







找往期文章包括但不限于本期文章中不懂的知识点:
个人主页:我要学编程(ಥ_ಥ)-优快云博客
所属专栏: 优选算法专题
目录
1046.最后一块石头的重量
题目:
有一堆石头,每块石头的重量都是正整数。
每一回合,从中选出两块 最重的 石头,然后将它们一起粉碎。假设石头的重量分别为
x和y,且x <= y。那么粉碎的可能结果如下:
- 如果
x == y,那么两块石头都会被完全粉碎;- 如果
x != y,那么重量为x的石头将会完全粉碎,而重量为y的石头新重量为y-x。最后,最多只会剩下一块石头。返回此石头的重量。如果没有石头剩下,就返回
0。示例:
输入:[2,7,4,1,8,1] 输出:1 解释: 先选出 7 和 8,得到 1,所以数组转换为 [2,4,1,1,1], 再选出 2 和 4,得到 2,所以数组转换为 [2,1,1,1], 接着是 2 和 1,得到 1,所以数组转换为 [1,1,1], 最后选出 1 和 1,得到 0,最终数组转换为 [1],这就是最后剩下那块石头的重量。提示:
1 <= stones.length <= 301 <= stones[i] <= 1000
思路:本题是一个简单的模拟题:按照题目要求,每次拿到数组两个最大值的值,两者之差如果不为0,则继续和数组中其余的值一起重复上述操作,直至最终数组的大小小于2即可停止,返回最终结果时,看是否剩下了数据,如果剩下了的话,就返回最终的数据,反之,则返回0即可。这里每次从数组中取两个最大值,就可以通过优先级队列来实现。
代码实现:
class Solution {
public int lastStoneWeight(int[] stones) {
PriorityQueue<Integer> maxHeap = new PriorityQueue<>((a, b) -> {
return b-a; // 实现大根堆
});
for (int i = 0; i < stones.length; i++) {
maxHeap.offer(stones[i]);
}
while (maxHeap.size() >= 2) {
int x = maxHeap.poll(), y = maxHeap.poll();
// 这里也可以不用绝对值,因为x先取出来的,肯定比y大
int ans = Math.abs(x - y);
if (ans != 0) { // 当剩余石头时,才需要入堆
maxHeap.offer(ans);
}
}
// 如果堆中还有元素,就返回最终元素的值,如果没有元素,就返回0
return maxHeap.size() == 0 ? 0 : maxHeap.poll();
}
}703.数据流中的第K大元素
题目:
设计一个找到数据流中第
k大元素的类(class)。注意是排序后的第k大元素,不是第k个不同的元素。请实现
KthLargest类:
KthLargest(int k, int[] nums)使用整数k和整数流nums初始化对象。int add(int val)将val插入数据流nums后,返回当前数据流中第k大的元素。示例 1:
输入:
["KthLargest", "add", "add", "add", "add", "add"]
[[3, [4, 5, 8, 2]], [3], [5], [10], [9], [4]]输出:[null, 4, 5, 5, 8, 8]
解释:
KthLargest kthLargest = new KthLargest(3, [4, 5, 8, 2]);
kthLargest.add(3); // 返回 4
kthLargest.add(5); // 返回 5
kthLargest.add(10); // 返回 5
kthLargest.add(9); // 返回 8
kthLargest.add(4); // 返回 8示例 2:
输入:
["KthLargest", "add", "add", "add", "add"]
[[4, [7, 7, 7, 7, 8, 3]], [2], [10], [9], [9]]输出:[null, 7, 7, 7, 8]
解释:
KthLargest kthLargest = new KthLargest(4, [7, 7, 7, 7, 8, 3]);
提示:
kthLargest.add(2); // 返回 7
kthLargest.add(10); // 返回 7
kthLargest.add(9); // 返回 7
kthLargest.add(9); // 返回 8
0 <= nums.length <= 10^41 <= k <= nums.length + 1-10^4 <= nums[i] <= 10^4-10^4 <= val <= 10^4- 最多调用
add方法10^4次
思路:本题就是让我们实现一个类的add方法,本次添加新元素时,都能给我们返回所有的数据中第k大的数据。看到这里我们就应该联想到 top-k 问题了。本题也是一个简单的 top-k 问题。top-k问题的处理思路是创建一个大小为k的堆(与我们求的相反,即大根堆求第k小的数据,小根堆求第k大的数据),将所求的数据入堆,如果满足堆顶元素小于后续元素,那么堆顶元素肯定就不是第k大的了,就需要更新数据。一直重复上述步骤直至遍历完即可。
问:寻找第K个最大的值,为什么需要建立小根堆呢?
答:建立小根堆之后,将数据入队,如果堆中元素大于K个了,说明堆顶元素一定不是前K个最大的(小根堆)。如果建立大根堆的话,只能判断出堆顶元素是数据中的最大值,而不能找到第K个最大的
代码实现:
class KthLargest {
private int k;
private PriorityQueue<Integer> minHeap;
public KthLargest(int k, int[] nums) {
this.k = k;
// 可以通过堆中元素的个数来限制堆的大小,而不需要去手动指定堆的大小
this.minHeap = new PriorityQueue<>();
// 初始化堆
for (int x : nums) {
minHeap.offer(x);
// 判断是否超出k个
if (minHeap.size() > k) {
// 堆顶元素一定不是第k大的
minHeap.poll();
}
}
}
public int add(int val) {
// 同样直接入堆
minHeap.offer(val);
// 再判断是否超出k个
if (minHeap.size() > k) {
minHeap.poll(); // 堆顶一定不是第k大的
}
return minHeap.peek();
}
}692.前K个高频单词
题目:
给定一个单词列表
words和一个整数k,返回前k个出现次数最多的单词。返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
示例 1:
输入: words = ["i", "love", "leetcode", "i", "love", "coding"], k = 2 输出: ["i", "love"] 解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。 注意,按字母顺序 "i" 在 "love" 之前。示例 2:
输入: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4 输出: ["the", "is", "sunny", "day"] 解析: "the", "is", "sunny" 和 "day" 是出现次数最多的四个单词, 出现次数依次为 4, 3, 2 和 1 次。注意:
1 <= words.length <= 5001 <= words[i] <= 10words[i]由小写英文字母组成。k的取值范围是[1, 不同 words[i] 的数量]
思路:看到 "前k 或 第k" 的字眼,我们首先就要想到 top-k问题。这里也是使用top-k的方式来解决的。我们先去统计每个单词出现的次数,然后再创建一个大小为K的小根堆来接收这些单词即可。但要注意的是,当单词的频率相同时,需要按照字典的方式进行排序。这也就意味这需要我们在实现小根堆时,比较函数先是比较次数,再是比较字典序。比较次数是实现小根堆的形式,比较字典序是实现大根堆的形式。
代码实现:
class Solution {
public List<String> topKFrequent(String[] words, int k) {
// 先统计每个单词出现的次数
Map<String, Integer> hash = new HashMap<>();
for (String s : words) {
hash.put(s, hash.getOrDefault(s, 0)+1);
}
// 创建小根堆
PriorityQueue<String> minHeap = new PriorityQueue<>((a, b) -> {
// 比较两个字符串在哈希表中出现的次数
int x = hash.get(a);
int y = hash.get(b);
if (x != y) { // 频次排序,小根堆
return x-y;
} else { // 字典排序,大根堆
return b.compareTo(a);
}
});
// 将单词入堆
for (String s : hash.keySet()) {
minHeap.offer(s);
if (minHeap.size() > k) {
// 说明堆顶元素一定不是前k个高频的单词
minHeap.poll();
}
}
// 存放到数组中
List<String> ret = new ArrayList<>();
while (!minHeap.isEmpty()) {
ret.add(minHeap.poll());
}
// 需要逆置数组
Collections.reverse(ret);
return ret;
}
}295.数据流的中位数
题目:
中位数是有序整数列表中的中间值。如果列表的大小是偶数,则没有中间值,中位数是两个中间值的平均值。
- 例如
arr = [2,3,4]的中位数是3。- 例如
arr = [2,3]的中位数是(2 + 3) / 2 = 2.5。实现 MedianFinder 类:
MedianFinder()初始化MedianFinder对象。
void addNum(int num)将数据流中的整数num添加到数据结构中。
double findMedian()返回到目前为止所有元素的中位数。与实际答案相差10-5以内的答案将被接受。示例 1:
输入 ["MedianFinder", "addNum", "addNum", "findMedian", "addNum", "findMedian"] [[], [1], [2], [], [3], []] 输出 [null, null, null, 1.5, null, 2.0] 解释 MedianFinder medianFinder = new MedianFinder(); medianFinder.addNum(1); // arr = [1] medianFinder.addNum(2); // arr = [1, 2] medianFinder.findMedian(); // 返回 1.5 ((1 + 2) / 2) medianFinder.addNum(3); // arr[1, 2, 3] medianFinder.findMedian(); // return 2.0提示:
-10^5 <= num <= 10^5- 在调用
findMedian之前,数据结构中至少有一个元素- 最多
5 * 104次调用addNum和findMedian
思路:题目就是让我们排序数据流,然后找出中间值。可以采取最暴力的方式,直接使用内置函数进行排序,然后在数据流中去平均值即可。但是这种方式时间复杂度非常大,直接超时了。可以采取大小堆的方式:
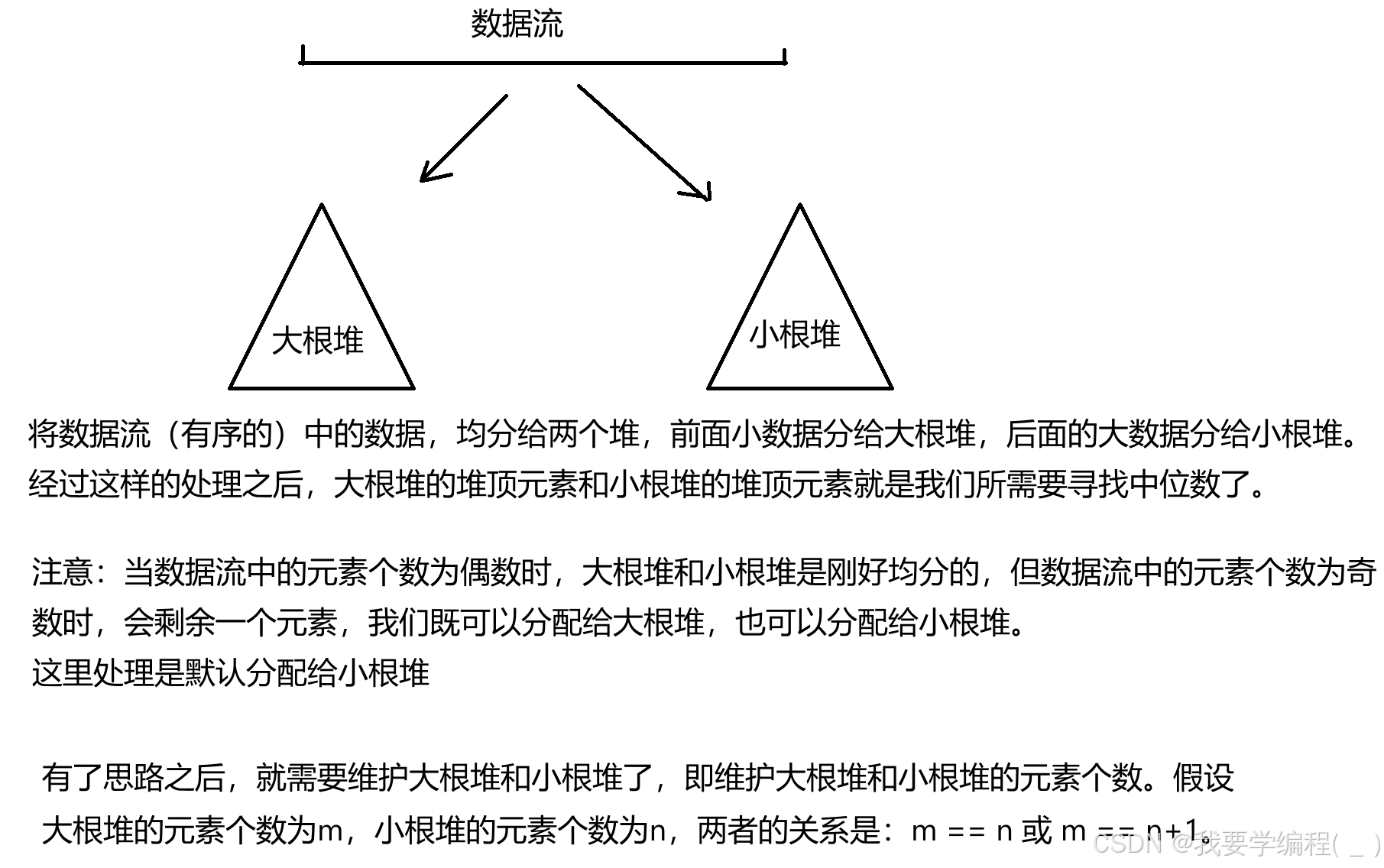
知道如何解决之后,就来看怎么实现该类中的 add 和 find 方法。
实现add方法:本质就是往数据流中添加数据,但是数据流已经被我们处理成了大根堆和小根堆,因此我们只需要维护大根堆和小根堆的容量是均分的情况即可。
设 x 为大根堆的堆顶元素,y 为小根堆的堆顶元素。
当 m == n(数据流中元素的个数是偶数)时,新增元素:1)num <= × 一> num 在数据流中的位置是处于 x 的左边,直接插入大根
堆,两个堆元素的个数:m = n+1 符合要求。
2)num > × —> num 在数据流中的位置是处于 x 的右边,直接插入小根堆,堆元素的个数:m= n + 1不符合要求,得减少小根堆的元素,增加大根堆的元素 一> 将小根堆的堆顶元素插入到大根堆即可,最终堆元素的个数:m == n 符合要求。当 m == n+1(数据流中元素的个数是奇数)时,
新增元素:1)num <= x 一> num 在数据流中的位置是处于 x 的左边,直接插入大根
堆,堆元素的个数:m = n+2 不符合要求,得减少大根堆的元素,增加小根堆的元素 一> 将大根堆的堆顶元素插入到小根堆中,最终堆元素的个数:m = n+1符合要求。
上述是add方法的实现逻辑,下面就来实现find方法,如果数据流中元素的个数是奇数的话,直接返回大根堆的堆顶元素即可;反之,则将大根堆和小根堆的堆顶元素取平均值即可。
注意:当大小根堆都为空时,得将元素插入大根堆中。
代码实现:
暴力排序:
class MedianFinder {
private List<Integer> ret;
public MedianFinder() {
this.ret = new ArrayList<>();
}
public void addNum(int num) {
ret.add(num);
}
public double findMedian() {
// 首先得对数组排序
Collections.sort(ret);
// 判断数组的长度是奇数还是偶数
int n = ret.size();
if (n % 2 == 1) {
// 奇数 -> 找中间值
return ret.get((0+n-1) / 2);
} else {
// 偶数 -> 中间值取平均
int x = ret.get((0+n-1) / 2);
int y = ret.get((0+n-1+1) / 2);
return (x+y) * 1.0 / 2; // 注意使用浮点数除法
}
}
}
大小根堆:
class MedianFinder {
// 创建大小根堆
private PriorityQueue<Integer> maxHeap;
private PriorityQueue<Integer> minHeap;
public MedianFinder() {
this.maxHeap = new PriorityQueue<>((a, b) -> {
return b - a;
});
this.minHeap = new PriorityQueue<>();
}
public void addNum(int num) {
if (maxHeap.size() == minHeap.size()) {
if (maxHeap.isEmpty() || num <= maxHeap.peek()) {
maxHeap.offer(num);
} else {
minHeap.offer(num);
// 更新大根堆和小根堆的元素数量
maxHeap.offer(minHeap.poll());
}
} else {
if (num <= maxHeap.peek()) {
maxHeap.offer(num);
// 更新大根堆和小根堆的元素数量
minHeap.offer(maxHeap.poll());
} else {
minHeap.offer(num);
}
}
}
public double findMedian() {
// 看数据流中的元素是奇数还是偶数
int m = maxHeap.size();
int n = minHeap.size();
if ((m + n) % 2 == 1) { // 奇数
// 取大根堆的堆顶值
return maxHeap.peek();
} else { // 偶数
// 取大根堆和小根堆的堆顶,然后平均值
return (maxHeap.peek() + minHeap.peek()) * 1.0 / 2;
}
}
}好啦!本期 常见“优先级队列(堆)”相关题目 的刷题之旅 就到此结束啦!我们下一期再一起学习吧!


















 60
60

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











