






目录
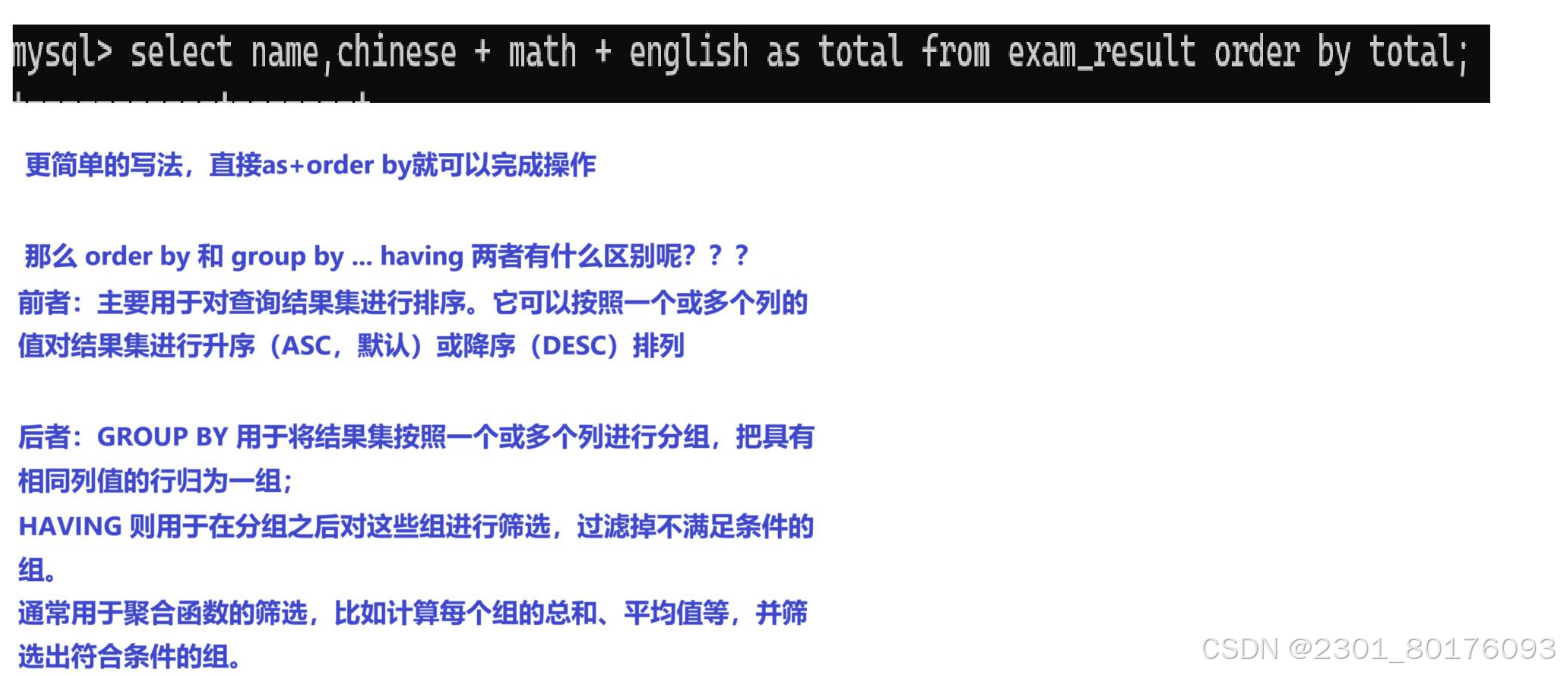
order by和group by...having都能完成任务筛选,两者有什么区别???
1.CRUD
接下来一一解释这个功能
把数据库比作一个“仓库”,表比作“货架”,数据比作“货物”。
select 查询 可以比作“从仓库里挑选特定的货物”。
insert 新增 数据可以比作“往仓库里添加新货物”。
update 修改 数据可以比作“更换仓库里货物的标签”。
delete 删除 数据可以比作“从仓库里移除货物”。
2.新增(C)
2.1语法
insert into 表名 values (值,值),(值,值);2.2单行插入 + 全列插入

2.3多行数据+指定列插入

2.4如何获取当前的时间?
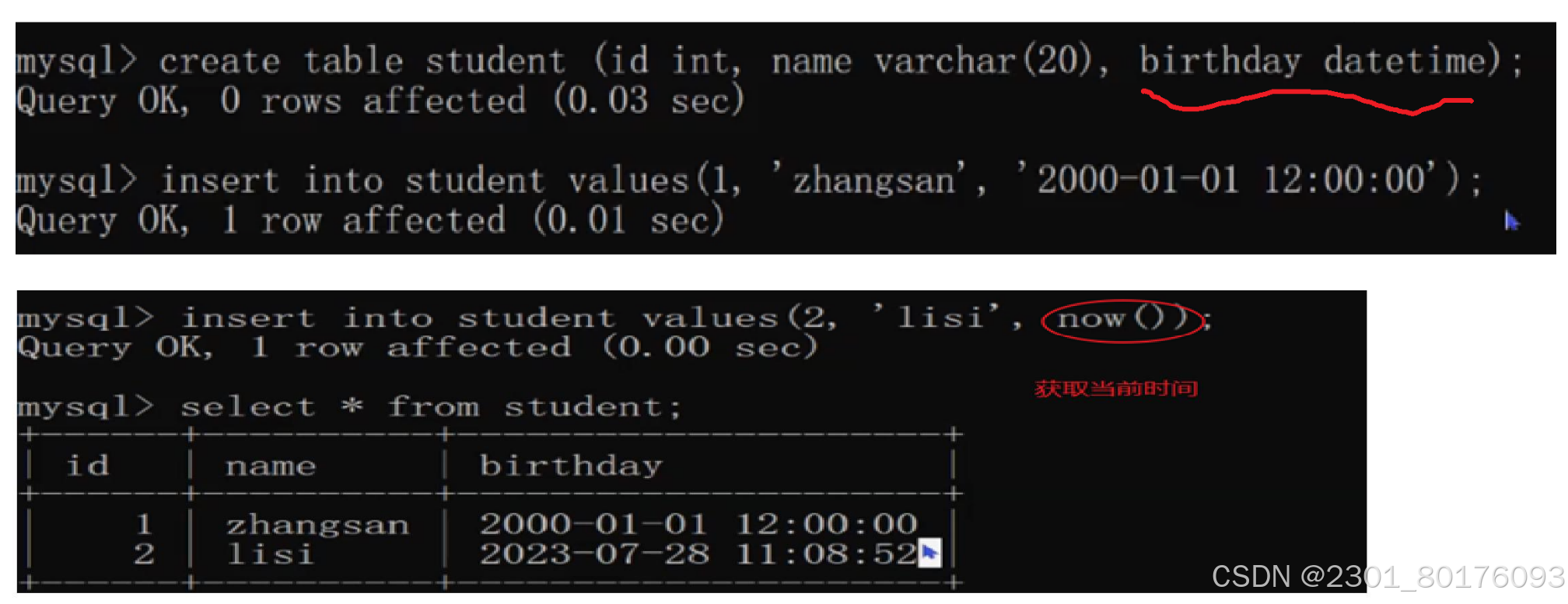
3.查询(R)
//插入使用的数据
-- 创建考试成绩表
create table exam_result (
id INT,
name VARCHAR(20),
chinese DECIMAL(3,1),
math DECIMAL(3,1),
english DECIMAL(3,1)
};
--插入测试数据
insert into exam_result (id,name,chinese,math,english) values
(1,'唐三藏',67,98,56),
(2,'孙悟空',87.5,78,77),
(3,'猪悟能',88,98.5,90),
(4,'曹孟德',82,84,67),
(5,'刘玄德',55.5,85,45),
(6,'孙权',70,73,78.5),
(7,'宋公明',75,65,30);3.1全列查找
语法
select * from 表名称 注意
当表中存在数据过多时,使用该语句就会造成电脑卡死!!!
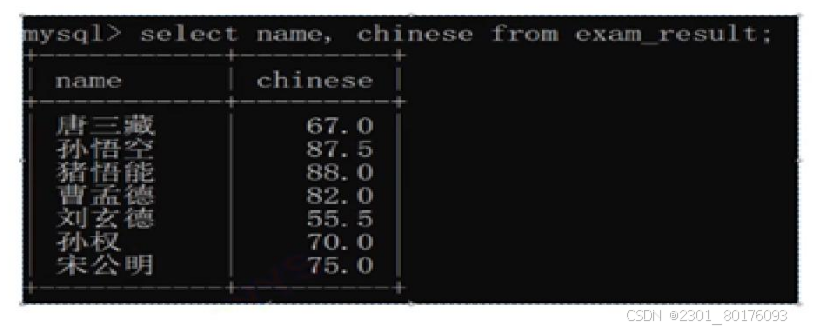
3.2指定列查询
语法
select 列名,列名... from 表名称;注意
使用这个的好处就是,当一个表中的数据非常多的时候,某个场景下的操作,只需要关注其中的几个列来操作即可
3.3 查询字段为表达式
表达式不包含字段
select id,name,10 from exam_result;
表达式包含一个字段
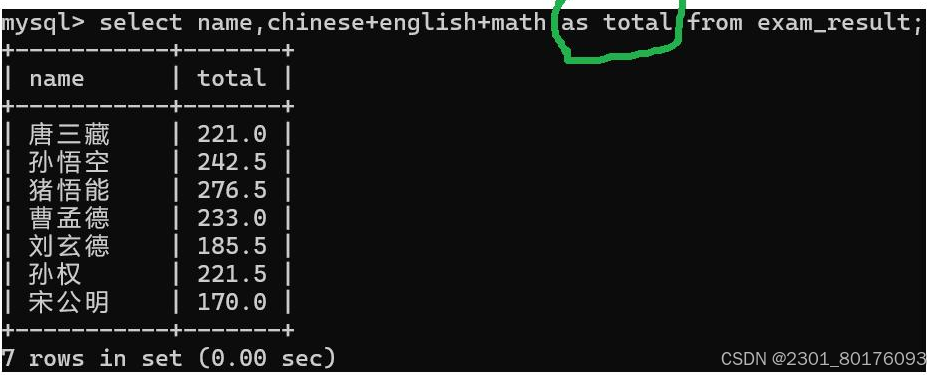
select id,name,english+ + 10 from exam_result;表达式包含多个字段
select id,name,chinese + math + english from exam_result;例子实践

3.4别名
语法
select 表达式 as 别名 from 表名;别名的解释
就是另一个名字,相当于小名,外号,花名,及时雨宋江等等
3.5去除重复的数据
语法
select distinct 表达式(数据式子完全相同) from 表名称;
例子
--取出重复的叫孙悟空
select distinct * from exam_result where name = '孙悟空';3.6 order by 排序
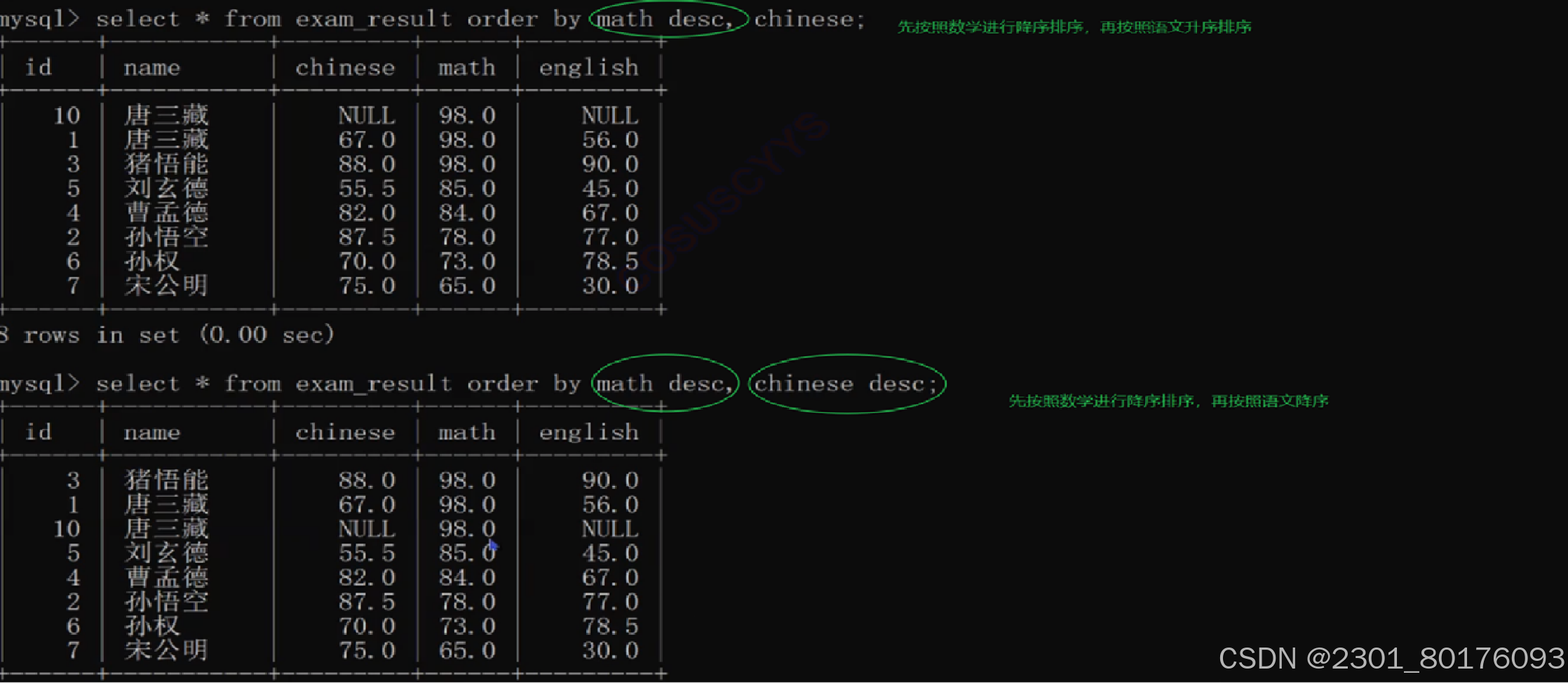
语法
select 表达式 order by 表达式 (desc)
//默认就是升序,如果想表达降序的话,desc表示降序需要写例子
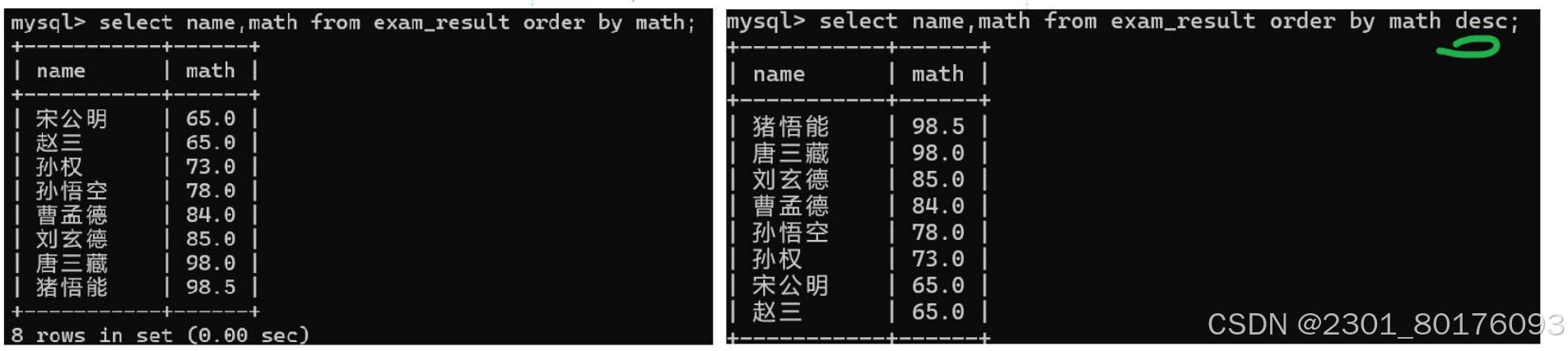
-- 按数学成绩升序排序
SELECT * FROM exam_result ORDER BY math ASC;
-- 按语文成绩降序排序
SELECT * FROM exam_result ORDER BY chinese DESC;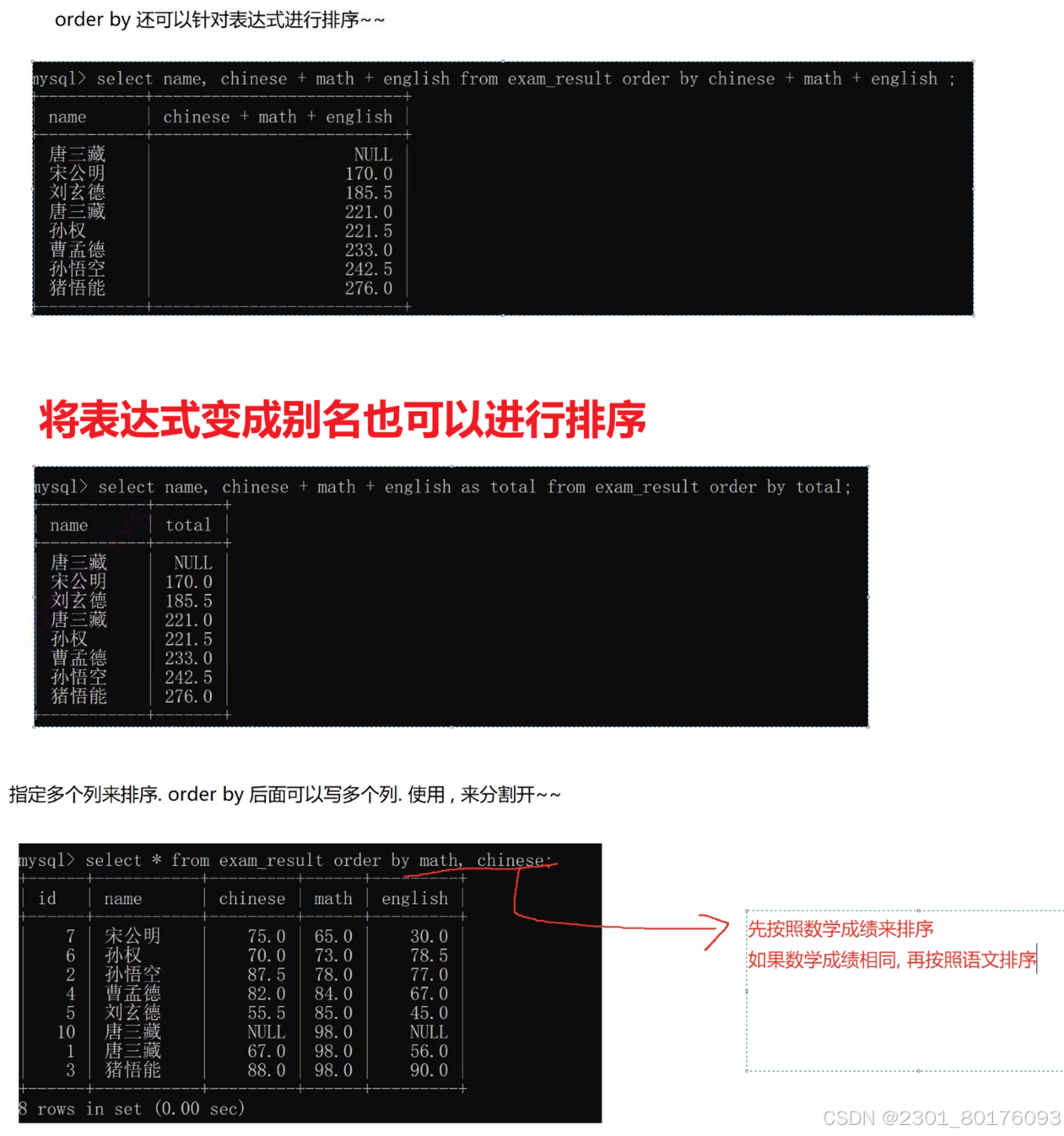
注意
排序是针对的是临时的数据,不管怎么样原始的数据都不发生改变。
3.7条件查询(where)
比较运算符
>,>=,<,<=,
等于=(NULL不安全,例如 NULL = NULL 的结果是 NULL), <=> (NULL安全,例如 NULL <=> NULL 的结果是 TRUE(1))
不等于!=,<>
范围匹配 between ..a. and ..b. ,[a,b],如果a<= value <= b,返回TRUE(1)
范围任意一个 option中的,返回TRUE(1)
是NULL IS NULL
不是NULL IS NOT NULL
模糊匹配 like %表示任意多个字符;_表示任意一个字符
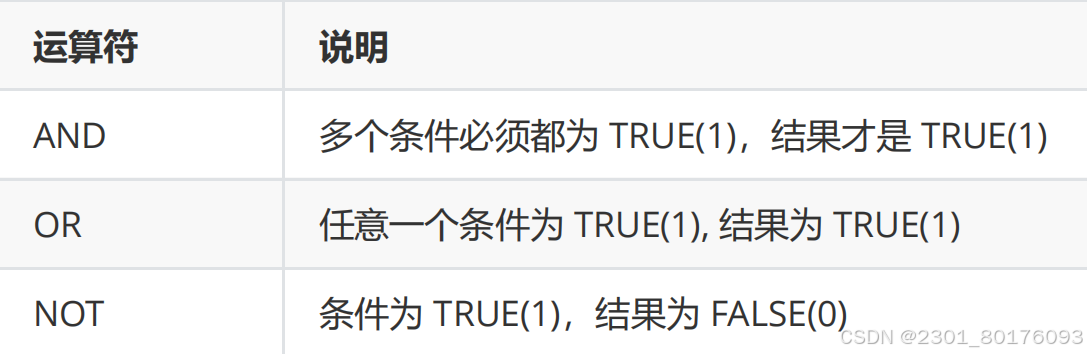
逻辑运算符
例子
基本查询
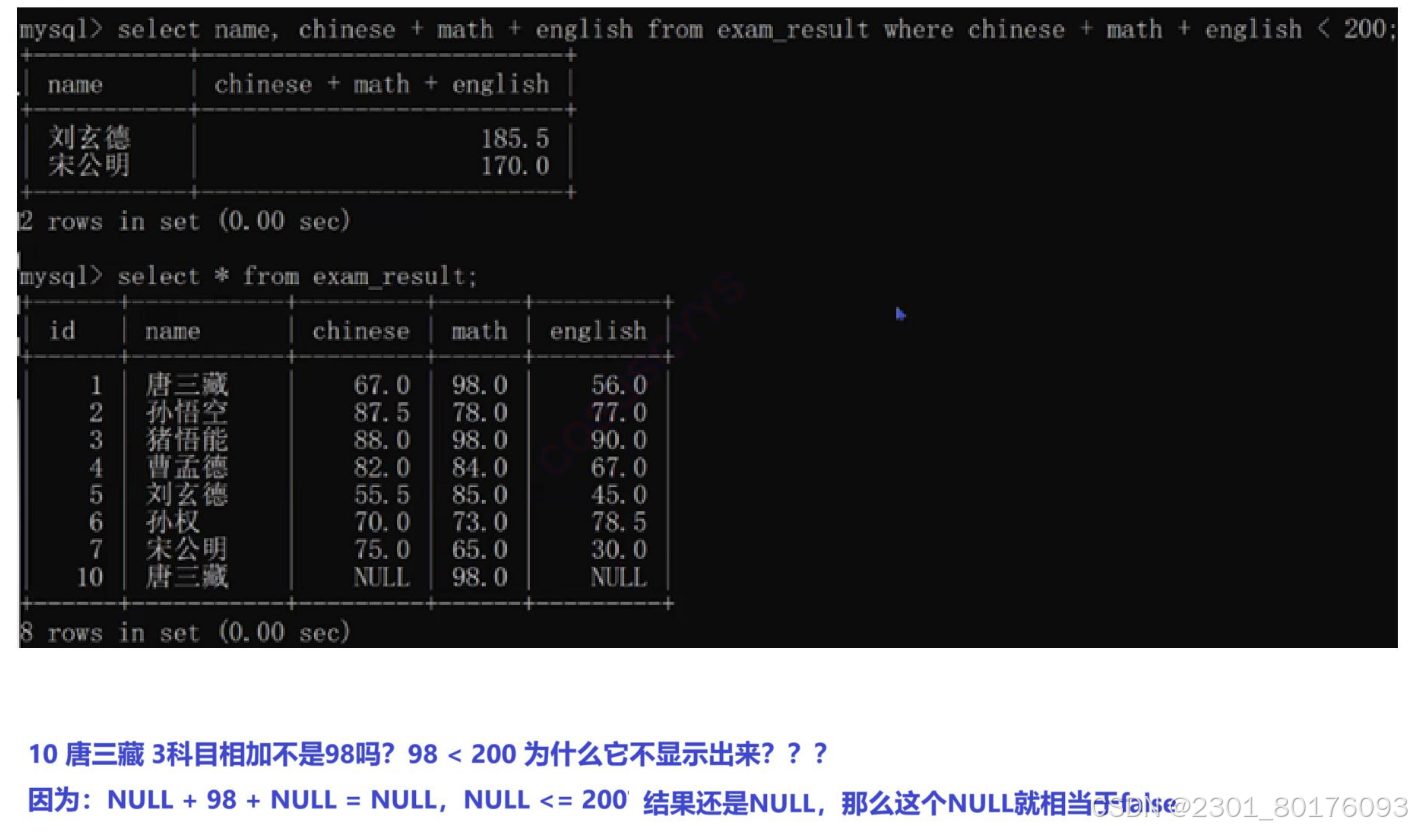
-- 查询英语不及格的同学及英语成绩 ( < 60 )
SELECT name, english FROM exam_result where english < 60;and和or
select * from exam_result where chinese > 80 and english > 80;
select * from exam_result where chinese > or english > 80;范围查询
1.between ... and ...
select name,chinese from exam_result where chinese between 80 and 90;2.in
select name,math form exam_result where math in (58,59,98,99);模糊查询
like
select name from exam_result where name like '孙%'; -- 名字开头含有是孙
select name from exam_result where name like '孙_'; -- 名字开头是孙,且只有2个名字
select name from exam_result where name like '%孙%'; -- 名字含有孙即可
NULL的查询:IS[NOT]NULL
select name,abc form student where abc is not NULL; -- 查询已知
select name,abc form student where abc is NULL; -- 未知
3.8分页查询
语法
select ... from 表名称 ... limit n / s,n / n offset s;
为什么使用这样的查询???

例子
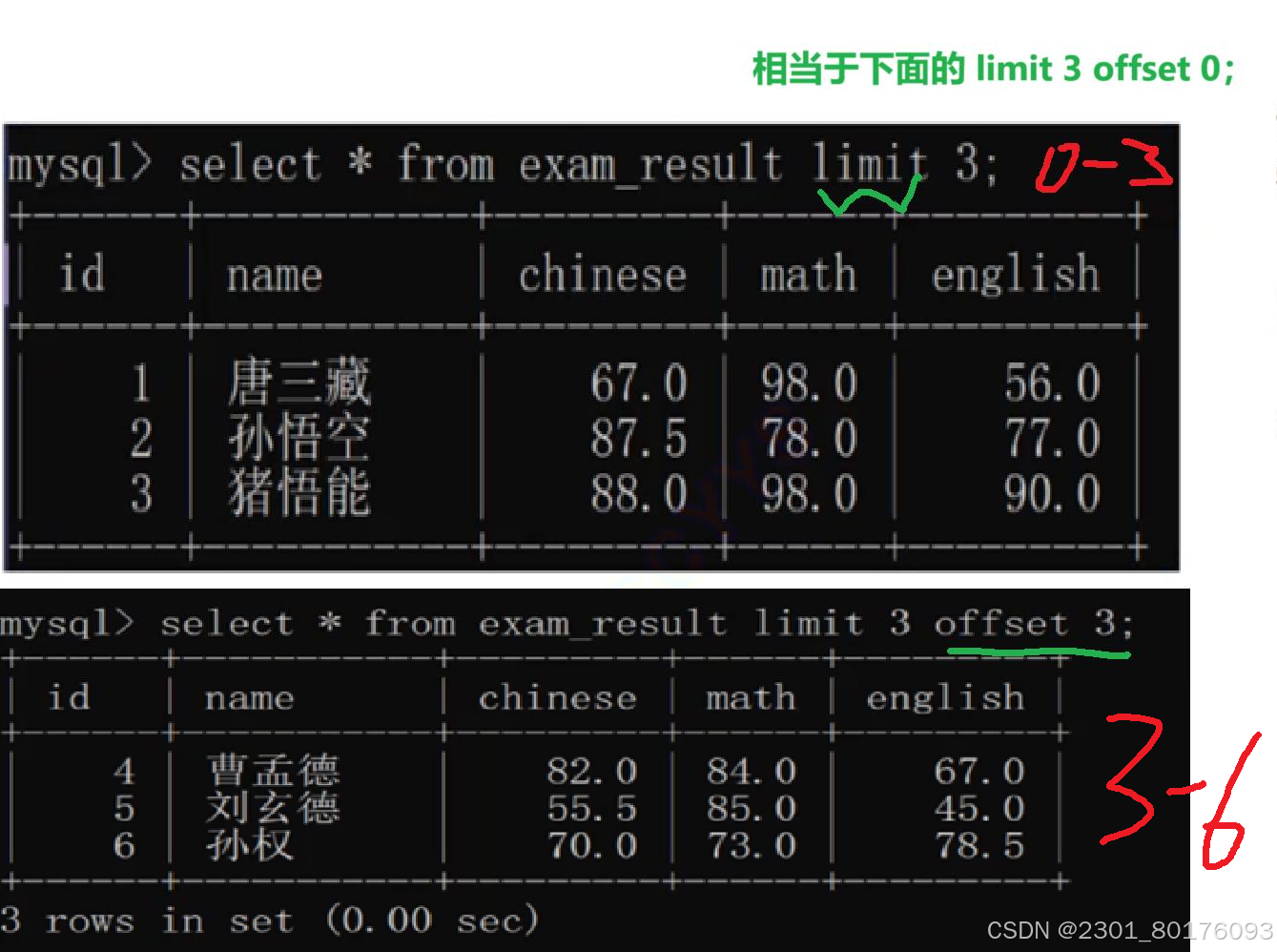
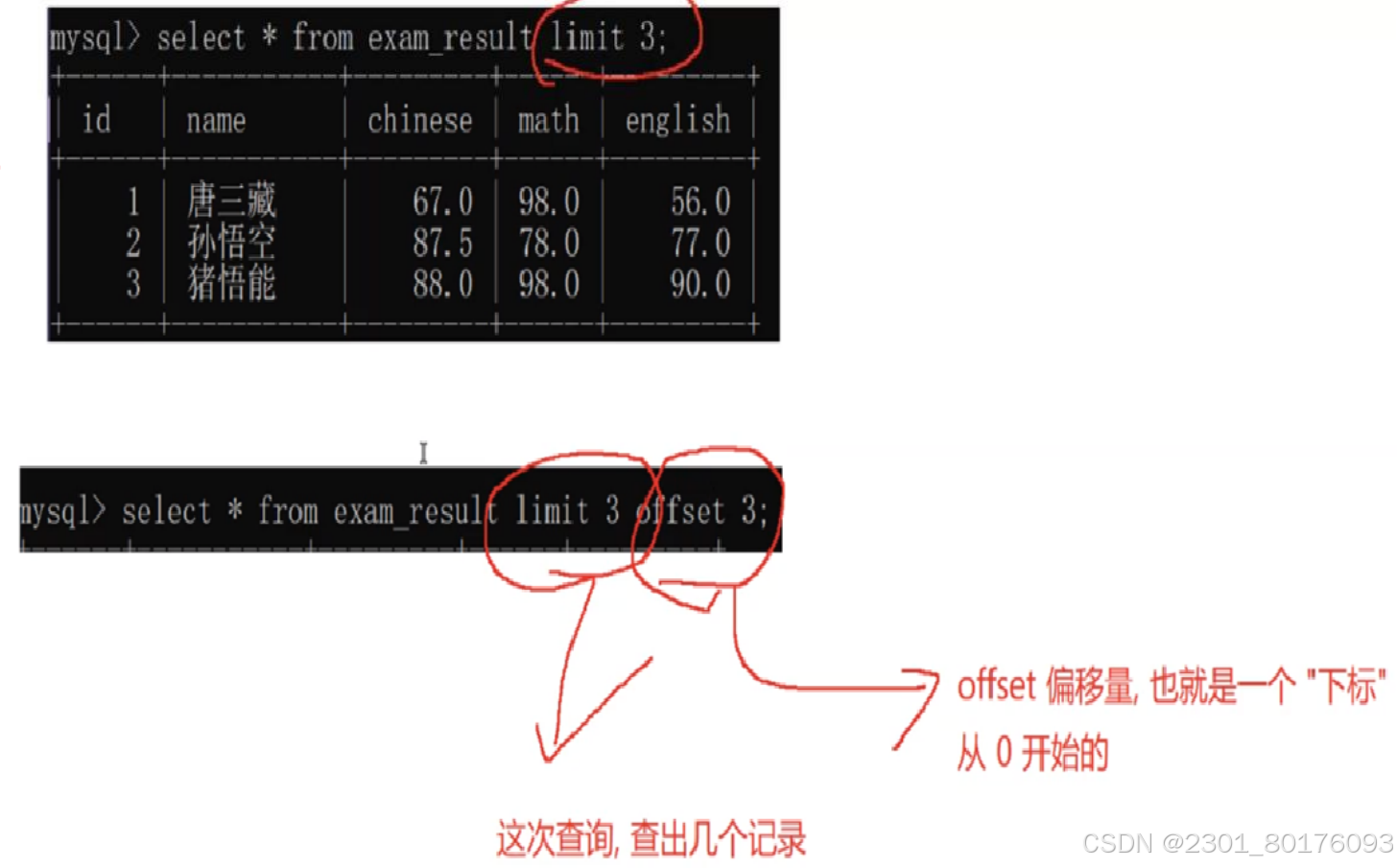
意思就是从3下标开始,然后将其往下查询3个
总结

小思考!!!
能否用as来简短代码长度?

select的执行顺序是怎么样?

order by和group by...having都能完成任务筛选,两者有什么区别???
为什么筛选不出完整的200以下的人???
=和<=>都是等于,那么两者区别是什么???
= 是普通的等于运算符,但对 NULL 不安全。例如:NULL = NULL 的结果是 NULL。
<=> 是 NULL 安全等于运算符,可以正确处理 NULL。例如:NULL <=> NULL 的结果是 TRUE。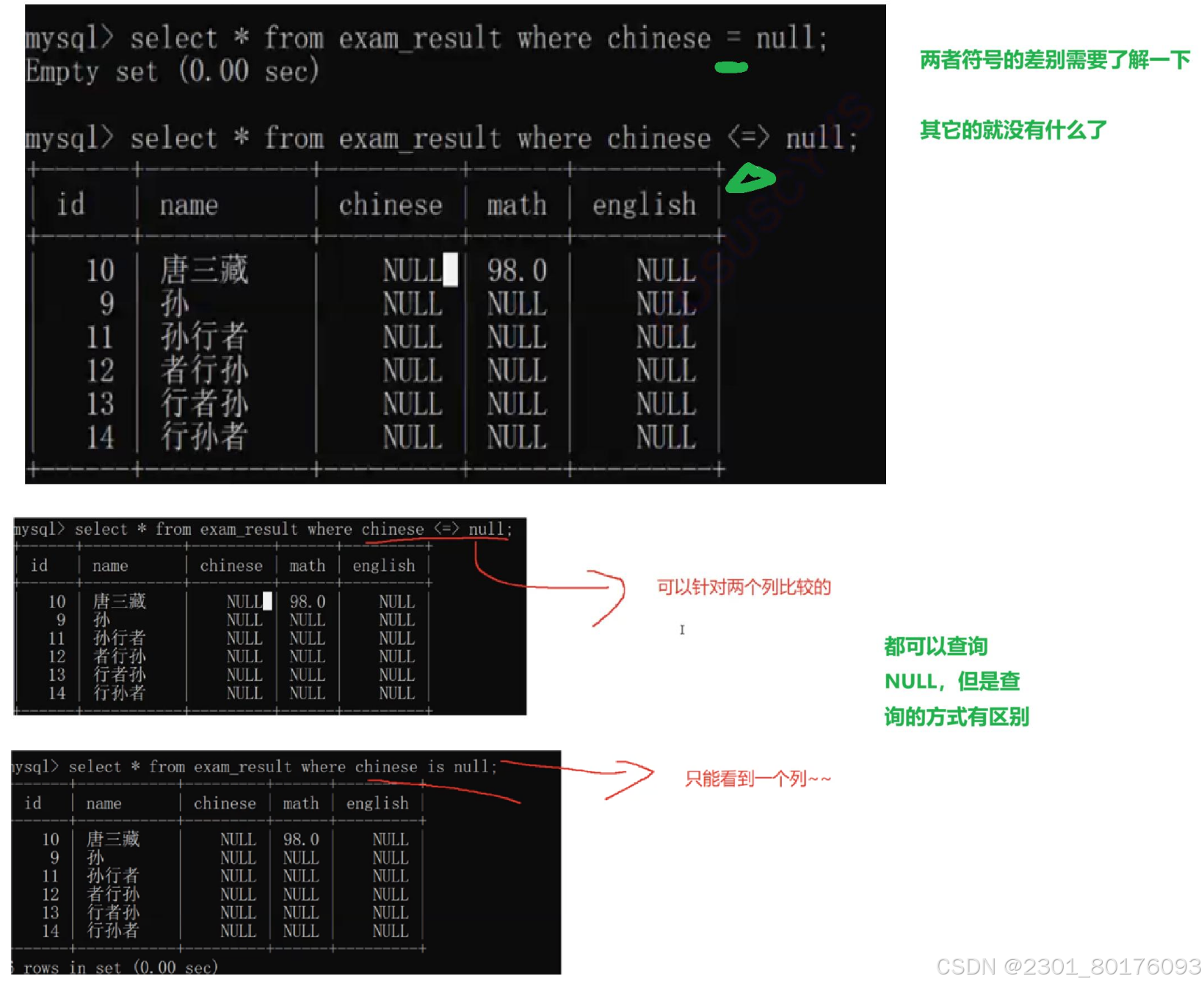
4.修改(U)
语法
update 表名称 set 操作;例子
updata exam_result set math = 80 where name = '孙悟空'; -- 将孙悟空的成绩变成80分
updata exam_result set math = math * 2; -- 将所有同学的语文成绩变成原来的2倍
5.删除(D)
语法
delete from 表名称 ... ;例子
delete from exam_result where name = '孙悟空'; -- 删除孙悟空的成绩
delete from exam_result; -- 删除整张表
delete 和 drop 两者删除的差别
语法
delete from 表名称;
drop 表名称;例子展示
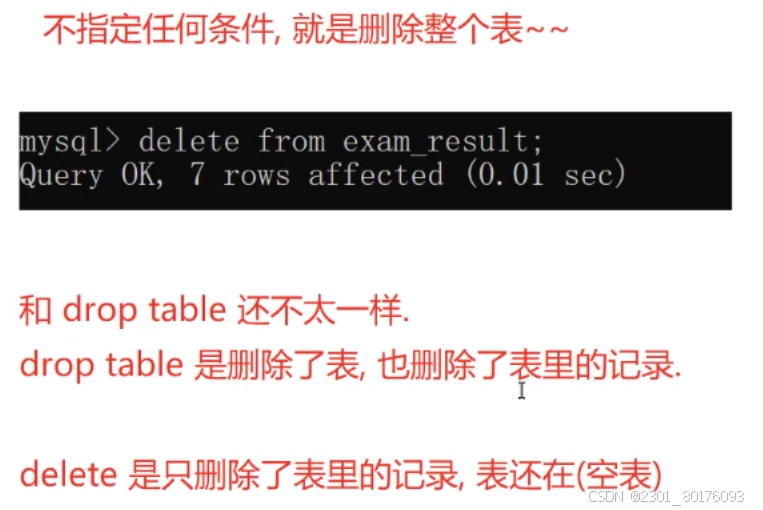
简单理解就是,有一个盒子,盒子里面有饼干。
delete就是把饼干吃了,剩下盒子;drop是盒子和饼干都吃了。
注意
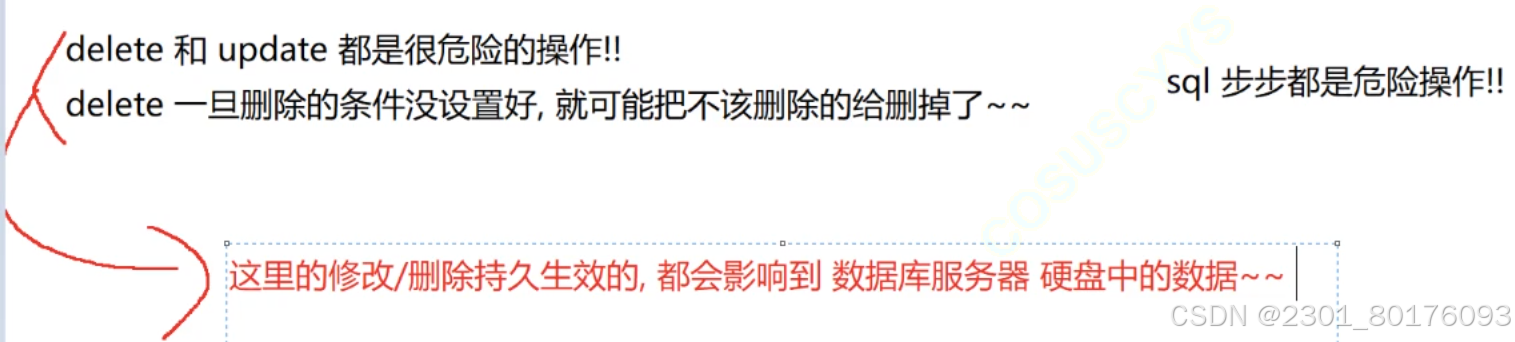
个人思考
通过学习 CRUD 操作,我明白了数据库操作的核心是围绕数据的增删改查展开的。新增(C)、查询(R)、修改(U)、删除(D)这四种基本操作贯穿了数据库的整个生命周期。每种操作都有其特定的语法和注意事项,比如新增时需要注意表的结构和字段类型,查询时需要关注数据的安全性和性能优化等等。这些细节虽然看似繁琐,但却是确保数据准确性和完整性的重要保障。
在实际开发中,查询操作是最常用的。我以前在开发一个图书管理系统的项目时,经常需要查询图书的信息,比如根据图书名称、作者、分类等条件来筛选图书。在这个过程中,我逐渐意识到掌握查询的优化技巧非常重要。比如,避免全列查询可以提高查询效率。当只需要获取特定的列时,明确指定列名而非使用 *,可以减少数据的传输量和处理时间。例如:
-- 不好的写法(全列查询)
SELECT * FROM books WHERE author = '李白';
-- 好的写法(指定列查询)
SELECT title, author, publish_date FROM books WHERE author = '李白';此外,合理使用索引也是优化查询的关键。索引就像书的目录一样,能够快速定位到需要的数据。在项目中,我为 author 和 title 列创建了索引,使得查询速度有了显著的提升。总之,学习 CRUD 操作让我更加深入地理解了数据库的工作原理,并且能够在实际开发中更加高效地管理和操作数据。

















 2827
2827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









