起来效果不错,前提是这些内容都是唯一的,id唯一、name唯一、tap唯一、link内容唯一等,但是对于大型网站来说,就显得力不从心了,所以我们就要用更强大的定位工具xpath
(3)写法:browser.find_element(By.XPATH, "xx")
(4)xpath获取
- 使用浏览器打开需测试的网址,然后点击【F12】按钮,打开开发者调试工具
- 点击开发者工具中左上角的左上箭头,点击要定位元素,右侧会出现相关源代码
- 在相关源代码上点击右键,Copy--->Copy Xpath,就获取到对应的Xpath了
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
# 访问csdn首页
browser.get('https://www.youkuaiyun.com/')
# 获取csdn首页,通过xpath检索搜索框,并输入python内容
browser.find_element(
By.XPATH, "//*[@id='toolbar-search-input']").send_keys('Python')
time.sleep(5)
# selenium4.0前版本写法
# browser.find_element_by_xpath("//*[@id='toolbar-search-input']").send_keys('Python')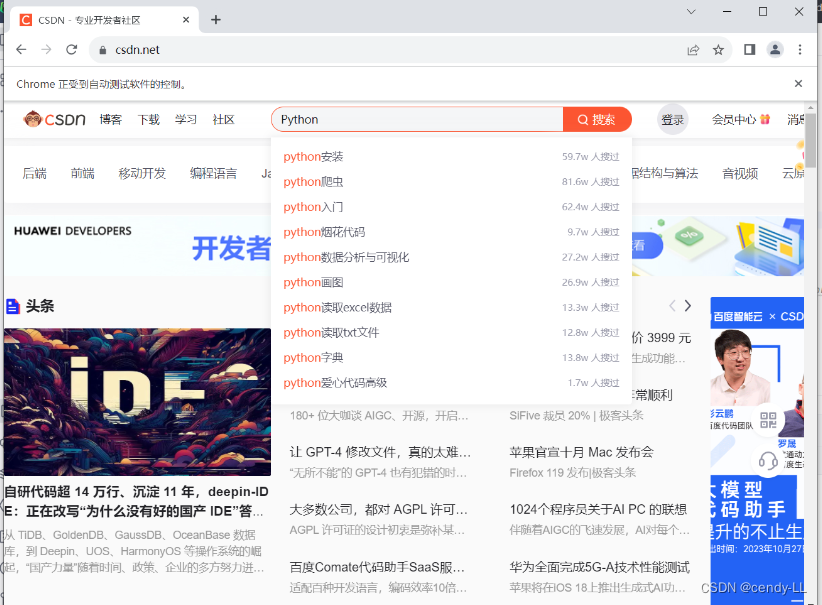
9、css 定位
(1)含义:具有匹配的CSS选择器的第一个元素将被返回
(2)写法:browser.find_element(By.CSS_SELECTOR, "#xx") ----前面有个#号
(3)优点:使用CSS定位方法会比xpath更加简洁,效率更高
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
# 访问csdn首页
browser.get('https://www.youkuaiyun.com/')
# 获取csdn首页,通过css写法,获取id为toolbar-search-input的搜索框
browser.find_element(By.CSS_SELECTOR, "#toolbar-search-input") .send_keys('Python')
time.sleep(5)
# selenium4.0前版本写法
# browser.find_element_by_css_selector('#toolbar-search-input').send_keys('Python')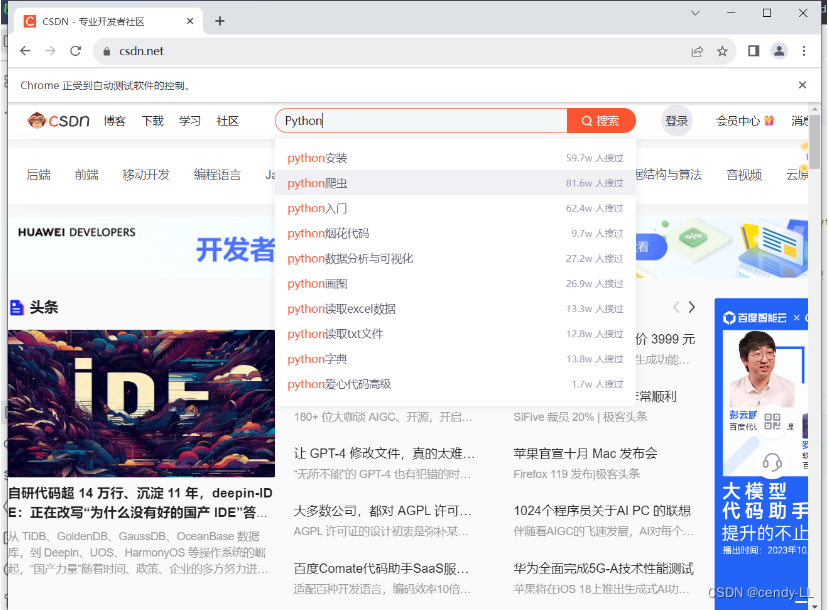
三、鼠标控制
1、单击左键
(1)含义:模拟完成单击鼠标左键的操作,一般点击进入子页面等会用到,左键不需要用到 `ActionChains`
(2)写法:click()
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
# 访问csdn首页
browser.get('https://www.youkuaiyun.com/')
# 获取csdn首页,通过css写法,获取id为toolbar-search-input的搜索框
browser.find_element(By.CSS_SELECTOR, "#toolbar-search-input") .send_keys('Python')
# 定位搜索按钮
button = browser.find_element(By.XPATH,'//*[@id="toolbar-search-button"]/span')
# 执行单击操作
button.click()
time.sleep(10)
# selenium4.0前版本写法
# browser.find_element_by_css_selector('#toolbar-search-input').send_keys('Python')
2、单击右键
(1)含义:鼠标右击的操作与左击有很大不同,需要使用 `ActionChains`
(2)写法:ActionChains(browser).context_click(button).perform()
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import time
browser = webdriver.Chrome()
# 访问csdn首页
browser.get('https://www.youkuaiyun.com/')
# 定位搜索按钮
button = browser.find_element(By.XPATH,'//*[@id="toolbar-search-button"]/span')
# 右键搜索按钮
ActionChains(browser).context_click(button).perform()
time.sleep(10)
# selenium4.0前版本写法
# browser.find_element_by_css_selector('#toolbar-search-input').send_keys('Python')3、双击
模拟鼠标双击操作
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import time
browser = webdriver.Chrome()
# 访问csdn首页
browser.get('https://www.youkuaiyun.com/')
# 定位搜索按钮
button = browser.find_element(By.XPATH,'//*[@id="toolbar-search-button"]/span')
# 执行双击动作
ActionChains(browser).double_click(button).perform()
time.sleep(10)
4、拖动
模拟鼠标拖动操作,该操作有两个必要参数:
- source:鼠标拖动的元素
- target:鼠标拖至并释放的目标元素
# 定位要拖动的元素
source = driver.find_element(By.XPATH,'xxx')
# 定位目标元素
target = driver.find_element(By.XPATH,'xxx')
# 执行拖动动作
ActionChains(driver).drag_and_drop(source, target).perform()5、鼠标悬停
模拟悬停的作用一般是为了显示隐藏的下拉框,如图
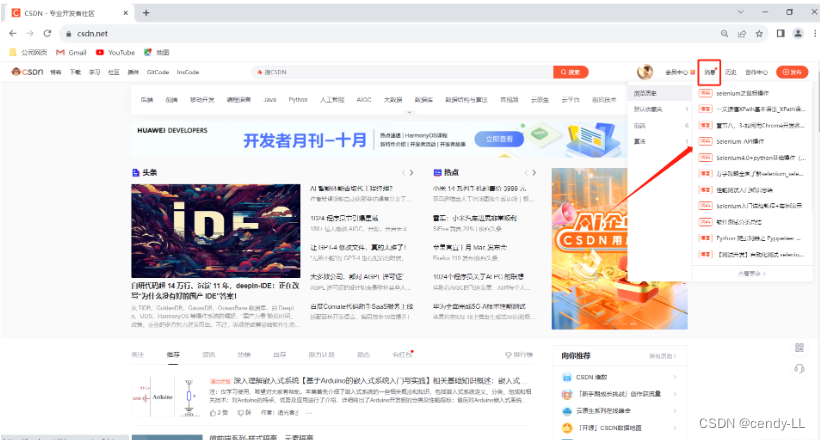
# 定位前端栏
collect = browser.find_element(By.XPATH,'//*[@id="floor-nav_557"]/div/div/div/ul/li[2]/a')
# 鼠标悬停至前端标签处
ActionChains(browser).move_to_element(collect).perform()四、键盘控制
1、前言
在 Selenium 模块中,提供了一个 Keys 类,来处理键盘操作
在 Selenium 模块中,使用 send_keys() 方法,来模拟键盘输入
# 添加包
from selenium.webdriver.common.keys import Keys2、keys类常用方法
| 序号 | Keys类键盘事件 | 实现功能 |
| 1 | Keys.BACK_SPACE | 删除键 |
| 2 | Keys.SPACE | 空格键 |
| 3 | Keys.TAB | Tab键 |
| 4 | Keys.ESCAPE | 回退键 |
| 5 | Keys.ENTER | 回车键 |
| 6 | Keys.CONTROL,”a” | 组合键,Ctrl + A |
| 7 | Keys.CONTROL,”x” | 组合键,Ctrl + X |
| 8 | Keys.CONTROL,”v” | 组合键,Ctrl + V |
| 9 | Keys.CONTROL,”c” | 组合键,Ctrl + C |
| 10 | Keys.F1/F12 | F1/F12键 |
| 11 | Keys.SHIFT | 大小写转换键 |
| 12 | Keys.CONTROL | Control键 |
| 13 | Keys.ALT | ALT键 |
| 14 | Keys.PAGE_UP | 翻页键上 |
| 15 | Keys.PAGE_DOWN | 翻页键下 |
| 16 | Keys.END | 行尾键 |
| 17 | Keys.HOME | 行尾键 |
| 18 | Keys.LEFT | 方向键左 |
| 19 | Keys.UP | 方向键上 |
| 20 | Keys.RIGHT | 方向键右 |
| 21 | Keys.DOWN | 方向键下 |
| 22 | Keys.INSERT | 插入键 |
| 23 | Keys.NUMPAD0 ~ NUMPAD9 | 数字键1-9 |
3、操作案例
(1)需求描述:
打开百度浏览器 输入python , Ctrl+a-全选 , Ctrl+x-剪切 , Ctrl+v-粘贴,按下回车键
(2)代码
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
browser = webdriver.Chrome()
browser.get("http://baidu.com/")
# 定位到输入框
inputBaidu = browser.find_element(By.ID, 'kw')
# 在输入框输入python
inputBaidu.send_keys("python")
inputBaidu.send_keys(Keys.SPACE) # 再输入一个空格
time.sleep(3)
inputBaidu.send_keys(Keys.CONTROL, 'a') # Ctrl+a 模拟全选
time.sleep(3)
inputBaidu.send_keys(Keys.CONTROL, 'x') # Ctrl+x 模拟剪切
time.sleep(3)
inputBaidu.send_keys(Keys.CONTROL, 'v') # Ctrl+v 模拟粘贴
time.sleep(3)
inputBaidu.send_keys(Keys.ENTER) # 模拟回车
time.sleep(3)
(3)实现效果:
这里暂不展示了,感兴趣的小伙伴可以手动操作下,查看效果
五、切换句柄
1、前言
有些网站页面在点开链接后会出现新的窗口,但是浏览器对象 browser(driver) 还是之前页面的对象,针对此问题,需要切换到不同的窗口进行操作,Selenium 模块提供了 switch_to.window() 方法-切换句柄 和 window_handles 属性-获取句柄列表
2、方法
(1)获取当前窗口句柄:`browser.current_window_handle`
(2)获取所有句柄:`browser.window_handles`
(3)切换句柄:`browser.switch_to.window()`
(4)关闭当前句柄:`browser.close()`
(5)关闭浏览器:`browser.quit()`
3、使用流程
(1)先创建浏览器对象:browser = webdriver.Chrome()
(2)先获取当前所有句柄(列表):all_handles = browser.window_handles
(3)再切换到指定句柄(利用列表下标索引取值):browser.switch_to.window(all_handles[1])
4、实现案例
(1)需求描述
打开百度界面,点击界面左上角的新闻切换至新闻窗口
(2)代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
handles = []
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
time.sleep(5)
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
# 点击 python,进入分类页面
driver.find_element(By.XPATH,'//*[@id="s-top-left"]/a[1]').click()
# 切换窗口
driver.switch_to.window(driver.window_handles[1])
time.sleep(5)
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
print(handles)
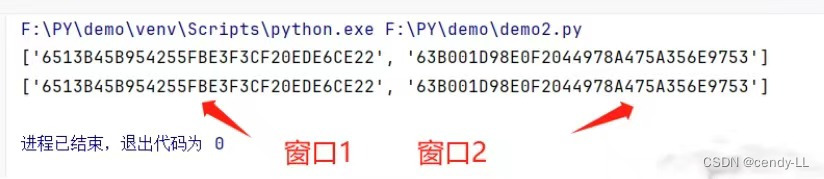
print(driver.window_handles)(3)结果
上面代码在点击跳转后,使用 `switch_to.window` 切换窗口,`window_handles` 返回的 `handle` 列表是按照页面出现时间进行排序的,最新打开的页面肯定是最后一个,两次列表的抓取都不一致,说明已经跳转到最新页面了
五、切换操作
1、窗口切换
即第五章的切换窗口句柄
2、表单切换
(1)什么是表单:就是使用iframe/frame,引用了其他页面的链接,真正的页面数据并没有出现在当前源码中,但是在浏览器中我们看到,简单理解可以使页面中开了一个窗口显示另一个页面
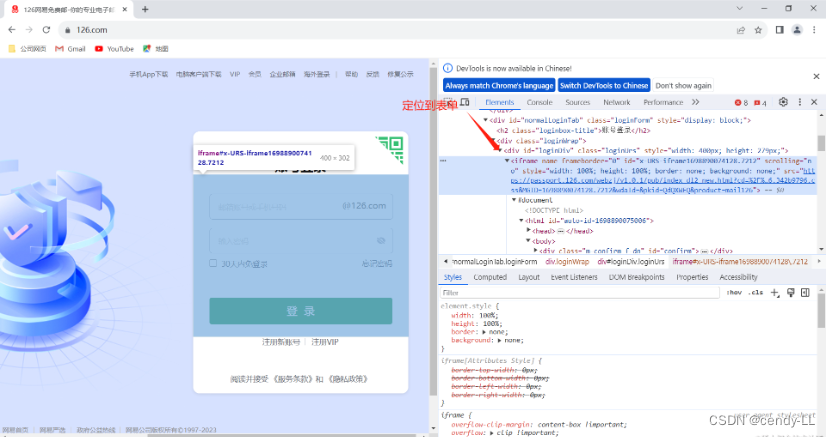
(2)前言:在web自动化测试中,我们经常会碰到frame表单嵌套结构,直接定位会报错,因此需要切换表单后才能成功定位,比如一个登录网站,如下图
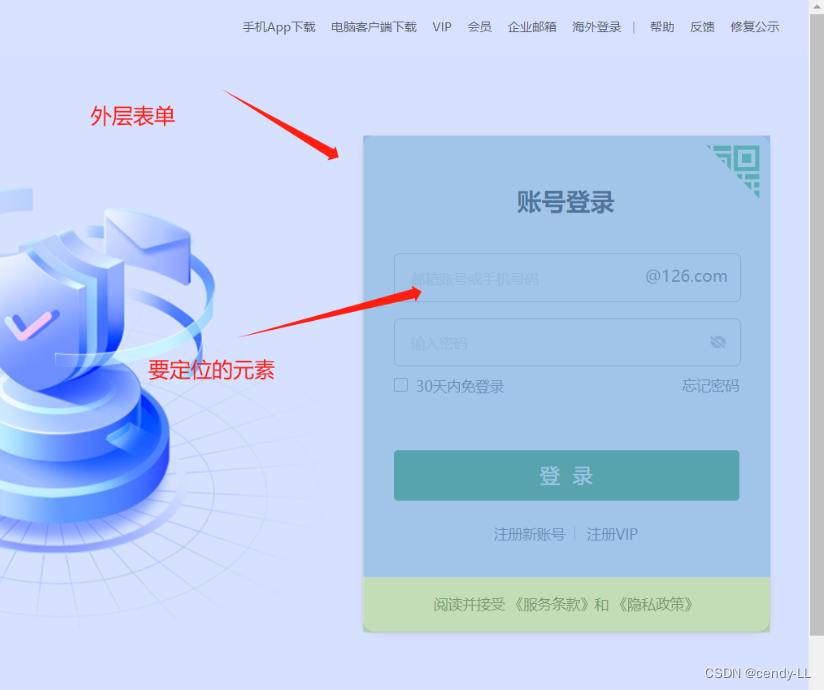
webdriver只能在一个页面上对元素识别与定位,对于frame/iframe表单内嵌页面上的元素无法直接定位,这时就需要通过switch_to_frame()方法将当前定位的主体切换为内嵌表单
(3)方法:将当前定位的主体切换进表单后再进行定位
- driver.switch_to.frame()--------------------切换进表单
- driver.switch_to.default_content()---------跳回最外层的页面
- driver.switch_to.parent_frame()------------跳回上层的页面
(4)举例说明
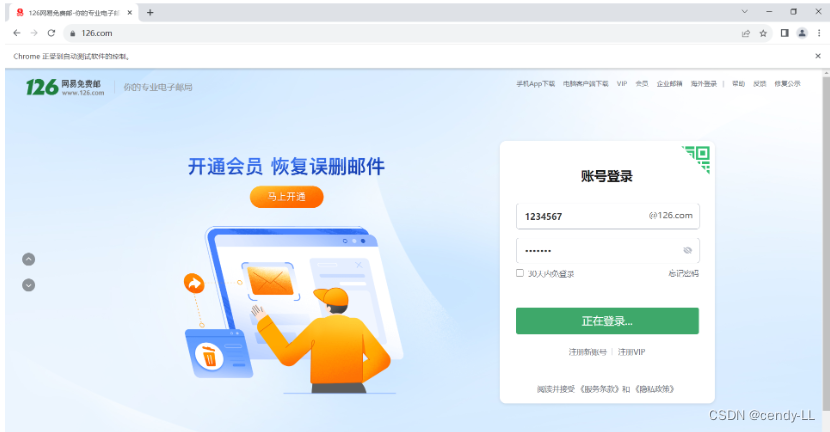
以邮箱为例,先定位到表单,再切换进入表单,定位账号、密码并输入,点击登陆
代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome()
driver.get('http://126.com/')
# 界面最大化
driver.maximize_window()
# 防止加载太快
time.sleep(5)
# 定位到表单
el_frame = driver.find_element(By.TAG_NAME,'iframe')
# 切换进入表单中
driver.switch_to.frame(el_frame)
# 在表单中定位账号输入框
el_user = driver.find_element(By.NAME,'email')
# 输入账号(自己的账号)
el_user.send_keys('1234567')
# 定位密码输入框标签
el_pwd = driver.find_element(By.NAME,'password')
# 输入密码(自己的密码)
el_pwd.send_keys('8765tre')
# 定位登陆按钮
el_sub = driver.find_element(By.ID,'dologin')
# 点击登录
el_sub.click()
time.sleep(5)
driver.close()结果图如下:
六、弹窗处理
1、JavaScript三种弹出对话框的简单介绍
JavaScript的三种对话框是通过调用 "window对象" 的三个方法 "alert()"、"confirm()" 、"prompt()" 来获得,我们可以利用这些对话框来完成 "js" 的输入和输出,实现与用户进行交互的js代码
(1)alert() - 警告框
定义:alert是一个警告框,表现为直接弹出一个提示窗,该提示窗只有一个按钮确定按钮,点击【确定】按钮后无返回值,alert警告框经常被用于确保用户可以得到某些信息;当警告框出现后,用户需要点击确定按钮才能继续进行操作
语法:alert("文本")
代码示例:
<html>
<head>
<title></title>
<a id="tooltip" href="#" data-toggle="tooltip" title="这是一个警告框" onclick="alert(this.title);">点击(弹出警告)</a>
</head>
</html>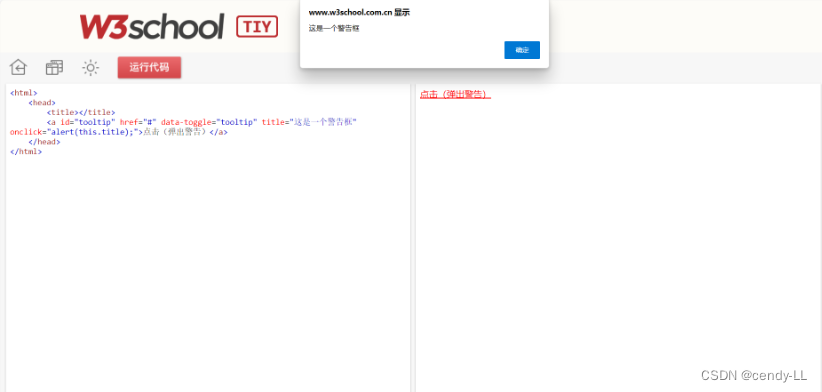
(2)confirm() - 确认框
定义:confirm是确认框,它有两个按钮,确定 与 取消 ,返回 true 或 false 。确认框用于让用户可以验证或者接受某些信息。当确认框出现后,用户需要点击确定或者取消按钮才能继续进行操作。如果用户点击确认,那么返回值为 true;如果用户点击取消,那么返回值为 false。
语法:confirm("文本")
代码示例:
<html>
<head>
<title>confirm</title>
</head>
<body>
<script language="JavaScript">
if(confirm("准备好了么?")){
alert("准备好了!");
}
else{
alert("不,我还需要再做些准备!");
}
</script>
</body>
</html>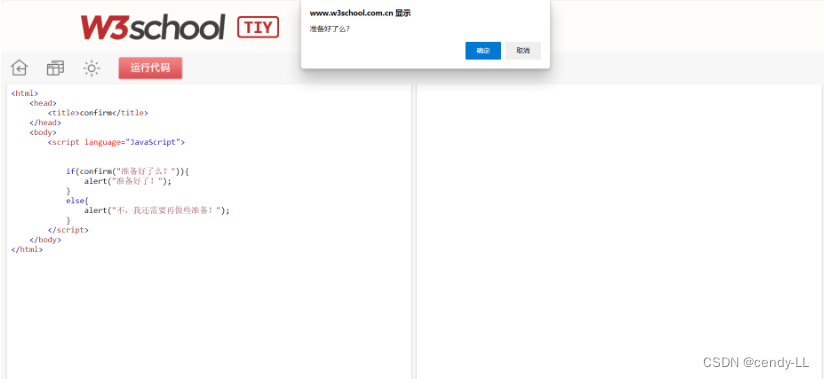
(3)prompt() - 提示框
定义:prompt是提示框,它会返回输入框输入的消息,或者其默认值;提示框经常用于提示用户在进入页面前输入某个值。当提示框出现后,用户需要输入某个值,然后点击确认或取消按钮才能继续操纵。如果用户点击确认,那么返回值为输入的值;如果用户点击取消,那么返回值为 null
语法:prompt("文本","默认值")
代码示例:
<html>
<head>
</head>
<body>
<script language='JavaScript' type="text/javascript" >
var aa= prompt("你叫什么名字?","cendy");document.write("Welcome to my world, "+aa+"<br>")
</script>
</body>
</html>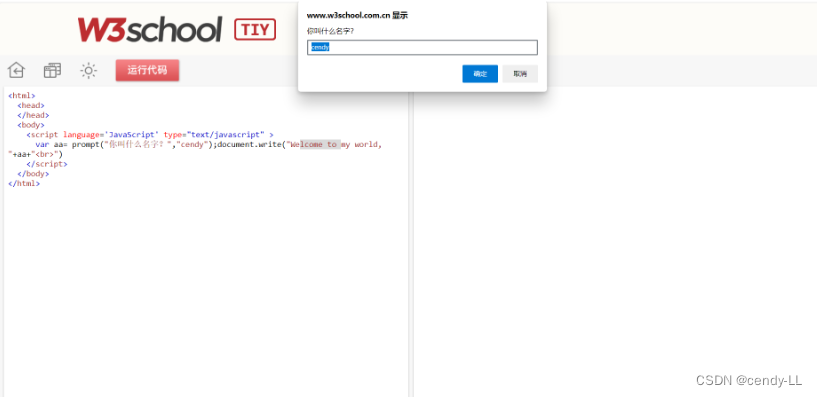
2、selenium 处理弹出对话框的常用方法
处理方法:首先选择到目标对话框,接着对对话框进行接受/取消/返回信息/输入文字等操作
常用方法如下:
- driver.switch_to.alert------------选择alert对话框
- text----------------------------------返回 alert、confirm、prompt 里面的文字信息
- accept------------------------------接受
- dismiss-----------------------------取消
- send_keys-------------------------向 prompt 里面输入文字
(1)selenium 处理 alert() 弹窗
弹窗页面同第1点
代码示例:
from time import sleep
from selenium import webdriver
from selenium.webdriver.chrome.webdriver import WebDriver
from selenium.webdriver.common.by import By
driver: WebDriver = webdriver.Chrome() # 启动 Chrome浏览器的 driver
driver.maximize_window() # Chrome 浏览器最大化
sleep(2)
driver.get('file:///F:/DEMO/alert.html') # 打开对应文件
sleep(2)
driver.find_element(By.ID,'tooltip').click() # 点击页面 id='tooltip' 的元素(会弹出alert)
sleep(2)
alert = driver.switch_to.alert # 选择 alert
print(alert.text) # 打印输出 alert 的内容
alert.accept() # 针对 alert 执行 accept(接受)方法
sleep(2)
driver.quit()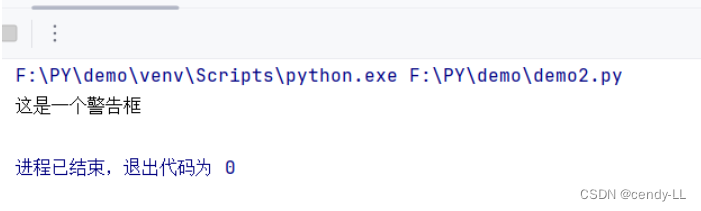
(2)selenium 处理 confirm() 弹窗
弹窗页面同第1点
代码示例:
from time import sleep
from selenium import webdriver
from selenium.webdriver.chrome.webdriver import WebDriver
from selenium.webdriver.common.alert import Alert
driver: WebDriver = webdriver.Chrome() # 启动 Chrome浏览器的 driver
driver.maximize_window() # Chrome 浏览器最大化
sleep(2)
driver.get('file:///F:/DEMO/confirm.html') # 打开对应文件
sleep(2)
# 下面是执行拒绝的方法
confirm = driver.switch_to.alert # 不管是 alert 还是 confirm、prompt ,"switch_to" 的方式是一样的
print(confirm.text) # 打印输出 "confirm" 的内容
sleep(2)
confirm.dismiss() # 针对 confirm 执行 dismiss(取消)方法
sleep(2)
confirm1 = driver.switch_to.alert
print(confirm1.text)
# 下面是执行接受的方法
# alert = driver.switch_to.alert # 选择 confirm 执行 accept(接受)方法后的 alert
# print(alert.text) # 打印输出 alert 的内容
# sleep(2)
# alert.accept() # 针对 alert 执行 accept(接受)方法
# alert1 = driver.switch_to.alert
# print(alert1.text)
# sleep(2)
driver.quit()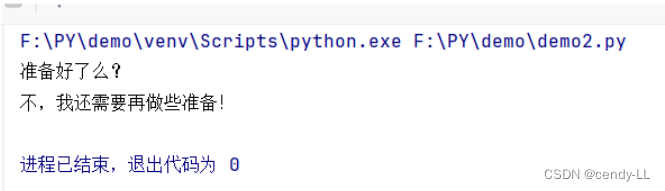
selenium 处理 confirm() 弹窗时,执行接受/取消的操作互相冲突,只能分批执行
上文的脚本中,我们通过 switch_to 的方法选择 alert 略显得麻烦一些,能不能直接通过 confirm 把它当成一个来处理呢——可以只选择一次,后续直接调用(减少了代码冗余)
话不多说,直接上代码
from time import sleep
from selenium import webdriver
from selenium.webdriver.chrome.webdriver import WebDriver
from selenium.webdriver.common.alert import Alert
driver: WebDriver = webdriver.Chrome() # 启动 Chrome浏览器的 driver
driver.maximize_window() # Chrome 浏览器最大化
sleep(1)
driver.get('file:///F:/DEMO/confirm.html') # 打开对应文件
sleep(1)
# 下面是执行拒绝的方法
# confirm = driver.switch_to.alert # 不管是 alert 还是 confirm、cprompt ,"switch_to" 的方式是一样的
# print(confirm.text) # 打印输出 "confirm" 的内容
# sleep(1)
# confirm.dismiss() # 针对 confirm 执行 dismiss(取消)方法
# sleep(1)
# print(confirm.text)
# 下面是执行接受的方法
confirm = driver.switch_to.alert # 不管是 alert 还是 confirm、cprompt ,"switch_to" 的方式是一样的
print(confirm.text) # 打印输出 "confirm" 的内容
confirm.accept() # 针对 alert 执行 accept(接受)方法
print(confirm.text)
sleep(1)
driver.quit()(3)selenium 处理 prompt() 弹窗
弹窗组件 - prompt(),页面可参考第1点,有一个输入框、两个按钮,可以选择确定或取消
代码示例:
from time import sleep
from selenium import webdriver
from selenium.webdriver.chrome.webdriver import WebDriver
from selenium.webdriver.common.alert import Alert
driver: WebDriver = webdriver.Chrome() # 启动 Chrome浏览器的 driver
driver.maximize_window() # Chrome 浏览器最大化
sleep(1)
driver.get('file:///F:/DEMO/prompt.html') # 打开对应文件
sleep(1)
prompt = driver.switch_to.alert # 不管是 alert 还是 confirm、cprompt ,"switch_to" 的方式是一样的
print(prompt.text) # 打印输出 "confirm" 的内容
sleep(1)
prompt.send_keys('I LOVE YOU!') # "prompt.html" 文件默认输入框里传入的是 "cendy" ,这里我们传入 "I LOVE YOU!"
prompt.accept()
sleep(1)
driver.quit()
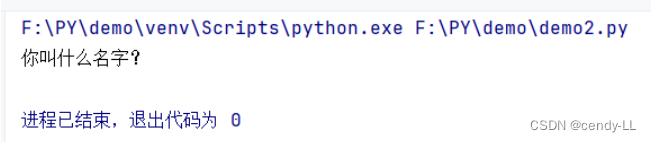
从截图中我们可以看到打印输出的内容并没有我们输入的内容,与之前文章的 `send_keys` 不一样,这是因为它是 JavaScript 原生的东西,既然是原生的组件,我们是看不到它的输入过程的,只能是通过 webdriver 来控制它的底层来改变输入的元素内容。所以虽然输入正确,返回也正确,但是在过程中是看不出来的
七、上传&下载文件
1、上传文件
(1)流程
- 启动浏览器
- 打开目标网页
- 定位文件上传元素
- 输入文件路径
- 提交上传
(2)代码举例:
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.maximize_window() # Chrome 浏览器最大化
sleep(1)
driver.get('file:///F:/DEMO/upload.html') # 打开对应文件
sleep(1)
# 定位文件上传元素
upload = driver.find_element(By.XPATH,"/html/body/input")
# 输入需要上传的文件路径
upload.send_keys("F:/PY/demo/百度.png")
# 定位提交按钮并上传
upload_button = driver.find_element(By.TAG_NAME,'button')
upload_button.click()
sleep(5)
driver.quit()上传时,使用send_keys()方法向文件上传元素发送文件路径,其中"F:/PY/demo/百度.png"是待上传文件的路径
2、下载文件
(1)流程
- 启动浏览器
- 打开目标网页
- 定位文件下载链接
- 点击下载链接
- 等待文件下载完成
(2)语法:
- download.default_directory:设置下载路径
- profile.default_content_settings.popups:0 禁止弹出窗口
(3)简单代码示例:
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.maximize_window()
#打开下载地址
driver.get('https://pypi.org/project/selenium/#files')
sleep(1)
#点击下载链接下载
driver.find_element(By.XPATH,'//*[@id="files"]/div[1]/div[2]/a[1]').click()
sleep(10)
driver.quit()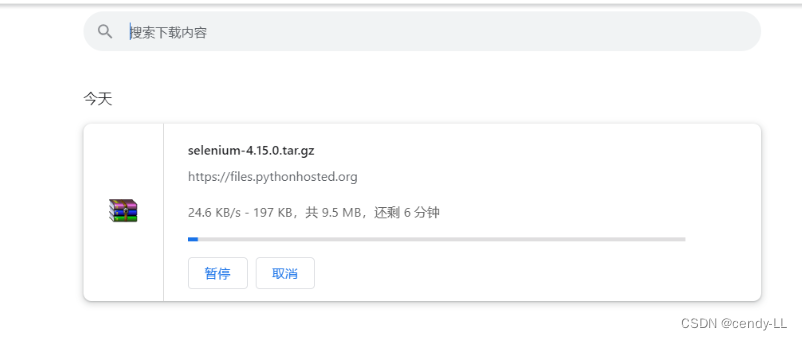
八、cookies操作/调用JavaScript
1、cookies操作
cookies是识别用户登录与否的关键,爬虫中常常使用 `selenium + requests` 实现 `cookie `持久化,即先用 `selenium` 模拟登陆获取 `cookie` ,再通过 `requests` 携带 `cookie` 进行请求。
webdriver 提供 cookies 的几种操作:读取、添加删除
- get_cookies:以字典的形式返回当前会话中可见的 cookie 信息
- get_cookie(name):返回 cookie 字典中 key == name 的 cokie 信息。
- add_cookie(cookie_dict):将 cookie 添加到当前会话中
- delete_cookie(name):删除指定名称的单个 cookie
- delete_all_cookies():删除会话范围内的所有 cookie
代码示例:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://blog.youkuaiyun.com/")
# 输出所有cookie信息
print(driver.get_cookies())
cookie_dict = {
'domain': '.youkuaiyun.com',
'expiry': 1732604623,
'httpOnly': True,
'name': 'test',
'path': '/',
'secure': True,
'value': 'null'}
# 添加cookie
driver.add_cookie(cookie_dict)
# 显示当前会话中可见的cookie信息
print(driver.get_cookies())
# 显示 name = '__gpi' 的cookie信息
print(driver.get_cookie('c_ref'))
# 删除 name = 'test' 的cookie信息
driver.delete_cookie('test')
# 删除当前会话中的所有cookie
driver.delete_all_cookies()
2、调用JavaScript滑动滚动
webdriver 对于滚动条的处理需要用到JavaScript ,同时也可以向textarea文本框中输入文本(webdriver只能定位,不能输入文本),webdriver中使用execute_script方法实现JavaScript执行
(1)通过 x ,y 坐标滑动
对于这种通过坐标滑动的方法,我们需要知道起始位置在页面左上角(0,0)---很少用
window.scrollTo(0,1000)-------# f(x,y) x:横坐标,y:纵坐标,单位:xp(像素点)
from selenium import webdriver
import time
driver = webdriver.Chrome() # 初始化一个谷歌浏览器
driver.maximize_window() # 浏览器窗口最大化
driver.get("https://readhub.cn/topics") # 打开一个存在懒加载的网页
time.sleep(5) # 等待一段时间,待页面加载出来再执行js代码
# 方法一:坐标法
driver.execute_script('window.scrollTo(0,1000)') # 横坐标不变,纵坐标 滚动到1000像素点
time.sleep(2) # 等待一段时间,方便查看滚动的效果
driver.execute_script('window.scrollTo(0,2000)') # 再滚动一次
time.sleep(2) # 等待一段时间,方便查看滚动的效果(2)滚动到窗口底部,然后定位要找的元素
window.scrollTo(0,document.body.scrollHeight) -------document.body.scrollHeight 当前窗口的高度
from selenium import webdriver
import time
driver = webdriver.Chrome() # 初始化一个谷歌浏览器
driver.maximize_window() # 浏览器窗口最大化
driver.get("https://readhub.cn/topics") # 打开一个存在懒加载的网页
time.sleep(5) # 等待一段时间,待页面加载出来再执行js代码
# 方法二:滚动到窗口底部
# 拉到底部,但是有新的加载就会退回到三分之二的位置;加载出来后又跳到四分之一的位置
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(2) # 等待一段时间,方便查看滚动的效果
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)') # 再继续滚动
time.sleep(2)(3)将元素滚动到可视范围之内
场景:有时候元素在比较下面,需要先滚动下页面才能看到元素并点击
document.getElementById(“id”).scrollIntoView()
或者分成两行写:
el = document.getElementById(“id”)
el.scrollIntoView()
from selenium import webdriver
import time
driver = webdriver.Chrome() # 初始化一个谷歌浏览器
driver.maximize_window() # 浏览器窗口最大化
driver.get("
https://www.baidu.com/s?ie=UTF-8&wd=%E8%8A%B1%E9%9D%99%E9%80%B8") # 打开百度搜索“白桃乌龙”的结果
time.sleep(5) # 等待一段时间,待页面加载出来再执行js代码
# document.getElementsByClassName("pc")[1] # js指令:百度搜索结果页,定位页面底部翻页的元素“2”
driver.execute_script('document.getElementsByClassName("pc")[1].scrollIntoView()')
time.sleep(5)
# 或者分成两行写
# driver.execute_script('el = document.getElementsByClassName("pc")[1]')
# driver.execute_script('el.scrollIntoView()')注意:mentsByClassName 定位到的是一组元素,我们需要通过索引(从0开始)来取到元素“2”
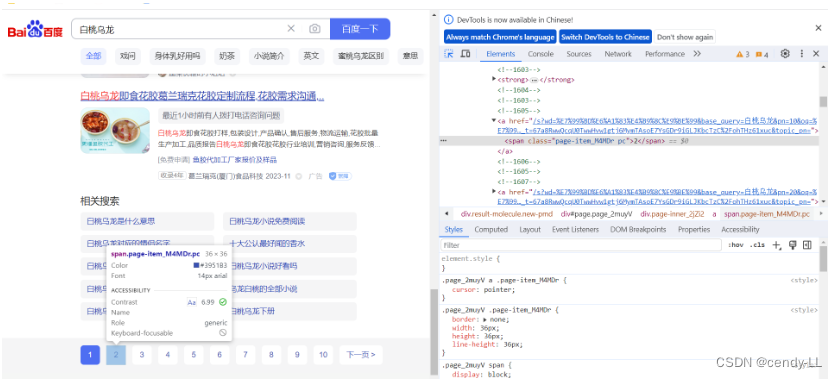
九、其他操作
1、关闭所有页面
使用 quit()`方法可以关闭所有窗口并退出驱动程序
driver.quit()2、关闭当前页面
使用 close()方法可以关闭当前页面,使用时要注意 “当前页面” 这四个字,当你关闭新打开的页面时,需要切换窗口才能操作新窗口并将它关闭。
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://blog.youkuaiyun.com/')
driver.implicitly_wait(3)
# 点击进入新页面
driver.find_element(By.XPATH,'//*[@id="floor-blog-index_747"]/div/div[1]/div[1]/div[1]/div/div/div[1]/a/p[1]/span').click()
# 切换窗口
# driver.switch_to.window(driver.window_handles[-1])
sleep(5)
driver.close()不切换窗口时,`driver` 对象还是操作最开始的页面
3、对当前页面进行截图
(1)理解:wendriver中使用get_screenshot_as_file()对 “当前页面” 进行截图,这里和上面的 `close()` 方法一样,对于新窗口的操作,一定要切换窗口,不然截的还是原页面的图。对页面截图这一功能,主要用在我们测试时记录报错页面的,我们可以将 try except 结合 get_screenshot_as_file()`一起使用来实现这一效果
(2)举例说明:
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://blog.youkuaiyun.com/')
driver.implicitly_wait(3)
# 点击进入新页面
driver.find_element(By.XPATH,'//*[@id="floor-blog-index_747"]/div/div[1]/div[1]/div[1]/div/div/div[1]/a/p[1]/span').click()
# 切换窗口
driver.switch_to.window(driver.window_handles[-1])
# 截图
driver.get_screenshot_as_file(r'F:\PY\img\text.png')
sleep(5)
driver.close()
(3)主要应用在下面例子:
try:
driver.find_element_by_xpath('//*[@id="mainContent"]/aside/div[1]/div').click()
except:
driver.get_screenshot_as_file(r'C:\Users\pc\Desktop\screenshot.png')4、常用方法总结
# 获取当前页面url
driver.current_url
# 获取当前html源码
driver.page_source
# 获取当前页面标题
driver.title
# 获取浏览器名称(chrome)
driver.name
# 对页面进行截图,返回二进制数据
driver.get_screenshot_as_png()
# 设置浏览器尺寸
driver.get_window_size()
# 获取浏览器尺寸,位置
driver.get_window_rect()
# 获取浏览器位置(左上角)
driver.get_window_position()
# 设置浏览器尺寸
driver.set_window_size(width=1000, height=600)
# 设置浏览器位置(左上角)
driver.set_window_position(x=500, y=600)
# 设置浏览器的尺寸,位置
driver.set_window_rect(x=200, y=400, width=1000, height=600)大概就是这么多东西了,后续可继续补充!

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









