







前言
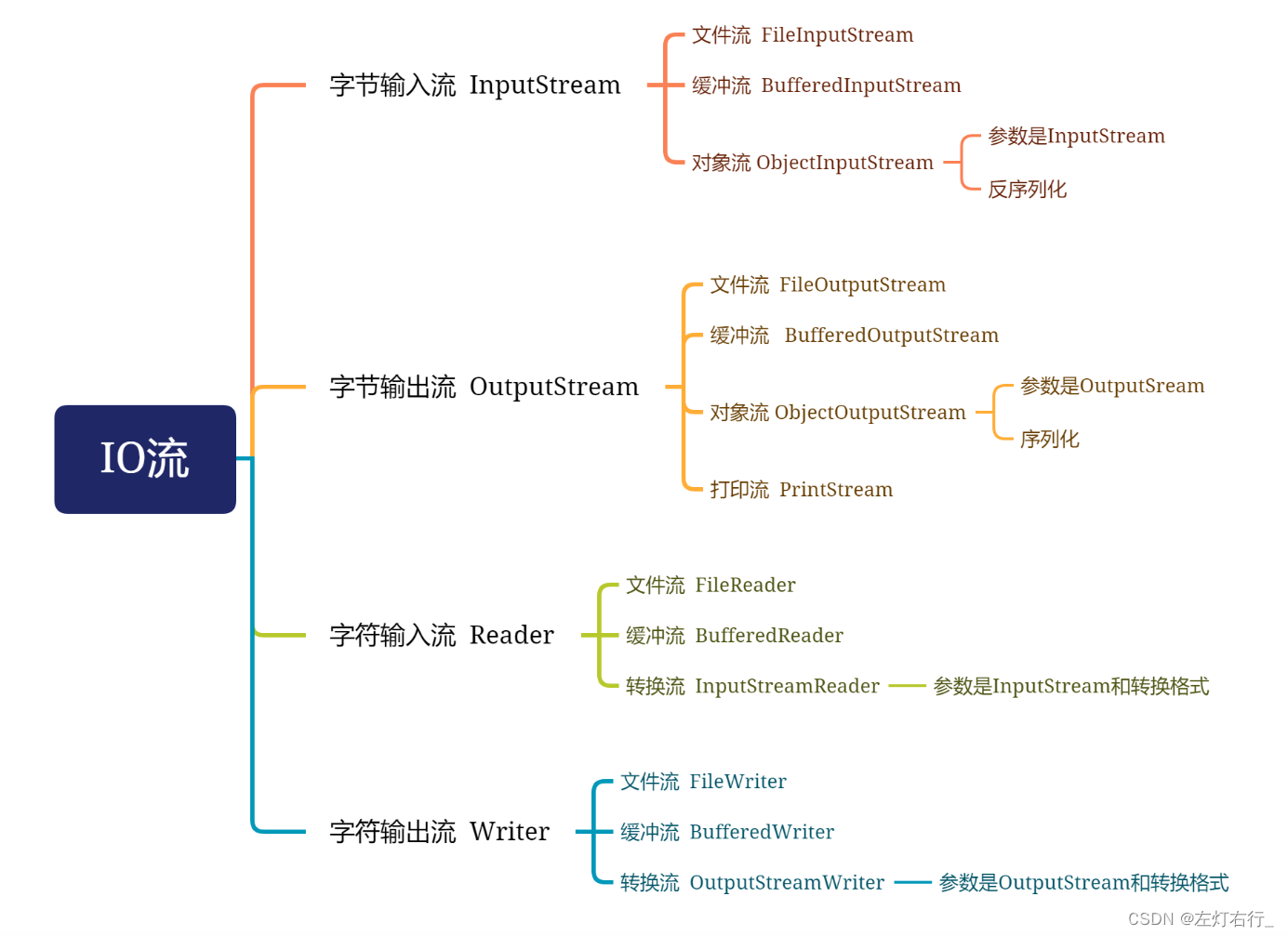
如何区分输入与输出?
这些“输入”“输出”是相对于内存而言的。文件都存放在磁盘上,编译器运行在内存里。即:从文件里读的意思是把数据从磁盘读到内存里,是往内存里输入数据,所以是Input;同样地,往文件里面写数据是把内存中的数据写道磁盘上,是从内存往外输出,所以是Output。
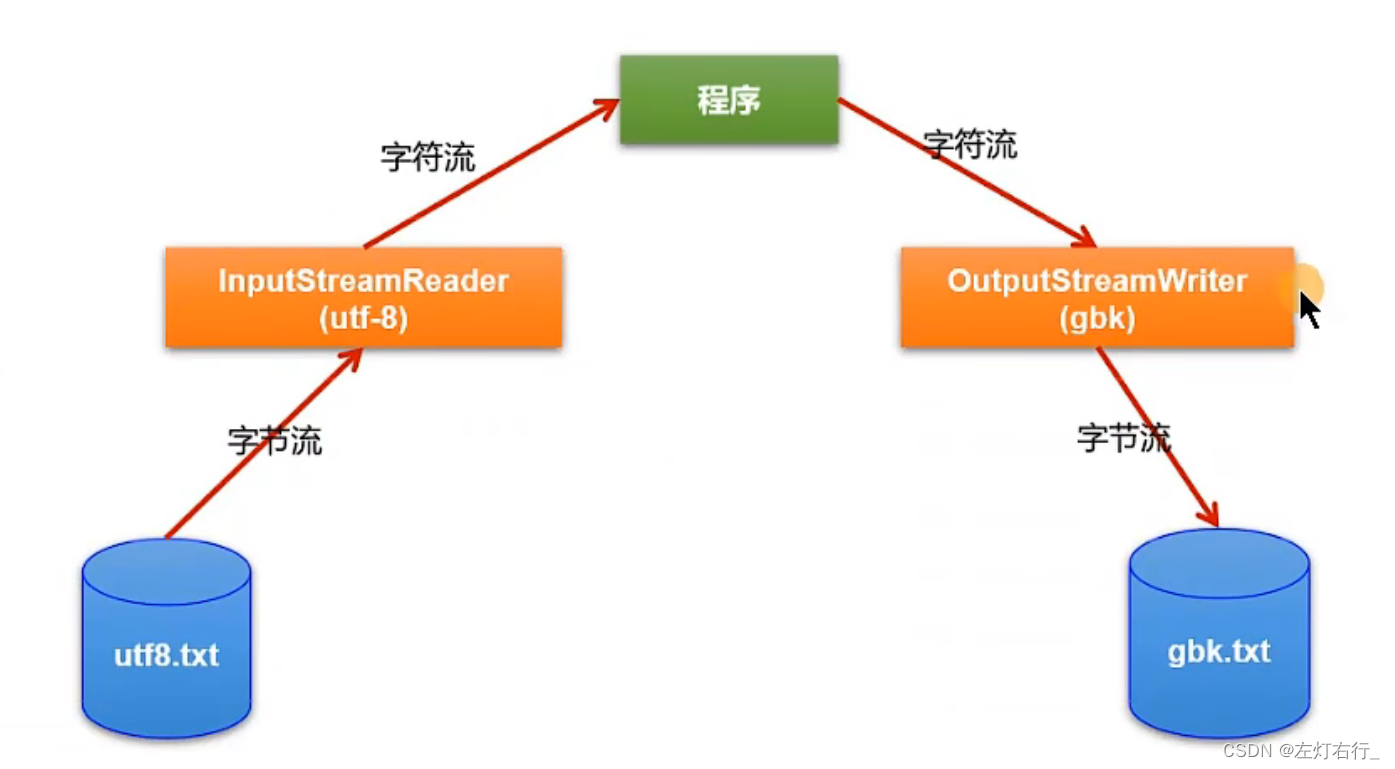
字符流和字节流之间的转换
转换流只能对流的类型转换,不能对流向转换
一、字节输入流InputStream
InputStream是一个接口,他有三个常用实现子类:
1.1 文件字节输入流FileInputStream
- 作用:将文件数据流入内存,可能会抛出
FileNotFoundException异常 - 参数:文件路径(
String类型或File类型)。
InputStream is=new FileInputStream(filePath);
- 常用方法:
| 方法 | 作用 |
|---|---|
| int read() | 读取一个字节的数据,当返回值为-1时表示已经读完 |
| int read( byte[] array) | 读取一个数组长度的数组,返回数组长度,当返回值为-1时表示已经读完 |
| void close() | 关闭流 |
1.2 缓冲字节输入流BufferedInputStream
- 作用:从文件中读取数据的时候,底层会创建一个长度是
8192的byte数组,把数据先读入到这个byte数组中。每次程序要操作数据时,再从byte数组中获取数据进行操作。相比于文件流,缓冲流更加高效,因为缓冲流减少了磁盘IO的次数。 - 特征:
Java缓冲流自身并不具有IO功能,只是在别的流上增加缓冲,以提高程序性能。 - 参数:
InputStream
对于字符输出流,内部使用到了一个
字符缓冲区(字符数组),在进行数据写出时,通常是将需要写出的数据缓存存在了字符数组中,然后在关闭流时(或者缓冲区存满时),一次性将缓冲区的数据写出到目标输出源。
如果需要在流未关闭前(或者缓冲区未满时)强制的将字符缓冲区中的数据写出,可以手动调用flush()强制输出。
InputStream is=new FileInputStream(filePath);
BufferedInputStream bis=new BufferedInputStream(is);
- 常用方法:与文件流用法相同
1.3 对象字节输入流ObjectInputStream
- 应用场景:当需要将自定义类对象写入文件时,需要使用对象流,且自定义的类需要
“序列化”;当需要读取含有自定义类对象的文件数据时,需要“反序列化”。(“序列化”与“反序列化”放在输出字节流再说) - 作用:反序列化读取包含自定义类对象的文件数据
ObjectInputStream ois=new ObjectInputStream(is);
常用方法:
| 方法 | 作用 |
|---|---|
| Object readObject() | 读取一个对象 |
如:
ObjectInputStream ois=new ObjectInputStream(is);
Object obj=ois.readObject();
System.out.println(obj); //控制台打印这个对象
二、字节输出流OutputStream
2.1.文件字节输出流FileOutputStream
- 作用:将内存数据流出到磁盘(
String类型或File类型)。可能会抛出FileNotFoundException异常,当文件不存在时会自动创建,但如果是目录不存在,则会抛出异常。 - 参数:
文件路径和boolean append,false表示不拼接,直接覆盖原数据;true表示拼接,接着原数据往下写。默认是false
File filePath=new File("");
OutputStream os=new FileOutputStream(filePath,true);
- 常用方法:
| 方法 | 作用 |
|---|---|
| void write(byte data) | 往文件里写入一个ASCII码对应的字符,范围0~127 |
| void write(byte[] array) | 往文件里写入一组ASCII码对应的字符 |
| void write(byte[] array,int strat,int len) | 往文件里写入一组ASCII码对应的字符,规定起始位置和写入个数 |
| void close() | 关闭流 |
2.2 缓冲字节输出流BufferedOutputStream
- 作用:从内存读取数据到磁盘时,底层会创建一个长度是
8192的byte数组,让写出的数据先存入到byte数组中。当byte数组存满,或者 显示的调用flush方法的时候,会把该数组中的数据写出到文件。
OutputStream os=new FileOutputStream(filePath,true);
BufferedOutputStream bos=new BufferedOutputStream(os);
- 常用方法:与文件流用法相同
2.3 对象字节输出流ObjectOutputStream
- 应用场景:当需要将自定义类对象写入文件时,需要使用对象流,且自定义的类需要
“序列化”;当需要读取含有自定义类对象的文件数据时,需要“反序列化” - 作用:序列化将内存中包含自定义类对象的数据输出到文件
**【序列化与反序列化】**
序列化 : 自定义类实现
Serializable接口,在类中设置静态常量serialVersionUID = 1L。序列化的结果在文件中是乱码,若要读取,则需要经过反序列化读到控制台查看
反序列化: 能反序列化的前提是先要序列化,不然就报错:invalid stream header
注意事项:
- 能序列化的对象必须实现
Serilizable接口- 成员变量中如果有自定义类,那么这个类也必须实现
Serilizable接口- 反序列化时,类的结构和序列化时的类结构要一致。如果不能保证,则可以添加一个静态常量
serialVersionUID;- 被
transient关键字修饰的成员变量,不参与序列化。读取到控制台时为null
- 常用方法:
| 方法 | 作用 |
|---|---|
| void writeObject() | 写出一个对象 |
如:
ObjectOutputStream oos=new ObjectOutputStream(os);
oos.writeObject(new Person("Savy",24,new School("WUST","一本")));
三、字符输入流 Reader
3.1 文件字符输入流FileReader
- 作用:创建字符输入流时,底层会创建一个长度为
8192的byte数组,先把文件数据存入8192的byte数组中,在调用read方法往内存中读取时,再把8192的byte数组中的数据转换存入char数组中。 - 空间变化:文件 ->
byte数组->char数组 - 常用方法:与字节输入流类似
3.2 缓冲字符输入流BufferedReader
- 作用:从文件中读取数据的时候,底层会创建一个长度是
8192的char数组,把数据先读入到这个char数组中。每次程序要操作数据时,再从char数组中获取数据进行操作。
相比于文件流,缓冲流更加高效,因为缓冲流减少了字节到字符的转换。 - 空间变化:文件 ->
char数组 - 参数:
Reader
| 方法 | 作用 |
|---|---|
| String readLine() | 读取一行数据,没有数据返回null |
3.3 字节->字符 转换流InputStreamReader
- 作用:保证编码和解码一致,参数是
InputStream和要转换的编码形式
InputStream is=new FileInputStream(filePath);
InputStreamReader isr=new InputStreamReader(is,"UTF-8");
如果目标文件的编码形式是UTF-8,则可以正确解码
如果目标文件的编码形式不是UTF-8,则不可以正确解码
四、字符输出流 Writer
4.1 文件字符输出流FileWriter
- 作用:创建字符输出流时,底层会创建一个长度是
8192的byte数组。当该数组存不下数据,或者显示的调用flush方法则会把该数组中的数据写出到目标位置。调用close方法也会把数组中的数据写出到目标位置。 - 常用方法:与 文件字节输出流 类似
- 注意:输入完成后必须关闭流
4.2 缓冲字符输出流BufferedWriter
- 作用:从内存中写出数据的时候,底层会创建一个长度是
8192的char数组,把数据先读入到这个char数组中。当这个char数组存满或显示调用flush方法后,会把数据写入到文件。
相比于文件流,缓冲流更加高效,因为缓冲流减少了字节到字符的转换。
| 方法 | 作用 |
|---|---|
| void newLine() | 换行 |
4.3字符->字节 流OutputStreamWriter
- 作用:保证编码和解码一致,参数是
OutputStream和要转换的编码形式。
OutputStream os=new FileOutputStream(filePath);
OutputStreamWriter osw=new OutputStreamWriter(os,"ACSII");
osw.write("白桃乌龙茶");
ASCII码无法识别中文,目标文件会乱码
常用字符编码:
ASCII编码:只能正确识别ASCII码表中的字符
GBK编码:一个中文是2字节,Eclipse工具默认编码格式是GBK
UTF-8:一个中文是3字节


















 659
659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











