






 本文讲解了MySQL分组查询的基本语法,特点,以及如何在实际项目中运用,涉及多个案例分析。
本文讲解了MySQL分组查询的基本语法,特点,以及如何在实际项目中运用,涉及多个案例分析。
1.数据库来源:Mysql 基础教程
2.数据库说明:
本文使用的数据库名称为 myemployees,其中有 8 张表,分别为 customers 表,departments 表,employees 表,job_grades 表,jobs 表,locations 表,orders 表,salespeople 表。
一、分组查询基本语法
select 分组函数,查询列表(出现在 group by 的后面)
from 表
where 筛选条件
group by 分组的字段
having 筛选条件2(一般为分组函数,如 min,max,sum,avg等)
order by 排序的字段
二、分组查询特点
1、 和分组函数一同查询的字段必须是 group by 后出现的字段,因为 select 的执行顺序在 group by 之后,select 只可选取 group by 聚合过后的字段和计算的字段(select 后的字段范围小于等于 group by 后的字段范围)
2、 筛选分为两类:分组前筛选和分组后筛选
| 针对的表 | 位置 | 连接的关键字 | |
|---|---|---|---|
| 分组前筛选 | 原始表 | group by 前 | where |
| 分组后筛选 | group by 后的结果集 | group by 后 | having |
having 相当于 Excel 中数据透视表的筛选器
3、 分组可以按单个字段也可以按多个字段,同时可以搭配排序查询使用
4、注意关键词 “每个/每组”,遇到类似表述就要使用分组查询
三、分组查询相关案例(仅展示有限部分)
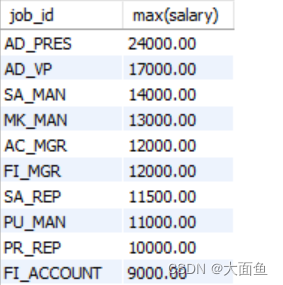
案例一:查询每个工种的最高工资,并按最高工资降序排列
select job_id, max(salary)
from employees
group by job_id
order by max(salary) desc
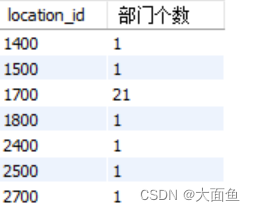
案例二:查询每个位置上的部门个数
select location_id, count(*) 部门个数
from departments
group by location_id
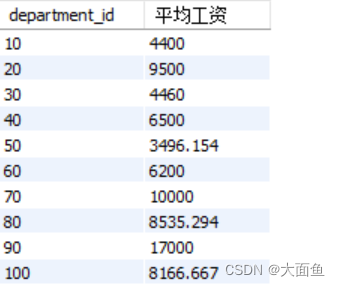
案例三:查询邮箱中包含a字符且部门id不为空值的,每个部门的平均工资
select department_id, round(avg(salary),3) 平均工资
from employees
where email like '%a%' and department_id is not null
group by department_id
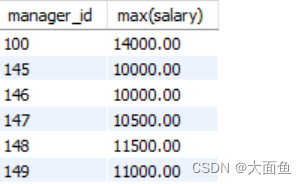
案例四:查询每个领导手下,有奖金的员工的最高工资
select manager_id, max(salary)
from employees
where commission_pct is not null
group by manager_id
案例五:查询哪个部门的员工个数 > 1
select department_id, count(*)
from employees
group by department_id
having count(*) > 1
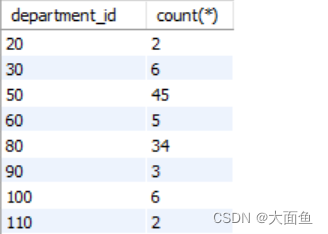
案例六:查询每个工种有奖金的员工的最高工资>10000的工种编号和最高工资
select job_id, max(salary)
from employees
where commission_pct is not null
group by job_id
having max(salary) > 10000
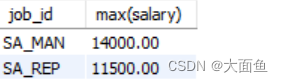
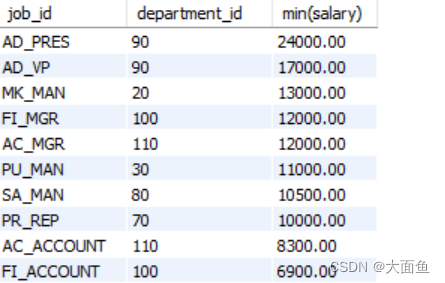
案例七:查询最低工资 > 5000 的每个工种与每个非空部门,并按最低工资降序
select job_id, department_id, min(salary)
from employees
where department_id is not null
group by job_id, department_id
having min(salary) > 5000
order by min(salary) desc

















 1815
1815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









