



一、什么是字符串?
字符串是一个或多个字符的序列(包括:数字、字母、空格等)如:
“This is an array of strings” 要注意:双引号不是字符串的一部分。双引号仅告诉编译器它括起来的是字符串
二、如何定义字符串
C语言没有专门用于存储字符串的变量类型(java中 String 这种),字符串都被存储在char类型的数组中。数组都由连续存储单元组成,字符串中的字符被存储在相邻的存储单元中,每个存储单元(一字节)存储一个字符。
在 C 语言中,字符串通常是以字符数组的形式存在的。 我们可以通过直接赋值或使用特定的函数来初始化字符串。
1、字符串常量
双引号括起来的内容称为字符串常量(C语言中不存在字符串变量)。
双引号中的字符和编译器自动加入末尾的\0字符,都作为字符串存储在内存中
#include <stdio.h>
int main()
{
// 在C语言中,字符串字面量(如 "this is test")通常被存储在程序的只读数据段中,
// 并且每次程序中使用相同的字符串字面量时,它们会共享同一个内存地址。
// 而当你将字符串字面量赋值给一个字符数组(如 char arr[] = "this is test";)时,
// 数组 arr 会在栈上分配空间,并将字符串的副本存储在那里。
char arr[] = "this is test";
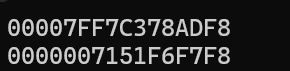
printf("%p \n%p","this is test",arr);
// 第一个% p 打印的是字符串字面量 "this is test" 的地址,这是在程序的只读数据段中的地址。
// 第二个 % p 打印的是数组 arr 的地址,这是在栈上的地址。
// 这里的地址表示的是数组的首地址
}
运行结果:
2、字符数组
字符数组: 存放字符数据的数组
初始化字符数组:
-
我们在定义字符串数组时,如果在程序运行前知道要存储内容,就可以开辟足够大的空间用来存储字符串,或是省略数组初始化声明中的大小(编译器会自动计算数组大小,并开辟出足够大的空间)。
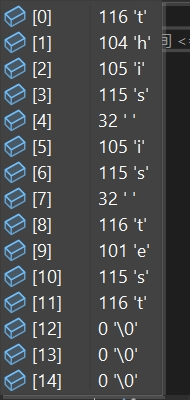
// 初始化字符数组 // 编译器会自动计算数组大小,并开辟出足够大的空间 char arr[] = "this is test"; char arr2[15] = "this is test"; // 在开辟空间大于字符串所需空间时,空间剩余部分会被初始化为‘\0’,测试看一下 printf("%s\n", arr); printf("%s", arr2);
arr【2】测试结果:
- 不常用的初始化
char arr1[] = {'A','B'};
char arr2[] = {'A','B','\0'};
printf("%s\n", arr1); // AB烫烫烫烫烫烫烫烫烫烫烫烫烫烫烫AB
printf("%s", arr2); // AB
3.字符串数组
字符串数组是这样的数组,它的每个元素又都是一个字符串。字符串数组是二维数组。采用二维字符串数组时,可先将二维变成若干个一维数组,其处理方法与一维数组相同。例如:
char s[2][10];
// 该语句定义s是一个具有两个字符串元素的字符串数组,每个字符串元素的长度为10个字符,包括字符串结束符“\0”。
// 一维字符串数组元素的引用,使用的是第一个下标元素,如s[0]表示数组中第一个字符串元素的首地址,s[1]表示数组中第二个字符串元素的首地址。
// 可以使用以下几种方法对字符串数组进行赋值操作。
char s[2][10];
char name[2][8] = {"Mary","Smith"}; // name[0] = "Mary", name[1] = "Smith";
char name[2][8] = { {'M','a','r','y'},{'S','m','i','t','h'}} // 如果定义为name[2][5],就会没有 '\0'
printf("%s \n%s", name[0], name2[1]);
4.字符串中常用函数
sizeof为关键字,获取某个数据类型所占用空间的字节数。
strlen为c语言中<string.h>的库函数,要计算长度的字符串。计算字符串 str 的长度,直到空结束字符,但不包括空结束字符。
eg:
char arr[] = { 'a','b','\0','a','b' };
printf("%d", strlen(arr)); //答案为: 2
程序例:
#include <stdio.h>
int main(){
char str[20] = "Hello";
int array_size = sizeof(str); // 返回 20,即数组的总大小
int string_length = strlen(str); // 返回 5,即有效字符的数量
printf("array_size:%d \nstring_length:%d", array_size, string_length); // 打印结果
}
函数名: strcpy
功 能: 将参数src字符串拷贝至参数dest所指的地址
用 法: char *strcpy(char *dest, const char *src);
返回值: 返回参数dest的字符串起始地址
说 明: 如果参数dest所指的内存空间不够大,可能会造成缓冲溢出的错误情况,在编写程序时需特别留意,或者用strncpy()来取代;
程序例:
#include <stdio.h>
#include <string.h>
int main(void)
{
char string[10];
char str1[] = "abcdefghi";
strcpy(string, str1);
printf("%s\n", string); // 输出:abcdefghi
return 0;
}
函数名: strncpy
功 能: 将字符串src前n个字符拷贝到字符串dest
用 法: char *strncpy(char *dest, const char *src, size_t n);
返回值: 返回参数dest的字符串起始地址
说 明: 不像strcpy(),strncpy()不会向dest追加结束标记’\0’;src和dest所指的内存区域不能重叠,且dest必须有足够的空间放置n个字符;
程序例:
#include <stdio.h>
#include <string.h>
int main(void)
{
char string[10];
char *str1 = "abcdefghi";
strncpy(string, str1, 3);
string[3] = '\0';
printf("%s\n", string); // 输出:abc
return 0;
}
函数名: strcat
功 能: 字符串拼接函数
用 法: char *strcat(char *dest, const char *src);
返回值: 返回dest字符串起始地址
说 明: strcat() 会将参数src字符串复制到参数dest所指的字符串尾部;
dest最后的结束字符’\0’会被覆盖掉,并在连接后的字符串的尾部再增加一个’\0’;
dest与src所指的内存空间不能重叠,且dest要有足够的空间来容纳要复制的字符串;
程序例:
#include <string.h>
#include <stdio.h>
int main(void)
{
char destination[25];
char *blank = " ", *c = "C++", *Borland = "Borland";
strcpy(destination, Borland);
strcat(destination, blank);
strcat(destination, c);
printf("%s\n", destination); // 输出:Borland C++
return 0;
}
函数名: strncat
功 能: 将n个字符追加到字符串的结尾
用 法: char *strncat(char *dest, const char *src, size_t n);
返回值: 返回dest字符串起始地址
说 明: strncat()将会从字符串src的开头拷贝n个字符到dest字符串尾部,dest要有足够的空间来容纳要拷贝的字符串;
如果n大于字符串src的长度,那么仅将src全部追加到dest的尾部;
strncat()会将dest字符串最后的’\0’覆盖掉,字符追加完成后,再追加’\0’;
程序例:
#include<stdio.h>
#include<string.h>
int main()
{
char arr[100] = "hello world\n";
char arr2[30] = "你好,大学";
strncat(arr, arr2, 1000);
printf("%s\n", arr);
return 0;
}

函数名: strcmp
功 能: 字符串比较
用 法: int strcmp(const char *s1, const char *s2);
返回值: 根据ASCII码比较,若参数s1和s2字符串相同则返回0,s1若大于s2则返回大于0的值,s1若小于s2则返回小于0的值
程序例:
#include <string.h>
#include <stdio.h>
int main(void)
{
char a[] = "aBcDeF";
char b[] = "AbCdEf";
char c[] = "aacdef";
char d[] = "aBcDeF";
printf("strcmp(a, b) : %d\n", strcmp(a, b)); // 输出:1
printf("strcmp(a, c) : %d\n", strcmp(a, c)); // 输出:-1
printf("strcmp(a, d) : %d\n", strcmp(a, d)); // 输出:0
return 0;
}

















 1241
1241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









