







目录
一、回归分析是什么?

(1)相关性:与因果性不同。例如,天气热的时候,空调费用花费多;夏天时候,雪糕销售量也多,按道理,若计算两者,能有“雪糕卖的越多,空调费用越高”,显然这是不合理的。绝大部分时候,我们是不能直接分析严格的因果关系,只能去通过回归分析来研究相关性。
(2)Y:因变量(被解释变量),在研究时候,是核心的研究变量。对应着五种的回归分析,有五种变量类型:
(a)连续性数值变量:例如GDP增长率
(b)0-1型变量:例如某公司研究借款人是否按时还款,Y=0为不还款,Y=1是还款
(c)定序变量:例如设计问卷来询问消费者的满意程度,1为非常满意,2为满意,3为一般,4为有点不满意,5为非常不满意
(d)计数变量:例如管理学历RFM模型,F代表一定时间内客户到访次数,易知改次数是非负整数
(e)生存变量:研究产品寿命、企业寿命甚至于人的寿命。比如,现在我们要观测运动对于人寿命的影响,老王现年65岁,平常基本无运动习惯,但研究时又不可能一直等到他趋势再研究该样本。所以,直接将数据记录为60+,这中数据是截断的。
(3)X:自变量(解释变量)
【分类】

二、回归分析究竟要去解决什么呢?
1、哪些X是和Y真正相关的,那些不是。也就是选择出真正重要的变量。
2、所有这些有用的X变量和Y的相关性是正的呢还是负的呢?
3、在确定了重要的X变量的前提下,还要赋予不同的X不同的权重(即不同的回归系数),分析不同变量之间的相对重要性。
三、数据
【数据分类】
1、横截面数据:在同一个时间节点获得的数据
例如:全国各个省份2018年降水总量
2、时间序列数据
例如:中国历年GDP数据;某地每个小时的温度湿度数据
3、面板数据:综合横截面数据和时间序列数据
例如:2008年到2018年,我国各个省份的GDP数据
【不同数据处理方法】

【数据获取】各类网站数据,python爬虫(留个坑......)
(补本书:《中级计量经济学》)
四、线性回归


在使用特定模型之前,需要先对数据进行预处理。
【回归系数的解释】


如何去衡量内生性:计算扰动项和自变量x的相关系数;
【蒙特卡洛方法】(模拟)
那如果变量很多呢?


什么时候取对数处理?
一般而言,涉及到某些特定的变量时候(由经验可得):

具体例子:


多分类的虚拟变量:一般而言引入分类数减1个虚拟变量,以免造成多重共线性*,省略的变量作为对照组进行数据分析。
含有交互项的自变量?
五、案例
1、分析定量变量:
stata 命令:regress y x1 x2 ... xk (或者用reg缩写)
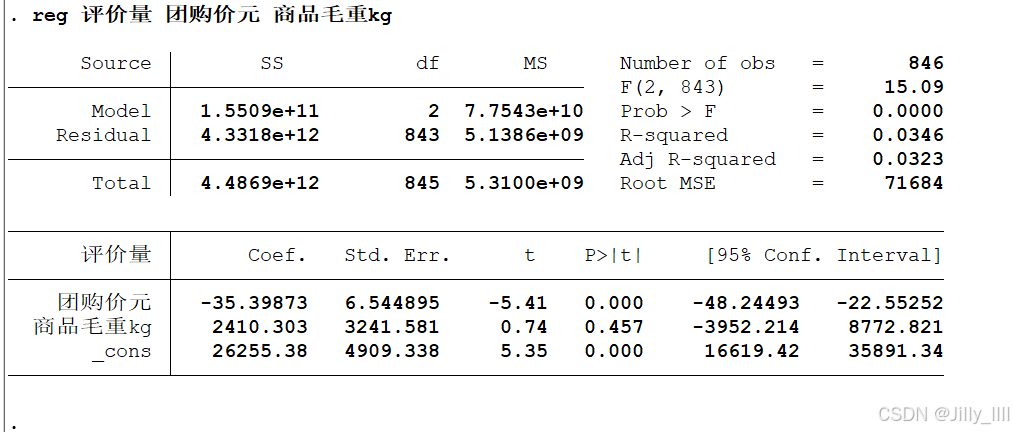
上面的图为方差分析图,数据含义:
SS一列分别代表:SSR, SSE, SST
df 一列代表自由度,model 的 df 值即为自变量个数 ,total的 df 值是n-k-1(n为样本数)
下面的图:
第一列Coef为估计出来的对应变量的系数,即前文的β1、β2,cons为β0
第二列std.err为对应的误差
第三列 t检验值: t=coef/std.err
第四列P值,用来分析此变量是否显著异于零(大于0.05),依此决定要不要考虑该变量。
第五第六为区间估计值
2、定性变量:
引入虚拟变量,stata 命令:“regress y x1 x2 ... xk, gen(A)”

















 7337
7337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









