







上一篇文章讲到ParseBeanDefinitions是如何进行解析的,这一篇是要先解决这个问题
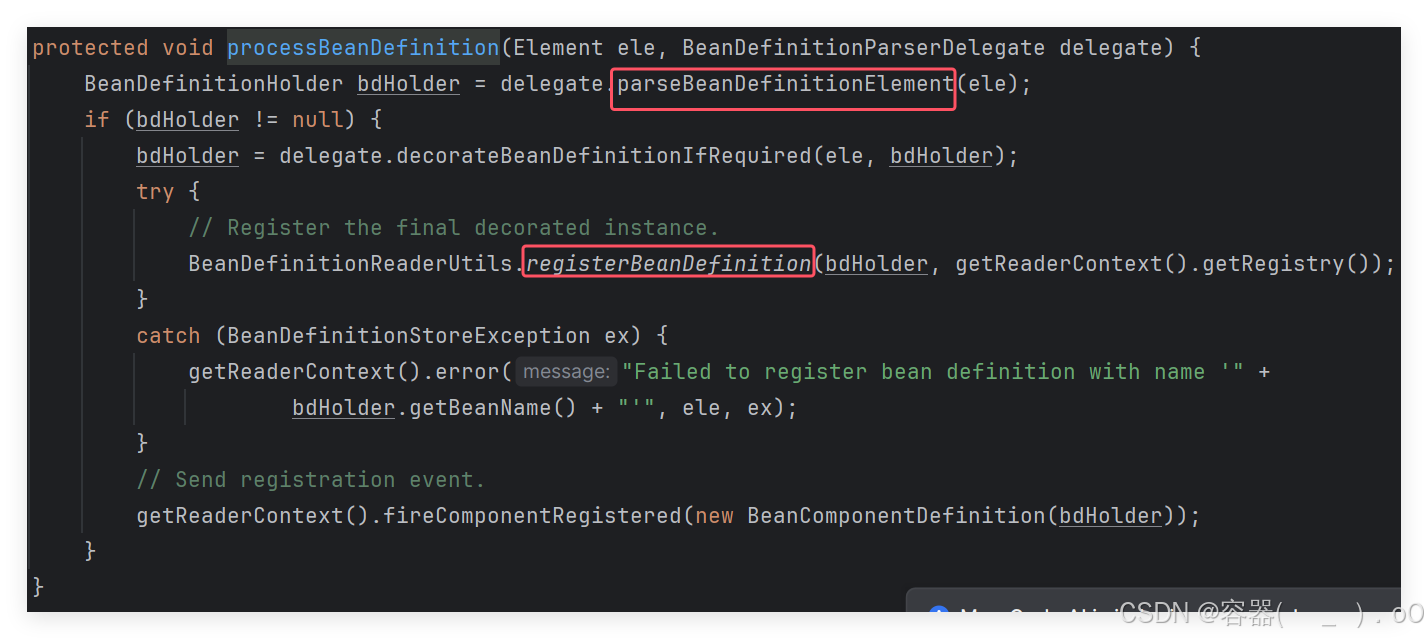
第一个问题:通过调用parseBeanDefinitionElement,spring是如何解析xml的标签元素用来封装beandefinition对象的;第二个问题,得到bean对象后,registerBeanDefinition是如何进行Bean信息的注册。
Spring中对于bean标签的定义信息是如何解析的
对于第一个问题,parseBeanDefinitionElement方法中,
 首先获取bean标签的id属性,之后获取bean标签的name属性,如果name属性不为空,就将获取的name字符串按照,或者;方式分割成数组,如果bean标签id属性不存在,name属性存在,就把第一个name属性拿出来作为bbean的id,之后进行校验bean的id是否唯一,并真正的开始解析bean的标签属性,在如下方法中。
首先获取bean标签的id属性,之后获取bean标签的name属性,如果name属性不为空,就将获取的name字符串按照,或者;方式分割成数组,如果bean标签id属性不存在,name属性存在,就把第一个name属性拿出来作为bbean的id,之后进行校验bean的id是否唯一,并真正的开始解析bean的标签属性,在如下方法中。

在这个方法中,获取bean标签的class属性,parent属性,之后创建一个BeanDefinition对象,并将className和parent属性传入,解析一些属性,其中来看看解析除了id,name,class,parent这个方法是如何进行实现的。
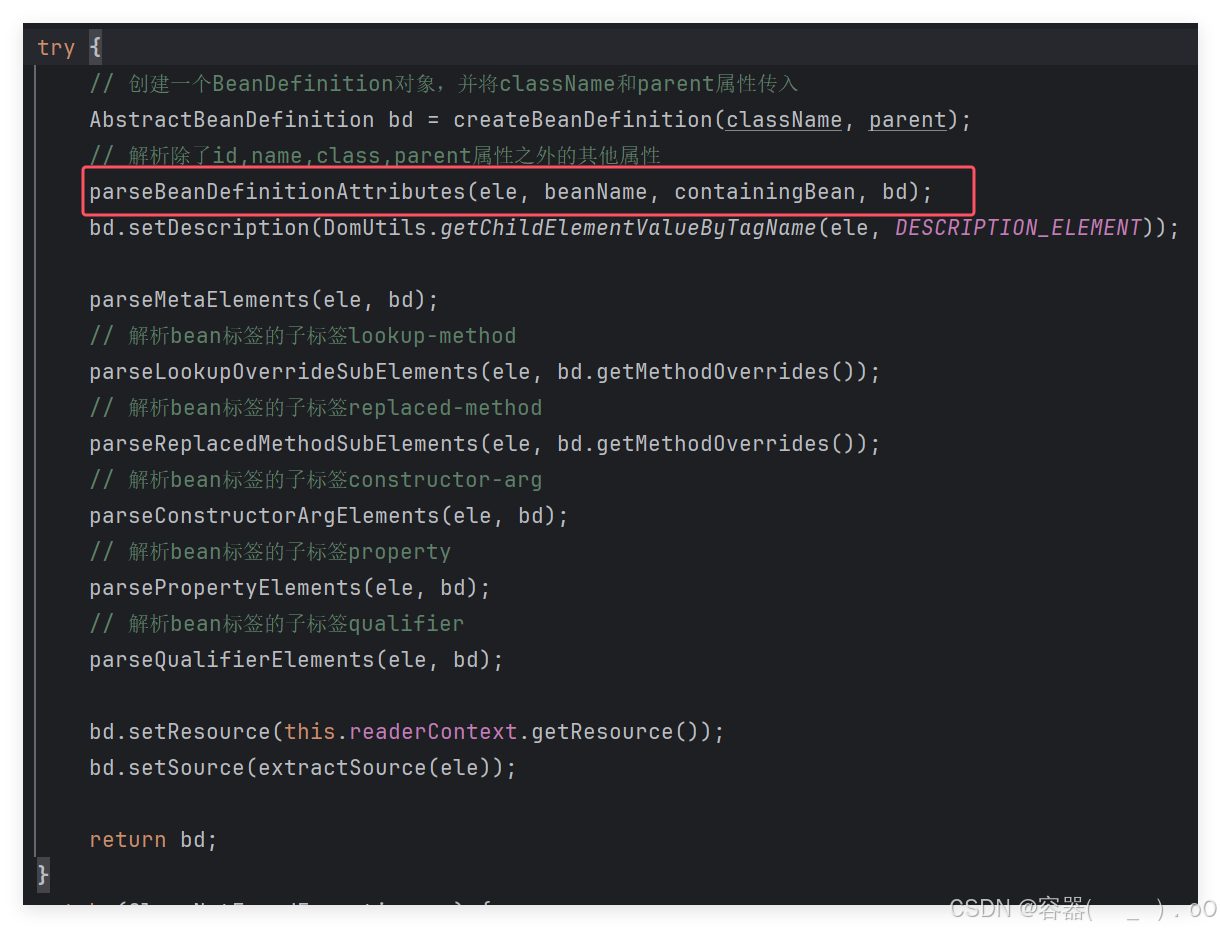
它主要是从给定的XML元素中提取属性值,并相应的更新或者设置AbstractBeanDefinition对象中的属性,包括但不限于scope、抽象性、懒加载初始化、自动装配模式、依赖项、是否为主要候选者、初始化方法、销毁方法以及工厂方法等属性。
在后面的子标签解析中,重点看下解析property标签的方法,因为在bean标签中,经常使用property标签进行依赖注入,在这个方法中使用循环,为什么呢?因为bean标签里面可能会有多个property子标签,需要循环解析。
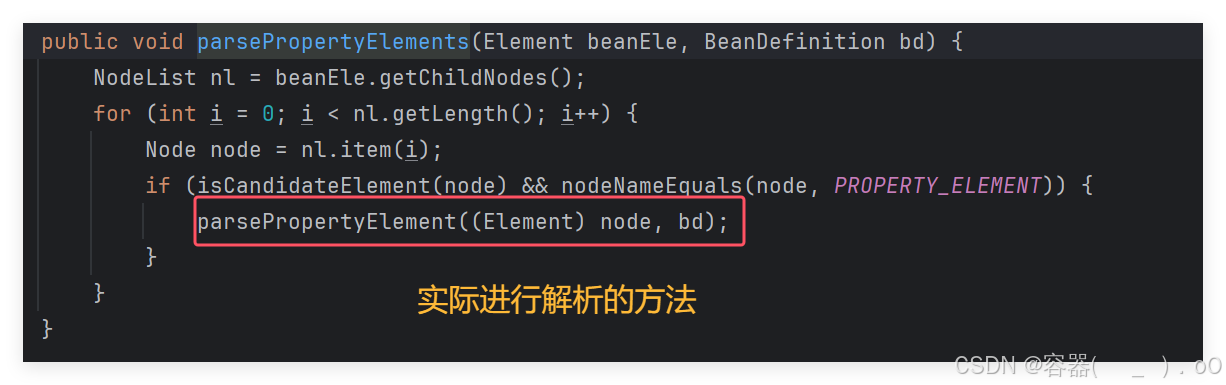
String propertyName = ele.getAttribute(NAME_ATTRIBUTE); Object val = parsePropertyValue(ele, bd, propertyName); PropertyValue pv = new PropertyValue(propertyName, val); parseMetaElements(ele, pv); pv.setSource(extractSource(ele)); bd.getPropertyValues().addPropertyValue(pv);
这三行表示的是拿到name和value值,将其封装到PropertyValue里,之后将拿到的pv设置到BeanDefinition里面。这样子BeanDefinition就解析完成。
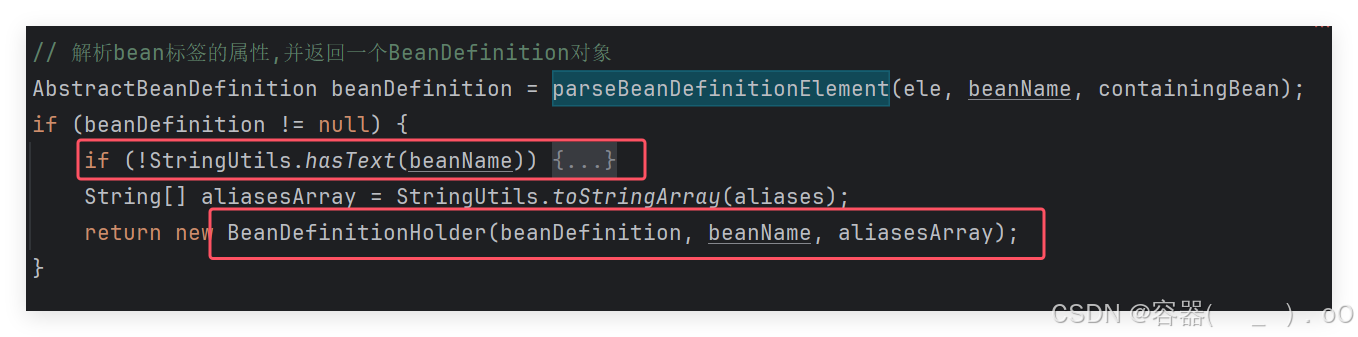
解析完成之后,为什么还需要有一个!StringUtils.hasText(beanName)来判断beanname不存在呢?他其实是为了防止一种极端情况,bean的id属性,name属性都不存在,此时spring框架会按照自己的算法自动生成一个bean的名称。由于是BeanDefinitionHolder对象进行接受,因此需要进行一次包装

总的来说:首先判断是否是一个bean标签{delegate.nodeNameRquals(ele,BEAN_ELEMENT)},s是的话通过processBeanDefinition进行解析。processBeanDefinition是先获取bean里面的id和name属性,然后将name属性放到一个List集合中。如果bean的id不存在,就将第一个元素取出来放到id中,之后进行唯一性校验,校验通过后真正的进行对象的解析,在parseBeanDefinitionElement中主要对bean的属性做一个解析,对子标签进行解析。解析完毕后做一个极端的校验,如果id和name都没有,spring按照自己的方式进行自动生成一个bean的名称,最后将完整的解析的信息封装到BeanDefinitionHolder中
Spring中对于bean标签的定义信息是如何封装的
是不是封装到一个map集合中,map的key就是bean的id,map的value就是bean的对象?
这个问题就是BeanDefinition对象解析出来后,是如何进行注册的。

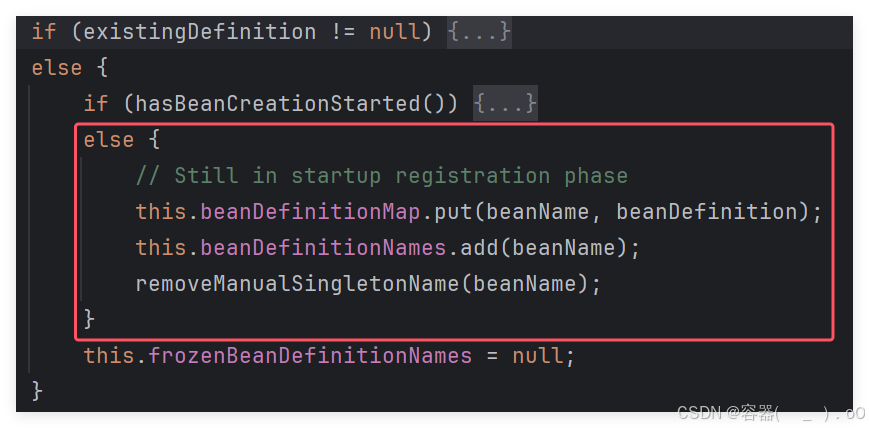
这个方法里,首先获取bean的名称,然后调用registerBanDfinition这个方法,用来注册bean的定义信息。它是使用bean的定义信息注册器进行注册,他这里设计成接口

DefaultListableBeanFactory用来帮助进行定义信息的注册,DefaultListableBeanFactory是 Spring 框架中的一个核心实现类,它实现了BeanDefinitionRegistry和AutowireCapableBeanFactory接口,并继承AbstractAutowireCapableBeanFactory类。因此,它不仅整合了其他 Bean 工厂的功能,还提供了额外的能力来注册和管理 Bean 定义信息。在这个bean工厂里,有下面这个方法。
其中的就是从map集合中通过bean的名称获取bean的定义信息,这就验证了bean的定义信息确实是往mapper去放的
下面的就是注册过程的核心代码,至此,完成注册功能。
整个过程
首先XmlBeanFactory类中的XmlBeanFactory方法中的this.reader.loadBeanDefinitions为加载bean定义信息的入口方法。这个方法中又调用loadBeanDefinitions进行一次包装,在这个方法中首先获取字节输入流(InputStream),之后通过SAX技术进行解析输入流得到InputSource,之后调用doLoadBeanDefinitions再次进一步的解析。这个方法里,先把InputSource解析成Document对象,之后调用registerBeanDefinitions进行定义信息的注册。registerBeanDefinitions方法里通过documentReader进行定义信息的注册,documentReader调用registerBeanDefinitions,registerBeanDefinitions又调用了doRegisterBeanDefinitions进行注册,首先判断是否是bean标签,是的话调用parseBeanDefinitions进行解析,循环进行解析,因为可能又很多标签,它分为基本标签和自定义标签,由于bean是基本标签,它走的是基本标签的逻辑,即pareseDefaultElement这个方法,又在这个方法中进入processBeanDefinition这个方法专门进行bean标签的解析,它将其先封装成一个对象,就是前面讲的如何进行封装。首先调用perseBeanDefinitionElement,这个方法先获取bean标签的id和name,还要做一些唯一性校验,完成后调用parseBeanDefinitionElement做一个真正的对象封装,这个封装方法首先获取class属性和parent属性,获取这些属性封装成对象后,还需要解析除了id,name,class,parent属性之外的其他属性,之后解析bean标签的一些子标签,最后对定义信息做一个包装。之后bean工厂帮助进行注册,获取bean的名称,通过注册器(DefaultListableBeanFactory)来进行注册,在这个注册器里首先是先进行一些校验,后面进行两次进else,就完成了封装和注册。最后发送注册完成的事件。

自定义标签BeanDefinition解析
自定义标签的格式如下,每个自定义标签就是开启某一项功能
<aop:config>
<mvc:annotation-driven>
<tx:annotation-driven>自定义标签能够被spring框架解析,背后都有对应的类进行处理,这里以<mvc:annotation-driven>为例。
现在已知在配置文件中引入自定义标签中,会把spring.schemas中对应的信息在配置文件中显示出来,那么这个自定义是如何被解析的。在spring.handler,有个类,它就是处理spring.schemas的所有内容。在这个类中,它为每一个不同的标签配置一个对应的自定义解析器,这个解析器就可以把对应标签的信息解析成对应的beanDefinition对象。

这个类中的parse方法是对<mvc:annotation-driven>进行解析,解析封装为BeanDefinition
自定义标签对应的schemas信息在spring.schemas中进行定义,而spring.schemas当中的信息交给spring.handlers中的类来进行处理,这个类规定不同的标签使用不同的解析器
Spring工厂创建Bean的整个流程
spring工厂可以做的事情:
- 解析xml配置文件,封装并注册BeanDefinition
- 创建对象
spring创建对象的过程
对象的创建底层是依据反射的机制,但是在配置文件使用<constructor-arg>这个标签的话,不是进行的反射机制。对象创建完成之后,需要进行属性注入,方式有set,构造函数,自动注入(配置文件中加入autowire),注解,容器注入。对象的创建有
- 使用bean标签进行管理,底层走的反射
- 工厂创建,实例化工厂和静态实例化工厂
- 实现FactoryBean接口
容器注入:要求bean所属的类必须实现Aware接口,例如BeanNameAware,BeanDactoryAware.手动注入在容器注入之前。
Bean的前置处理,要求Bean所属的类必须实现BeanPostProcessor接口里面的postProcessBefo-reInitialization方法,初始化如果有init-method,就会执行init-method属性指定的方法,当Spring容器创建了Bean实例并设置了其属性之后,它会自动调用该方法。如果bean所属的类实现了initializingBean接口,必须实现afterPropertiesSet方法。Spring容器会在设置完Bean的所有属性后调用此方法。后置处理必须实现Bean-PostProcessor接口里面的postProcessAfterInitialization方法。
Bean的生命周期
1.实例化(Instantiation):首先,Spring容器根据Bean定义的信息创建Bean的实例。
2.属性赋值(Populate Properties):一旦实例化完成,Bean的属性将会被赋值,包括通过构造函数参数或setter方法设置依赖。
3.前置处理(BeanPostProcessor's postProcessBeforeInitialization 方法):在任何初始化逻辑开始之前,如果配置了实现了BeanPostProcessor接口的处理器,则会调用其postProcessBeforeInitialization方法。
4.初始化(Initialization):
5.如果Bean实现了InitializingBean接口,则调用afterPropertiesSet()方法。
如果通过XML或其他配置方式指定了init-method,则调用该方法指定的初始化方法。
这两个步骤(如果有配置的话)按顺序执行。
6.后置处理(BeanPostProcessor's postProcessAfterInitialization 方法):在Bean的所有初始化工作完成后,如果配置了实现了BeanPostProcessor接口的处理器,则会调用其postProcessAfterInitialization方法。
7.使用(Usage):此时,Bean已经准备好并可以被应用程序使用。
8.销毁(Destruction):当应用上下文关闭时,如果Bean实现了DisposableBean接口,则调用destroy()方法;或者如果通过配置指定了destroy-method,则调用该方法指定的销毁方法。根据BeanDefinition对象,又是如何创建Bean对象的?
1. 解析Bean定义
首先,Spring容器会读取并解析Bean定义,这通常是从XML文件、注解或Java配置类中获取的。解析的结果是生成一个或多个BeanDefinition对象,每个对象都包含了一个特定Bean的所有必要信息,如类名、作用域、构造函数参数、属性值等。
2. 注册Bean定义
一旦解析完成,BeanDefinition对象会被注册到BeanFactory中,通常是DefaultListableBeanFactory。这个过程允许Spring容器知道需要管理哪些Bean,并且为每个Bean保留了详细的配置信息。
3. 实例化Bean
当需要使用某个Bean时,Spring容器将根据其BeanDefinition来决定如何实例化它:
通过反射调用构造方法:默认情况下,Spring容器使用Java反射API来调用Bean类的无参构造函数来实例化Bean。如果Bean定义指定了构造函数参数,则Spring会尝试匹配合适的构造函数,并传递相应的参数。
静态工厂方法或实例工厂方法:如果Bean定义指定了工厂方法(无论是静态的还是实例的方法),Spring将不会直接实例化Bean类,而是调用指定的工厂方法来创建Bean实例。
4. 属性填充
一旦Bean被实例化后,Spring容器会按照BeanDefinition中的配置,设置Bean的属性值,这包括:
设置依赖的其他Bean
设置基本属性值
调用setter方法设置属性
5. 初始化阶段
在Bean实例化和属性填充完成后,进入初始化阶段:
如果实现了BeanNameAware, BeanFactoryAware, 或 ApplicationContextAware接口,相关的方法会被调用。
如果实现了BeanPostProcessor接口,postProcessBeforeInitialization方法会被调用。
如果实现了InitializingBean接口,afterPropertiesSet方法会被调用。
如果指定了init-method,则调用该方法。
6. 使用Bean
此时,Bean已经准备好并可以被应用程序使用。
7. 销毁阶段
当应用上下文关闭时,对于那些具有销毁方法的单例Bean:
如果实现了DisposableBean接口,destroy方法会被调用。
如果指定了destroy-method,则调用该方法。首先是beanFactory调用getBean方法.为什么不是创建Bean?spring框架将bean创建完成后,如果是单例bean,会放在Map集合里,如果后续需要这个bean,就直接从map集合中获取(一级缓存)。
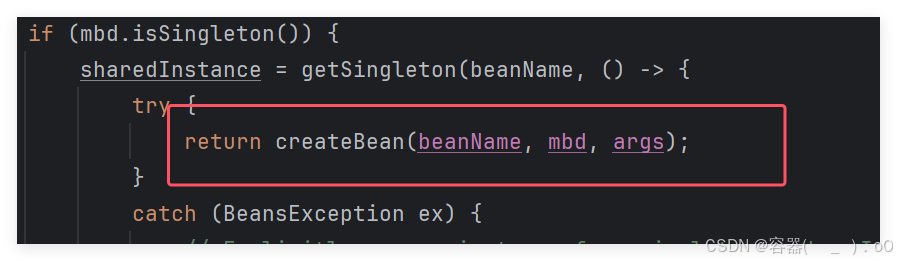
getBean调用AbstractBeanFactory类里的,之后调用doGetBean,
之后调用doGetBean方法里的getSingleton,这个方法里有双重检查锁的单例模式,确保获取的bean是单例bean,这个就是spring底层为了保证获取到的bean是单例bean。第一次获取不到,因为还没有进行bean对象的创建,不能从缓存中获取,在doGetBean里还有一个方法,createBean()
bean创建
进入到AbstractAutowireCapableBeanFactory里面的doCreateBean方法,那么这个方法是如何创建bean的,里面的createBeanInstance就是基于反射的机制创建Bean.


首先,这个方法获取字节码对象,后面调用instantiateBean(beanName, mbd);进行实例化。
这里面通过获取实例化策略器,通过这个策略器来进行对象的实例化,基于反射

bean对象创建完成后
现在回到spring-framework-5.1.x\spring-beans\src\main\java\org\springframework\beans\factory\support\AbstractAutowireCapableBeanFactory.java这个类的
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException
方法中,主要到
populateBean是对属性的赋值,initializeBean里的invokeAwareMethods说明要进行容器级别的注入。在bean的初始化环节,有容器注入,bean的后置处理器的前置处理方法,bean初始化方法的执行,bean初始化后后置处理器的后置处理方法。
总的来说,首先创建对象,之后属性的注入,最后是初始化。创建对象的话,如果是bean标签来管理bean这种简单对象的创建,是以反射的形式。属性的注入都是调用populateBean方法,容器注入,bean的前置处理,初始化和bean的后置处理都是属于初始化这个大的范畴,在initializeBean()内部


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









