







SQLAlchemy中Query对象的使用
- 前言
- 一、表结构的声明和数据的插入
- 二、使用
- 1.过滤,分组,排序的使用
- 1.1过滤(filter)使用
- 1.2分组(group_by)的使用
- 1.3排序(order_by)的使用
- 2.去重,合并的使用
- 2.1去重(distinct)
- 2.2合并
- 3.连接
- 4.切片,分页。
- 5.快捷方式
- 总结
- 补充
- 子查询
- 传统方式
- 子查询
前言
Query 对象是 SQLAlchemy ORM 的核心部分,它用于构建和执行对数据库的查询。
配置的解读见
一、表结构的声明和数据的插入
from sqlalchemy import create_engine, String
from sqlalchemy.orm import sessionmaker, declarative_base, Mapped, mapped_column
HOST = "127.0.0.1"
PORT = "3306"
DATABASENAME = "test_db"
USE = "root"
PWD = "123456"
DB_CLASS = "mysql"
DRIVER = "pymysql"
DB_URL = f"{DB_CLASS}+{DRIVER}://{USE}:{PWD}@{HOST}:{PORT}/{DATABASENAME}"
engine = create_engine(DB_URL)
Base = declarative_base()
Session = sessionmaker(bind=engine)
class QueryTable(Base):
__tablename__ = 'q_table'
id: Mapped[int] = mapped_column(primary_key=True, autoincrement=True)
content: Mapped[str] = mapped_column(String(64))
name: Mapped[str] = mapped_column(String(64))
age: Mapped[int] = mapped_column()
def __repr__(self):
#定义个__repr__方法,方便打印对象信息
return f"<QueryTable(id={self.id}, content='{self.content}', name='{self.name}', age={self.age})>"
def create_data():
Base.metadata.create_all(engine)
with Session.begin() as session:
session.add_all([
QueryTable(content='hello', name='zhangsan', age=18),
QueryTable(content='world', name='lisi', age=20),
QueryTable(content='python', name='wangwu', age=22),
QueryTable(content='flask', name='zhaoliu', age=24),
QueryTable(content='sqlalchemy', name='zhaoqi', age=26),
QueryTable(content='mysql', name='zhaohui', age=28),
QueryTable(content='sqlite', name='zhaojie', age=30),
QueryTable(content='postgresql', name='zhaochen', age=32),
QueryTable(content='redis', name='zhaozhong', age=34),
QueryTable(content='mongodb', name='zhaozheng', age=36),
QueryTable(content='celery', name='zhaoyuan', age=38),
QueryTable(content='tornado', name='zhaojun', age=40),
QueryTable(content='aiohttp', name='zhaohuan', age=42),
QueryTable(content='scrapy', name='zhaozhu', age=44),
QueryTable(content='django', name='zhaozhao', age=46),
QueryTable(content='flask', name='zhaozhan', age=48),
QueryTable(content='fastapi', name='zhaozhong', age=50),
QueryTable(content='vue.js', name='zhaozhao', age=52),
QueryTable(content='react.js', name='zhaozhu', age=54),
QueryTable(content='angular.js', name='zhaozhao', age=56),
QueryTable(content='jquery', name='zhaozhu', age=58),
QueryTable(content='express.js', name='zhaozhao', age=60),
QueryTable(content='vue.js', name='zhaozhu', age=62),
QueryTable(content='react.js', name='zhaozhao', age=64),
QueryTable(content='angular.js', name='zhaozhu', age=66),
QueryTable(content='jquery', name='zhaozhao', age=68),
QueryTable(content='express.js', name='zhaozhu', age=70),
QueryTable(content='vue.js', name='zhaozhao', age=72),
QueryTable(content='react.js', name='zhaozhu', age=74),
QueryTable(content='angular.js', name='zhaozhao', age=76),
])
create_data()
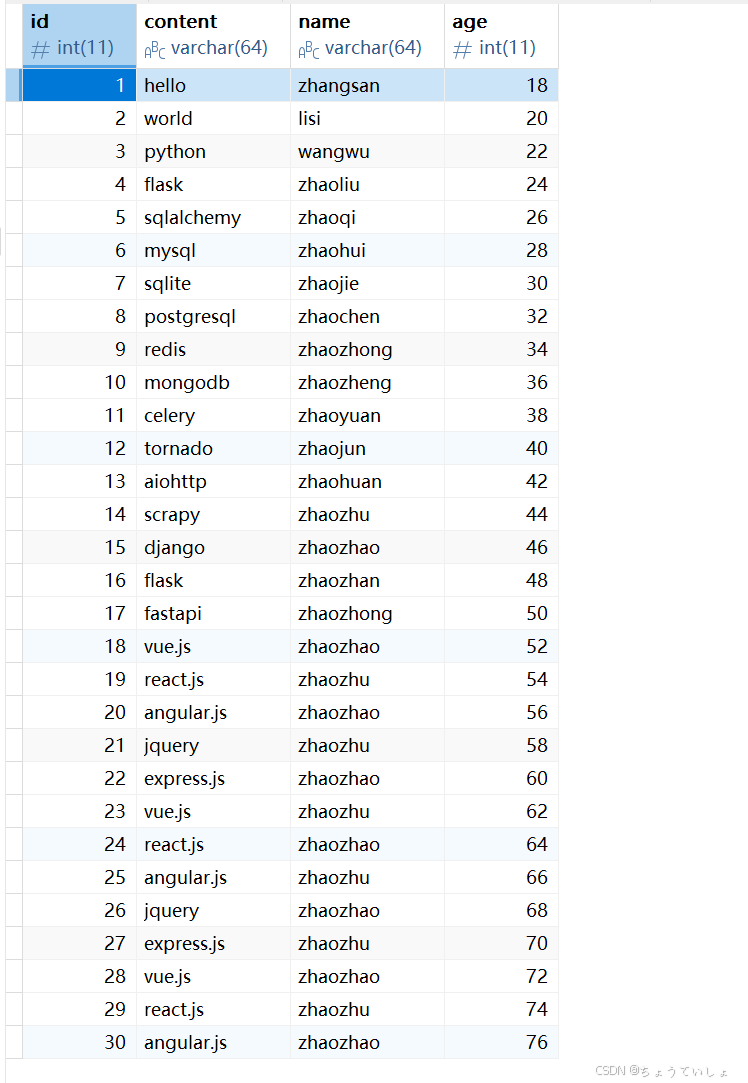
运行create_data函数生成表和数据。结果如下
二、使用
1.过滤,分组,排序的使用
1.1过滤(filter)使用
这里直接上代码了,也不演示结果,因为Sqlalchemy基本使用已经演示过了。
with Session() as session:
sql = session.query(QueryTable).filter(QueryTable.id == 1)
# Query对象中还有where和filter_by方法,但其实都是用的filter方法,所以就用filter方法就ok
result = sql.all()
print(sql)
print(result)
1.2分组(group_by)的使用
from sqlalchemy import func
#func里面有一些聚合函数如,sum, avg, max, min, count等。
with Session() as session:
sql = session.query(QueryTable.name, func.avg(QueryTable.age)).group_by(
QueryTable.name
) #group_by中可以传入多个列
"""
sql = (
session.query(QueryTable.name, func.avg(QueryTable.age))
.group_by(QueryTable.name)
.having(func.avg(QueryTable.age) > 20)
)
也是可以跟上having子句进一步过滤。
"""
result = sql.limit(2).all()#数据有点多,就拿2条看一下ok。
print(sql)
print(result)
#注意在session.query()中不能出现既没有在聚合函数中又没有在group_by中列。
# session.query(QueryTable.name, QueryTable.age).group_by(QueryTable.name)
#这是不合法的sql语句
另外在query()中传入的参数决定你返回的对象,比如query(QueryTable)则返回的是QueryTable实例,如果像上面的例子一样传入的是一个属性的话,返回的是是Row实例,你可以理解为一个元组。
运行结果如下

1.3排序(order_by)的使用
with Session() as session:
sql = session.query(QueryTable).order_by(QueryTable.age.desc())
#升序是asc(默认)
result = sql.limit(5).all()
print(sql)
print(result)
运行结果如下

2.去重,合并的使用
2.1去重(distinct)
from sqlalchemy import distinct
#distinct映射到数据库中是标准的distinct语法
#这里使用distinct函数因为query对象里面自带的distinct支持on distinct语法
#而mysql中没有,所以会有警告,不过也是能用的,不推荐
with Session() as session:
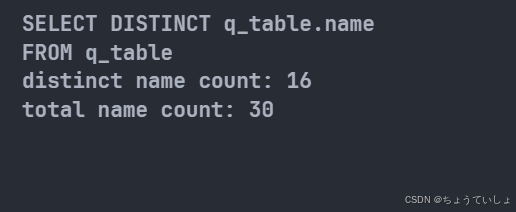
sql = session.query(distinct(QueryTable.name))
s = session.query(QueryTable.name).count()
result = sql.count()
#使用count统计查询到的数据数量方便观察。
print(sql)
print(f"distinct name count: {result}")
print(f"total name count: {s}")
运行结果如下
2.2合并
union关键字会合并并去重。
with Session() as session:
sql1 = session.query(QueryTable).filter(QueryTable.age > 72)
sql2 = session.query(QueryTable).filter(QueryTable.name == 'zhaozhu')
sql3 = sql1.union(sql2)
result = sql3.all()
print(sql3)
print(result)
""""
这里的union返回的是一个新的Qurey对象,
所以是可以链式调用的。
如果给union中传入了多个Query对象那么返回的查询是平级的
如
sql1 = session.query(QueryTable).filter(QueryTable.age > 72)
sql2 = session.query(QueryTable).filter(QueryTable.name == 'zhaozhu')
sql3 = session.query(QueryTable).filter(QueryTable.age < 24)
sql4 = sql3.union(sql2, sql1)
它返回的结果是类似
SELECT * FROM (
SELECT * FROM q_table WHERE age < 24
UNION
SELECT * FROM q_table WHERE name = 'zhaozhu'
UNION
SELECT * FROM q_table WHERE age > 72
);(当然这玩意儿肯定不能运行的,要把*替换成具体列才可以)
链式调用是嵌套的结构,因为每次union是生成的一个新的Query对象实例。
"""
运行结果如下

上面的图片不直观,看下面这张我自己写的sql语句。
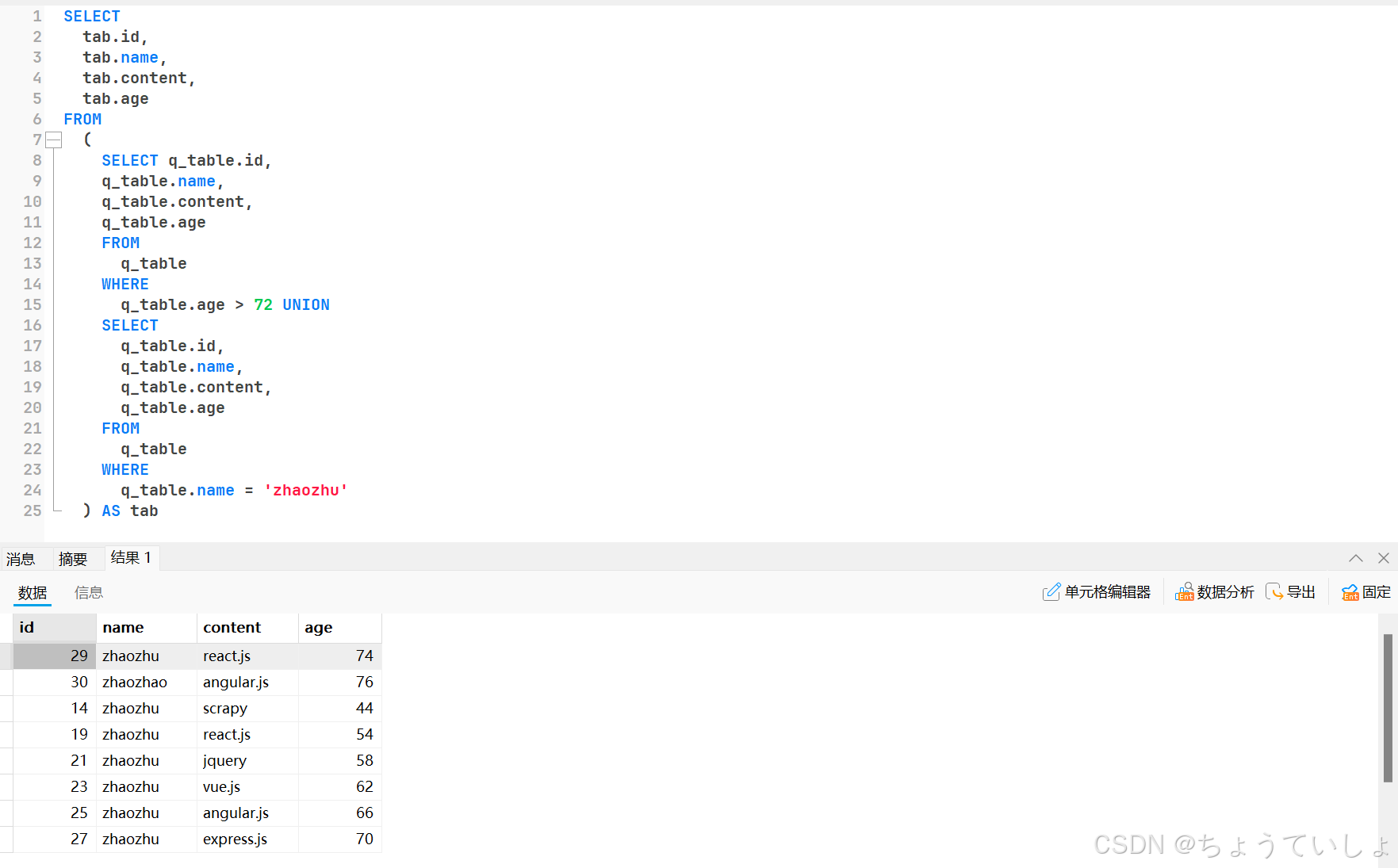
3.连接
首先创建一个辅助表
from sqlalchemy import ForeignKey#这里引入外键为了演示一个特性
class Test(Base):
__tablename__ = "test"
id: Mapped[int] = mapped_column(primary_key=True, autoincrement=True)
qid: Mapped[int] = mapped_column(ForeignKey(QueryTable.id))#定义外键
name: Mapped[str] = mapped_column(String(64), nullable=False)
def testData():
Base.metadata.create_all(engine)
with Session.begin() as session:
session.add_all(
[
Test(qid=1, name="test1"),
Test(qid=2, name="test2"),
Test(qid=1, name="test3"),
]
)
testData()#运行testData函数以生成辅助表test和数据
下面是演示和说明
Query对象的join默认是内连接。
1.直接连接
with Session() as session:
sql = session.query(QueryTable).join(Test)
#直接和Test表join不给任何条件,默认会自动找关联关系也就是 QueryTable.id == Test.oid
print(sql)
运行结果如下

可以看到生成的sql语句的条件就是外键关联的条件,并且是内连接。
2.给连接的条件
with Session() as session:
sql = session.query(QueryTable).join(Test, QueryTable.id == Test.id)#附加连接条件
print(sql)
运行结果如下

3.外连接
with Session() as session:
sql = session.query(QueryTable).outerjoin(Test)
#使用outerjoin外连接,同样的不给条件就会自己找外键的连接关系
print(sql)
运行结果如下

补充一下
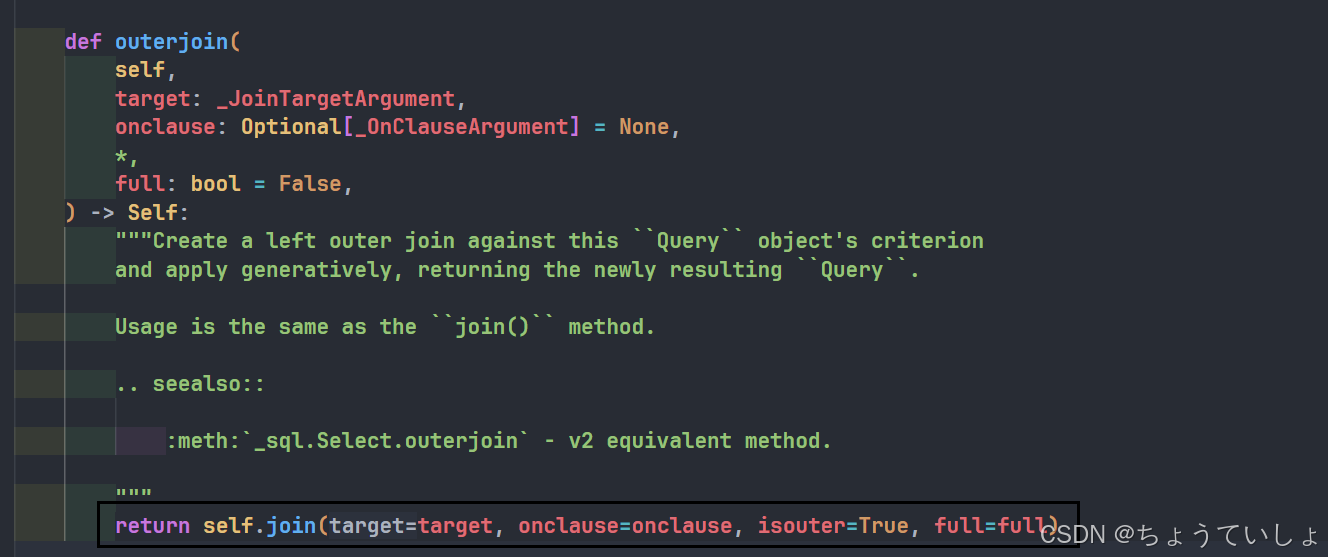
通过查看outerjoin可以发现实际上调用的是join方法
通过isouter=True实现外连接。
而full则控制是否全外连接。
onclause是可选的条件(就是我们传入的条件,不传就是None)
4.切片,分页。
1.切片
with Session() as session:
sql = session.query(QueryTable).slice(1, 3)#左闭右开
# 上面的意思是在session中查询QueryTable表,并返回索引1到索引2记录
print(sql)
print(sql.all())
运行结果如下

2.分页
这里的操作和sql语句里差不多。
示例如下
with Session() as session:
sql = session.query(QueryTable).limit(2).offset(1)
#这样的结果其实和上面的切片是一样的
#上面的切片也不过是把传入的参数转化为limit和offset
print(sql)
print(sql.all())
运行结果如下

5.快捷方式
对于删除和更新可以直接通过返回的对象实例操作也可以直接操作。
示例如下
1.更新
with Session() as session:
session.query(QueryTable).filter(QueryTable.id == 1).update({QueryTable.age: QueryTable.age + 100})
#也可以使用session.query(QueryTable).filter(QueryTable.id == 1).update({'age': QueryTable.age + 100})
#通过传入的字典就可以更新指定的字段
session.commit()
data = session.query(QueryTable).filter(QueryTable.id == 1).first()
print(data)
运行结果如下

2.删除
删除和更新差不多
with Session() as session:
session.query(QueryTable).filter(QueryTable.id == 5).delete()
session.commit()
data = session.query(QueryTable).filter(QueryTable.id == 5).first()
print(data)
运行结果如下

其实不commit也会是这样的结果这是因为synchronize_session参数默认就是’auto’该选项会遍历当前会话中的对象,检查它们是否符合更新条件,并更新那些对象的属性。但是数据库是没有更新的,如果需要更新还是要commit一下
总结
以上就是Query的一些操作,欢迎评论区讨论,感谢!!!。
补充
子查询
假设你有这样一个需求,你要查询q_table中与id=1的数据,年龄相同的用户。
传统方式
with Session() as session:
data = session.query(QueryTable).filter(QueryTable.id == 1).first()
age = data.age
sql = session.query(QueryTable).filter(QueryTable.age == age)
print(sql)
print(sql.all())
运行结果如下

这里我们先查到了id=1里面的对象实例,所以我们可以拿里面的age当条件。但这是建立在先在数据库查询一次的基础之上的。所以说有2次查询。但是我们有更优雅的方式。
子查询
with Session() as session:
subquery = session.query(QueryTable).filter(QueryTable.id == 1).subquery()
sql = session.query(QueryTable).filter(QueryTable.age == subquery.c.age)
print(sql)
print(sql.all())
运行结果如下

可以看到这是输出的sql有2张表,其中一张表就是subquery生成的,这个查询只向数据库提交了一次。
因此更加高效。如果有类似的业务场景推荐大家使用。


















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











