







二叉搜索树的概念
二叉树搜索树是在普通二叉树的基础上对二叉树的父亲左右节点的大小关系做一个要求,满足一定的大小关系方便进行增删差改
具体的标准就是:1、它的左树不为空,那么左树的所有节点的值都小于等于根节点的值;
2、它的右树不为空,那么右树的所有节点的值都大于等于根节点的值;
3、它的左右字数左右字数都是二叉搜索树
4、通过插入值的类型,可以分为有K-V结构的map,multimap,没有K-V结构的set,multiset(其中K-V就是同时存一组有着对应关系的结构);分为没有重复元素的map,set,有重复元素的multimap,multiset。(第四点看不懂无所谓,下面会详细讲)
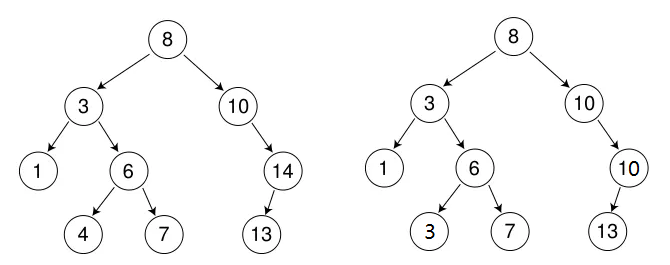
二叉树性能分析
通过上面的讲解,构建一颗二叉树不难,只要每次增删查改保证左边的比根小右边的比根大就可保证它时刻是一颗二叉搜索树。
那么我们对其进行性能分析:如果我们对其插入的刚刚好是一颗完全二叉树甚至满二叉树,那么时间复杂度就是标准的O(logN)级别,但是时间复杂度我们要看最坏的情况,如果我们每次插入的值都在树的一边,就会近似形成单边的链表最后退化成O(N)级别的时间复杂度。
因此简单的二叉搜索树是不足以满足我们的要求的,最终它的时间复杂度依旧是O(N)级别。因此就有了后面的AVL树和红黑树,让增删查改的效率都是恐怖的O(logN)级别。
二叉搜索树的增删查
为什么没有改,原因是改掉一个节点的数据可能会破坏二叉树的结构,使其不满足左边小右边大的性质。如果一定要实现,那么只能删除再插入。
这里我们现实现没有重复数据的二叉搜索树
节点的结构
首先我们把搜索二叉树的结构写一下:

查找
因为删除和插入都要用到查找的思维,因此我们现实现查找的代码
查找先从根节点开始,如果等于这个值就找到了,如果这个值比它小就走左子树去找,如果比它大就走右子树去找。
这个应该是不难的,通过循环来让cur节点顺着向下找到对应的值,如果最后是空就说明没找到。这里如果根节点就是空的也没事,不会进入循环。
插入
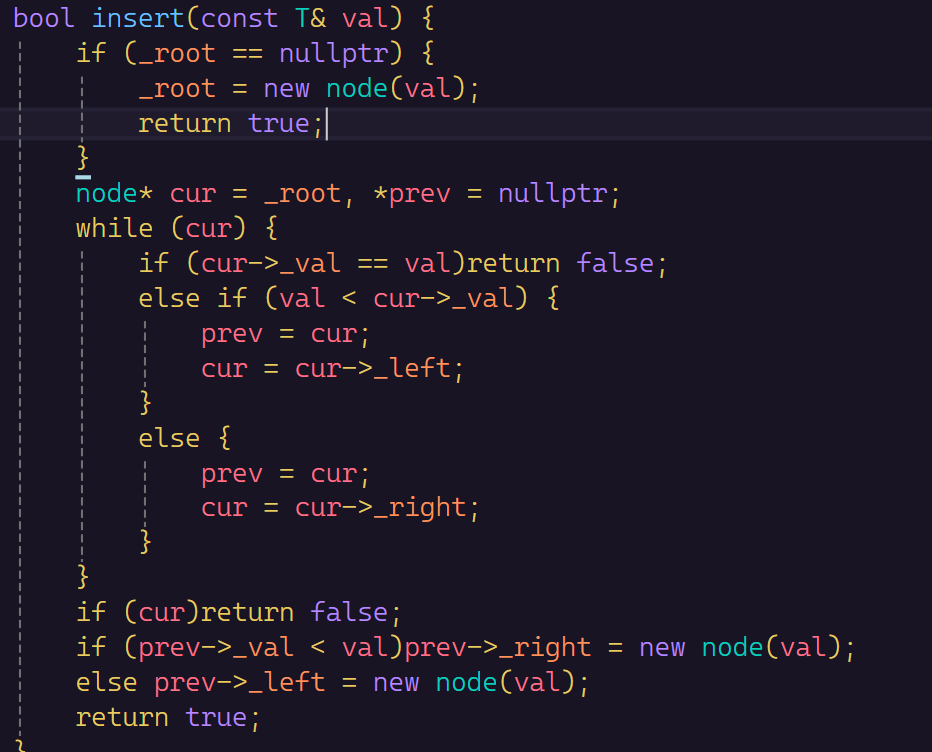
插入就利用了查找的思路,只不过我们单纯的查找只能最终定位到空,或者找到了就返回插入失败。
例如下面的这棵树,我们要插入15会插入到14的右边,但是我们查找只会最后落到14的空指针去。因此我们还要来一个指针来记录上一个节点的地址。
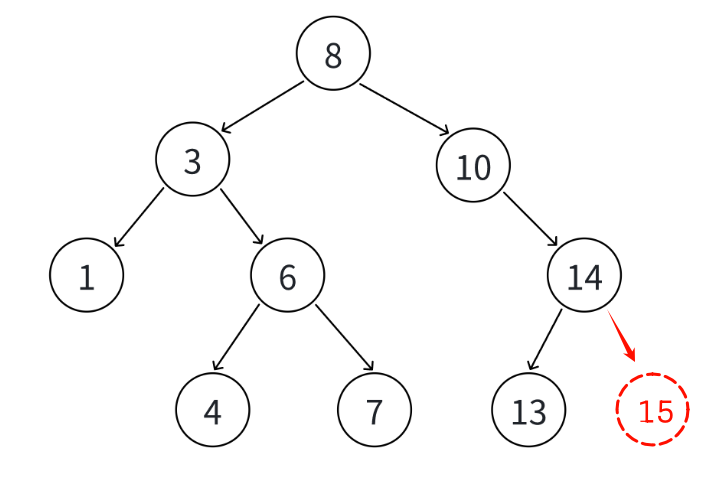
当我们的cur指针到了nullptr的时候,prev指针刚好到了要插入节点的父亲节点,我们只要在判断一下是插入在父亲左边还是右边就可完成插入。
可能有些人会疑惑最后一步是否有问题:如果我们向prev的左边插入的时候已经有值了不就出错了吗,或者右边插入也有节点了。这就是上面查找做的工作,查找会找到一个空节点位置让val值插入进去,如果不是空节点就是找到了,会返回false。并且如果插入的那边有节点了,说明这个节点不等于val值(因为等于val值就是找到了要返回),不等于val值,那么就应该继续找这个节点对应的左右子树,因此绝对不会出现插入的这个地方已经有人的情况。
我们来调试看看是不是插入正确了:

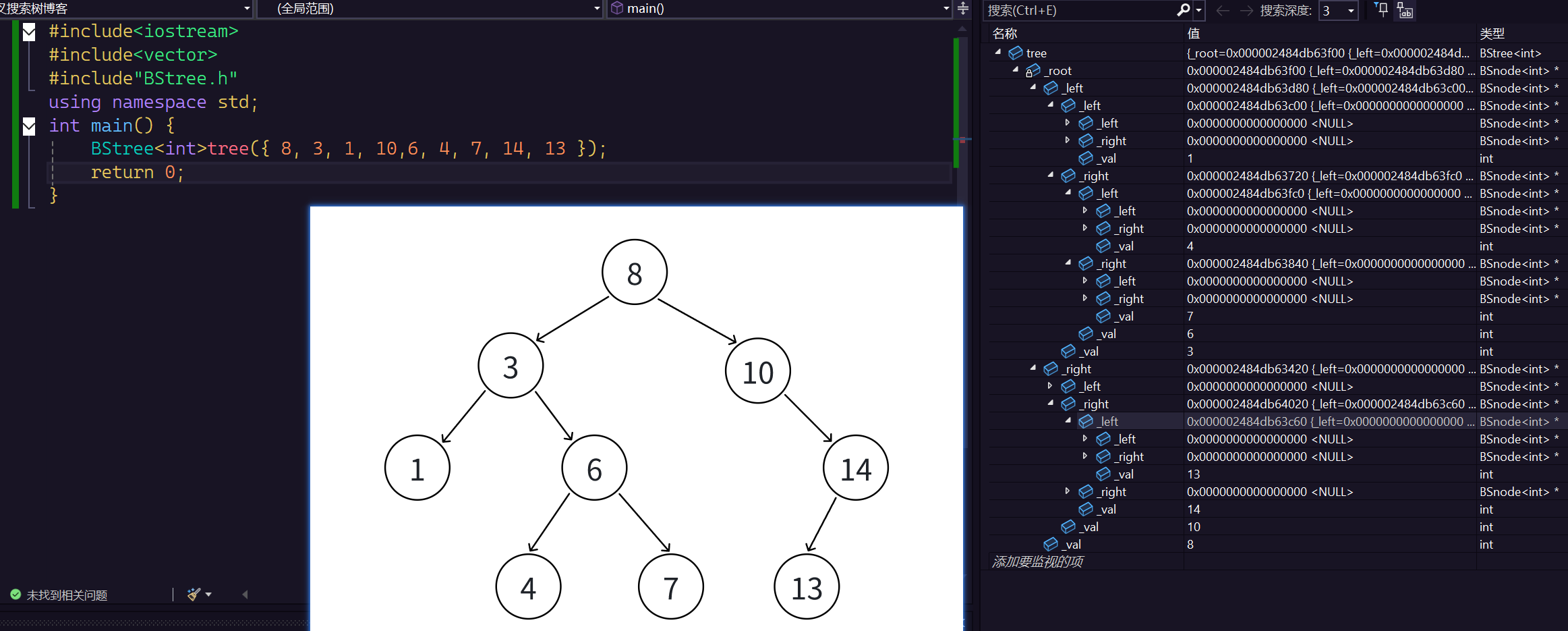
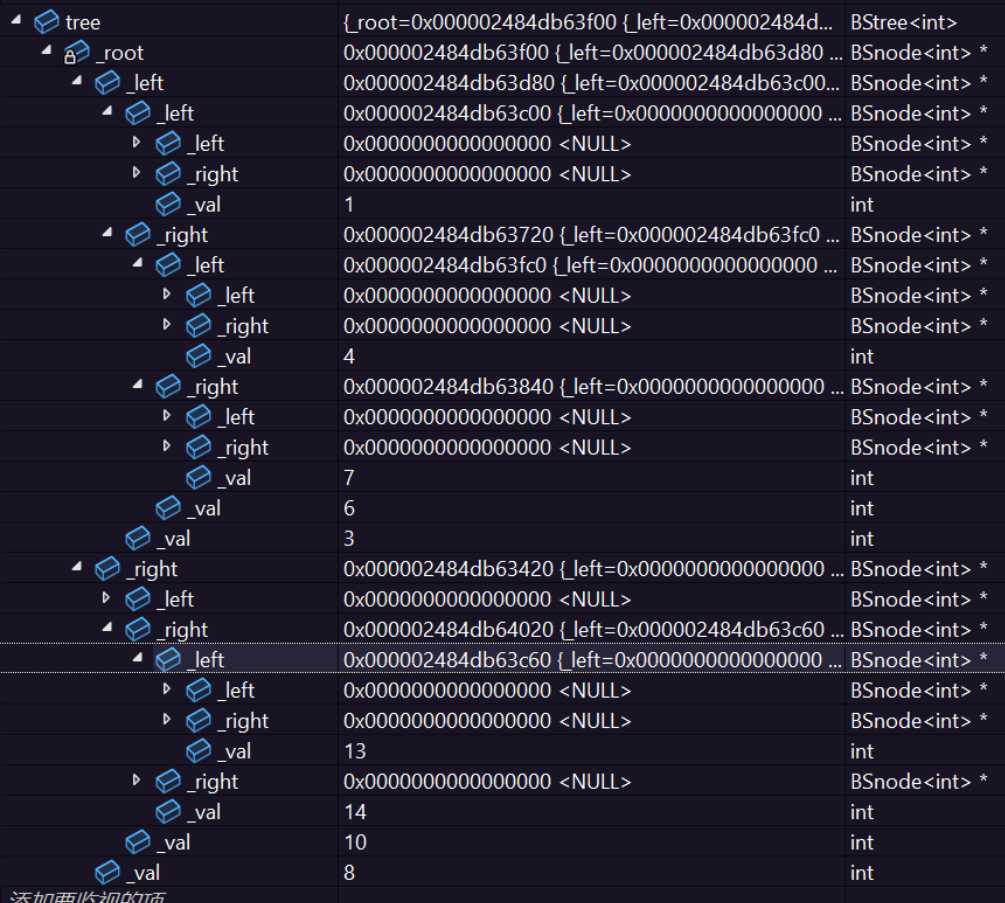
调试出来确实是对的。
中序遍历的性质
这里我小插一曲二叉树中序遍历的性质,对下面删除的操作讲解做铺垫。
我们先写一个二叉树的中序遍历看看结果是怎样的: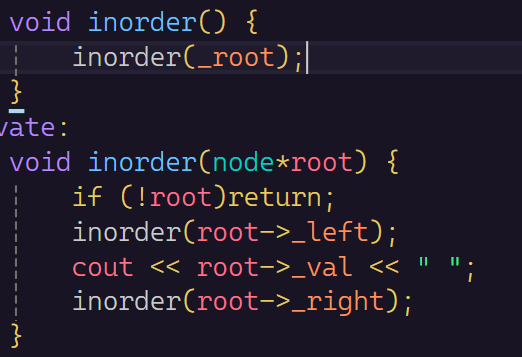
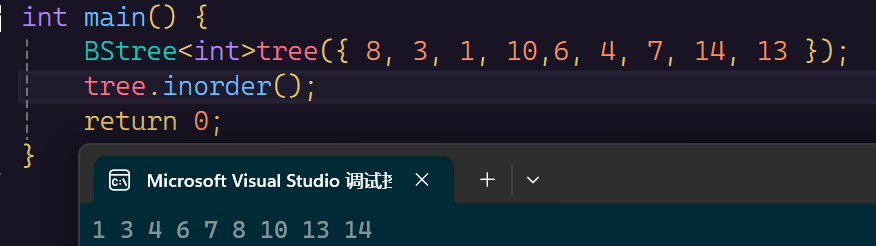
我们惊奇的发现是一个顺序打印。为什么呢?(ο´・д・)??
我们可以从搜索二叉树的结构来推断:在搜索二叉树中左子树<根<右子树。
中序遍历走的是左子树,根,右子树。那么就会始终先从小左子树开始走,只有把左子树走完了才会选择走根,然后右子树。
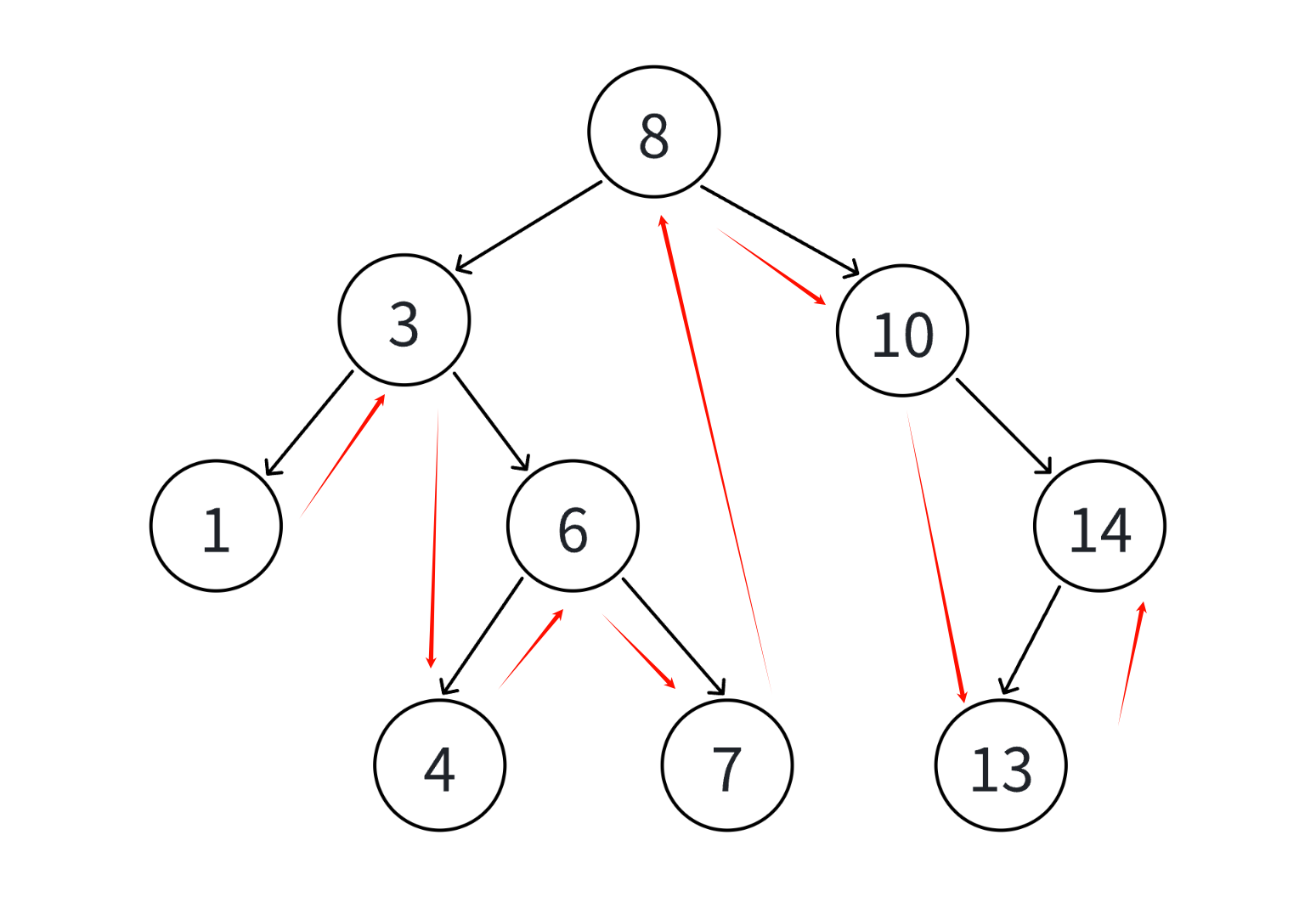
那么我们好好来看看走的过程,每个节点往下面一个节点走都应该从本节点树考虑,那么1就应该先考虑走它的右子树,但是它的右子树没有,那么只能变为整体作为左子树被访问完,那么就要开始访问3为树的根,然后访问下一棵树的左子树,然后重复这个操作。
那么一个节点的上一个比它小的节点就是它的左子树的最右侧节点,因为这个节点就是左子树的最终节点;一个节点的下一个比它大的节点就是右子树的最左边的节点,因为这个节点就是右子树的最开始的节点。
但是可能这个节点没有左树或者右树了,这种情况说明这个节点作为了这颗子树的根,就要将它作为左子树或者右子树来找它的根。例如7已经没有左右子树了,要么找它的根6,要么找它根的根的根,所以这种情况是比较复杂的。
(后面的可以不用看,等讲到set、map迭代器的实现的时候再看也不迟)
如果要考虑,那么我们就要看看其中的规律是什么,我们发现像7回到8,是走的6的右子树,3的右子树,然后到8的左子树停下,13到上一个10也是先走14的左边,遇到一个的右边就停下。
因此我们得出规律:遇到cur的左子树没有的情况,说明这个节点就是树dest的右子树的第一个,那么我们就要跳到上一个节点去,期间往上中途总是回到父亲的左节点,只要遇到为父亲的右节点,那么就是上一个值dest->val。同理,遇到cur的右节点没有值,那么这个节点就是树的dest的左子树的最后一个节点,我们只要往上找的时候遇到父亲节点的左子树是它那么就是最终的dest。
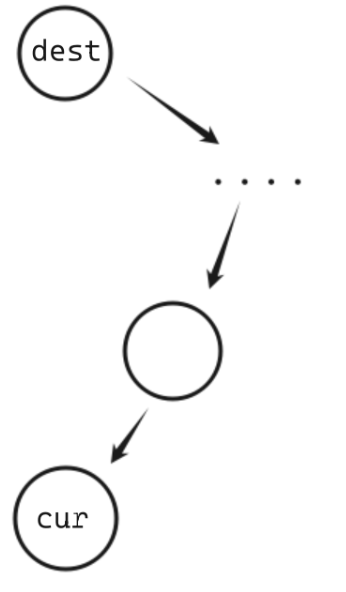
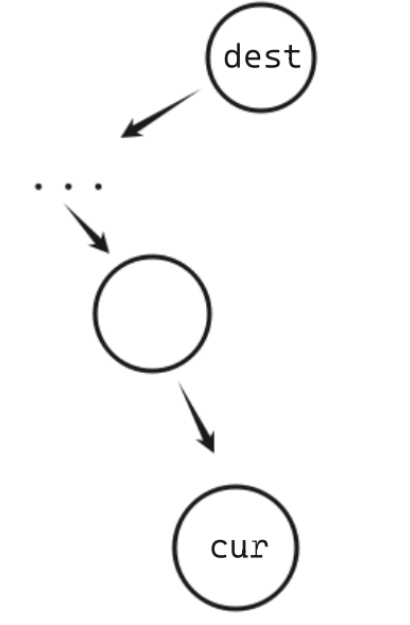
这样我们就可以在随便给出的一个节点的时候准确找到它的上一个值或者下一个值:
上一个:如果有左子树,那么上一个就是左子树的最后一个节点(左子树最右边的节点),如果没有左子树,那么就是上述的dest,向上一直找到子节点是父节点右边的节点这个父节点就是dest。
下一个:如果有右子树,那么下一个值就是右子树的第一个节点(右子树最左边的节点),如果没有右子树,那么就是上述的dest,向上一直找子节点是父节点左边的节点这个父节点就是dest。
如果看懂这个了,那么map和set的迭代器增减就会了。
删除
删除是一个相对复杂的过程。如果我们找到对应的值,它在叶子节点还好,我们删除了不会导致结构的崩坏,我们如果删的是树中间的节点,如果是直接删除,那么就会导致结构的崩坏。
因此我们要找到一种办法来解决这个问题:
通过二叉搜索树的中序顺序规律,我们知道一个节点的上一个或者下一个要么是叶子节点要么就是一个根节点,但是这个根节点是建立在这个节点是叶子节点的基础上,因此我们的这个节点如果不是叶子节点,那么它的上一个或者下一个节点就必定是叶子节点。
那就很好删除了,我们对于叶子节点我们直接删除。对于不是叶子节点的,我们可以将它的前一个节点或者后一个节点换到这个地方来,再把它作为叶子节点删掉。能这样做的原因是,我们删除这个值后,搜索二叉树的节点依然是有序的,那么这个值的前一个和后一个就会挨在一起,我们就可以提前让他们挨在一起,然后删除这个值。
但是这里仔细想想还是有一些没有考虑到的点,如果这个节点不是叶子节点,且左为空,怎么办,我们是不是只能找右树的最左节点。如果右树没有最左节点呢?
例如下面的8,我就不用7来交换,我要用它右边的,那么就会出现它没有右树的左节点。或者说它右树最左节点就是10,那么我们能否直接删除这个10,然后将下面的树直接连上来呢?答案是很可以的。那么最后一种情况也就解决了:
当左子树没有右节点时或者右子树没有左节点时,我们可以直接删除根节点让下面的树链接上来。
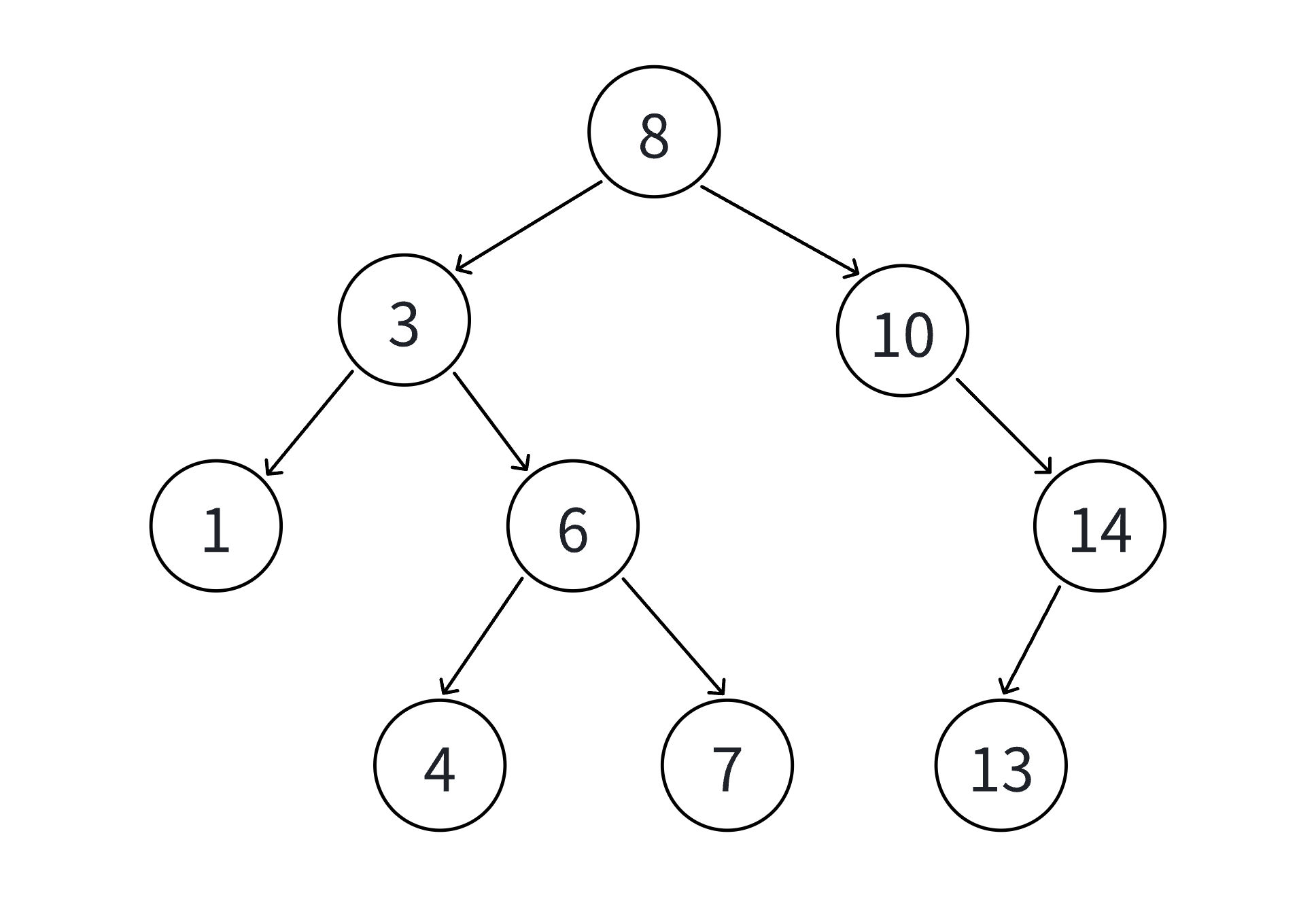
综上就是:我们对于叶子节点我们直接删除。对于不是叶子节点的,我们可以将它的前一个节点或者后一个节点换到这个地方来,再把它作为叶子节点删掉。能这样做的原因是,我们删除这个值后,搜索二叉树的节点依然是有序的,那么这个值的前一个和后一个就会挨在一起,我们就可以提前让他们挨在一起,然后删除这个值。当左子树没有右节点时或者右子树没有左节点时,我们可以直接删除根节点让下面的树链接上来,然后把删除的根节点的另一边连接过来。
但是写代码的情况我们还有一种要考虑,就是如果我们删除的是root节点8,且是叶子节点,我们要将root置空;如果不是叶子节点,那么就应该把3连到10的左边,然后删除8,然后更新root;
我们再写一个测试的,进行100w个数据的删除。
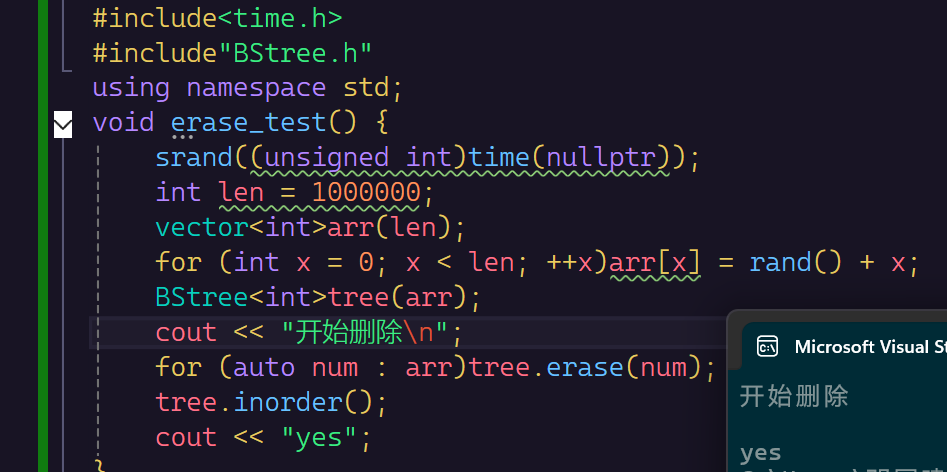
是正确的。
这里我们对于删除8的情况是3连10,但是我们可以换另一种情况。我们在删除10的时候,我们可以直接删除10,然后将下面的树链接上去。这种也可以解决这种情况的删除。同时这种情况能更好的写代码,是比上面的那种方式更好的。(这里没有写的原因是我忘记后面这个方法了)
下面是代码
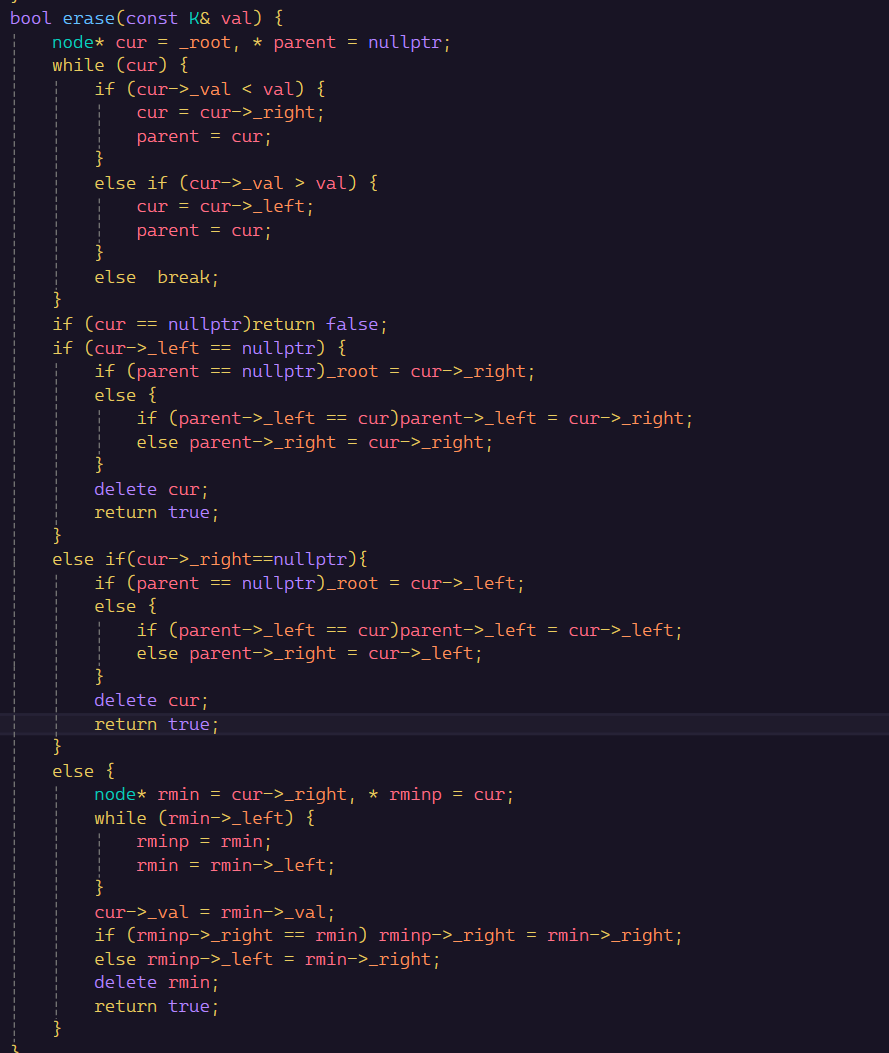
代码实现:
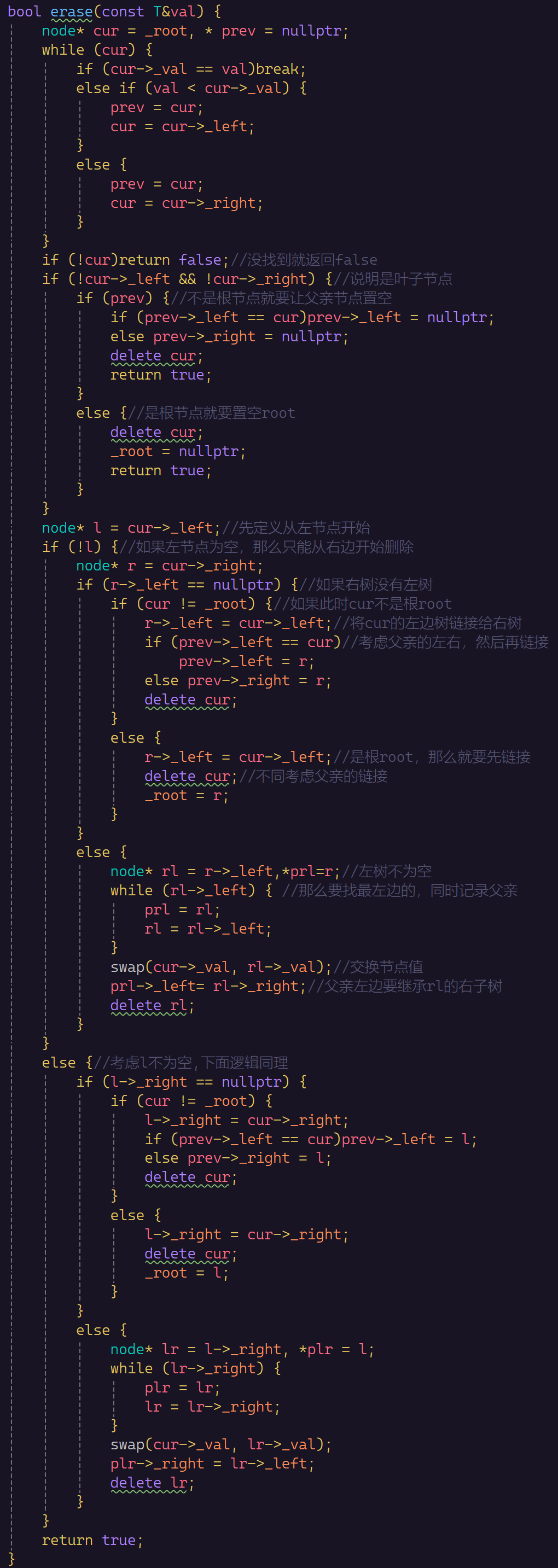
bool Erase(const K& key)
{
node* parent = nullptr;
node* cur = _root;
while (cur)
{
if (cur->_val < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_val > key)
{
parent = cur;
cur = cur->_left;
}
else
{
// 0-1个孩子的情况
// 删除情况1 2 3均可以直接删除,改变父亲对应孩子指针指向即可
if (cur->_left == nullptr)
{
if (parent == nullptr)
{
_root = cur->_right;
}
else
{
if (parent->_left == cur)
parent->_left = cur->_right;
else
parent->_right = cur->_right;
}
delete cur;
return true;
}
else if (cur->_right == nullptr)
{
if (parent == nullptr)
{
_root = cur->_left;
}
else
{
if (parent->_left == cur)
parent->_left = cur->_left;
else
parent->_right = cur->_left;
}
delete cur;
return true;
}
else
{
// 2个孩子的情况
// 删除情况4,替换法删除
// 假设这里我们取右子树的最小结点作为替代结点去删除
// 这里尤其要注意右子树的根就是最小情况的情况的处理,对应课件图中删除8的情况
// 一定要把cur给rightMinP,否会报错。
node* rightMinP = cur;
node* rightMin = cur->_right;
while (rightMin->_left)
{
rightMinP = rightMin;
rightMin = rightMin->_left;
}
cur->_val = rightMin->_val;
if (rightMinP->_left == rightMin)
rightMinP->_left = rightMin->_right;
else
rightMinP->_right = rightMin->_right;
delete rightMin;
return true;
}
}
}
return false;
}
代码实现
最后补上K结构的搜索二叉树类基本实现代码
BStree.h
#include<iostream>
#include<initializer_list>
#include<vector>
#include<utility>
#pragma once
using namespace std;
template <class T>
struct BSnode {
BSnode* _left;
BSnode* _right;
T _val;
BSnode(const T&val=T(),BSnode*left=nullptr,BSnode*right=nullptr)
:_val(val)
,_left(left)
,_right(right)
{ }
};
template <class T>
class BStree {
typedef BSnode<T> node;
public:
BStree(){}
BStree(const std::initializer_list<T>&x) {
for (auto& num : x)insert(num);
}
BStree(const vector<int>& x) {
for (auto& num : x)insert(num);
}
~BStree() {
destroy(_root);
_root = nullptr;
}
bool find(const T& val) {
node* cur = _root;
while (cur) {
if (cur->_val == val)return true;
else if (val < cur->_val)cur = cur->_left;
else cur = cur->_right;
}
if (cur)return true;
else return false;
}
bool insert(const T& val) {
if (_root == nullptr) {
_root = new node(val);
return true;
}
node* cur = _root, *prev = nullptr;
while (cur) {
if (cur->_val == val)return false;
else if (val < cur->_val) {
prev = cur;
cur = cur->_left;
}
else {
prev = cur;
cur = cur->_right;
}
}
if (cur)return false;
if (prev->_val < val)prev->_right = new node(val);
else prev->_left = new node(val);
return true;
}
bool erase(const T&val) {
node* cur = _root, * prev = nullptr;
while (cur) {
if (cur->_val == val)break;
else if (val < cur->_val) {
prev = cur;
cur = cur->_left;
}
else {
prev = cur;
cur = cur->_right;
}
}
if (!cur)return false;//没找到就返回false
if (!cur->_left && !cur->_right) {//说明是叶子节点
if (prev) {//不是根节点就要让父亲节点置空
if (prev->_left == cur)prev->_left = nullptr;
else prev->_right = nullptr;
delete cur;
return true;
}
else {//是根节点就要置空root
delete cur;
_root = nullptr;
return true;
}
}
node* l = cur->_left;//先定义从左节点开始
if (!l) {//如果左节点为空,那么只能从右边开始删除
node* r = cur->_right;
if (r->_left == nullptr) {//如果右树没有左树
if (cur != _root) {//如果此时cur不是根root
r->_left = cur->_left;//将cur的左边树链接给右树
if (prev->_left == cur)//考虑父亲的左右,然后再链接
prev->_left = r;
else prev->_right = r;
delete cur;
}
else {
r->_left = cur->_left;//是根root,那么就要先链接
delete cur;//不同考虑父亲的链接
_root = r;
}
}
else {
node* rl = r->_left,*prl=r;//左树不为空
while (rl->_left) { //那么要找最左边的,同时记录父亲
prl = rl;
rl = rl->_left;
}
swap(cur->_val, rl->_val);//交换节点值
prl->_left= rl->_right;//父亲左边要继承rl的右子树
delete rl;
}
}
else {//考虑l不为空,下面逻辑同理
if (l->_right == nullptr) {
if (cur != _root) {
l->_right = cur->_right;
if (prev->_left == cur)prev->_left = l;
else prev->_right = l;
delete cur;
}
else {
l->_right = cur->_right;
delete cur;
_root = l;
}
}
else {
node* lr = l->_right, *plr = l;
while (lr->_right) {
plr = lr;
lr = lr->_right;
}
swap(cur->_val, lr->_val);
plr->_right = lr->_left;
delete lr;
}
}
return true;
}
void inorder() {
inorder(_root);
cout << endl;
}
private:
void destroy(node* root) {
if (root == nullptr)return;
destroy(root->_left);
destroy(root->_right);
delete root;
}
void inorder(node*root) {
if (!root)return;
inorder(root->_left);
std::cout << root->_val << " ";
inorder(root->_right);
}
node* _root;
};
test.c
#include<iostream>
#include<vector>
#include<algorithm>
#include<time.h>
#include"BStree.h"
using namespace std;
void erase_test() {
srand((unsigned int)time(nullptr));
int len = 10000;
vector<int>arr(len);
for (int x = 0; x < len; ++x)arr[x] = rand() + x;
BStree<int>tree(arr);
cout << "开始删除\n";
for (auto num : arr)tree.erase(num);
tree.inorder();
cout << "yes";
}
int main() {
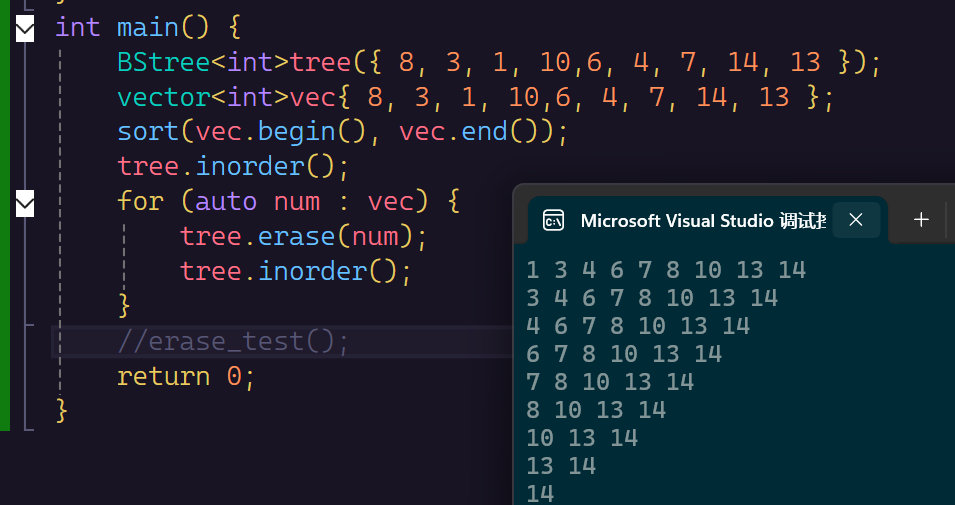
BStree<int>tree({ 8, 3, 1, 10,6, 4, 7, 14, 13 });
vector<int>vec{ 8, 3, 1, 10,6, 4, 7, 14, 13 };
sort(vec.begin(), vec.end());
tree.inorder();
for (auto num : vec) {
tree.erase(num);
tree.inorder();
}
//erase_test();
return 0;
}
搜索二叉树K K-V结构
上面说了K,K-V结构,那么这个两个到底是什么呢?
K指的是Key,是我们通过这个值要在二叉树中寻找,V指的是Value,指的是我们找到后,我们可能顺便回存储Key对应的一些关系,这个对于关系的值就叫value。
其实就是给二叉树的存储样式改了,原先就是存储一个值,现在我们存储一个结构体有两个值罢了。
那么代码几乎没有改变,只是把要插入K的结构改成要插入K-V结构了:
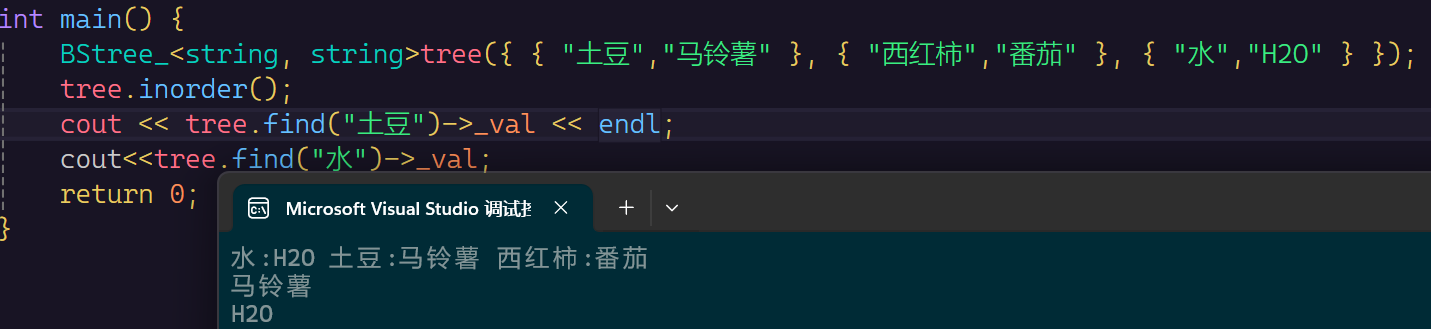
测试两个样例,一个是单词查找:
第二个是单词数量统计
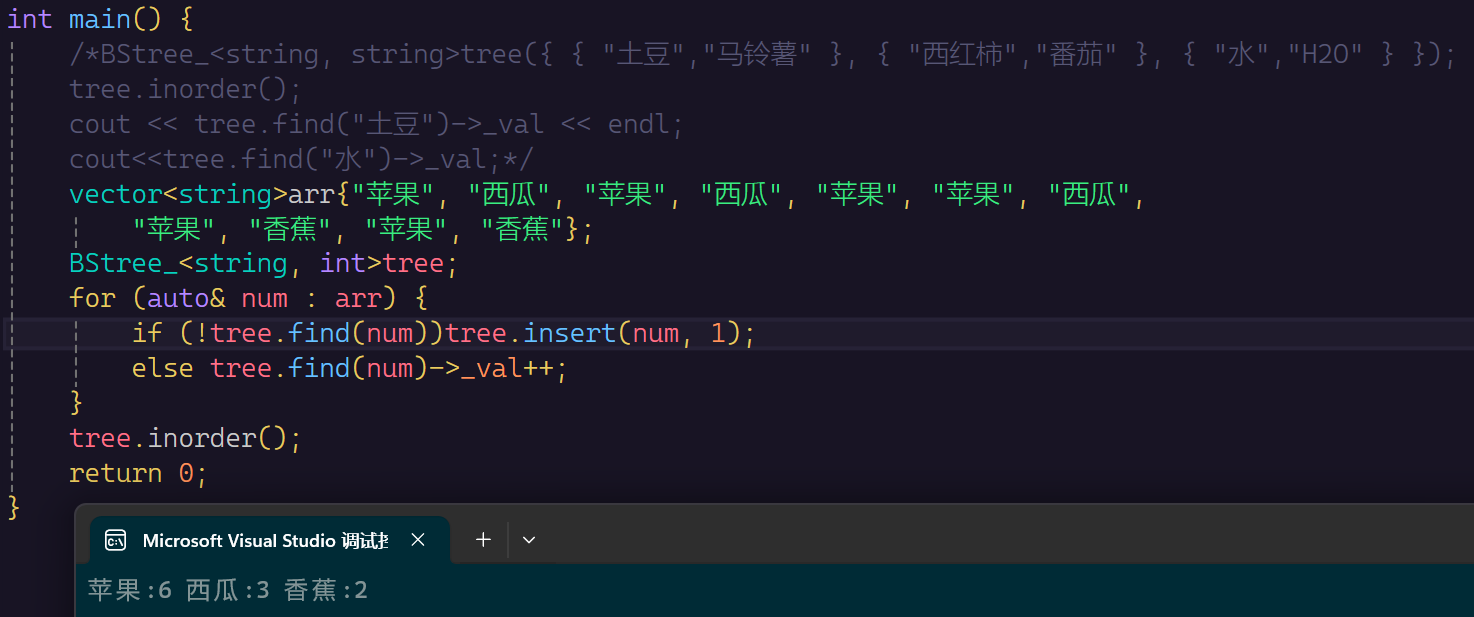
都是正确的,说明我们的K-V结构是正确的。
附上代码:
template <class K,class V>
struct BSnode_ {
BSnode_* _left;
BSnode_* _right;
K _key;
V _val;
BSnode_(const K& key = K(),const V&val=V(), BSnode_* left = nullptr, BSnode_* right = nullptr)
:_val(val)
,_key(key)
, _left(left)
, _right(right)
{
}
};
template <class K,class V>
class BStree_ {
typedef BSnode_<K, V> node;
public:
BStree_() {}
BStree_(const std::initializer_list<node>& x) {
for (auto& num : x)
insert(num._key,num._val);
}
~BStree_() {
destroy(_root);
_root = nullptr;
}
node* find(const K& key) {
node* cur = _root;
while (cur) {
if (cur->_key == key)return cur;
else if (key < cur->_key)cur = cur->_left;
else cur = cur->_right;
}
return nullptr;
}
bool insert(const K& key,const V&val) {
if (_root == nullptr) {
_root = new node(key,val);
return true;
}
node* cur = _root, * prev = nullptr;
while (cur) {
if (cur->_key == key)return false;
else if (key < cur->_key) {
prev = cur;
cur = cur->_left;
}
else {
prev = cur;
cur = cur->_right;
}
}
if (cur)return false;
if (prev->_key < key)prev->_right = new node(key,val);
else prev->_left = new node(key,val);
return true;
}
bool erase(const K& key) {
node* cur = _root, * prev = nullptr;
while (cur) {
if (cur->_key == key)break;
else if (key < cur->_key) {
prev = cur;
cur = cur->_left;
}
else {
prev = cur;
cur = cur->_right;
}
}
if (!cur)return false;//没找到就返回false
if (!cur->_left && !cur->_right) {//说明是叶子节点
if (prev) {//不是根节点就要让父亲节点置空
if (prev->_left == cur)prev->_left = nullptr;
else prev->_right = nullptr;
delete cur;
return true;
}
else {//是根节点就要置空root
delete cur;
_root = nullptr;
return true;
}
}
node* l = cur->_left;//先定义从左节点开始
if (!l) {//如果左节点为空,那么只能从右边开始删除
node* r = cur->_right;
if (r->_left == nullptr) {//如果右树没有左树
if (cur != _root) {//如果此时cur不是根root
r->_left = cur->_left;//将cur的左边树链接给右树
if (prev->_left == cur)//考虑父亲的左右,然后再链接
prev->_left = r;
else prev->_right = r;
delete cur;
}
else {
r->_left = cur->_left;//是根root,那么就要先链接
delete cur;//不同考虑父亲的链接
_root = r;
}
}
else {
node* rl = r->_left, * prl = r;//左树不为空
while (rl->_left) { //那么要找最左边的,同时记录父亲
prl = rl;
rl = rl->_left;
}
swap(cur->_key, rl->_key);//交换节点值
prl->_left = rl->_right;//父亲左边要继承rl的右子树
delete rl;
}
}
else {//考虑l不为空,下面逻辑同理
if (l->_right == nullptr) {
if (cur != _root) {
l->_right = cur->_right;
if (prev->_left == cur)prev->_left = l;
else prev->_right = l;
delete cur;
}
else {
l->_right = cur->_right;
delete cur;
_root = l;
}
}
else {
node* lr = l->_right, * plr = l;
while (lr->_right) {
plr = lr;
lr = lr->_right;
}
swap(cur->_key, lr->_key);
plr->_right = lr->_left;
delete lr;
}
}
return true;
}
void inorder() {
inorder(_root);
cout << endl;
}
private:
void destroy(node* root) {
if (root == nullptr)return;
destroy(root->_left);
destroy(root->_right);
delete root;
}
void inorder(node* root) {
if (!root)return;
inorder(root->_left);
std::cout << root->_key << ":"<<root->_val<<" ";
inorder(root->_right);
}
node* _root;
};
#include<iostream>
#include<vector>
#include<algorithm>
#include<time.h>
#include"BStree.h"
using namespace std;
//void erase_test() {
// srand((unsigned int)time(nullptr));
// int len = 10000;
// vector<int>arr(len);
// for (int x = 0; x < len; ++x)arr[x] = rand() + x;
// BStree<int>tree(arr);
// cout << "开始删除\n";
// for (auto num : arr)tree.erase(num);
// tree.inorder();
// cout << "yes";
//}
//int main() {
// BStree<int>tree({ 8, 3, 1, 10,6, 4, 7, 14, 13 });
// vector<int>vec{ 8, 3, 1, 10,6, 4, 7, 14, 13 };
// sort(vec.begin(), vec.end());
// tree.inorder();
// for (auto num : vec) {
// tree.erase(num);
// tree.inorder();
// }
// //erase_test();
// return 0;
//}
int main() {
/*BStree_<string, string>tree({ { "土豆","马铃薯" }, { "西红柿","番茄" }, { "水","H2O" } });
tree.inorder();
cout << tree.find("土豆")->_val << endl;
cout<<tree.find("水")->_val;*/
vector<string>arr{"苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜",
"苹果", "香蕉", "苹果", "香蕉"};
BStree_<string, int>tree;
for (auto& num : arr) {
if (!tree.find(num))tree.insert(num, 1);
else tree.find(num)->_val++;
}
tree.inorder();
return 0;
}
目前,我们的代码还是有很多缺点的:
一、我们写了两份十分相似的类,看着太不好看了。是否能通过什么东西将两个类合成为一个类呢?这里我就只提示用类模版,具体讲解请看后面的set,map的封装博客。
二、封装性不好,我们在用到K-V结构的时候,查找并改变V是有数据泄露的风险的,后面需要用一系列封装进行避免。缺少迭代器,不好于其它数据结构进行关联......
三、搜索二叉树本身的平衡性十分差,不易做到O(logN)级别的时间复杂度,因此要对插入进行进一步的优化,具体优化请看后面的AVL、红黑树。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









