






目录
一、打开想要爬取的网站
以豆瓣读书为例:https://book.douban.com/tag/%E5%8A%B1%E5%BF%97
二、复制粘贴网站
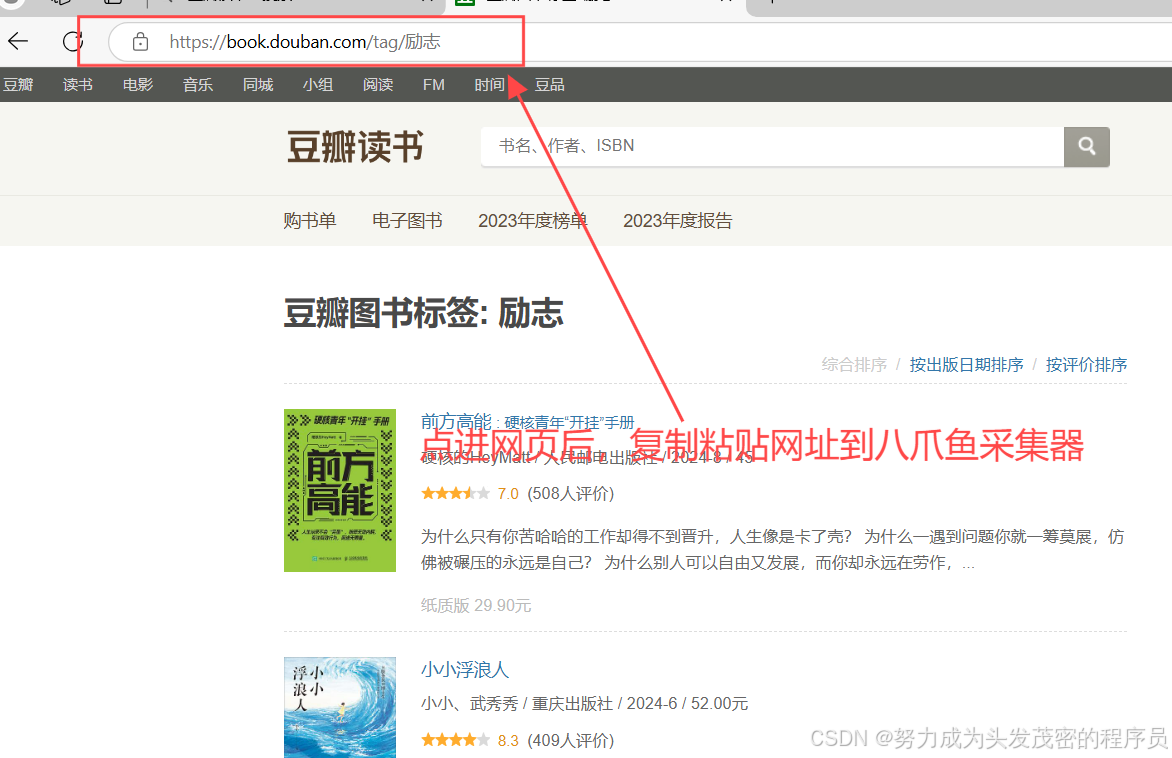
三、打开八爪鱼采集器
步骤:新建-自定义任务-手动输入下的文本框里粘贴网址-保存设置
四、进入页面,鼠标点击你想查询的内容,如下图所示:
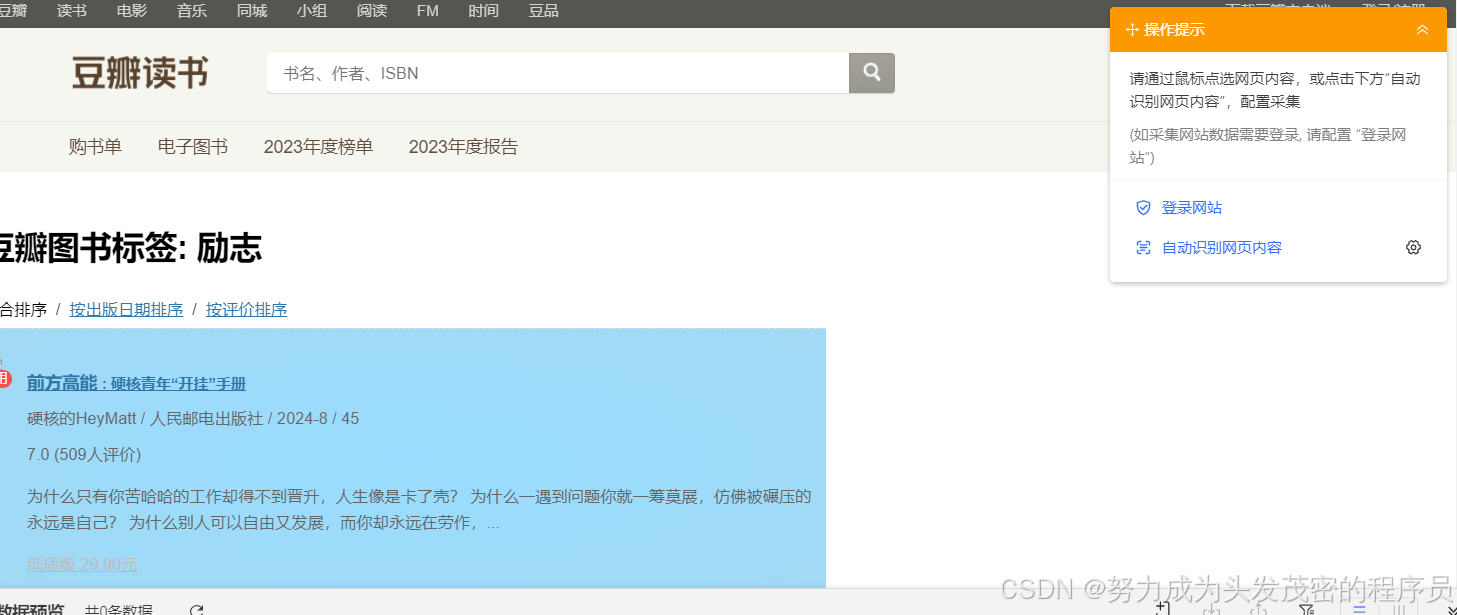
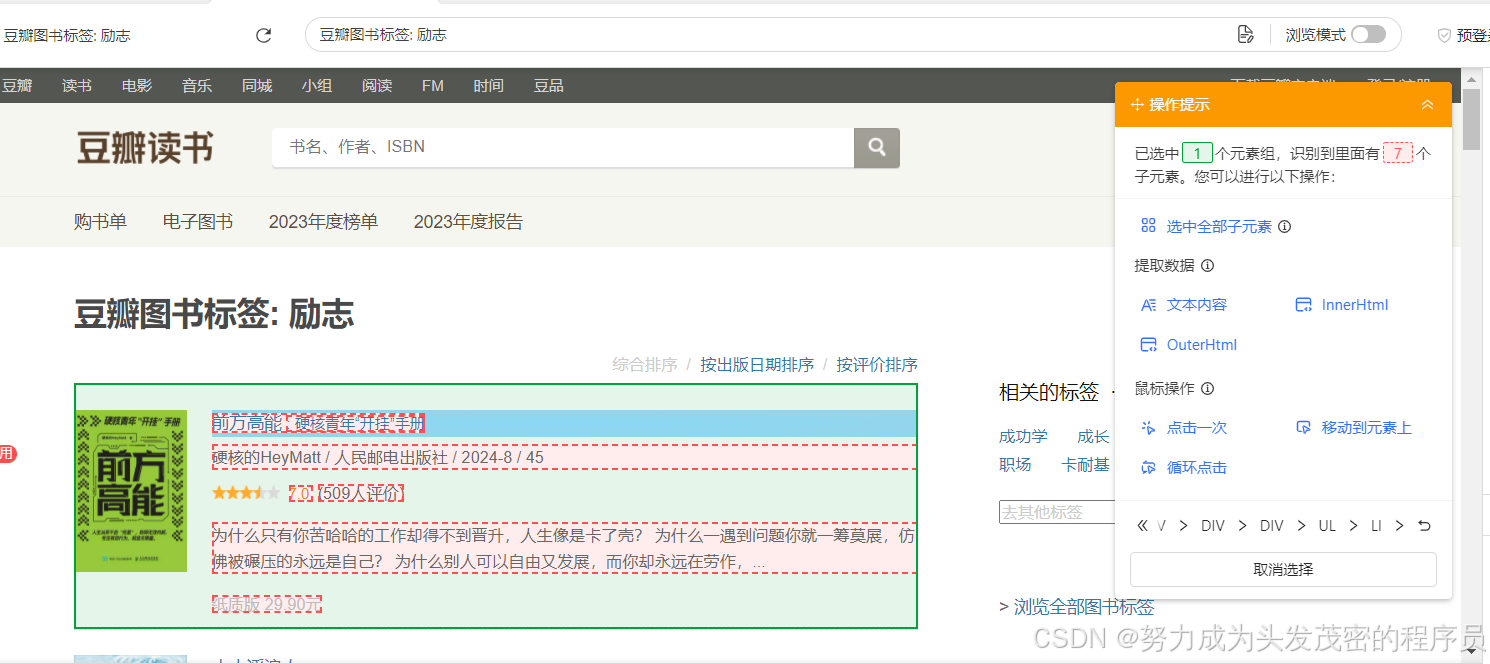
五、根据右上角的操作提示来完成,如下图
选中全部子元素-选中全部相似组-元素中的数据内容
【如果不翻页,那么此时就可以不用继续往下看文章了,直接点击右上角的保存-采集,即可】
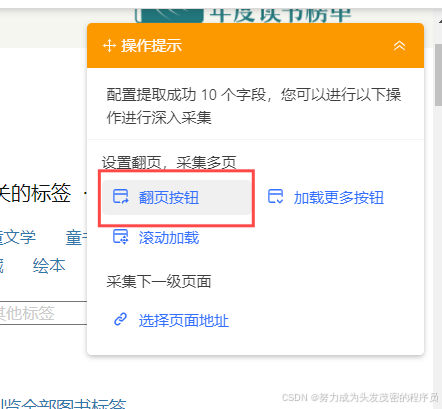
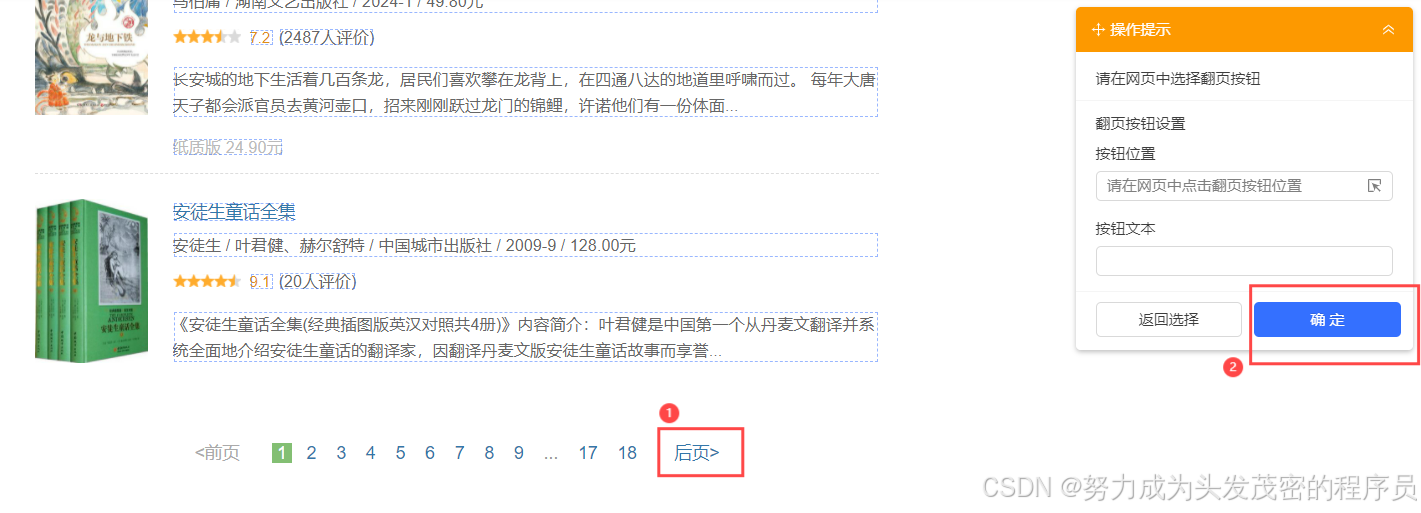
六、网页翻页
点击翻页按钮-点击“后页”-确认-完成,如图
七、再次打开刚才的网页界面
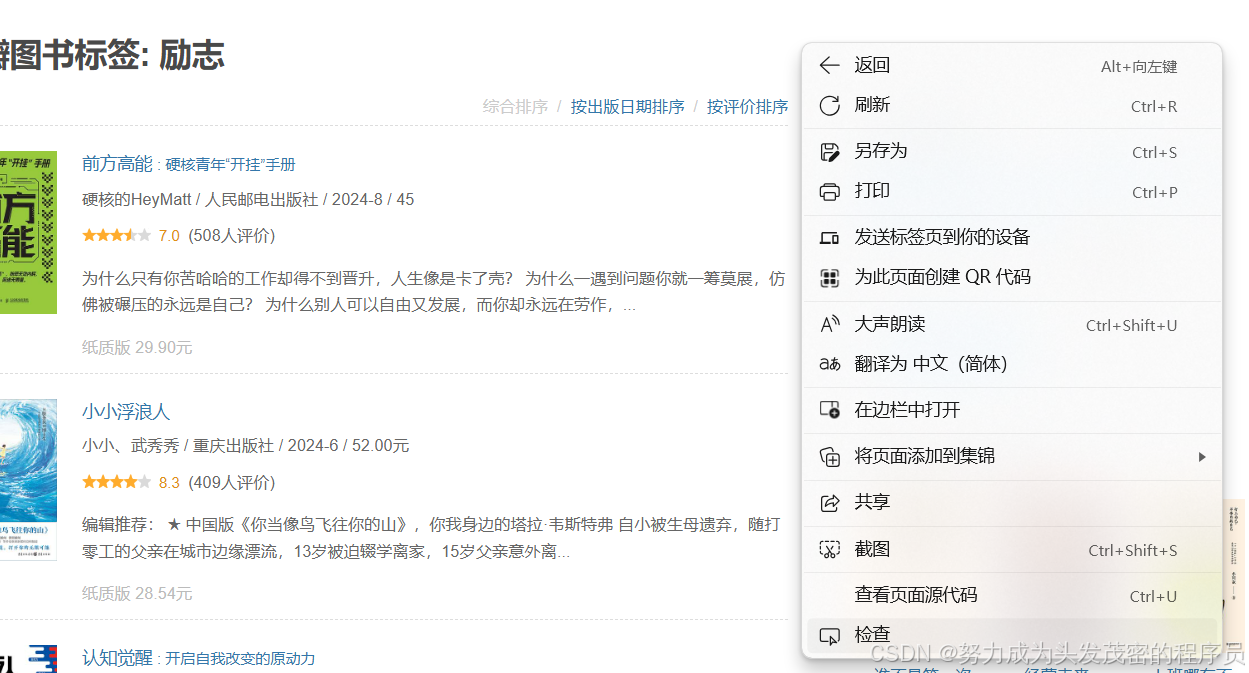
单击右键-点击检查-鼠标划到最后点击“后页”。
(这个网页是“后页”,但其他的网站是什么,大家根据实际情况看就行)如下图
八、代码编写
这里是要写一部分代码啦,很重要哦(敲黑板)
1、我们先学习一下这条代码的XPath语言逻辑与注解
1、/或//:选取元素的符号,也表示不论后面的元素在html中的任何位置,均选取该元素(也就是所查询那节代码开头的第一个“单词”)
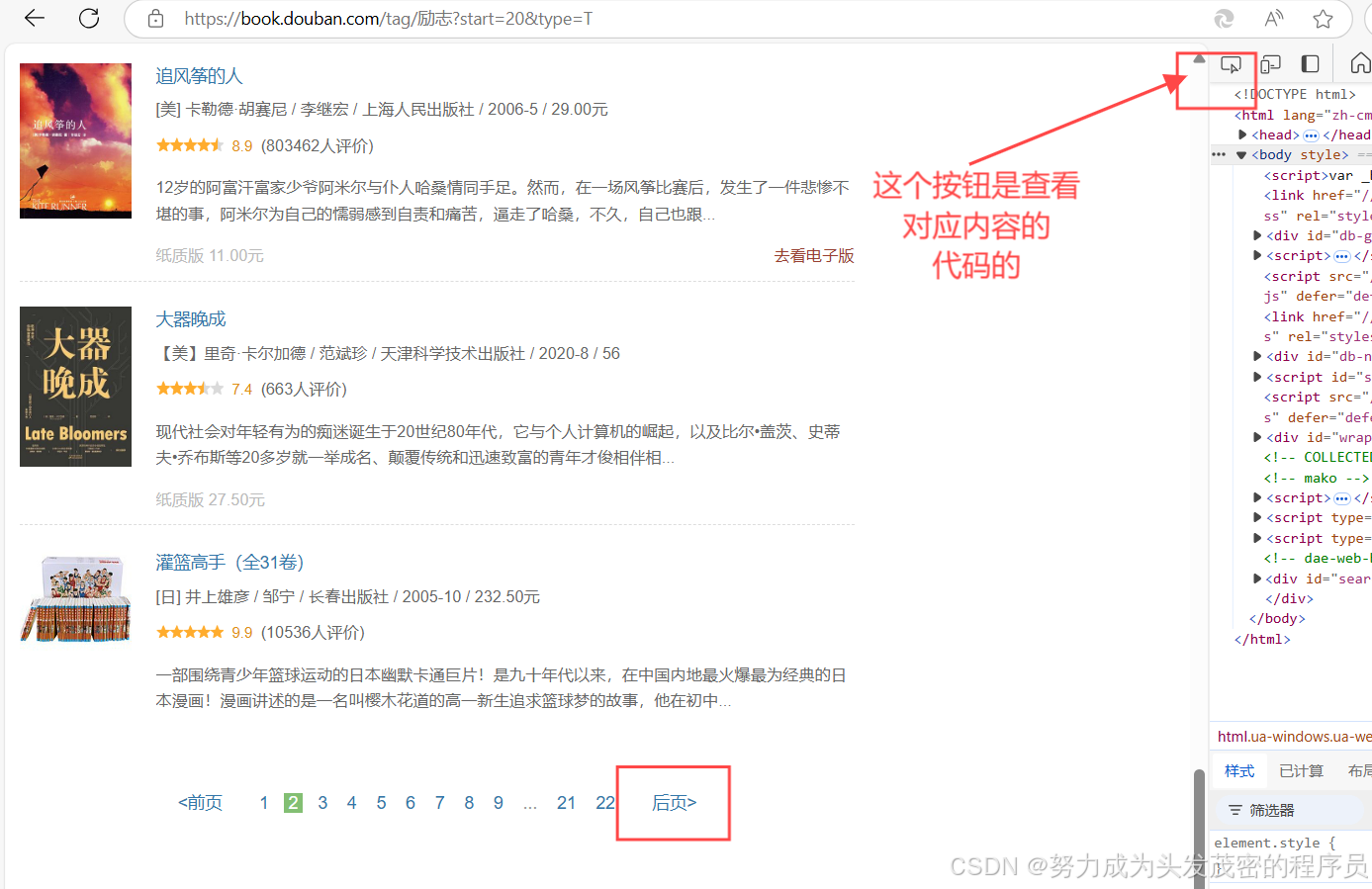
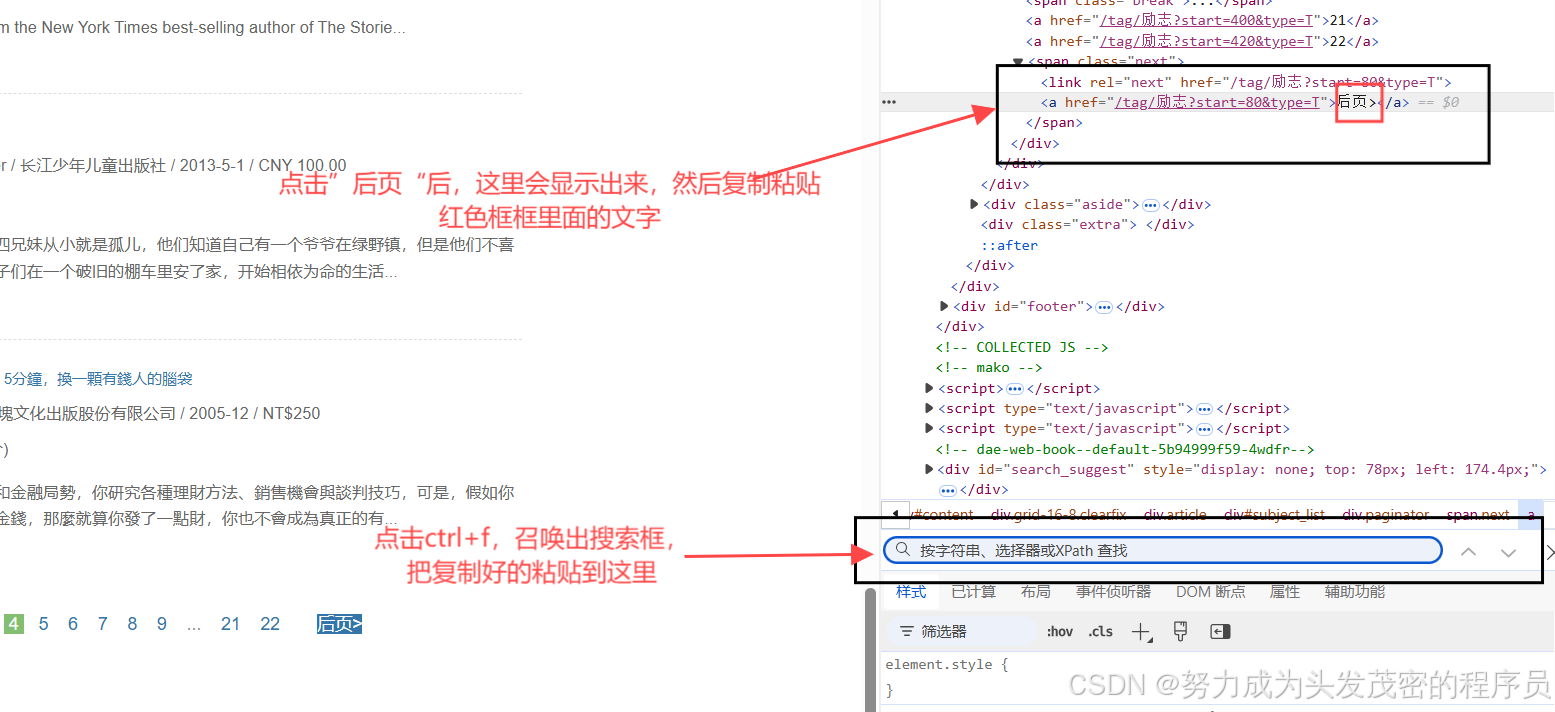
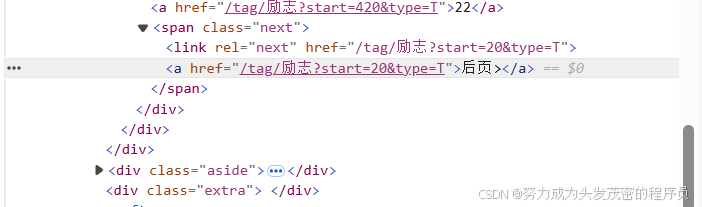
如下图的代码:<a href "/tag/励志?start=20&ty.pe=T">后页></a>
那么开头的单词就是“a”
因此写为://a[ ]
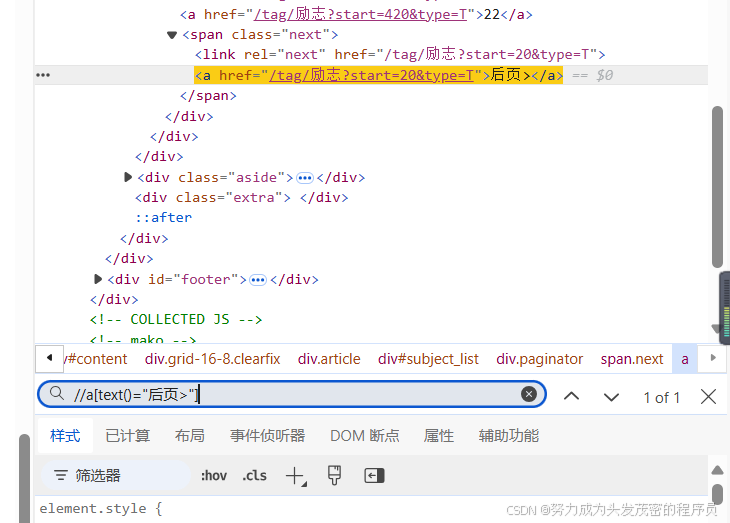
因为“后页”是文本爬取,所以需要用taxt这个特殊函数(特殊原因:用不上@符号,关于@符号文章后面会提,这里不做过多阐述)
所以翻页代码如下
//a[text()="后页>"]这就是最简单的XPath代码逻辑,在搜索框写完后,通过看代码页面有没有显示黄色标注(如下图),如没有,则代码有错,再仔细核对修改;如有,则可继续看步骤九了。
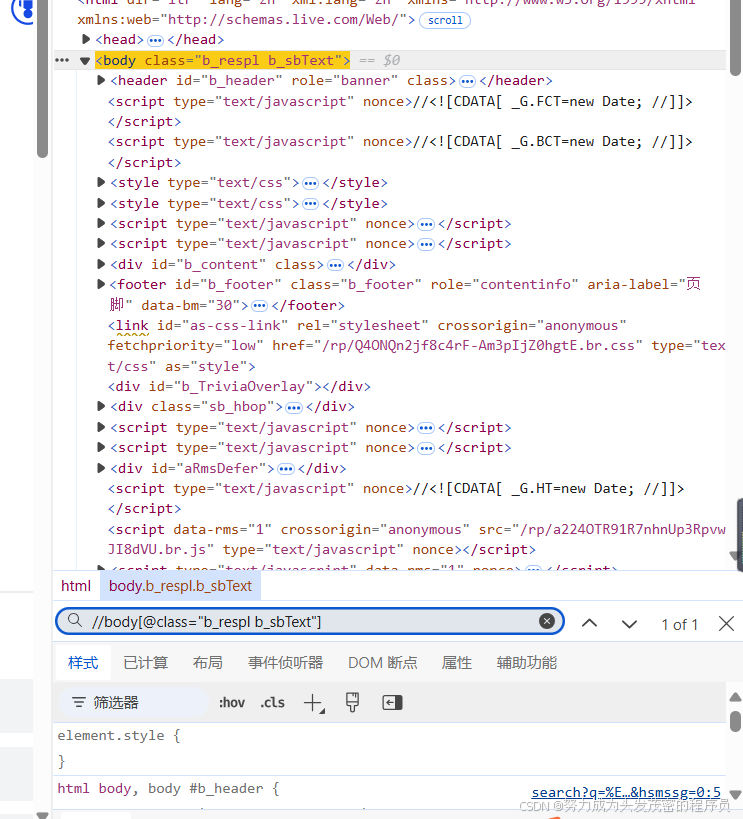
补充:2、@:选取属性(写在属性前面)
如图的代码(这个代码是我额外补充的知识点,和例子八爪鱼爬取翻页关系不大,但很实用):<body class="b_respl b_sbText"
那么属性就是:class
因此写为://body[ @class="b_respl b_sbText"]
通过看代码页面有没有显示黄色标注(如下图),如没有,则代码有错,再仔细核对修改;如有,则可继续看步骤九了。
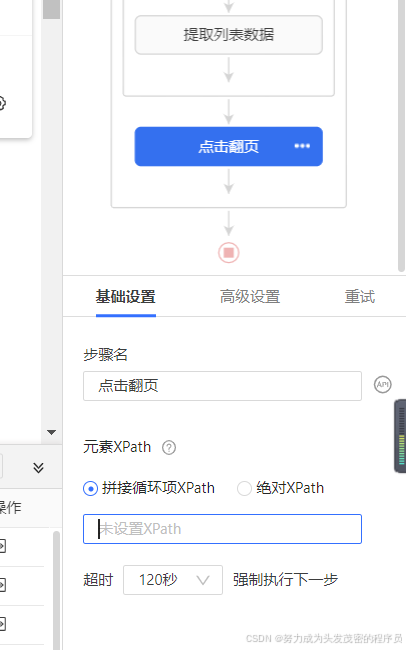
九、将编辑好的代码放入八爪鱼采集器中
因为我是以:如何使网页在八爪鱼采集器中翻页为例,所以再次进入开始打开的爬取界面,
“点击翻页”-基础设置-元素XPath-拼接循环项XPath-复制粘贴步骤八测试出的代码-点击“应用”
即可,如图
ps:测试自己有没有翻页成功:点击“循环翻页”-“点击翻页”-再次点击“循环翻页”-再次点击“点击翻页”。然后观察网页界面,会发现网页跳转到第二页了,恭喜!说明翻页成功!


















 30万+
30万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









