






算法描述:
-
算法的特性:有穷性,可行性,确定性,唯一性,输入,输出;
-
判断算法的优劣基本准则:正确,可读,健壮,高效;
-
算法效率:
- 时间复杂度--- 整体代码的执行频度是单行代码执行频度的和;只取整体执行频度的最高次幂
- 空间复杂度:空间复杂度主要用于描述某个算法对应的程序现想在计算机上执行,除了用来存储代码与输入数据的内存空间外,还需要的额外空间。
线性表--(一种数据结构):
- 描述: 线性表是 n 个数据元素的有限序列,其中 n 个数据是相同数据类型(常用于结构体)的;
- 使用案例 --图书信息管理系统;
顺序表
区分线性表与顺序表:
顺序表的描述:--(一种线性表的实现方式),其数据存取方式为随机存取;-通常使用数组为基础结构;
//顺序表结构定义:
#define MAXSIZE=100;
typedef int ElemType;//将int类型 重新命名为ElemType //便于统一修改类型;
typedef struct {
ElemType data[MAXSIZE];
int length;
}SeqList //使用结构体 定义了一种抽象数据(ADT) 顺序表
顺序表的 初始化:--(数组静态分配 -栈内存分配):
#define MAXSIZE=100
typedef int ElemType
typedef struct
{
ElemType data=[MAXSIZE];
int length;
}SeqList
//初始化顺序表的长度
void initList(SeqList *L)
{
L->length=0;
}
int main()
{
SeqList list;//创建一个顺序表
initList(&list//取地址);
return 0;
}顺序表的添加,遍历与删除 查找操作
int addElemt(SeqList *L, ElemType e) //返回值设置为int 0/1 代表真假值
{
if(L->length>MAXSIZE)
{
printf("顺序表已经满了");
return 0;
}
L->data[L->length]=e;
//把顺序表长度增加:
L->length++;
retrun 1;
}
//插入元素
int insertElem(SeqList *L,int pos,ElemType e)
{
for(int i= L->length-1;i>=pos-1;i--)
{
//一次覆盖-向后移
L->data[i+1]=L->data[i];
}
//放入数据;
L->data[pos-1]=e;
//增加长度
L->length++;
return 1;
}
//遍历
void listElem(SeqList * L)
{
for(int i=0;i<L->length;i++)
{
printf("%d",L->data[i]);
}
printf("\n");
}
//删除
int deleteElem(SeqList *L,int pos ,ElemType *e){
//仅传入删除位置,可以返回此位置对应的元素 --获取到被删除的元素;
*e =L-> data[pos-1];
//该删除末尾数据在内存仍然存在 --只是length-1 后不能再获取了
if(pos<L->length)
{ //注意i-1 的范围 pos-1 到 length -2 ;
//i的范围 pos 到 length-1
for(int i=pos;i<L->length;i++)
{
L->data[i-1]=L->data[i];
}
}
L->length--;
return 1;
}
//查找:
// 传入顺序表指针 被查找元素
int findElem(SeqList *L,ElemType e)
{
for(int i=0;i<L->length;i++)
{
if(L->data[i]==e)
{
return i+1;
}
}
return 0;
}
单向链表:
描述:链表的存取方式是顺序存取,存放空间随使用空间变化,空间动态可变;
单向链表的基本结构:
1. 头节点:headNode,指针域指向首节点,数据与一般赋值为0/null
2.首节点:数据域中存放首个可用数据
2.单个链表结点:单个链表节点包括数据域和指针域两部分;
3. 尾部节点:指针域指向NULL;
代码实现:
#include<stdio.h>
#include <stdlib.h>
typedef int ElemType;//将int类型 重新命名为ElemType //便于统一修改类型;
typedef struct node{
struct node *next;//在结构体中定义指
ElemType data;
}Node;//每个结构体代表一个结点 Node
//链表的初始化:
//1. 创建头节点;
//2. 让头结点中的结构体指针赋值为0;
//3. 该头结点对应data数据为0;
Node *initList()
{
//动态分配内存
Node* head=(Node*)malloc(sizeof(Node));
head->data = 0;//基本设置为0
head->next = NULL;
return head;
}
//链表中元素的插入--头插法
//1.将新建元素 指向头节点的后一元素
//2. 将头节点指向 新增元素
void insertHead(Node* l,ElemType e)
{
//首先先创建一个结点
Node* p = (Node*)malloc(sizeof(Node));
//放入元素
p->data = e;
p->next = l->next;
l->next = p;
}
//对链表的遍历:
void listNode(Node* l)
{
Node* p = l->next;
while (p != NULL)
{
printf("%d\n", p->data);
p = p->next;
}
printf("\n");
}
//获取尾部结点:
Node* getTail(Node* L)
{
//直接传址操作--为了不改变原链表指针的操作,应新创建指针
Node* p = L->next;
while (p->next != NULL)
{
p = p->next;
}
return p;
}
//尾插法:
//1. 先获取尾部结点的地址:
//2.参数: 传入尾部结点, 要插入的元素:
Node* insertTail(Node* tail, ElemType e)
{
//创建结点:
Node* p = (Node*)malloc(sizeof(Node));
p->data = e;
tail->next = p;
p->next = NULL;
return p;//返回新的尾部节点?
}
//在任意位置添加元素:
int insertNode(Node* L,int pos, ElemType e)
{
//遍历获得位置前一元素:
Node* p = L;
//需要记住 ---计数器从0 开始 ,小于 ,具体位置
int i = 0;
while (i < pos - 1)
{
p = p->next;
i++;
if (p == NULL)
{
return 0;
}
}
//创建新的结点:
Node* q = (Node*)malloc(sizeof(Node*));
q->data = e;
q->next = p->next;
p->next = q;
return 1;
}
// 删除结点操作:
//被删除元素的前一元素指向被删元素的后一元素:
ElemType deleteNode(Node* L, int pos)
{
Node* p=L;
int i = 0;
//获取前一元素
while (i < pos - 1)
{
p = p->next;
i++;
//删除位置没有元素
if (p->next == NULL)
{
return 0;
}
}
Node* q = p->next;
p->next = q->next;
//p->next = (p->next)->next; //语法正确
//p = q;//q 代表被删除元素结点
//释放 结点:
free(q); //
return 1;
}
//获取链表的长度
int getLength(Node* L)
{
Node* p = L;
int i = 0;
while(p->next!=NULL)
{
p = p->next;
i++;
}
return i;
}
//释放链表:
int freeList(Node* L) {
Node* p = L->next;//p代表第一个结点
//让q指向p的下下个结点
Node* q = p->next;
if (p ==NULL)
{
return 0;
}
//依次循环释放结点
while (p != NULL)
{
q = p->next;
free(p);
p = q;
}
//让头节点指向空: //否则头节点将指向位置(已被释放)
L->next = NULL;
}
双向链表:
描述:在单向链表的基础上添加了一个指针域,用于指向链表节点的前驱节点;
作用:通过新增指针域,对链表的操作会被简化---由于其特性,双向链表在某些场景下比单向链表和其他数据结构更有效,尤其是在需要频繁插入和删除操作时。
代码实现:
// 双向链表:
#include <stdio.h>
#include <stdlib.h>
// 定义数据类型:
typedef int ElemType;
// 定义节点类型:
typedef struct node
{
ElemType data;
// 设置前后结点指针:
struct node* next, * prev;
} Node;
// 头插法实现:
void insertHead(Node* head, ElemType val)
{
// 新建结点:
Node* p = (Node*)malloc(sizeof(Node));
p->data = val;
p->prev = head;
// 新建结点的后继结点设置为头节点的下一节点:
p->next = head->next;
//如果不是NULL将后一结点的前驱设置为新建节点(注意判断是否存在节点)
if (head->next != NULL)
{
head->next->prev = p;
}
head->next = p;
}
//遍历双向结点:
//对链表的遍历:
void listNode(Node* l)
{
Node* p = l->next;
while (p != NULL)
{
printf("%d\n", p->data);
p = p->next;
}
printf("\n");
}
//初始化双向链表:
Node* initList()
{
//动态分配内存
Node* head = (Node*)malloc(sizeof(Node));
head->data = 0;//通常设置为0
head->next = NULL;
head->prev = NULL;
return head;
}
//删除结点;
void delectNode(Node*head,int pos)
{
//首先找到被删除结点的前置结点(如果 被删结点为最后一个结点)
int i = 1;
Node* p = head;//一开始赋值统一为头节点
//找到前置结点
while (i < pos)
{
p = p->next;
i++;
//确保删除位置存在
if (p == NULL)
{
return 0;
}
}
Node* q = p->next;
Node* m = p->next->next;
//对前置节点操作
if (m == NULL)
{
p->next = NULL;
}
else {
p->next = m;
m->prev = p;
}
free(q);
}
单向循环链表:
描述:循环链表是另一种形式的链式存储结构,其特点是表中的最后一个节点的指针域指向头节点,整个链表形成一个环。
注意:
单向链表和循环链表的区别:判别当前指针p是否指向表尾节点的终止条件不同,单链表为p!=NULL或者p->next!=NULL, 而循环链表的判定条件是p!=L或者p->next!=L
链表习题练:
1.快慢指针:

1.创建快慢指针
2.快指针先走k步
3.快慢指针一起走,直到快指针走到NULL,慢指针此时为对应节点2. 题目:获取相同后缀中的是首元素: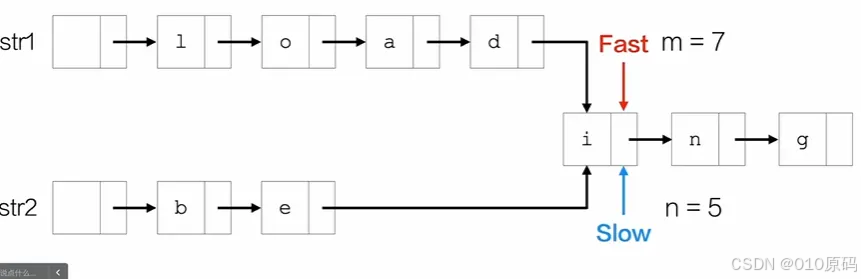
1. 创建快慢节点;
2. 获取两个链表的长度
3. 快指针先走两长度之差步,
4. 快慢指针同时走知道 两个指针指向数据相同时,该节点为相同后缀的首元素2. 拿空间换时间操作:

1. 创建一个长度为n的数组;
2. 将数组元素都赋值为0;
3. 遍历链表如果链表,如果链表数据值对应的数组元素的绝对值为0将其变为1,如果对应元素为1,将该节点进行删除;顺序表与链表的比较:
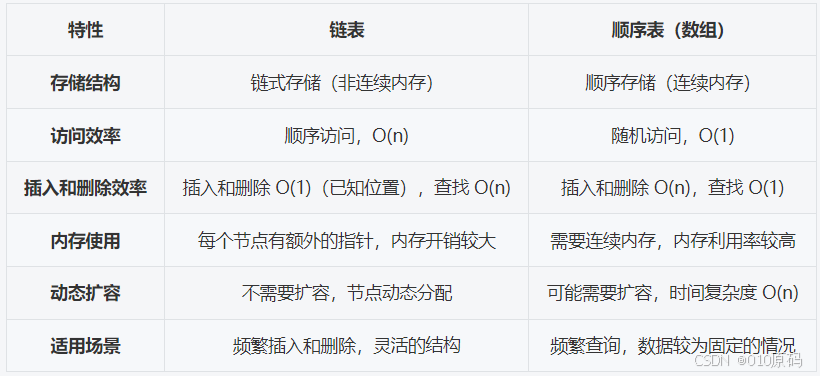
栈与队列:
栈(Stack):
特点:
仅在表尾(限制删除插入操作仅能在一个位置进行的表)进行删除插入操作; 元素先进后出,后进先出;
描述:
对于线性表,表尾端为栈顶,表头端为栈底,不含元素的表为空栈
栈和队列的设计目标是高效的按特定顺序处理数据,遍历并不是它们的主要功能。
元素的添加删除;
- pop(删除):出栈;
- push(添加):入栈;
代码实现:
顺序表存储(静态内存分配)
typedef int ElemType;
//栈的顺序存储
typedef struct {
ElemType data[100];
int top;//顺序存储中top代表数组下标 //栈中代表栈顶指针
}Stack;
//初始化栈结构:
void initStack(Stack* s)
{
s->top = -1;
return ;
}
//判断是否为空:
void isEmpty(Stack* s)
{
if (s->top == -1)
{
printf("此栈为空\n");
}
else
{
printf("此栈不为空\n");
}
}
//进行压栈操作:
int Push(Stack* s, ElemType e)
{
//先判断栈是否满了:
if (s->top >= 99)
{
printf("栈已经满了\n");
return 0;
}
s->top++;
s->data[s->top] = e;
return 1;
}
//进行出栈操作:
int Pop(Stack* s, ElemType* e)
{
if (s->top == -1)
{
printf("此栈为空\n");
return 0;
}
else
{
*e = s->data[s->top];
s->top--;
return 1;
}
}顺序表存储 动态内存分配:(动态开辟空间--指针调用数组)
typedef int ElemType;
//栈的顺序存储
typedef struct {
ElemType *data;//用于指向堆内存中开辟的数组空间
int top;//顺序存储中top代表数组下标 //栈中代表栈顶指针
}Stack;
//初始化栈:
Stack* initStack(){
Stack *s=(Stack*)malloc(sizeof(Stack));
s->data=(ElemType*)malloc(sizeof(ElemType)*100);
s->top=-1;
return s;
}
int main()
{
Stack* s=initStack();
//之后对栈操作 --传地址;--s报错地址
//其余操作与静态分配相同
}栈的链式存储结构:
需要注意的点:(栈顶与栈底自定义)
1. 头节点的下一节点--首节点--代表栈顶--添加元素--链表的头插法:
2.栈的长度没有局限
3.判断栈为空 L->next=NULL
typedef int ElemType;
//栈的链式存储:
typedef struct stack
{
ElemType data;
struct stack * next;
}Stack
//初始化栈--(初始化一个链表-创建头节点):
Stack* initStack()
{
Stack *s=(Stack*)malloc(sizeof(Stack));
s->data=0;
s->next=NULL;
return s;
}
//压栈操作--链表的头插法:
void Push(Stack* s,ElemType e)
{
Stack*p =s;//p--随函数自动销毁?可以不使用
//创建新的结点:
Stack *a=(Stack*)malloc(sizeof(Stack)); //何时
a->next=p->next;
p->next=a;
p->data=e;
return ;
}
//判断是否为空:
int isEmpty(Stack * s)
{
if(s->next==NULL)
{
printf("栈为空");
return 0;
}
else return 1;
}
//出栈操作
void Pop(Stack* s,ElemType *e)
{
//首先判断是否为空
if(!isEmpty(s))
{
return 0;
}
else
{
*e=s->next->data;
s->next=s->next->next;//
//正确:
Stack *p =s->next;
s->next=p->next;
free(p);
return 1;
}
}队列:
特点:
先进先出的线性表,只允许在一端进行删除,在另一端进行添加元素;
结构 描述:
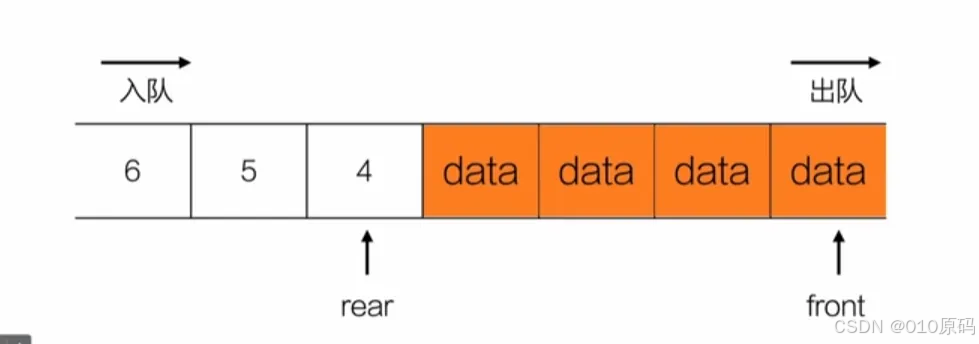
队列的顺序存储结构:(静态内存分配):
typedef int ElemType;
typedef struct queue
ElemType data[100];
int front;
int rear;
}Queue;
//初始化队列:
int initQueue(Queue* q){
//自定义为 0或 -1
q—>front=0;
q->queue=0;
return 1;
}
//入队操作:
int equequ(Queue* q,ElemType e)
{
//判断是否队列伪满 并将队列重新分配
if(q->rear>=100)
{
if(!queueFull(q))
{
return 0;
}
}
q—>data[q->rear]=e;
q->rear+=1;
return 1;
}
//判断队列是否为真满:
int queueFull(Queue *q)
{
if(q->front==0)
{
printf("该队列真的满了");
return 0;
}
//设置step
int step =Q->front;//->i-step为对应填入的索引
//注意注意 可以相等
for(int i=q->front;i<=q->rear;i++)
{
q->data[i-step]=q->data[i] ;
//i用于取出每个元素
}
q->front=0;
q->rear=q->rear-step;
return 1;
}
//出队操作:
int oqueue(Queue* q,ElemType* e)
{
//判断队列是否为空:
if(q->front==q->rear)
{
printf("队列已满");
return 0;
}
q->front--;
return 1;
}循环对列:
描述 :
为了解决元素入队时,发生“假溢出”的现象,将队列设置为环状队列;
特点:
- 在 顺序结构的循环队列中 会留下一个位置给尾指针/队尾指针,数组不会装满;
- 队列满了与空时的判断:
队满:(Q->rear+1)%MAXSIZE == Q->front
队空:Q->rear=Q->front;
- 队头(front)索引的 增加
q->front=(q->front+1)%MAXSIZE
- 对尾(rear)索引的赋值
q->rear=(q->rear+1)%MAXSIZE;
实现:
- 队列的初始化相同:
rear 和 front 初始化为 0 - 队列的入队操作:
//队列满了的判断条件:
int equeue(Queue * q,ElemType e)
{
if((Q->rear+1)%MAXSIZE == Q->front)
{
printf("满了")
}
//元素入队:
q—>data[q->rear]=e;
q->rear=(q->rear+1)%MAXSIZE;
return 1;
}出队操作:
int oqueue(Queue *q,ElemType *e)
{
//判断是否为空
if(q->rear=q->front)
{
prntf("空的\n");
return 0;
}
*e=q->data[q->front];
q->front=(q->front+1)%MAXSIZE
//(两个下标前进的条件相同)
return 1;
}想象结构:
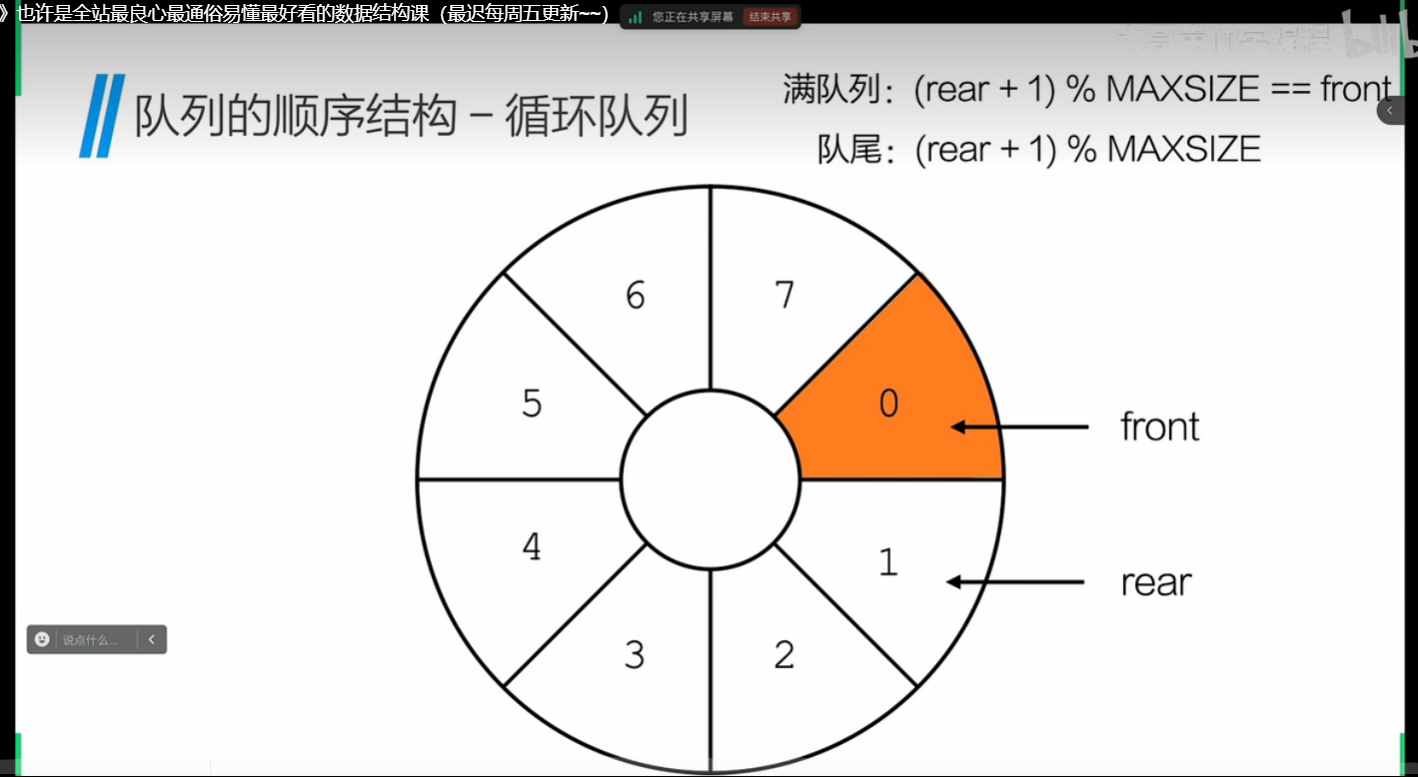
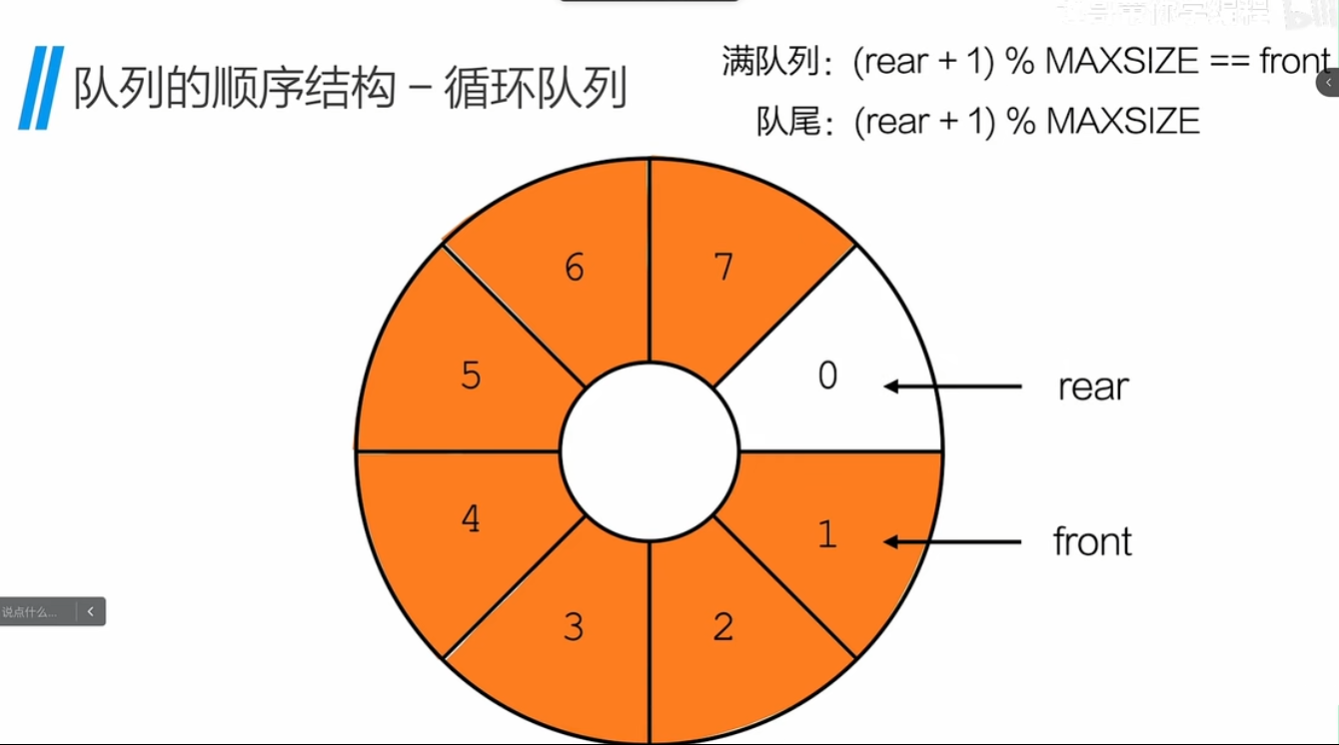
例题:
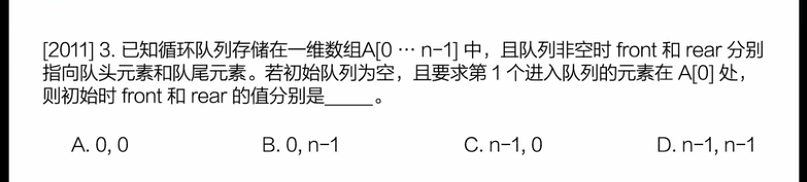
此案例中 front=0 rear 为 n-1 结合上图看就是 7/(8-1) 的位置,
进行入队操作时,不能先进行判满操作,先进行 rear+1 操作 ,任然会发生数组一个空位置的情况
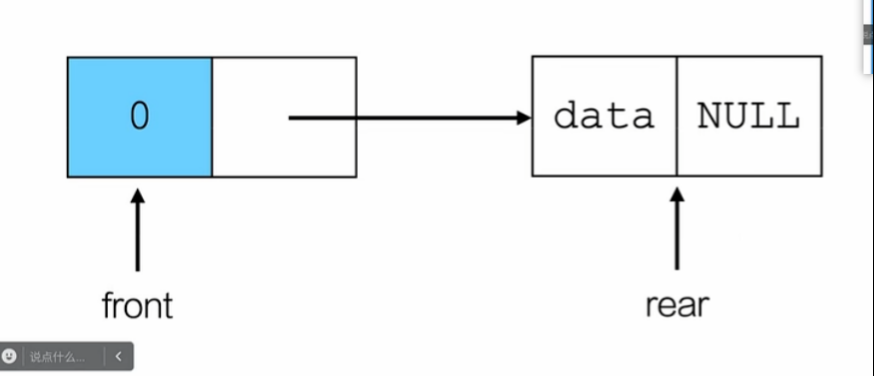
队列的链式结构:
将头结点的下一结点作为队头;
将尾结点作为队尾 ;
入队则使用尾插法;
typedef struct Node
{
ElemType data;
struct Node* next;
}QueueNode
//新增类型//头尾指针:
typedef struct
{
QueueNode * front;
QueueNode * rear;
}Queue
Queue* initQueue()
{
//创建首尾指针
Queue *q =(Queue*) malloc(sizeof(Queue));
//创建头节点
QueueNode * node=(QueueNode*)malloc(sizeof(QueueNode));
q->front=node
q->rear= node
return q //返回首尾指针
}
void eQueue(Queue* q,ElemType e)
{
//创建新的结点:
QueueNode * p=(QueueNode*)malloc(sizeof(QueueNode));
p->data=e;
p->next=NULL;
//尾指针先链接后移动
q->rear->next=p;
q->rear=p;
}int dqueue(Queue * q,ElemType *e)
{
// 获取被出队结点
QueueNode *node =q->front ->next;
*e=node->data;
//断开操作
q->front->next=node->next;
//如果此时是最后一个结点
if(q->rear==node)
{
q->rear=q->front;
}
//释放创建的node结点;
free(node);
return 1;
}双端队列:(概念多)
描述: 两端都能出 ,两端都能进的队列

解题方法: 假设一端为出队端,画图尝试;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









