






 本文详细介绍了Java中LinkedHashMap和TreeMap在Map体系中的位置、特点和底层原理,重点讲解了TreeMap的排序机制,包括自然排序和自定义Comparator,以及如何在实际场景中运用它们进行排序和统计操作。
本文详细介绍了Java中LinkedHashMap和TreeMap在Map体系中的位置、特点和底层原理,重点讲解了TreeMap的排序机制,包括自然排序和自定义Comparator,以及如何在实际场景中运用它们进行排序和统计操作。
LinkedHashMap:
在 Map体系中的位置:
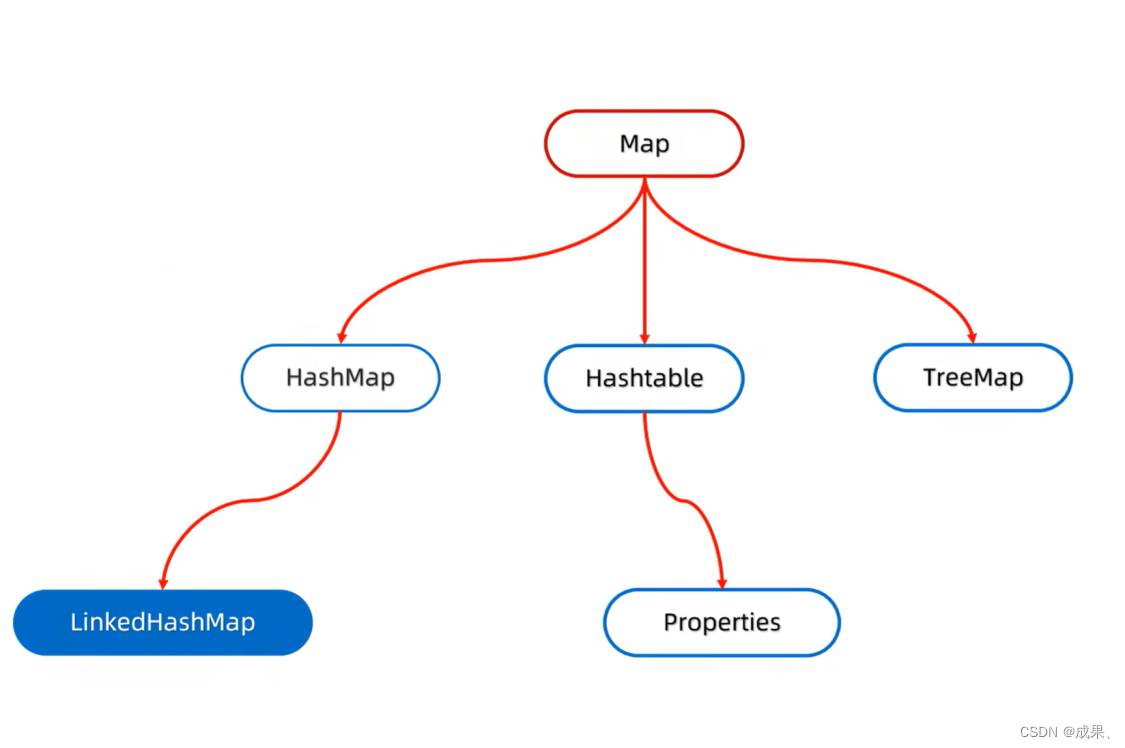
特点:
● 由键决定:有序、不重复、无索引。
这里的有序指的是保证存储和取出的元素顺序一致
原理:
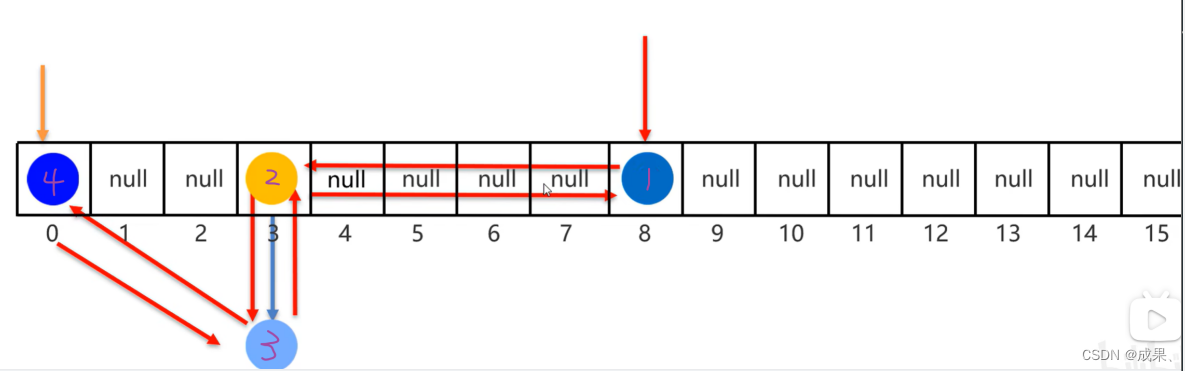
底层数据结构是依然哈希表,只是每个键值对元素又额外的多了一个双链表的机制记录存储的顺序,所以有序。如图:
TreeMap:
注意它和 HashCode 和 equals 无关
在 Map 体系中的位置: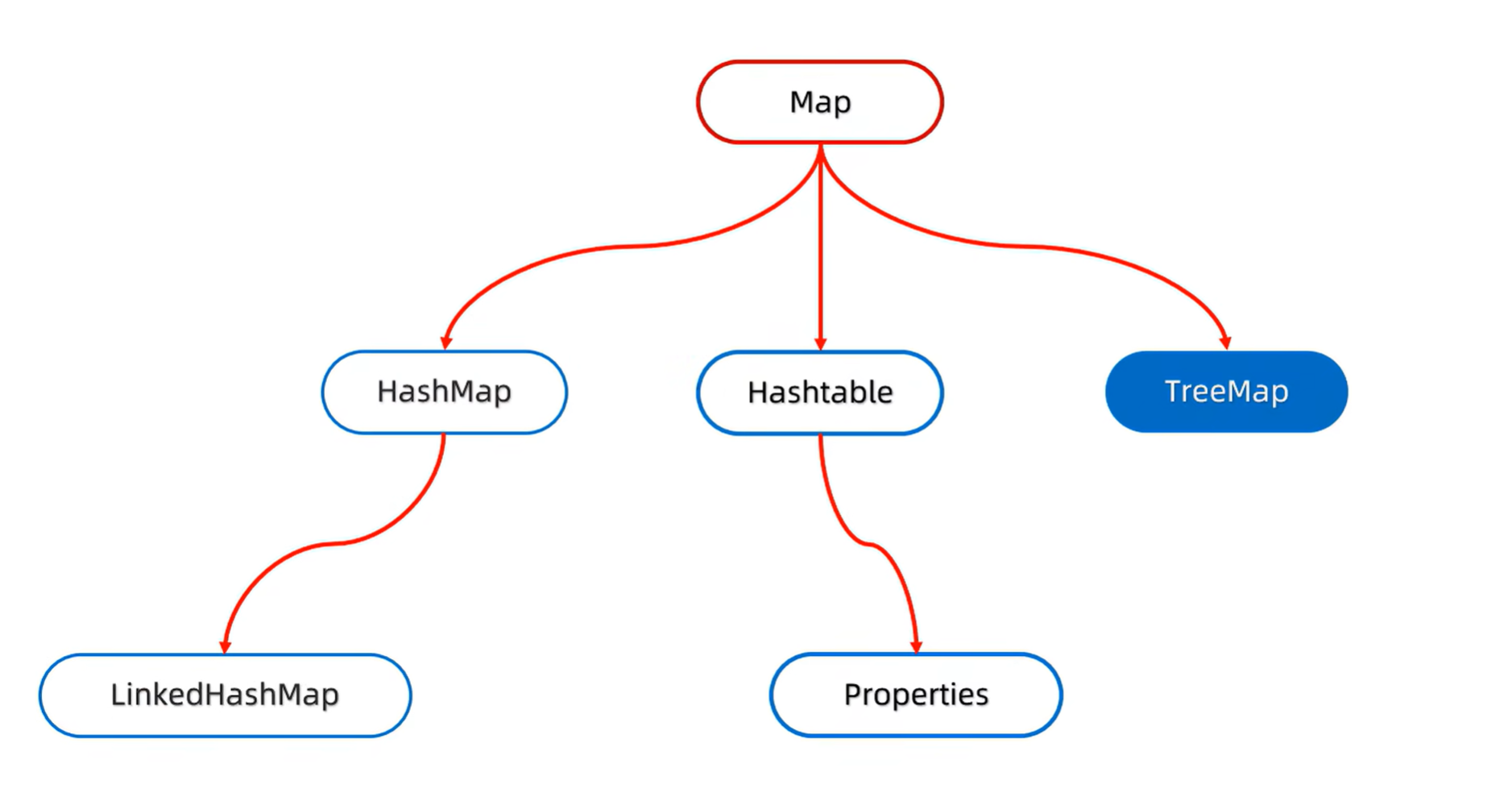
特点:
- 由键决定特性:**可排序 **、 不重复、无索引、
- 可排序:对键进行排序。
- 注意:默认按照键的从小到大进行排序,也可以自己规定键的排序规则
底层:
- TreeMap跟TreeSet底层原理一样,都是红黑树结构的。增删改查性能较好
两种排序规则:
自然排序:
- 实现Comparable接口(并在实现类中确定泛型类型),重写 CompareTo 方法指定比较规则。
比较器排序(自定义):
- 创建集合时传递Comparator比较器对象,指定比较规则。
排序练习 1:

1.升序
//创建TreeMap对象
TreeMap<Integer,String>tm1=new TreeMap<>();
//添加元素
tm1.put(2,"白菜");
tm1.put(3,"胡萝卜");
tm1.put(1,"菠菜");
//自然排序-升序
System.out.println(tm1);
//或用keySet、entrySet、Lambda表达式遍历也行
{1=菠菜, 2=白菜, 3=胡萝卜}
Integer 类已经实现了 Comparable 接口,并重写了 CompareTo 方法,直接打印即可
如图:

2.降序
//降序遍历
TreeMap<Integer,String>tm2=new TreeMap<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
//o1表示要添加的元素,o2表示红黑树中已存在的元素
return o2-o1;
}
});
tm2.put(2,"白菜");
tm2.put(3,"胡萝卜");
tm2.put(1,"菠菜");
System.out.println(tm2);
{3=胡萝卜, 2=白菜, 1=菠菜}
实现 Comparator 比较器
排序练习 2:

可用自然排序解决:
Student:手动实现 Comparable 接口,并重写 CompareTo 方法
public class Student implements Comparable<Student> {
private String name;
private int age;
// 构造+Set+Get+toString...
//this:要添加的对象
// o:红黑树中已存在的对象
// 返回值:
// 负数表示当前存的元素是小的
// 正数表示当前村的其实元素是大的
// 0表示当前元素已存在
@Override
public int compareTo(Student o) {
if (this.getAge()-o.getAge()!=0){
return this.getAge()-o.getAge();
}else {
//若年龄相同则调用默认的字母排序
return this.getName().compareTo(o.getName());
}
}
}
测试类:
//创建集合
TreeMap <Student,String>tm=new TreeMap<>();//构建具有非可比元素的分类集合
tm.put(new Student("zhangsan",23),"jiangxi");
tm.put(new Student("lisi",24),"shanghai");
tm.put(new Student("wangwu",23),"xingjiang");
tm.put(new Student("zhangsan",23),"zhejiang");//键相同,会覆盖原有键值对
System.out.println(tm);
{Student{name = wangwu, age = 23}=xingjiang, Student{name = zhangsan, age = 23}=zhejiang, Student{name = lisi, age = 24}=shanghai}
TreeMap 统计练习:统计个数:

看得出,按字母顺序排序。所以要求是:1.统计,2.排序
public class Test03统计 {
public static void main(String[] args) {
//统计字符出现次数
String str = "cccjjjgggbbb";
//定义Map集合,键是字符,值是出现次数
TreeMap<Character, Integer> tm = new TreeMap<>();
//先遍历字符串
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
if (tm.containsKey(c)) {
//表示c字符又出现了一次,拿出c字符出现的次数,+1,再放进去
Integer count = tm.get(c);
count++;
tm.put(c, count);
} else {
//表示c字符在集合中没有,放入c,1即可
tm.put(c, 1);
}
}
/*打印结果--因为Character已经实现了Comparable接口,
默认是字母顺序排序,直接打印即可*/
System.out.println(tm);
//修改展示样式:方式一
StringBuffer sb=new StringBuffer();
Set<Map.Entry<Character, Integer>> entries1 = tm.entrySet();
for (Map.Entry<Character, Integer> entry : entries1) {
sb.append(entry.getKey()).append("(").append(entry.getValue()).append(") ");
}
System.out.println(sb);
//方式二:
StringJoiner sj=new StringJoiner("","","");
Set<Map.Entry<Character, Integer>> entries2 = tm.entrySet();
for (Map.Entry<Character, Integer> entry : entries2) {
sj.add(entry.getKey()+"").add("(").add(entry.getValue()+"").add(") ");
}
System.out.println(sj);
}
}
控制台:
{b=3, c=3, g=3, j=3}
b(3) c(3) g(3) j(3)
b(3) c(3) g(3) j(3)
在以前统计题我们是定义一个变量来计数,但是弊端是:当要统计的东西较多,如上面这题,有好几个字母要分别统计,不可能每一个字母都定义一个变量来统计。
新的思想:利用map集合进行统计
- 如果题目中 只要求统计,默认使用Hash Map
- 如果题目中 要求 “统计+排序”,使用TreeMap
其中:
键:表示要统计的内容
值:表示次数


















 629
629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











