






上篇博客我们讲述了使用Jedis操作Redis,那么如何在Spring中操作Redis?
在Spring中操作Redis
创建项目

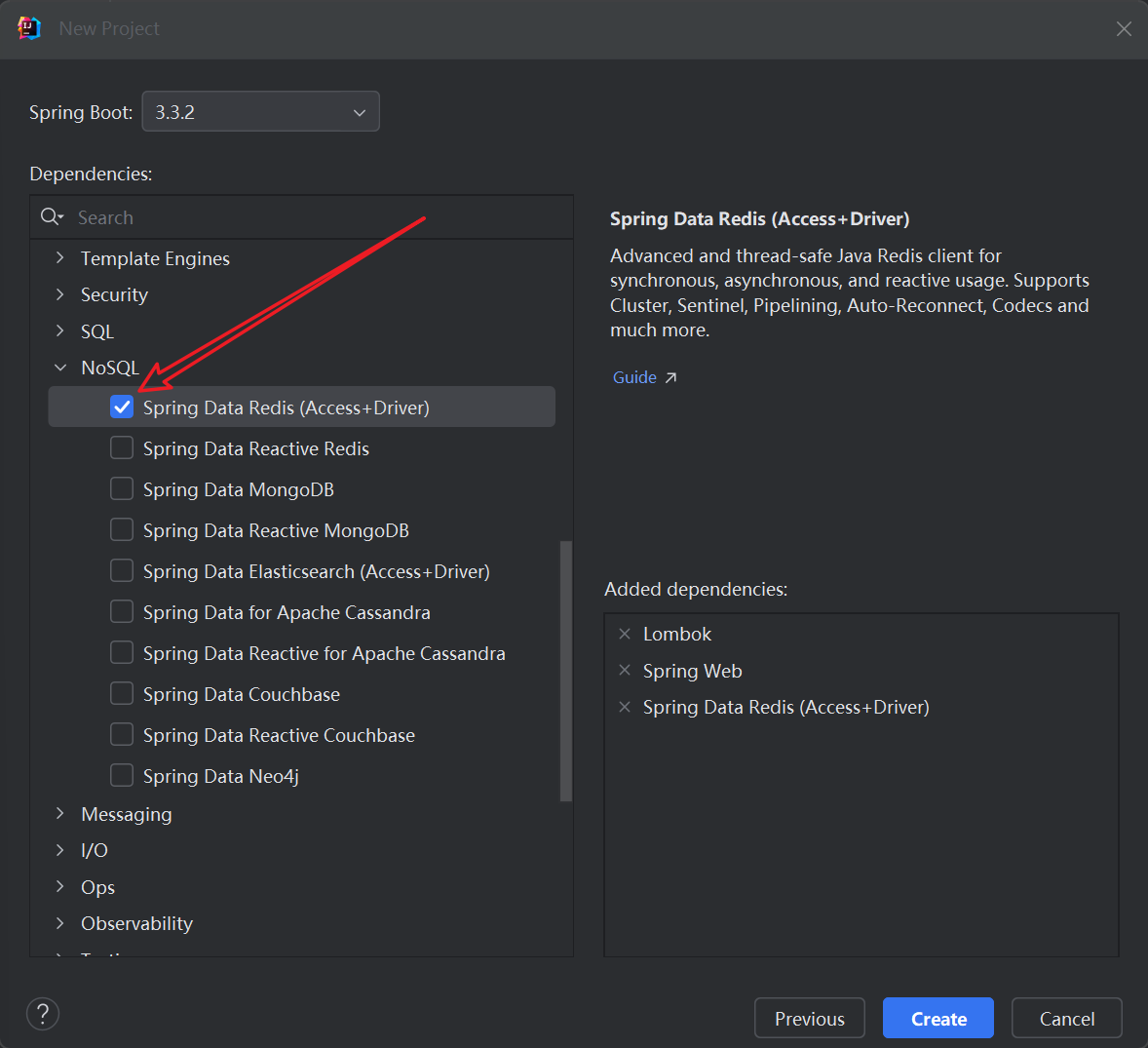
修改配置
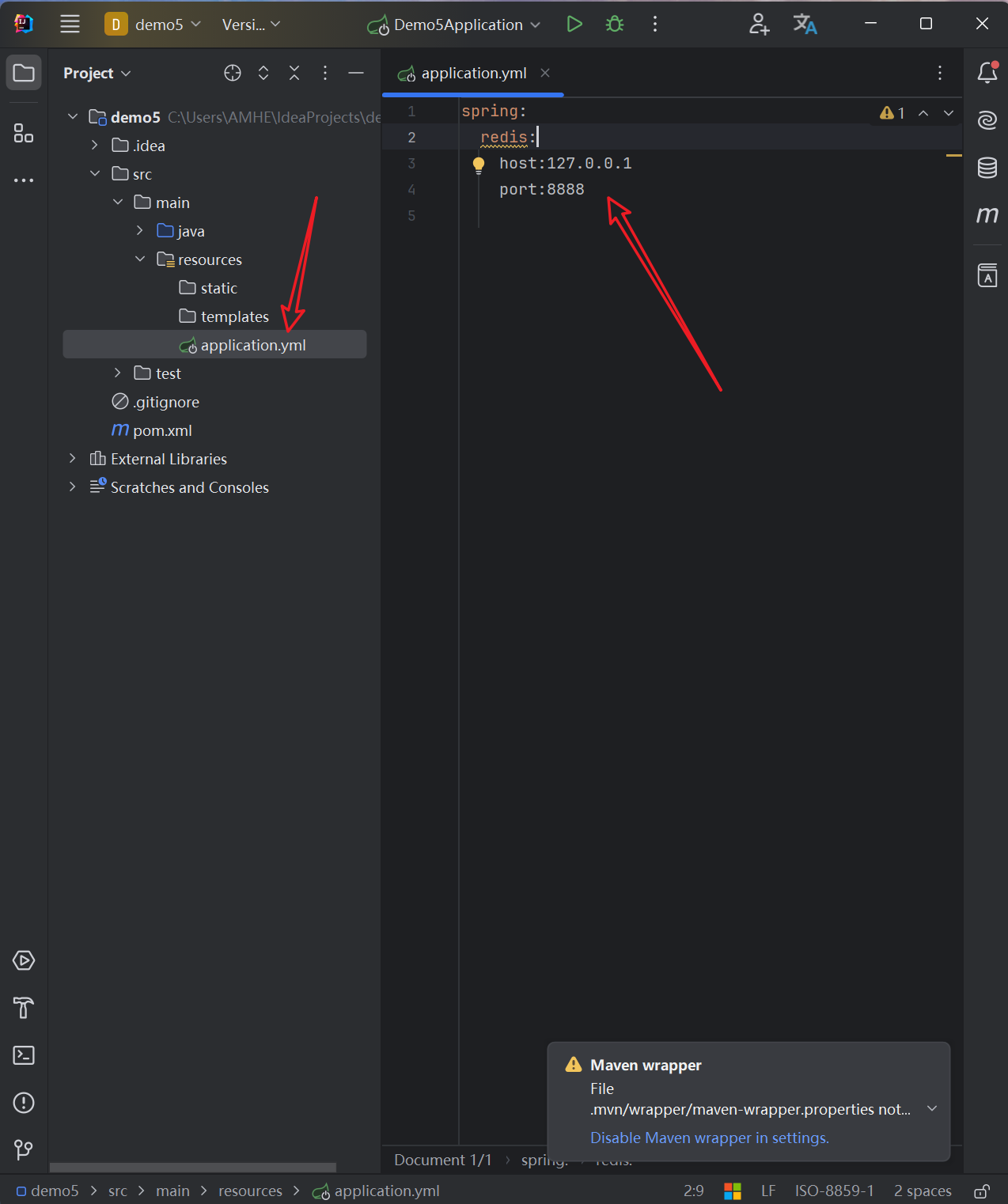
- 之前使用jedis,是通过jedis对象里的各种方法来操作redis的,此处的Spring中则是通过StringRedisTemplate来操作redis
- 最原始提供的类是RedisTemplate,StringRedisTemplate是RedisTemplate的子类,专门用来处理文本数据的
- StringRedisTemplate提供的方法,相比于之前的jedis中的各种方法,还是存在较大的差异的
- 此处RedisTemplate是把这些操作Redis的方法,分成了几个类别,分门别类的来组织的,作了进一步的封装
- 就得到了一个专门用来操作字符串的对象opsForValue()
- 得到了一个专门操作Zset的对象opsForZset()
String
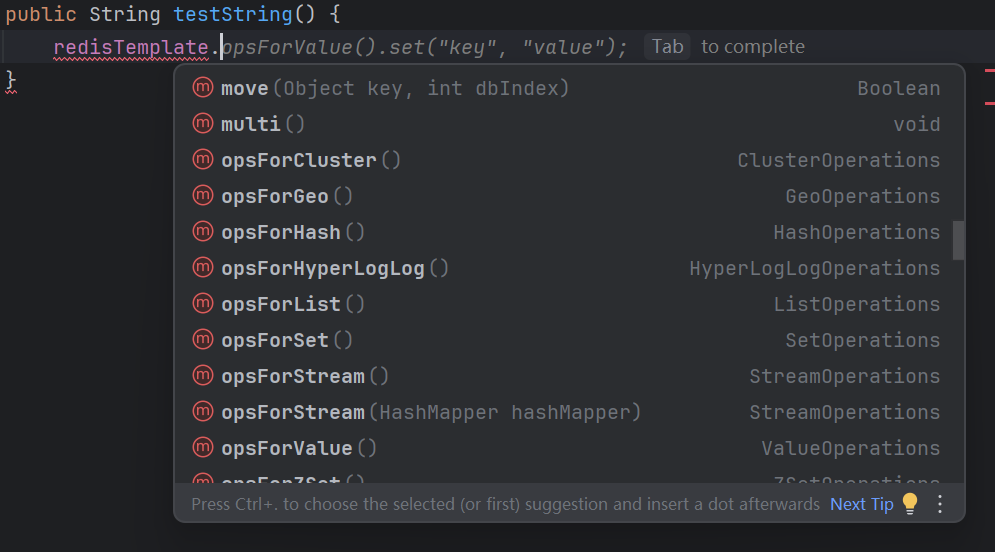
此处提供的一些接口风格,和原始的Redis命令就有一定的差异了,开发者初心是希望通过上述的封装,让接口用来更简单,但是上述初心并没有达成,接口上重新组织指挥,接口的使用并没有更简单,反而因为和Redis原生命令的差异,提高了使用者的学习成本
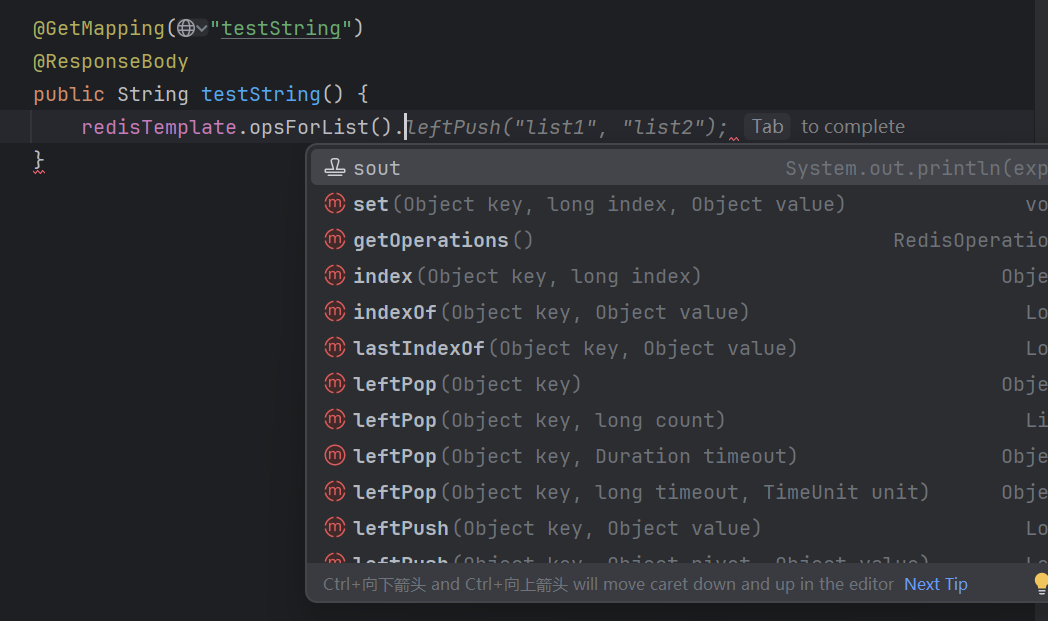
和原生Redis方法不太一样了
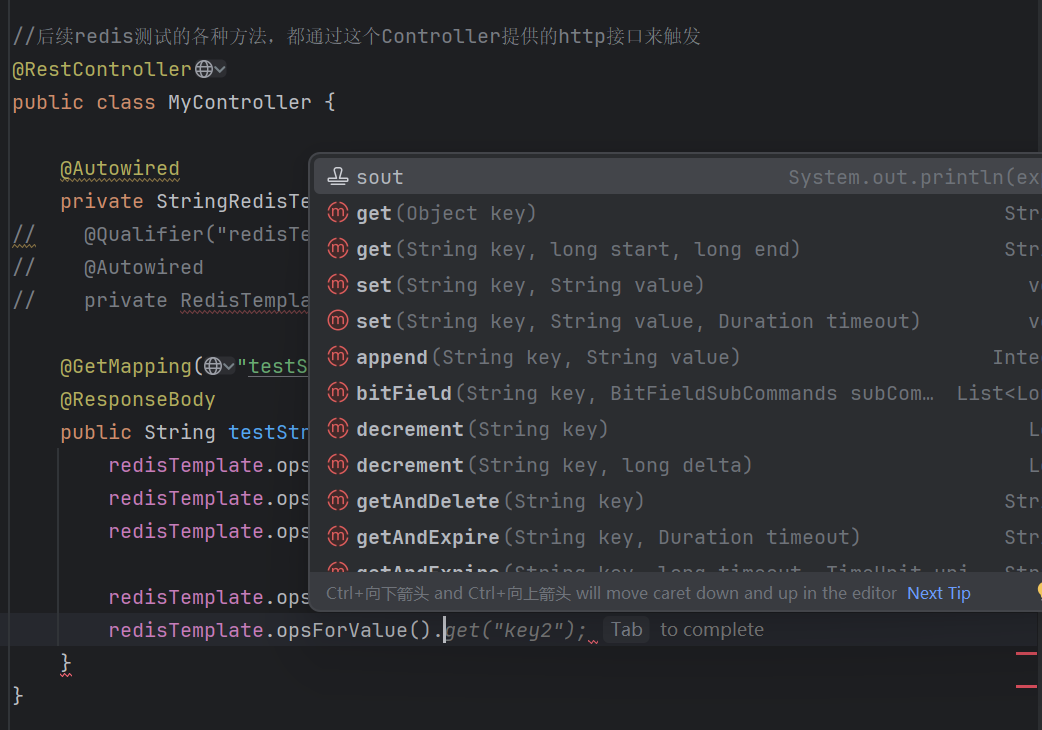
package com.example.demo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
//后续redis测试的各种方法,都通过这个Controller提供的http接口来触发
@RestController
public class MyController {
@Autowired
private StringRedisTemplate redisTemplate;
@GetMapping("/test")
@ResponseBody
public String test() {
redisTemplate.opsForValue().set("key", "value");
redisTemplate.opsForValue().set("key2", "value2");
redisTemplate.opsForValue().set("key3", "value3");
redisTemplate.opsForValue().get("key");
return "OK";
}
}RedisTemplate留了一个后手,让我们随时能够执行到Redis原生的命令
List
execute方法
函数式接口,相当于一个回调函数,就在这个回调里,写要执行的redis命令,这个回调就会被RedisTemplate内部执行
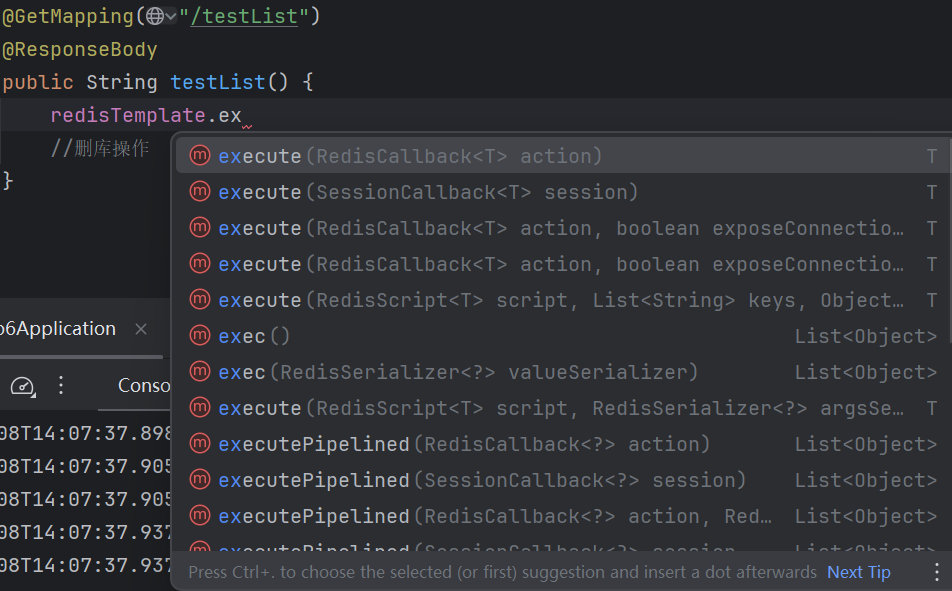
参数是RedisConnection,代表了Redis连接,对标Jedis对象
package org.springframework.data.redis.core;
import org.springframework.dao.DataAccessException;
import org.springframework.data.redis.connection.RedisConnection;
import org.springframework.lang.Nullable;
public interface RedisCallback<T> {
@Nullable
T doInRedis(RedisConnection connection) throws DataAccessException;
}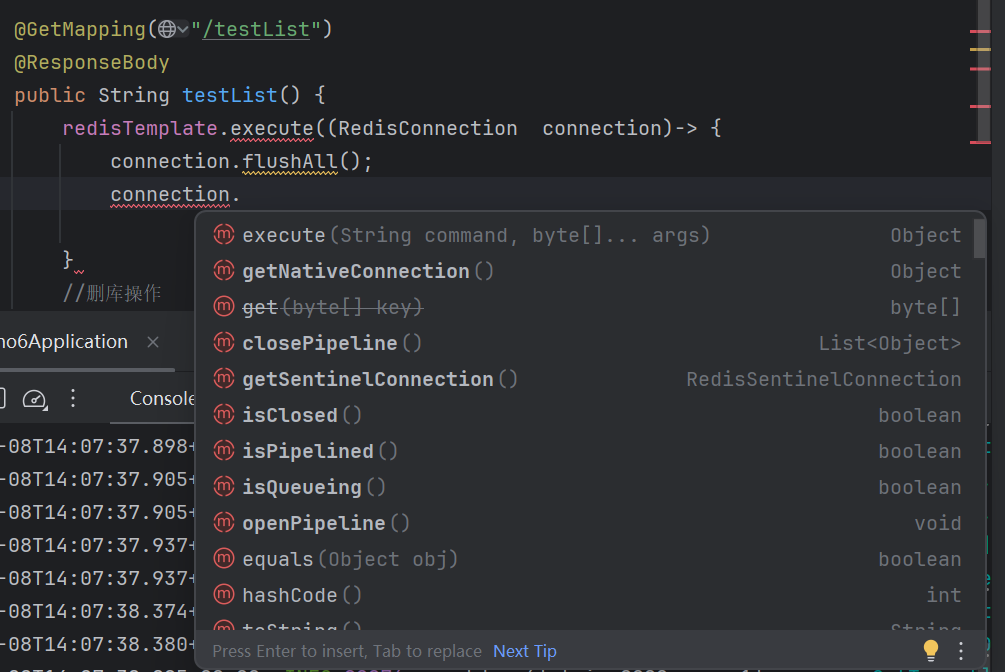
使用lambda表达式找到Redis原生命令
@GetMapping("/testList")
@ResponseBody
public String testList() {
redisTemplate.execute((RedisConnection connection)-> {
//execute 要求回调方法中必须写return语句,返回个东西
//这个回调返回的对象,返回作为execute本身的返回值
//删库操作
connection.flushAll();
return null;
});
redisTemplate.opsForList().set("key",0,"hello");
return "ok";
}一般不使用lambda表达式,而是使用ops里自带的方法
Set
@GetMapping("/testSet")
@ResponseBody
public String testSet() {
redisTemplate.execute((RedisConnection connection) -> {
connection.flushAll();
return null;
});
redisTemplate.opsForSet().add("key","value");
redisTemplate.opsForSet().
return "ok";
}Hash
@GetMapping("/testHash")
@ResponseBody
public String testHash() {
redisTemplate.execute((RedisConnection connection) -> {
connection.flushAll();
return null;
});
redisTemplate.opsForHash().put("key","value","hello");
redisTemplate.opsForSet().move("key","value","key");
return "ok";
}
Zset
@GetMapping("/testZSet")
@ResponseBody
public String testZSet() {
redisTemplate.execute((RedisConnection connection) -> {
connection.flushAll();
return null;
});
redisTemplate.opsForZSet().add("key", "zhangsan", 10);
redisTemplate.opsForZSet().add("key", "lisi", 20);
redisTemplate.opsForZSet().add("key", "wangwu", 30);
Set<String> members = redisTemplate.opsForZSet().range("key", 0, -1);
System.out.println("members: " + members);
Set<ZSetOperations.TypedTuple<String>> membersWithScore = redisTemplate.opsForZSet().rangeWithScores("key", 0, -1);
System.out.println("membersWithScore: " + membersWithScore);
Double score = redisTemplate.opsForZSet().score("key", "zhangsan");
System.out.println("score: " + score);
redisTemplate.opsForZSet().remove("key", "zhangsan");
Long size = redisTemplate.opsForZSet().size("key");
System.out.println("size: " + size);
Long rank = redisTemplate.opsForZSet().rank("key", "lisi");
System.out.println("rank: " + rank);
return "OK";
}以上就是Spring操作Redis的操作啦!!!
如果想找一些上面操作的api,可以搜索spring redis,就能看到doc了
文档
直接搜索即可 docx

















 3142
3142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









