







目录
(3)CF617 EXOR and Favorite Number
前言
今日机房集训,对根号类算法有了一点浅薄的理解,把篇博客庆祝一下
分块
1.引入
我们思考一下这个问题
LOJ6277 数列分块入门 1 给定长度为 n 的数列,n 次操作,区间加法,单点查询。 n≤50000
假设我们很菜,没学过线段树,甚至刚刚学会A+B Problem,那么这种情况下,我们将写出一种优雅的算法,暴力,区间加法时从 l 到 r 枚举,暴力修改,复杂度 O(n^2)。
思考优化
我们发现区间修改这个操作对 l 到 r 每个位置执行的操作都是把 a_i 加上一个数 x。 那我们能不能把不同位置合并一下,一次性对连续的一些数一起进行操作?
其实这就是分块的思想。
分块的基本思想是,通过对原数据的适当划分,并在划分后的每一个块上预处理部分信息,从而较一般的暴力算法取得更优的时间复杂度。 ——oi-wiki
2.算法思路
如果我们将数列连续B个划为一块,维护一个tag数组,(约等于线段树里的懒标记),对这个区间进行修改只需要将tag+x即可,节省了时间。
下一个问题,对于区间并未完全覆盖的情况怎么办?
也就是说,如果询问范围(l,r),扣除整块之后还有一些边角料,怎么办?
对于修改中不在整块内的位置,当然,本来就是暴力优化来的,从哪里来到哪里去,暴力进行修改。这样一次修改的复杂度为 O(B+n/B)。 查询时加上整个块的 tag 就好了。
3.复杂度分析
下一个问题随之产生:B取什么值?
注意到高中数学的均值不等式, B+n/B≥2√n,B=√n 时取等。 所以令 B=√n,复杂度就是 O(n√n)。 这也是为什么叫做根号类算法。
4.算法分析
优点
1.只涉及到了分块和打标记的思想,没有其他复杂的操作,暴力也不需要满足可合并等性质(线段树等需要)。
2.比线段树更低的思维难度解决线段树类算法无法解决的问题。
缺点
时间复杂度稍差(但也没差到哪去)
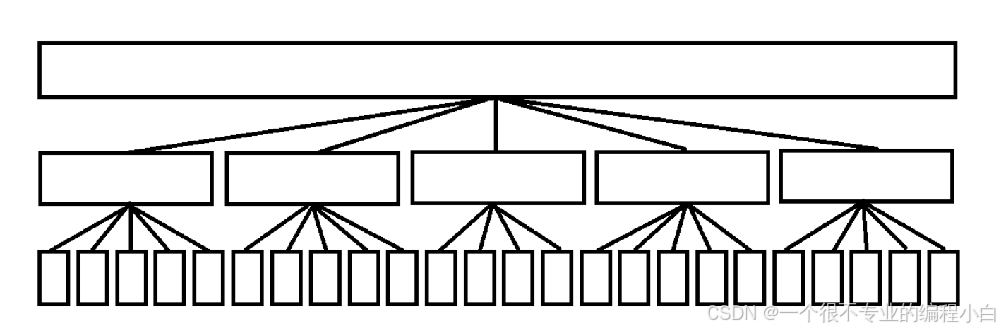
本质
分块的本质是一个度数是 √n,只有三层的树。
图如下:
5.例题讲解
(1)P2801 教主的魔法
格式化题面
n 个数,q 次操作,区间加或者区间询问某个数的排名。 n≤10^6,q≤3000。
思路
考虑分块。还是先设 B 个分一块,那么区间加这个操作和上一题一样很容易解决。 但询问怎么办? 注意到我们分块之后区间的排名可以分别在某个块中求排名最后再加起来,而散块可以直接暴力,整块则需排序后二分,所以不难想到可以维护每个块排序的结果。 由于区间修改时整块的排序结果不变,只需要在散块暴力修改后重构一下(重新排序)就好了。
来分析一下复杂度,一次修改 O(Blogn+n/B),查询 O(B+nlogn/b),B 取 √n 复杂度就是 O(n√nlogn) 的。
完事了吗? 完事了可以通过,但复杂度不够优秀。
注意到我们修改是区间加,也就是在重构散块时实际上左右都是有序的。 于是不难想到归并一下修改的复杂度就变成了 O(B+n/B)。 然而查询还是 O(B+nlogn/B) 的,这样还是 O(n√nlogn)? 可以调块长啊
分块的核心其实是平衡整块和散块的时间复杂度。 现在散块可以暴力,而整块需要二分,也就是整块会多出一个 log 。 所以将块长设为 B=√nlogn ,复杂度就是 O(n√nlogn) 的。 其实这也是对 B+nlogn/B 使用均值不等式的结果
也就是说,让散块短一点,整块多一点
AC代码
#include<bits/stdc++.h>
#define N 1001001
using namespace std;
long long n,q,a[N],b[N],B,p[N],num[N],ls[N],rs[N];
char s[N];
void reset( long long x)
{
for( long long i=ls[x];i<=rs[x];i++)
b[i]=a[i];
sort(b+ls[x],b+rs[x]+1);
return;
}
long long calc(long long l,long long r, long long x)
{
long long ans=0,tmp=r,mid;
while(l<=r)
{
mid=l+r>>1;
if(b[mid]>=x)
{
ans=mid;
r=mid-1;
}
else
l=mid+1;
}
return ans?tmp-ans+1:0;
}
void add( long long l, long long r, long long x)
{
if(p[l]==p[r])
{
for( long long i=l;i<=r;i++)
a[i]+=x;
reset(p[l]);
return;
}
for( long long i=p[l]+1;i<p[r];i++)
num[i]+=x;
for( long long i=l;i<=rs[p[l]];i++)
a[i]+=x;
for( long long i=ls[p[r]];i<=r;i++)
a[i]+=x;
reset(p[r]);
return;
}
long long query( long long l, long long r, long long x)
{
long long cnt=0;
if(p[l]==p[r])
{
for( long long i=l;i<=r;i++)
if(a[i]+num[p[i]]>=x)
cnt++;
return cnt;
}
for( long long i=p[l]+1;i<p[r];i++)
cnt+=calc(ls[i],rs[i],x-num[i]);
for( long long i=l;i<=rs[p[l]];i++)
if(a[i]+num[p[i]]>=x)
cnt++;
for( long long i=ls[p[r]];i<=r;i++)
if(a[i]+num[p[i]]>=x)
cnt++;
return cnt;
}
int main()
{
ios::sync_with_stdio(false);
cin>>n>>q;
B=4000;
for( long long i=1;i<=n;i++)
{
cin>>a[i];
p[i]=(i-1)/B+1;
if(p[i]!=p[i-1])
ls[p[i]]=i,rs[p[i-1]]=i-1;
}
rs[p[n]]=n;
for( long long i=1;i<=p[n];i++)
reset(i);
long long x,y,z;
for( long long i=1;i<=q;i++)
{
cin>>s>>x>>y>>z;
if(s[0]=='M')
add(x,y,z);
else
cout<<query(x,y,z)<<endl;
}
}(2)P4135 作诗
思路
还是分块,考虑先预处理出连续的整块的答案,每次询问时将散块插入进去计算。 具体而言,令 f[i][j]表示 从第 i 块 到第 j 块有多少个数出现偶数次, g[i][j] 表示前 i 块中 j 的出现次数。这两个都可以在 O(n√n) 的时间内求出。 然后每次查询时先将答案设为中间一段连续整块的答案。然后检查周围散块,修正他们对答案的贡献。最终就可以得到结果。 时空复杂度都是 O(n√n) 的。
AC代码
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+90,S=1e3+90;
int l[N],r[N],pos[N],len,num;
int a[N],n,m,c,las;
int cnt[S][N],ans[S][S];
int t[N];
int query(int ll,int rr){
int posl=pos[ll],posr=pos[rr];
if(posl+1>=posr)
{
int s=0;
for(int i=ll;i<=rr;i++)
{
t[a[i]]++;
if(!(t[a[i]]&1)) s++;
else if(t[a[i]]>=3) s--;
}
for(int i=ll;i<=rr;i++) t[a[i]]--;
return s;
}
else
{
int s=ans[posl+1][posr-1];
for(int i=ll;i<=r[posl];i++)
{
t[a[i]]++;
int temp=cnt[posr-1][a[i]]-cnt[posl][a[i]];
if(!((t[a[i]]+temp)&1)) s++;
else if(t[a[i]]+temp>=3) s--;
}
for(int i=l[posr];i<=rr;i++)
{
t[a[i]]++;
int temp=cnt[posr-1][a[i]]-cnt[posl][a[i]];
if(!((t[a[i]]+temp)&1)) s++;
else if(t[a[i]]+temp>=3) s--;
}
for(int i=ll;i<=r[posl];i++) t[a[i]]--;
for(int i=l[posr];i<=rr;i++) t[a[i]]--;
return s;
}
}
int main(){
scanf("%d%d%d",&n,&c,&m);
len=sqrt(n);
num=ceil(n*1.0/len);
for(int i=1;i<=num;i++)
{
l[i]=(i-1)*len+1;
r[i]=i*len;
}
r[num]=n;
for(int i=1;i<=n;i++)
{
scanf("%d",&a[i]);
pos[i]=(i-1)/len+1;
cnt[pos[i]][a[i]]++;
}
for(int i=1;i<=num;i++)
for(int j=0;j<=c;j++)
cnt[i][j]+=cnt[i-1][j];
for(int i=1;i<=num;i++)
{
for(int j=i;j<=num;j++)
{
ans[i][j]=ans[i][j-1];
for(int k=l[j];k<=r[j];k++)
{
t[a[k]]++;
if(!(t[a[k]]&1)) ans[i][j]++;
else if(t[a[k]]>=3) ans[i][j]--;
}
}
memset(t,0,sizeof t);
}
while(m--)
{
int l,r;
scanf("%d%d",&l,&r);
int L=(l+las)%n+1,R=(r+las)%n+1;
if(L>R) swap(L,R);
int as=query(L,R);
printf("%d\n",as);
las=as;
}
return 0;
}(3)P4168 [Violet] 蒲公英
格式化题面
n 个数,m 次询问区间众数,强制在线。 n≤40000,m≤50000, 值域 10^9。
思路
大致想法和上一题差不多,依旧是预处理一段连续的块的众数,然后将散块插入进去。 大概做法是找出中间整块的众数后判断两边散块内的数在加上两边散块内的出现次数后是否能超过原众数。 最终复杂度是 O((n+m)√n) 的。
AC代码
#include<bits/stdc++.h>
using namespace std;
#define R register int
#define AC 40100
#define ac 210
#define D printf("line in %d\n",__LINE__);
int block,n,m,answer,tot;
int s[AC];
struct abc{
int num,w,x;
}b[AC];
int sum[ac][AC];
int ans[ac][ac];
int belong[AC];
int color[AC];
inline int read()
{
int x=0;char c=getchar();
while(c>'9' || c<'0') c=getchar();
while(c>='0' && c<='9') x=x*10+c-'0',c=getchar();
return x;
}
bool cmp1(abc a,abc b)
{
return a.w < b.w;
}
bool cmp2(abc a,abc b)
{
return a.num < b.num;
}
void search(int x,int y)
{
int l=x/block + 1,r=y/block - 1;
if(r - l <= 1)
{
answer=0;
for(R i=x;i<=y;i++)
if((++color[b[i].x] > color[answer]) || (color[b[i].x] == color[answer] && b[i].x < answer)) answer=b[i].x;
for(R i=x;i<=y;i++)
--color[b[i].x];
printf("%d\n",s[answer]);
return ;
}
else
{
int ll=l * block - 1,rr=(r+1) * block;
answer=ans[l][r];
for(R i=x;i<=ll;i++)
{
++color[b[i].x];
if(color[b[i].x] + sum[r][b[i].x] - sum[l-1][b[i].x] > color[answer] + sum[r][answer] - sum[l-1][answer]) answer=b[i].x;
else if(color[b[i].x] + sum[r][b[i].x] - sum[l-1][b[i].x] == color[answer] + sum[r][answer] - sum[l-1][answer] && b[i].x < answer) answer=b[i].x;//编号小也要优先,因为一行写不下,为了美观,,,就用else吧,不然就用||了
}
for(R i=rr;i<=y;i++)
{
++color[b[i].x];
if(color[b[i].x] + sum[r][b[i].x] - sum[l-1][b[i].x] > color[answer] + sum[r][answer] - sum[l-1][answer]) answer=b[i].x;
else if(color[b[i].x] + sum[r][b[i].x] - sum[l-1][b[i].x] == color[answer] + sum[r][answer] - sum[l-1][answer] && b[i].x < answer) answer=b[i].x;
}
for(R i=x;i<=ll;i++) --color[b[i].x];
for(R i=rr;i<=y;i++) --color[b[i].x];
printf("%d\n",s[answer]);
return ;
}
}
int main()
{
n=read(),m=read();
block=sqrt(n);
for(R i=1;i<=n;i++) b[i].w=read(),b[i].num=i;
sort(b+1,b+n+1,cmp1);
for(R i=1;i<=n;i++)
{
if(b[i].w != b[i-1].w)
{
s[++tot]=b[i].w;
b[i].x=tot;
}
else b[i].x=b[i-1].x;
}
sort(b+1,b+n+1,cmp2);
for(R i=1;i<=n;i++)
{
belong[i]=i/block;
sum[belong[i]][b[i].x]++;
}
for(R i=0;i<=belong[n];i++)
for(R j=1;j<=tot;j++)
sum[i][j]+=sum[i-1][j];
for(R i=0;i<=belong[n];i++)
{
int be=i * block,now=0;
if(!be) be=1;
for(R j=be;j<=n;j++)
{
if((++color[b[j].x] > color[now]) || (color[b[j].x] == color[now] && b[j].x < now)) now=b[j].x;
ans[i][belong[j]]=now;
}
for(R j=be;j<=n;j++) --color[b[j].x];
}
int a,b;
for(R i=1;i<=m;i++)
{
a=(read() + s[answer] -1) % n + 1,b=(read() + s[answer] - 1) % n + 1;
if(a < b) search(a,b);
else search(b,a);
}
return 0;
}普通莫队
插句题外话
为什么叫莫队?
发明人是前国家队队长莫涛。
1.引入
假设有两个区间询问 [l_1,r_1],[l_2,r_2],我们已经得到了 [l_1,r_1] 的答案。 如果我能快速的进行插入、删除,也就是能快速从 [l,r] 移动到 [l,r−1],[l,r+1],[l+1,r],[l−1,r]。 那么我们就能在一系列移动之后从 [l_1,r_1] 转移到 [l_2,r_2]。 但这样暴力移动的话复杂度仍然是 O(nm) 的,和暴力没有区别(^_^优化了个寂寞^_^)。 有没有什么解决办法?
2.算法思路
莫队的思想仍然是分块,分块之后用一种特殊的顺序离线处理所有询问,使总移动次数在可接受的范围内。 对询问排序时,对序列分块,然后以询问的左端点所在块为第一关键字,右端点为第二关键字进行排序。 然后在排序后暴力移动左右端点。
3.复杂度分析
来看时间复杂度,我们设块长为 B。 对于左端点,跨越块的移动总复杂度是 O(n) 的。在块内移动每次 O(B),总复杂度为 O(mB)。 对于右端点,当左端点所在块不变时右端点是单调增的,一共 O(n/B) 个块,这样的移动总复杂度是 O(n^2/B) 的。左端点所在块变化只有 O(n/B) 次,这样还是 O(n^2/B)。 平衡一下,B 取 n/√m 时复杂度就是 O(n√m)。
4.例题讲解
(1)P1494 [国家集训队] 小 Z 的袜子
思路
稍微运用一下组合数学的知识,如果区间每种颜色出现次数为 ,那么答案就是
。 相当于区间数颜色,每次移动时把该颜色原来的贡献减去,修改后再加上新贡献就好。
AC代码
#include<bits/stdc++.h>
#define N 101001
#define ll long long
using namespace std;
int n,m,a[N],l,r,num[N],p[N],B;
struct node
{
int l,r,data;
ll res;
}q[N];
bool cmp(node x,node y)
{
if(p[x.l]==p[y.l])
return x.r<y.r;
return p[x.l]<p[y.l];
}
bool _cmp(node x,node y)
{
return x.data<y.data;
}
ll val;
void add(int pos)
{
val-=1ll*num[a[pos]]*(num[a[pos]]-1);
num[a[pos]]++;
val+=1ll*num[a[pos]]*(num[a[pos]]-1);
return;
}
void del(int pos)
{
val-=1ll*num[a[pos]]*(num[a[pos]]-1);
num[a[pos]]--;
val+=1ll*num[a[pos]]*(num[a[pos]]-1);
return;
}
template<typename T>
inline void read(T &x)
{
x=0;char c = getchar();int s = 1;
while(c < '0' || c > '9') {if(c == '-') s = -1;c = getchar();}
while(c >= '0' && c <= '9') {x = x*10 + c -'0';c = getchar();}
x*=s;
}
template<typename T>
inline void write(T x)
{
if(x<0)
putchar('-'),x=-x;
if(x>9)
write(x/10);
putchar(x%10+'0');
return;
}
int main(){
read(n),read(m);
B=225;
for(int i=1;i<=n;i++)
p[i]=(i-1)/B+1;
for(int i=1;i<=n;i++)read(a[i]);
for(int i=1;i<=m;i++)
{
read(q[i].l);read(q[i].r);
q[i].data=i;
}
sort(q+1,q+m+1,cmp);
int l=1,r=0;
for(int i=1;i<=m;i++)
{
while(l>q[i].l)
add(--l);
while(r<q[i].r)
add(++r);
while(l<q[i].l)
del(l++);
while(r>q[i].r)
del(r--);
q[i].res=val;
}
sort(q+1,q+m+1,_cmp);
for(int i=1;i<=m;i++)
{
ll a=q[i].res,b=1ll*(q[i].r-q[i].l+1)*(q[i].r-q[i].l);
if(!a)
{
puts("0/1");
continue;
}
ll d=__gcd(a,b);
a/=d,b/=d;
printf("%lld/%lld\n",a,b);
}
return 0;
}
(2)P4396 [AHOI2013] 作业
格式化题面
n 个数,m 次区间询问,查询 [l,r] 区间中 在 [a,b] 区间内的数值有多少个。 n,m,值域≤10^5。
思路
考虑使用莫队维护区间内出现过的颜色。 移动时维护区间内有无这个颜色时简单的,问题是怎么求 [a,b] 区间。 使用树状数组等数据结构的话会使复杂度多一个 log,复杂度太高。 我们注意到莫队之后问题其实变成了一个有 O(n√m) 次单点修改,m 次区间查询的数据结构题,而值域分块正好可以 O(1) 修改,O(√n) 查询前缀和。
值域分块,顾名思义就是在值域上进行分块。 考虑维护整个块的和,那么单点修改只需要改自己这个点已经所在块的和,是 O(1) 的。 查询前缀和我们就分成整块和散块正常查询就好了,O(√n)。 于是这道题就以 O(n√m+m√n) 的复杂度解决了。
AC代码
#include <bits/stdc++.h>
using namespace std ;
const int N = 200010 ;
void debug(int *tp, int minn, int maxn, char c){
for (int i = minn ; i <= maxn ; ++ i)
cout << tp[i] << " " ; cout << c ;
}
int B ;
int V ;
int n, m,bl[N],blv[N],res[N],ans[N],sum[N],sumr[N],sump[N],base[N] ;
struct query{
int id ;
int l, r ;
int a, b ;
}q[N] ;
inline bool comp(query a, query b){
return (bl[a.l] ^ bl[b.l]) ? bl[a.l] < bl[b.l] :
((bl[a.l] & 1) ? a.r < b.r : a.r > b.r) ;
}
inline void del(int p){
sump[base[p]] -- ;
sumr[blv[base[p]]] -- ;
if (sump[base[p]] <= 0) -- sum[blv[base[p]]] ;
}
inline void add(int p){
sump[base[p]] ++ ;
sumr[blv[base[p]]] ++ ;
if (sump[base[p]] <= 1) ++ sum[blv[base[p]]] ;
}
inline int get_ans(int l, int r){
int ret = 0 ;
r = min(r, V) ;
if (l > V) return 0 ;
int nl = blv[l] + 1 ;
int nr = blv[r] - 1 ;
if (blv[l] == blv[r]){
for (int i = l ; i <= r ; ++ i)
ret += (bool)sump[i] ; return ret ;
}
for (int i = nl ; i <= nr ; ++ i) ret += sum[i] ;
for (int i = l ; blv[i] == blv[l] && l <= V ; ++ i) ret += (bool)sump[i] ;
for (int i = r ; blv[i] == blv[r] && r >= 0 ; -- i) ret += (bool)sump[i] ;
return ret ;
}
inline int get_res(int l, int r){
int ret = 0 ;
r = min(r, V) ;
if (l > V) return 0 ;
int nl = blv[l] + 1 ;
int nr = blv[r] - 1 ;
if (blv[l] == blv[r]){
for (int i = l ; i <= r ; ++ i)
ret += sump[i] ; return ret ;
}
for (int i = nl ; i <= nr ; ++ i) ret += sumr[i] ;
for (int i = l ; blv[i] == blv[l] && l <= V ; ++ i) ret += sump[i] ;
for (int i = r ; blv[i] == blv[r] && r >= 0 ; -- i) ret += sump[i] ;
return ret ;
}
int main(){
ios::sync_with_stdio(false);
cin.tie(0);cout.tie(0);
cin >> n >> m ;
B = 1.0 * n / sqrt(m) + 1 ;
for (int i = 1 ; i <= n ; ++ i)
cin>>base[i], V = max(V, base[i]), bl[i] = i / B ;
for (int i = 1 ; i <= m ; ++ i)
cin>>q[i].l>>q[i].r>>q[i].a>>q[i].b, q[i].id = i ;
sort(q + 1, q + m + 1, comp) ;
int l = 1, r = 0 ; B = sqrt(V) + 1 ;
for (int i = 0 ; i <= V ; ++ i) blv[i] = i / B ;
for (int i = 1 ; i <= m ; ++ i){
int a = q[i].a, b = q[i].b ;
while (l < q[i].l) del(l ++) ;
while (l > q[i].l) add(-- l) ;
while (r < q[i].r) add(++ r) ;
while (r > q[i].r) del(r --) ;
res[q[i].id] = get_res(a, b) ;
ans[q[i].id] = get_ans(a, b) ;
}
for (int i = 1 ; i <= m ; ++ i)
cout<<res[i]<<" "<<ans[i]<<endl;
return 0 ;
}(3)CF617 EXOR and Favorite Number
思路
这就是一道很裸的莫队
AC代码
#include <bits/stdc++.h>
using namespace std;
const int MAX = 1e6 + 7;
#define int long long
int cnt[MAX << 1], num[MAX];
int block[MAX];
int N, M, K;
int sum;
struct query
{
int L, R;
int id;
} q[MAX];
bool cmp(query a, query b)
{
if (block[a.L] != block[b.L])
{
return a.L < b.L;
}
return (block[a.L] & 2 ? a.R < b.R : a.R > b.R);
}
int xornum[MAX << 1], ans[MAX << 1];
void ins(int p)
{
sum += cnt[xornum[p] ^ K];
cnt[xornum[p]]++;
}
void del(int p)
{
cnt[xornum[p]]--;
sum -= cnt[xornum[p] ^ K];
}
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0);cout.tie(0);
cin >> N >> M >> K;
int lenb = sqrt(N);
for (int i = 1; i <= N; i++)
{
cin >> num[i];
block[i] = (i - 1) / lenb + 1;
xornum[i] = xornum[i - 1] ^ num[i];
}
for (int i = 1; i <= M; i++)
{
cin >> q[i].L >> q[i].R;
q[i].L--;
q[i].id = i;
}
sort(q + 1, q + 1 + M, cmp);
int L = 1, R = 0;
for (int i = 1; i <= M; i++)
{
while (q[i].L < L)
{
L--;
ins(L);
}
while (q[i].R > R)
{
R++;
ins(R);
}
while (q[i].L > L)
{
del(L);
L++;
}
while (q[i].R < R)
{
del(R);
R--;
}
ans[q[i].id] = sum;
}
for (int i = 1; i <= M; i++)
{
cout << ans[i] << endl;
}
}带修莫队
1.问题
当有修改操作时,普通的莫队将失效,因为要对询问进行排序,可能会出现先询问再修改的情况。
2.优化方案
当有修改操作时,普通的莫队将失效,因为要对询问进行排序,可能会出现先询问再修改的情况。 其实我们考虑普通莫队,本质上是将区间 [l,r] 看成一个点 (l,r),然后在平面坐标系上进行移动,
两点之间的哈夫曼距离就是从一个状态到另一个状态所需要的最小挪动
那么对于所有的查询,最快的办法就是在坐标系上找到哈夫曼最小生成树
(其实没有必要会这个因为太麻烦了)
你也许会说:“我不会啊!”
这完全没有关系,因为
我也不会
。 那么我们再加一维时间轴 t,再空间直角坐标系上进行移动不就行了? 也就是把排序方法变成先按 l 所在块排,再按 r 所在块排,再按 t 排。
在时间轴移动时要做的就是增添/撤销某个修改。 假设块长是 B ,经过和普通莫队类似的分析可以得出复杂度为 O(mB+n^2/B+n^3/B^2),令 B=n/√(3&m) 可得复杂度为 O(nm^2/3) 。
例题
P1903 [国家集训队] 数颜色 / 维护队列
思路
带修莫队直接上就行了。 太水了,太水了(这道题有点卡常)
AC代码
#include<bits/stdc++.h>
using namespace std;
const int N=500005;
int col[N],n,m,sum[1000005],be[N];
int ANS,qnum,cnum,ans[N];
struct qs{
int l,r,t,id;
}q[N];
struct cs{
int x,i;
}c[N];
inline bool cmp(qs x,qs y)
{
if(be[x.l]!=be[y.l])return x.l<y.l;
if(be[x.r]!=be[y.r])return x.r<y.r;
return x.t<y.t;
}
inline void upd1(int x)
{
if(!sum[col[x]])
++ANS;
++sum[col[x]];
}
inline void upd2(int x)
{
--sum[col[x]];
if(!sum[col[x]])
--ANS;
}
int l,r,now;
inline void change(int x)
{
if(c[x].i<=r && c[x].i>=l)
{
--sum[col[c[x].i]];
if(!sum[col[c[x].i]])
--ANS;
if(!sum[c[x].x])
++ANS;
++sum[c[x].x];
}
swap(c[x].x,col[c[x].i]);
}
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);cout.tie(0);
cin>>n>>m;
int xx=pow(n,2.0/3.0);
char opt;
for(int i=1;i<=n;i++)
{
cin>>col[i];
be[i]=i/xx+1;
}
for(int i=1;i<=m;i++)
{
cin>>opt;
if(opt=='Q')
{
++qnum;
cin>>q[qnum].l>>q[qnum].r;
q[qnum].t=cnum;
q[qnum].id=qnum;
}
else
{
++cnum;
cin>>c[cnum].i>>c[cnum].x;
}
}
sort(q+1,q+qnum+1,cmp);
l=r=ANS=now=0;
for(int i=1;i<=qnum;i++)
{
while(l<q[i].l)upd2(l++);
while(l>q[i].l)upd1(--l);
while(r>q[i].r)upd2(r--);
while(r<q[i].r)upd1(++r);
while(now<q[i].t)change(++now);
while(now>q[i].t)change(now--);
ans[q[i].id]=ANS;
}
for(int i=1;i<=qnum;i++)
cout<<ans[i]<<endl;
return 0;
}回滚莫队
1.问题
对于有一些题目,可能加入一个位置和删除一个位置的代价是不同的。比如说要求维护某种颜色在区间中最后一次出现的位置,这样加入很容易,但删除就会很困难。也就是说,对于加入删除不对等的操作(出现次数第几……)应该怎么办
而回滚莫队就是为了解决这种题目而诞生的,他的特点是可以做到只加入不删除,或者只删除不加入。
2.优化方案
还是像正常莫队一样对所有询问排序,我们现在假如要只加入不删除。 那么在处理左端点所在块相同的询问时,我们可以将求解的区间左端点设为该块的最右端,然后求解的区间右端点正常移动(因为右端点只会向右移动)。 然后对于左端点,我们每个询问都单独处理,从该块的最右端移动至该询问处,然后回滚。 回滚的方法是“撤销”修改。不能删除不代表不能撤销。可以记录一个栈,里面存储做了哪些修改,依次撤销即可。
例题
(1)P5906 【模板】回滚莫队&不删除莫队
格式化题面
区间查询相同颜色距离最大值。 n,m,值域≤2×10^5。
思路
很明显易加入不易删除。 所以直接不删除莫队就好了。
AC代码
#include<bits/stdc++.h>
#define eps 1e-10
#define re register
#define N 2001001
#define MAX 2001
#define inf 1e18
using namespace std;
typedef long long ll;
typedef double db;
inline void read(re ll &ret)
{
ret=0;re ll pd=0;re char c=getchar();
while(!isdigit(c)){pd|=c=='-';c=getchar();}
while(isdigit(c)){ret=(ret<<1)+(ret<<3)+(c^48);c=getchar();}
ret=pd?-ret:ret;
}
ll n,q,a[N],len,p[N],l,r,now,val[N],num[N],b[N],m,las,fir[N],ed[N],hy[N];
struct query
{
ll l,r,ans,data;
inline friend bool operator <(re query x,re query y)
{
if(p[x.l]==p[y.l])
return x.r<y.r;
return p[x.l]<p[y.l];
}
}que[N];
inline bool cmp(re query x,re query y)
{
return x.data<y.data;
}
inline ll calc(re ll l,re ll r)
{
for(re int i=l;i<=r;i++)
hy[a[i]]=0;
re ll ret=0;
for(re int i=l;i<=r;i++)
{
if(!hy[a[i]])
hy[a[i]]=i;
ret=max(ret,i-hy[a[i]]);
}
return ret;
}
int main()
{
read(n);
len=sqrt(n)+1;
for(re int i=1;i<=n;i++)
read(a[i]),p[i]=(i-1)/len+1,b[i]=a[i];
sort(b+1,b+n+1);
m=unique(b+1,b+n+1)-b-1;
for(re int i=1;i<=n;i++)
{
re ll tmp=lower_bound(b+1,b+m+1,a[i])-b;
num[tmp]=a[i];
a[i]=tmp;
}
read(q);
for(re int i=1;i<=q;i++)
{
read(que[i].l);
read(que[i].r);
que[i].ans=0;
que[i].data=i;
}
sort(que+1,que+q+1);
a[0]=-1;
for(re int i=1,block=1;i<=q;block++)
{
re ll rr=min(len*block,n);
l=rr;
r=l-1;
now=0;
for(re int j=1;j<=200000;j++)
fir[j]=0,ed[j]=0;
for(;p[que[i].l]==block;i++)
{
if(p[que[i].r]==block)
{
que[i].ans=calc(que[i].l,que[i].r);
continue;
}
while(r<que[i].r)
{
r++;
ed[a[r]]=r;
if(!fir[a[r]])
fir[a[r]]=r;
now=max(now,r-fir[a[r]]);
}
re ll tmp=now;
while(l>que[i].l)
{
l--;
if(!ed[a[l]])
ed[a[l]]=l;
now=max(now,ed[a[l]]-l);
}
que[i].ans=now;
while(l<rr)
{
if(ed[a[l]]==l)
ed[a[l]]=0;
l++;
}
now=tmp;
}
}
sort(que+1,que+q+1,cmp);
for(re int i=1;i<=q;i++)
printf("%lld\n",que[i].ans);
return 0;
}
(2)歴史の研究
AC代码
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N = 100005;
int n,Q;
LL lsh[N],lshtot;
int tot[N];
int belong[N];
LL ans[N];
struct query
{
int l,r,id;
bool operator < (const query &px) const{
if(belong[l] != belong[px.l])
return belong[l] < belong[px.l];
return r < px.r;
}
}q[N];
struct node
{
int x,id;
}p[N];
void Put1(LL x)
{
if(x > 9) Put1(x/10);
putchar(x%10^48);
}
void Put(LL x)
{
if(x < 0) putchar('-'),x = -x;
Put1(x);
}
template <typename T>T Max(T x,T y){return x > y ? x : y;}
template <typename T>T Min(T x,T y){return x < y ? x : y;}
template <typename T>T Abs(T x){return x < 0 ? -x : x;}
bool cmp1(node x,node y)
{
return x.x < y.x;
}
bool cmp2(node x,node y)
{
return x.id < y.id;
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);cout.tie(0);
cin>>n>>Q;
int sq = sqrt(n);
for(int i = 1;i <= n;++ i)
{
cin>>p[i].x;
p[i].id = i;
belong[i] = (i-1) / sq + 1;
}
sort(p+1,p+n+1,cmp1);
for(int i = 1;i <= n;++ i)
{
if(p[i].x != lsh[lshtot])
lsh[++lshtot] = p[i].x;
p[i].x = lshtot;
}
sort(p+1,p+n+1,cmp2);
for(int i = 1;i <= Q;++ i)
{
cin>>q[i].l;
cin>>q[i].r;
q[i].id = i;
}
sort(q+1,q+Q+1);
int l,r = 0;
LL now = 0,lst = 0;
for(int i = 1;i <= Q;++ i)
{
l = sq * belong[q[i].l];
if(belong[q[i].l] > belong[q[i-1].l])
{
for(int j = 1;j <= lshtot;++ j)
tot[j] = 0;
r = l - 1;
lst = now = 0;
}
now = lst;
while(r < q[i].r)
{
r++;
tot[p[r].x]++;
now = Max(now,tot[p[r].x] * lsh[p[r].x]);
}
while(r > q[i].r)
{
tot[p[r].x]--;
r--;
}
lst = now;
while(l > q[i].l)
{
l--;
tot[p[l].x]++;
now = Max(now,tot[p[l].x] * lsh[p[l].x]);
}
ans[q[i].id] = now;
for(int j = sq * belong[q[i].l]-1;j >= l;-- j)
tot[p[j].x]--;
}
for(int i = 1;i <= Q;++ i)
{
Put(ans[i]);
putchar('\n');
}
return 0;
}树上莫队
1.问题
如果是树上的问题,比如询问是树上一条路径,该如何用莫队解决?
2.优化方案
由于莫队只能解决线性问题,所以我们把树压缩成一个序列。 常用的方法是用括号序,也就是欧拉序,在括号序上跑莫队。 括号序的构建方法是 dfs一棵树,进入节点 x 时加入 x ,退出节点 x 时也加入 x,最终获得一个长为 2n 的序列。
处理 x 到 y 的路径时,假设 x 在 y 前边,我们可以取序列中第一个 x 到第二个 y 这一段区间。可以发现的是在这个区间中只有 x 到 y 路径上的点出现了 1 次,其他的点都会出现 0 或 2 次。于是可以记一个数组 vis ,序列每包含一个 x 就将 vis_x 异或 1 ,这样就能找到路径上的点。 因为可能没有包含 lca ,还需要特判 lca 的情况。最后处理询问时临时加入/删除就好了。
例题
COT2 - Count on a tree II
思路
树上莫队的模板题。
AC代码
#include<bits/stdc++.h>
using namespace std;
const int N=40005,M=100005;
int block;
struct Query{
int id;
int x,y,z;
bool operator <(Query i)const{
return x/block==i.x/block?y<i.y:x<i.x;
}
}q[M];
struct node{
int id,data;
bool operator <(node i)const{
return data<i.data;
}
}a[N];
struct Edge{
int to;
int nxt;
}e[2*N];
int cnt;
int head[N];
int c[N];
int dep[N],f[N][21];
int tp=0;
int s[2*N],st[N],ed[N];
int tot[N];
int ans=0;
int Ans[M];
bool vis[N];
void add(int u,int v){
e[cnt].to=v;
e[cnt].nxt=head[u];
head[u]=cnt++;
return ;
}
void dfs(int x,int fa){
s[++tp]=x;
st[x]=tp;
dep[x]=dep[fa]+1;
f[x][0]=fa;
for(int i=1;i<=20;i++)
f[x][i]=f[f[x][i-1]][i-1];
for(int i=head[x];i!=-1;i=e[i].nxt){
int tmp=e[i].to;
if(tmp==fa)continue;
dfs(tmp,x);
}
s[++tp]=x;
ed[x]=tp;
return ;
}
int lca(int x,int y){
if(dep[x]<dep[y])swap(x,y);
for(int i=20;i>=0;i--)
if(dep[f[x][i]]>=dep[y])
x=f[x][i];
if(x==y)return x;
for(int i=20;i>=0;i--)
if(f[x][i]!=f[y][i]){
x=f[x][i];
y=f[y][i];
}
return f[x][0];
}
void modify(int x){
vis[s[x]]^=1;
if(!vis[s[x]]){
tot[c[s[x]]]--;
if(tot[c[s[x]]]==0)ans--;
}
else{
tot[c[s[x]]]++;
if(tot[c[s[x]]]==1)ans++;
}
return ;
}
int main(){
int n,m;
ios::sync_with_stdio(false);
cin.tie(0);cout.tie(0);
cin>>n>>m;
block=sqrt(2*n);
for(int i=1;i<=n;i++){
a[i].id=i;
cin>>a[i].data;
}
sort(a+1,a+n+1);
int w=0;
for(int i=1;i<=n;i++){
if(a[i].data>a[i-1].data)w++;
c[a[i].id]=w;
}
memset(head,-1,sizeof(head));
for(int i=1;i<n;i++){
int u,v;
cin>>u>>v;
add(u,v);
add(v,u);
}
dfs(1,0);
for(int i=1;i<=m;i++){
int u,v;
cin>>u>>v;
int p=lca(u,v);
q[i].id=i;q[i].z=0;
if(p==u||p==v){
if(st[v]<st[u])swap(u,v);
q[i].x=st[u];q[i].y=st[v];
}
else{
if(ed[v]<st[u])swap(u,v);
q[i].x=ed[u];q[i].y=st[v];q[i].z=p;
}
}
sort(q+1,q+m+1);
int l=1,r=0;
for(int i=1;i<=m;i++){
int id=q[i].id,x=q[i].x,y=q[i].y,z=q[i].z;
while(l<x)modify(l++);
while(l>x)modify(--l);
while(r<y)modify(++r);
while(r>y)modify(r--);
if(z)modify(st[z]);
Ans[id]=ans;
if(z)modify(st[z]);
}
for(int i=1;i<=m;i++)cout<<Ans[i]<<endl;
return 0;
}
莫队二次离线
1.问题
首先莫队,但莫队完的问题仍然棘手,主要困难在于移动时无法计算一个点对整个区间的贡献。
2.优化方案
我们注意到其实莫队之后这个题会变成另一个数据结构问题:有 O(n√m) 次修改,O(m) 次询问的问题。 那么我们可以考虑将修改差分,一个点对区间的贡献变为一个点对两个前缀的差。 我们将这个离线下来,然后从 1 到 n 扫描,维护每一个值对当前的前缀的答案。然后统一处理前缀相同的修改。但这样空间复杂度会变成 O(n√m),还是无法通过。
事实上由于莫队移动时每次移动一段区间,所以我们可以将一个点对一个前缀的贡献改为一个区间对一个前缀的贡献来离线,就能使空间复杂度变为 O(n+m)。 最终时间复杂度为 O(n√m),和普通莫队是一样的。
例题
P4887 【模板】莫队二次离线(第十四分块(前体))
AC代码
#include<cstdio>
#include<algorithm>
#include<vector>
#include<cmath>
using namespace std;
const int N=1e5+10;
const int M=16384+10;
typedef long long ll;
int res[M],siz[M],val[M],tp,a[N], n,m,k,B;
ll ans[N];
struct nod{
int p,tim;
};
vector <nod> mrk1[N],mrk2[N];
struct dat{
int l,r,tim;
};
vector <dat> sp[N],spa[N],spm[N];
struct qry{
int l,r,tim;
}qr[N];ll trs;
inline bool cmp1(const qry& a,const qry& b){
return a.l<b.l;
}
inline bool cmp2(const qry& a,const qry& b){
return (a.r==b.r)?a.l<b.l:a.r<b.r;
}
inline void subsolve(int dl,int dr)
{
if(dl==dr)return;
sort(qr+dl,qr+dr,cmp2);
int l=qr[dl].l,r=qr[dl].r,t=qr[dl].tim,nl=l,nr=r;
mrk1[l-1].push_back((nod){-1,t});
mrk1[r].push_back((nod){1,t});
sp[l-1].push_back((dat){l,r,t});
for(int i=dl+1;i!=dr;i++)
{
l=qr[i].l;r=qr[i].r;t=qr[i].tim;
if(nr!=r)
{
mrk1[nr].push_back((nod){-1,t});
mrk1[r].push_back((nod){1,t});
sp[nl-1].push_back((dat){nr+1,r,t});
}
if(nl!=l){mrk2[nl].push_back((nod){-1,t}),mrk2[l].push_back((nod){1,t});}
if(nl<l)spa[r+1].push_back((dat){nl,l-1,t});
if(l<nl)spm[r+1].push_back((dat){l,nl-1,t});
nl=l;nr=r;
}
}
inline void subsolve2(int dl,int dr)
{for(int i=dl+1;i<dr;i++)ans[qr[i].tim]+=ans[qr[i-1].tim];}
inline void ins(int a){for(int i=1;i<=tp;i++)res[val[i]^a]++;}
int main()
{
for(int i=1;i<16384;i++)siz[i]=siz[i>>1]+(i&1);
scanf("%d%d%d",&n,&m,&k);
for(int i=1;i<=n;i++)scanf("%d",&a[i]);
for(int i=0;i<16384;i++)if(siz[i]==k)val[++tp]=i;
for(int i=1;i<=m;i++)scanf("%d%d",&qr[i].l,&qr[i].r),qr[i].tim=i;
sort(qr+1,qr+m+1,cmp1);
B=n/sqrt(m)+1;
for(int i=B,dl=1,dr=1;;i=min(i+B,n),dl=dr){
while(qr[dr].l<=i&&dr<=m)dr++;
subsolve(dl,dr);
if(i==n)break;
}
for(int i=1;i<=n;i++)
{
trs+=res[a[i]];ins(a[i]);
vector <nod> :: iterator it;
vector <dat> :: iterator it1;
for(it=mrk1[i].begin();it!=mrk1[i].end();it++)ans[it->tim]+=trs*it->p;
for(it1=sp[i].begin();it1!=sp[i].end();it1++)
for(int j=it1->l;j<=it1->r;j++)
ans[it1->tim]-=res[a[j]];
}for(int i=0;i<16384;i++)res[i]=0;
trs=0;
for(int i=n;i>=1;i--)
{
trs+=res[a[i]];
ins(a[i]);
vector <nod> :: iterator it;
vector <dat> :: iterator it1;
for(it=mrk2[i].begin();it!=mrk2[i].end();++it)
ans[it->tim]+=trs*it->p;
for(it1=spa[i].begin();it1!=spa[i].end();++it1)
for(int j=it1->l;j<=it1->r;j++)
ans[it1->tim]+=res[a[j]];
for(it1=spm[i].begin();it1!=spm[i].end();++it1)
for(int j=it1->l;j<=it1->r;j++)
ans[it1->tim]-=res[a[j]];
}
for(int i=B,dl=1,dr=1;;i=min(i+B,n),dl=dr){
while(qr[dr].l<=i&&dr<=m)dr++;
subsolve2(dl,dr);
if(i==n)break;
}
for(int i=1;i<=m;i++)printf("%lld\n",ans[i]);
return 0;
}
总算结束了
这是我的第九篇文章,如有纰漏也请各位大佬指正
辛苦创作不易,还望看官点赞收藏打赏,后续还会更新新的内容。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









