






目录
一则短视频平台拥有大量的视频,图片,这些视频文件图片文件该如何存储才能满足互联网上海量用户的浏览呢?本章的详细内容分布式文件系统就是解决海量用户查阅海量文件的方案。
百度百科解释分布式文件系统的定义为:

简单理解就是:一个计算机没有办法去存储海量的文件,就可以通过网络通信将若干计算机组织起来共同去存储海量的文件,也能够接收海量用户发来的请求
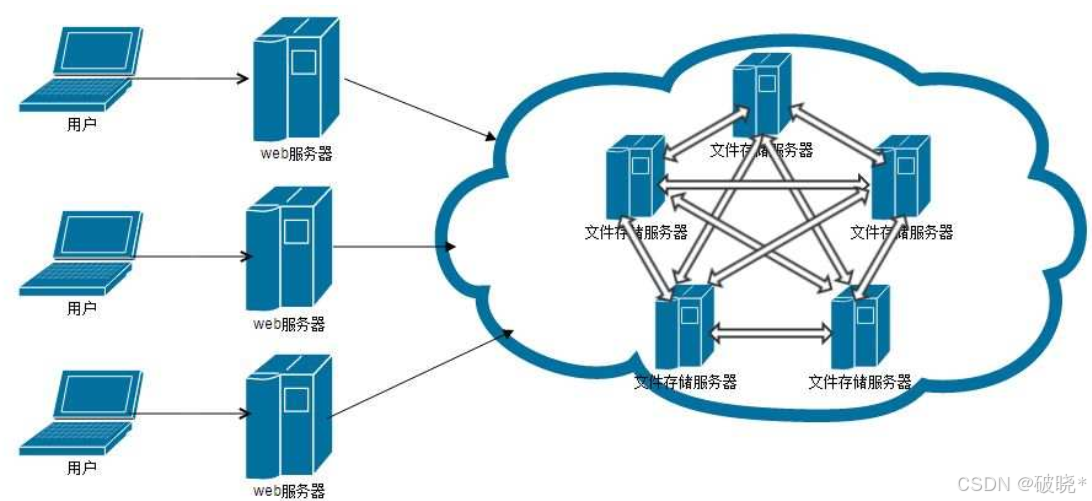
这样组织形式的好处有三点
1.一台计算机的文件系统处理能力能够扩充到多台计算机同时进行处理
2.一台计算机挂了还有另外副本计算机能够提供数据
3.每台计算机可以放在不同的地域,这样方便用户可以就近访问,提高数据访问速度
市面上常用的分布式文件系统的产品有哪些?
这里列举三个常用的分布式文件系统:NFS,GFS,HDFS
1.NFS(Network File System网络文件系统)是一种分布式文件系统的协议,它能够让用户通过网络访问远程文件系统,就像访问本地文件系统一样,它的架构是典型的 客户端-服务器 架构,支持跨平台文件共享
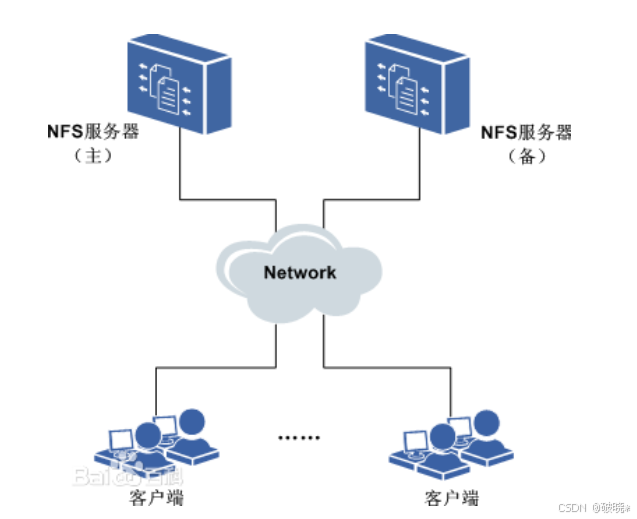
核心特点:
(1)实现透明访问
- 用户可以通过网络挂载远程文件系统,像操作本地文件一样访问远程文件
- 客户端通过网络访问NFS服务器的硬盘完全透明
(2)能够跨平台支持
- 支持多种操作系统(如Linux,UNIX,macOS,Windows)
- 通过协议标准化实现不同系统之间的文件共享
(3)基于RPC(远程过程调用)
- NFS使用RPC机制实现客户端与服务器之间的通信
- 并依赖于外部服务管理端口映射
NFS的主要应用场景:
- 文件共享 — 在局域网内共享文件,适合团队协作
- 数据中心 — 用于虚拟机或容器集群的共享存储
- 开发环境 — 开发人员能够通过NFS共享代码库和数据
但是,NFS是一种简单,易用的文件共享协议,更适合小规模网络环境;
在大规模,高性能或高安全性要求的场景中,我们需要用到更现代的分布式文件系统(如HDFS,GFS)来替代
适合大规模数据集的分布式文件系统:HDFS,GFS
1.HDFS(Hadoop Distributed File System)既Hadoop分布式文件系统,是Apache Hadoop项目的核心组件之一,是一个高度容错性的系统,适合部署在廉价的机器上。它能够提高 高吞吐量的数据访问,非常适合在大规模数据集上应用,HDFS的文件分布在集群机器上,同时又提供了副本进行容错以及可靠性保证,例如客户端写入读取文件的直接操作都是分布在集群各个机器上的,没有单点性能压力
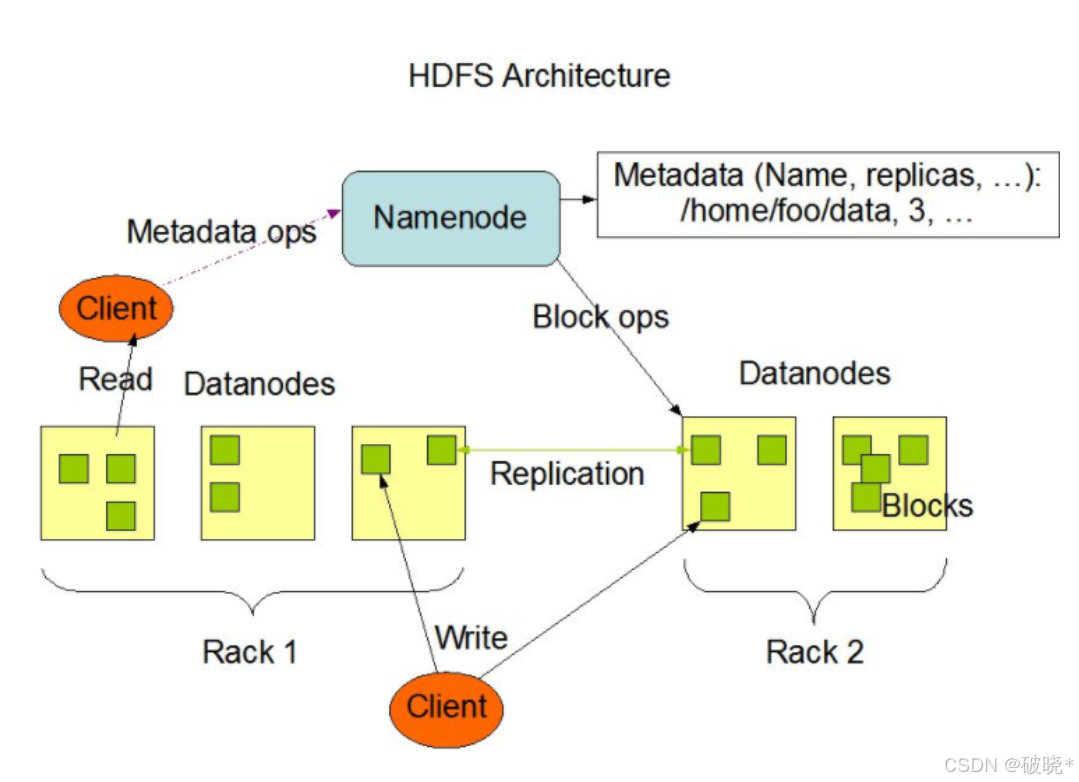
它的特点有:
(1)高容错性:数据自动复制到多个节点,即使某个节点发生故障,数据仍然可以从其他节点访问
(2)高吞吐量:优化了大数据批处理作业,适合顺序读写,而非随机访问;通过将大文件分块(128MB或256MB)分布存储,实现并发处理
主要应用场景有设计大数据分析,和作为数据源的基础存储层,并且适合存储大量的日志数据,能够供后续分析使用,也可以用在存出训练数据和模型支持分布式的机器学习
尽管它在低延迟访问和小文件处理方面存在局限性,但高吞吐量,高容错性和低成本的优势能够在大数据领域占据高地位
2.GFS是Google文件系统(Goodle File System),是谷歌公司开发,用来满足处理和存储大量的数据(如网页,图像,视频等)而开发的分布式文件系统,百度百科解释为:

主要特点有:
- GFS能够轻松扩展到包含成百上千个节点的大规模集群,并且能够通过数据冗余和自动故障检测与恢复机制,确保数据的可靠性和可用性
- 还采用了一系列优化技术提高数据读写性能,比如数据预取,流水线式的数据读写等等,对大规模数据有较好的支持,譬如适合处理大规模的顺序读写数据
适合于大规模数据存储管理,如互联网日志、科研实验数据;二是数据流式读写,契合大数据分析、数据备份归档需求;三是高并发读场景,像 CDN、在线视频服务;四是容错性要求高的领域,如金融交易、政府关键数据存储,能满足其对数据安全和可靠性的严苛要求
理解MinIO系统
这里我介绍另一种高性能的开源对象存储系统 MinIO系统,虽然它不属于传统意义上的分布式文件系统,但在分布式环境中能够发挥出重要作用
MinIO是一个非常 轻量 的服务,可以很简单的和其他应用结合使用,兼容亚马逊S3云存储服务接口,适合存储图片,视频,日志文件,备份数据和容器/虚拟机镜像等大容量非结构化的数据
它的一大特点就是轻量,使用简单,功能强大,支持各种平台,单个文件最大5TB,兼容Amazon S3接口,提供了Java,Python,Go等多版本SDK支持
MinIO中文官网:http://docs.minio.org.cn/docs/
MinIO集群采用去中心化共享架构,每个结点是对等关系,通过Nginx可对MinIO进行负载均衡访问
去中心化有什么好处?
在大数据领域,通常的设计理念都是 无中心 和 分布式,Minio分布式模式可以帮助搭建一个高可用的对象存储服务,我们可以使用这些存储设备,而不用考虑其真实物理位置
它将分布在不同服务器上的多块硬盘组成一个对象存储服务,由于硬盘分布在不同的节点上,分布式Minio避免了单点故障,如下图:
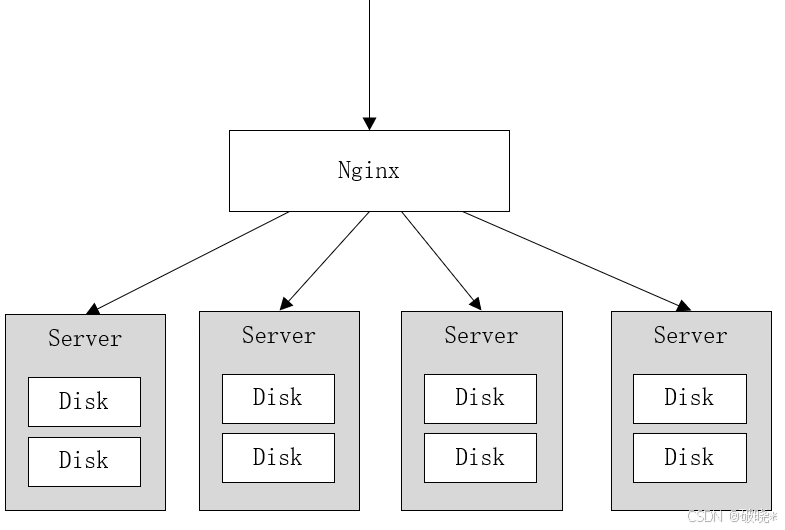
Minio使用 纠删码技术 来保护数据,它是一种恢复丢失和损坏数据的数学算法,它将数据分块冗余,分散存储在各个节点的磁盘上,所有可用磁盘组成一个集合,上图由8块硬盘组成一个集合,当上传一个文件时会通过纠删码算法计算对文件进行分块存储,除了将文件本身分为4个数据块,还会生成4个校验块,数据块和校验块会分散的存储在这8块硬盘上
使用纠删码的好处是即便丢失一半数量(N/2)的硬盘,仍然可以恢复数据,比如上边集合中有4个以内的硬盘损害,仍可保证数据恢复,不影响上传和下载;但如果多于一半的硬盘损坏,则无法恢复
数据恢复演示
我来演示一下MinIO恢复数据的过程,在本地创建4个目录表示4个硬盘

MinIO下载地址:https://dl.min.io/server/minio/release/
安装完成后,cmd进入有minio.exe所在目录,执行下边的命令,会在D盘创建4个目录,模拟4个硬盘
minio.exe server D:\develop\minio_data\data1 D:\develop\minio_data\data2 D:\develop\minio_data\data3 D:\develop\minio_data\data4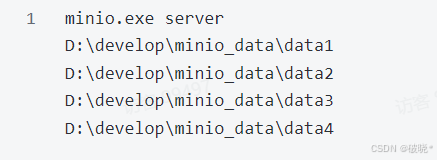
启动结果如下:
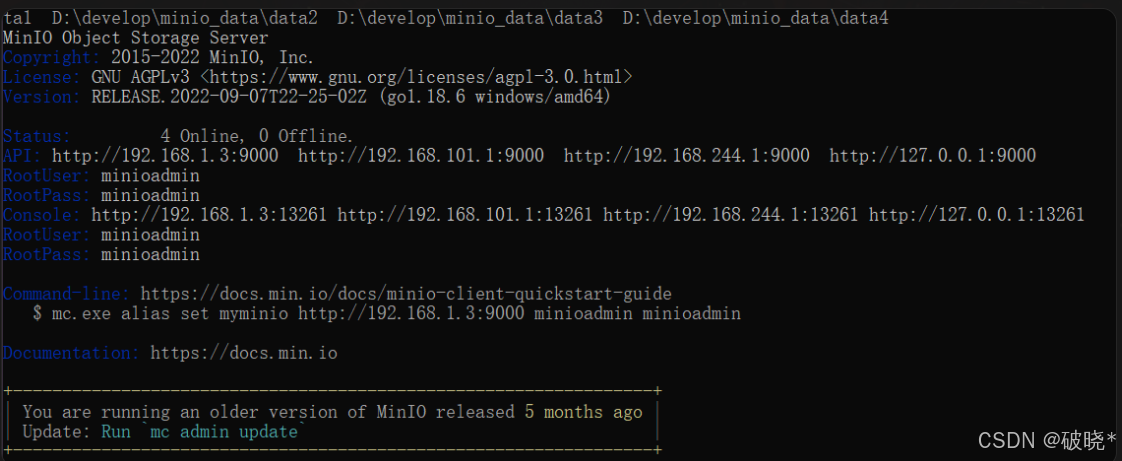
pool 即minio节点组成的池子,当前有一个pool和4个硬盘组成的set集合
登录MinIO,默认账号密码均为minioadmin

登陆成功:
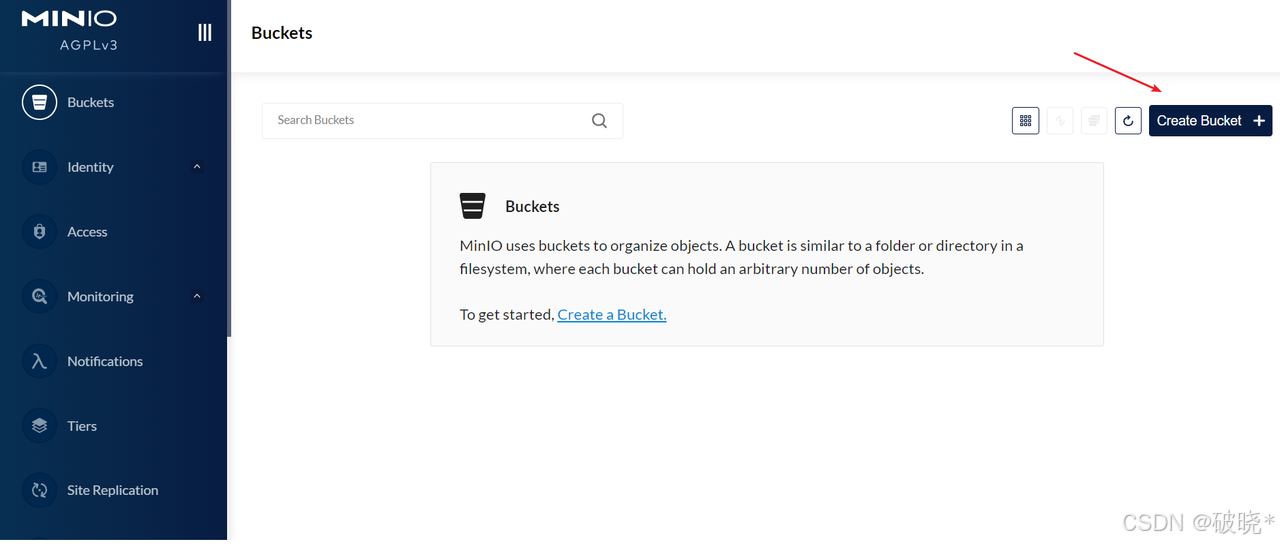
下一步创建bucket桶,它相当于存储文件的目录,可以创建若干的桶
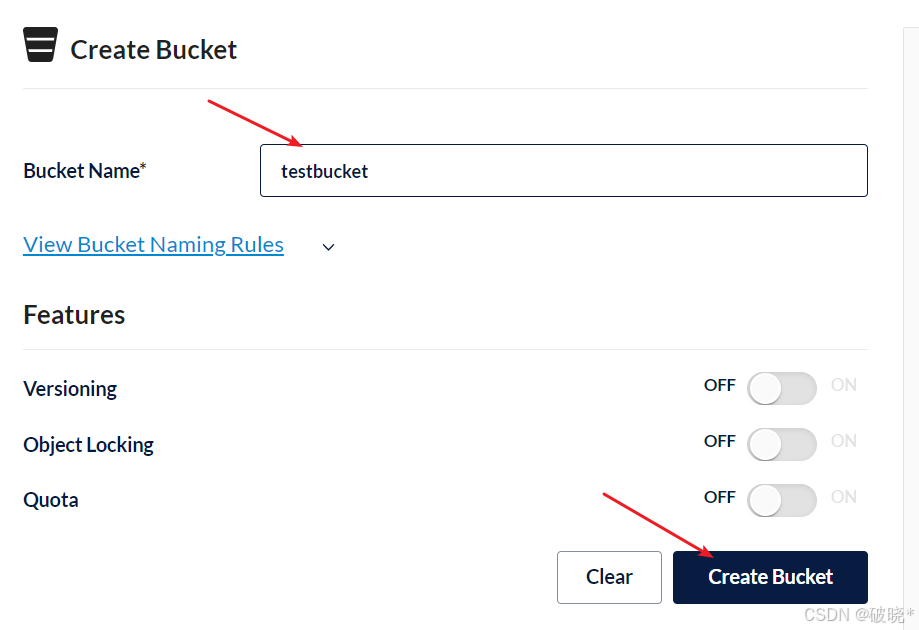
输入bucket的名称,点击“CreateBucket”,创建成功
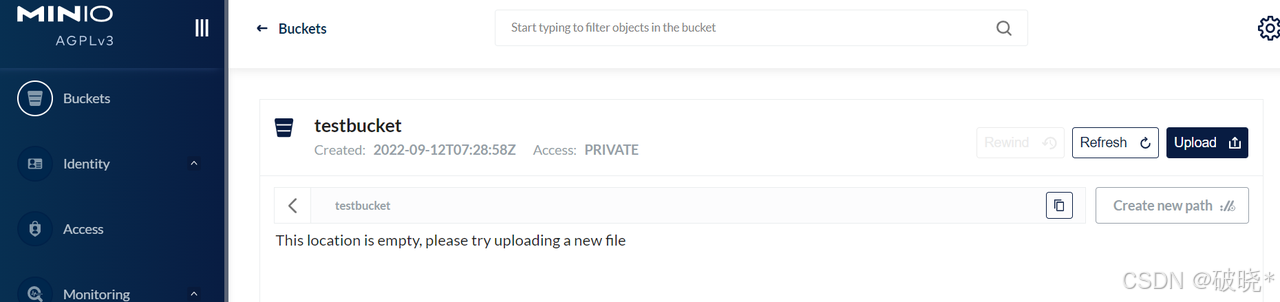
点击“upload”上传文件,观察四个目录下文件的存储情况
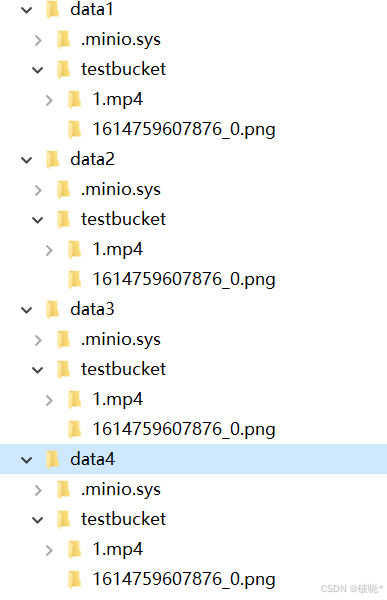
我们发现上传的1.mp4文件存储在了四个目录,既四个硬盘上
下面测试minio的数据恢复过程:
1.首先删除一个目录
删除目录后仍然可以在web控制台上传文件和下载文件,稍等片刻删除的目录自动恢复
2.删除两个目录
删除两个目录也会自动恢复
3.删除三个目录
由于集合中有4块硬盘,有大于一半的硬盘损坏数据无法恢复
此时报错: We encountered an internal error,please try again . (Read failed. Insufficient number of drivers online)在线驱动器数量不足
测试Docker环境
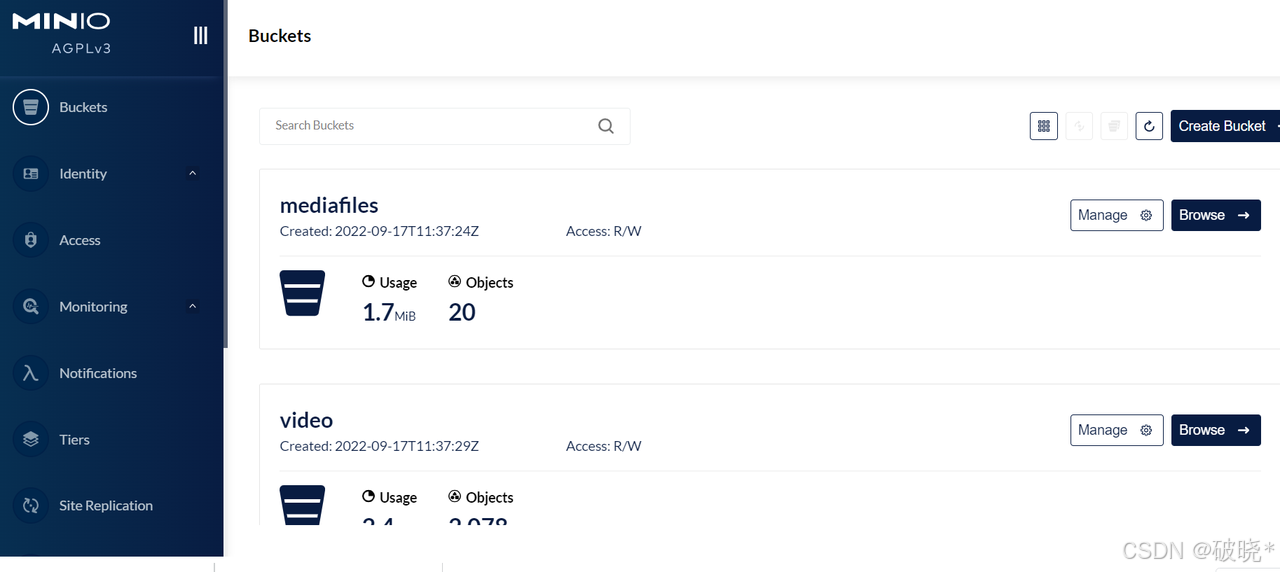
开发阶段和生成阶段统一使用Docker下的Minio,在下发的虚拟机中已经安装了Minio的镜像和容器,执行sh/data/soft/restart.sh启动Docker下的MinIO
启动完成登录MinIO查看是否正常,之后创建两个buckets : mediafiles(普通文件) 和 video(视频文件)
SDK(软件开发工具包)
上传文件
MinIO支持多个语言版本SDK的支持,Java版本的文档地址:https://docs.min.io/docs/java-client-quickstart-guide.html![]() https://docs.min.io/docs/java-client-quickstart-guide.html在我们的测试项目(媒介管理)service工程中添加依赖
https://docs.min.io/docs/java-client-quickstart-guide.html在我们的测试项目(媒介管理)service工程中添加依赖
<dependency>
<groupId>io.minio</groupId>
<artifactId>minio</artifactId>
<version>8.4.3</version>
</dependency>
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.8.1</version>
</dependency>从官方文档中看到,需要三个参数才能连接到minio服务
| 参数 | 说明 |
| Endpoint | 对象存储服务的URL |
| Access Key | Access key就像用户ID,可以唯一标识你的账户 |
| Secret Key | Secret key是你账户的密码 |
官方的示例代码:
import io.minio.BucketExistsArgs;
import io.minio.MakeBucketArgs;
import io.minio.MinioClient;
import io.minio.UploadObjectArgs;
import io.minio.errors.MinioException;
import java.io.IOException;
import java.security.InvalidKeyException;
import java.security.NoSuchAlgorithmException;
public class FileUploader {
public static void main(String[] args)throws IOException, NoSuchAlgorithmException, InvalidKeyException {
try {
// Create a minioClient with the MinIO server playground, its access key and secret key.
MinioClient minioClient =
MinioClient.builder()
.endpoint("https://play.min.io")
.credentials("Q3AM3UQ867SPQQA43P2F", "zuf+tfteSlswRu7BJ86wekitnifILbZam1KYY3TG")
.build();
// Make 'asiatrip' bucket if not exist.
boolean found =
minioClient.bucketExists(BucketExistsArgs.builder().bucket("asiatrip").build());
if (!found) {
// Make a new bucket called 'asiatrip'.
minioClient.makeBucket(MakeBucketArgs.builder().bucket("asiatrip").build());
} else {
System.out.println("Bucket 'asiatrip' already exists.");
}
// Upload '/home/user/Photos/asiaphotos.zip' as object name 'asiaphotos-2015.zip' to bucket
// 'asiatrip'.
minioClient.uploadObject(
UploadObjectArgs.builder()
.bucket("asiatrip")
.object("asiaphotos-2015.zip")
.filename("/home/user/Photos/asiaphotos.zip")
.build());
System.out.println(
"'/home/user/Photos/asiaphotos.zip' is successfully uploaded as "
+ "object 'asiaphotos-2015.zip' to bucket 'asiatrip'.");
} catch (MinioException e) {
System.out.println("Error occurred: " + e);
System.out.println("HTTP trace: " + e.httpTrace());
}
}
}这段代码使用MinIO Java SDK实现了一个简单的文件上传功能,它将本地文件上传到MinIO存储桶中,并在上传前检查存储桶是否存在,如果不存在则创建存储桶
代码主要实现了以下功能:
- 连接到MinIO服务器
- 检查存储桶asiatrip是否存在,如果不存在则创建
- 将本地文件/home/user/Photos/asiaphotos.zip上传到存储桶asiatrip中,并命名为asiaphotos-2015.zip
- 处理可能发生的异常,并打印错误信息
代码块解释:
import io.minio.BucketExistsArgs;
import io.minio.MakeBucketArgs;
import io.minio.MinioClient;
import io.minio.UploadObjectArgs;
import io.minio.errors.MinioException;
import java.io.IOException;
import java.security.InvalidKeyException;
import java.security.NoSuchAlgorithmException;这段import代码块语句,导入了MinIO SDK和相关依赖库,用于连接MinIO服务器,操作存储桶和上传文件
MinioClient minioClient =
MinioClient.builder()
.endpoint("https://play.min.io")
.credentials("Q3AM3UQ867SPQQA43P2F", "zuf+tfteSlswRu7BJ86wekitnifILbZam1KYY3TG")
.build();
- 创建了MinIO客户端实例,用于与MinIO服务器交互
- .endpoint("https://play.min.io"):指定了MinIO服务器的地址(这里是MinIO的公告测试服务器)
.credentials("Q3AM3UQ867SPQQA43P2F", "zuf+tfteSlswRu7BJ86wekitnifILbZam1KYY3TG")
- 这段代码提供了访问密钥和秘密密钥,用于身份验证
- build():则是构建了MinIO客户端对象
boolean found =
minioClient.bucketExists(BucketExistsArgs.builder().bucket("asiatrip").build());
- 检查存储桶asiatrip是否存在
- 如果存储桶不存在,则创建存储桶(创建名为asiatrip)的存储桶,如果存储桶已存在,则打印提示信息,存储桶已创建成功
minioClient.uploadObject(
UploadObjectArgs.builder()
.bucket("asiatrip")
.object("asiaphotos-2015.zip")
.filename("/home/user/Photos/asiaphotos.zip")
.build());该代码块主要是上传本地文件到MinIO存储桶
.bucket(“asiatrip”)用于指定目标存储桶
.object("asiaphotos-2015.zip")则是指定对象在存储桶中的名称
.filename("/home/user/Photo/asiaphotos.zip")用于指定本地文件的路径
那么我们在其基础上进行修改,完成基本的上传,下载和删除功能
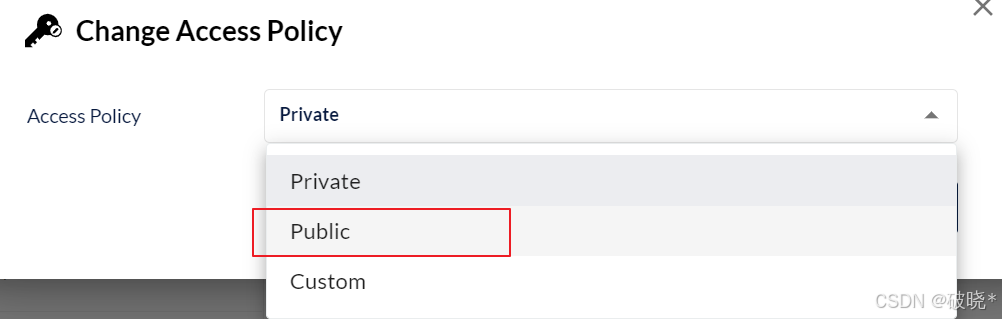
在此之前,我们先创建一个名为testbucket的桶,然后将其权限修改为public
修改为public权限
项目中,在需要管理文件的media-service工程的test下编写测试代码,修改一下连接参数,bucket名,和要上传的文件路径,就可以进行测试
@SpringBootTest
public class MinioTest {
//创建MinioClient对象
static MinioClient minioClient =
MinioClient.builder()
.endpoint("http://192.168.101.65:9000")
.credentials("minioadmin", "minioadmin")
.build();
//上传文件
@Test
public void upload() {
try {
UploadObjectArgs testbucket = UploadObjectArgs.builder()
.bucket("testbucket")
// .object("test001.mp4")
.object("001/test001.mp4")//添加子目录
.filename("D:\\develop\\upload\\1mp4.temp")
.contentType("video/mp4")//默认根据扩展名确定文件内容类型,也可以指定
.build();
minioClient.uploadObject(testbucket);
System.out.println("上传成功");
} catch (Exception e) {
e.printStackTrace();
System.out.println("上传失败");
}
}
}实现功能:基于Spring Boot的测试类,使用MinIO Java SDK实现文件上传功能
static MinioClient minioClient = MinioClient.builder()
.endpoint("http://192.168.101.65:9000")
.credentials("minioadmin", "minioadmin")
.build();
- 创建了一个静态的MinioClient对象,用于与MinIO服务器交互
- .endpoint() 则是指定了MinIO服务器的地址(这里是MinIO的默认用户名和密码)
- .build():用于构建MinIOClient对象
public void upload(){...};这段upload方法用于上传文件
UploadObjectArgs testbucket = UploadObjectArgs.builder().bucket("testbucket")
.object("test001.mp4")
.object("001/test001.mp4")//添加子目录
.filename("D:\\develop\\upload\\1mp4.temp")
.contentType("video/mp4")//默认根据扩展名确定文件内容类型,也可以指定
.build();- .bucket("testbucket")用于指定目标存储桶名称
- .object("001/test001.mp4")指定对象在存储桶中的名称
- .filename(“D:\\develop\\upload\\1mp4.temp”)指定本地文件的路径
- .contentType("video/mp4")指定文件的内容类型
- .build():构建上传参数对象
minioClient.uploadObject(testbucket);调用了minioClient的uploadObject方法,将本地文件上传到MinIO存储桶,如果上传成功则打印上传成功提示信息,并且能够通过web控制台查看文件,并预览文件
删除文件
编写测试方法
@Test
public void deleteTest() {
try {
minioClient.removeObject(RemoveObjectArgs
.builder()
.bucket("testbucket")
.object("pic01.png")
.build());
System.out.println("删除成功");
} catch (Exception e) {
System.out.println("删除失败");
}
}该deleteTest测试方法,主要功能是从MinIO对象存储服务的指定存储桶中删除一个指定的对象(文件),代码使用了MinIO Java SDK提供的客户端和相关API来完成对象删除操作,并对操作结果进行简单的反馈输出
minioClient.removeObject(RemoveObjectArgs
.builder()
.bucket("testbucket")
.object("pic01.png")
.build());
- minioClient是一个对象MinioClient对象,它是MinIO Java SDK提供的用于与MinIO服务器进行交互的客户端
- RemoveObjectArgs.builder()则是使用构建器模式创建一个RemoveObjectArgs对象的构建器实例,RemoveObjectArgs则是MinIO Java SDK中用于封装删除对象操作所需参数的类
- .bucket("testbucket"):设置要删除对象所在的存储桶名称为testbucket,存储桶是MinIO中用于组织和管理对象的容器
- .object(“pic01.png”):指定要删除的对象名称为“pic01.png”,这个名称是对象在存储桶中的唯一标识
- .build():调用构建器的build方法,构建并返回一个完整的RemoveObjectArgs对象
- minioClient.removeObject(...):调用MinioClient对象的removeObject方法,传入构建好的RemoveObjectArgs对象,向MinIO服务器发送删除对象的请求
查询文件
通过查询文件查看文件是否存在minio中,
@Test
public void getFileTest() {
try {
InputStream inputStream = minioClient.getObject(GetObjectArgs.builder()
.bucket("testbucket")
.object("pic01.png")
.build());
//校验文件的完整性 对文件计算出md5值
FileOutputStream fileOutputStream = new FileOutputStream("C:\\Users\\15863\\Desktop\\tmp.png");
IOUtils.copy(inputStream,fileOutputStream);
System.out.println("下载成功");
} catch (Exception e) {
System.out.println("下载失败");
}
}代码块使用JUnit框架编写的测试方法,主要功能是从MinIO对象存储服务中下载指定的文件到本地
InputStream inputStream = minioClient.getObject(GetObjectArgs.builder()
.bucket("testbucket")
.object("pic01.png")
.build());获取MinIO对象的输入流:minioClient:是一个MinioClient类型的对象,它是MinIO Java SDK提供的用于与MinIO服务器进行交互的客户端()
- .GetObjectArgs.builder():使用构建器模式创建GetObjectArgs对象的构建器实例。GetObjectArgs类用于封装从MinIO获取对象(文件)所需的参数
- .bucket(“testbucket”):指定要从哪个存储桶中获取文件,这里存储桶的名称是testbucket
- .object(“pic01.png”):指定要获取的文件在存储桶中的对象名称,既“pic01.png”
- .build():调用构建器的build方法,构建并返回一个完整的GetObjectArgs对象
- minioClient.getobject(...):调用MinioClient对象的getobject方法,传入构建好的GetobjectArgs对象,从MinIO服务器获取指定的文件,并返回一个InputStream类型的输入流,用于读取文件内容
创建本地文件输出流:
FileOutputStream fileOutputStream = new FileOutputStream("C:\\Users\\15863\\Desktop\\tmp.png");FileOutputStream:是Java中用于向文件写入数据的输出流类
"C:\\Users\\15863\\Desktop\\tmp.png":指定了要将从MinIO下载的文件保存到本地的路径和文件名,这里创建了一个文件输出流,用于将从MinIO读取的文件内容写入到本地文件tmp.png中
复制文本内容
IOUtils.copy(inputStream,fileOutputStream);IOUtils: 通常是Apache Commons IO库中的工具类,提供了许多方便的输入输出操作方法
IOUtils.copy(inputStream,fileoutputStream):调用IOUtils类的copy方法,将从MinIO获取到的输入流inputStream中的数据复制到本地文件的输出流fileOutputStream中,从而实现文件从MinIO下载到本地的功能
MinIO与传统文件系统的区别
MinIO是开源的,兼容Amazon S3 API的对象存储,适合存储非结构化数据(如图片,视频等)。而分布式文件系统(如HDFS,Ceph),旨在跨过个节点存储和管理文件,提供高可用性和扩展性
架构差异:MinIO使用纠错码来实现数据冗余,而HDFS采用副本机制,这影响到数据恢复和存储效率的不同
核心区别总结:
| 维度 | MinIO | 分布式文件系统 |
|---|---|---|
| 数据组织方式 | 对象(通过唯一键访问) | 文件(通过目录层级访问) |
| 接口兼容性 | 完全兼容 S3 API,适合云原生应用 | 需适配专用 API(如 HDFS 的 Java API) |
| 元数据管理 | 轻量级元数据,直接嵌入对象中 | 复杂元数据管理(如 HDFS 的 NameNode) |
| 小文件处理 | 效率较低(对象存储的通病) | 部分系统优化较好(如 CephFS) |
架构与设计目标方面:
| 特性 | MinIO | 分布式文件系统 |
|---|---|---|
| 数据冗余 | 使用纠删码(Erasure Coding)实现冗余 | 通常使用副本机制(如 HDFS 默认 3 副本) |
| 扩展性 | 横向扩展,支持动态添加节点 | 横向扩展,但需预规划存储策略 |
| 适用场景 | 非结构化数据(图片、视频、日志) | 结构化或半结构化数据(文件、数据库备份) |
| 性能优化 | 高吞吐量,适合顺序读写 | 根据类型不同,可能支持随机读写(如 Ceph) |
总结:选择MinIO的情况:
- 需要兼容S3协议,快速集成云原生应用
- 存储非结构化数据(如图片,视频)
选择分布式文件系统的情况:
- 需要文件系统的目录树结构(如传统应用迁移)
- 混合负载场景(需同时支持文件,块,对象存储)
- 对低延迟随机读写有要求(如数据库存储)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









