






Redis 共有 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
这 5 种数据类型是直接提供给用户使用的,是数据的保存形式,其底层实现主要依赖这 8 种数据结构:简单动态字符串(SDS)、LinkedList(双向链表)、Dict(哈希表/字典)、SkipList(跳跃表)、Intset(整数集合)、ZipList(压缩列表)、QuickList(快速列表)。
Redis 5 种基本数据类型对应的底层数据结构实现如下表所示:

String(字符串)
介绍
String 是 Redis 中最简单同时也是最常用的一个数据类型。
String 是一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
String(字符串)
介绍
String 是 Redis 中最简单同时也是最常用的一个数据类型。
String 是一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
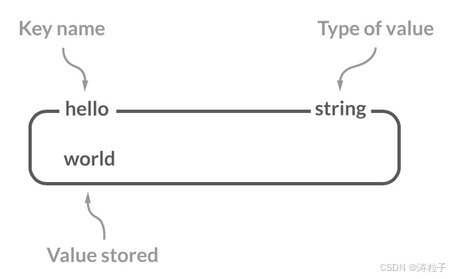
虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 简单动态字符串(Simple Dynamic String,SDS)。相比于 C 的原生字符串,Redis 的 SDS 不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)(C 字符串为 O(N)),除此之外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
常用命令
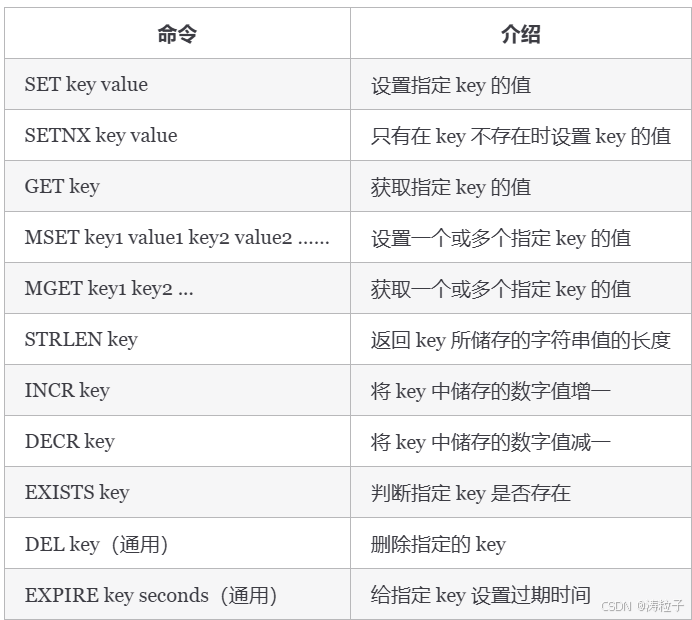
基本操作:
> SET key value
OK
> GET key
"value"
> EXISTS key
(integer) 1
> STRLEN key
(integer) 5
> DEL key
(integer) 1
> GET key
(nil)批量设置:
> MSET key1 value1 key2 value2
OK
> MGET key1 key2 # 批量获取多个 key 对应的 value
1) "value1"
2) "value2"计数器(字符串的内容为整数的时候可以使用):
> SET number 1
OK
> INCR number # 将 key 中储存的数字值增一
(integer) 2
> GET number
"2"
> DECR number # 将 key 中储存的数字值减一
(integer) 1
> GET number
"1"设置过期时间(默认为永不过期):
> EXPIRE key 60
(integer) 1
> SETEX key 60 value # 设置值并设置过期时间
OK
> TTL key
(integer) 56应用场景
需要存储常规数据的场景
- 举例:缓存 Session、Token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
- 相关命令:
SET、GET。
需要计数的场景
- 举例:用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数。
- 相关命令:
SET、GET、INCR、DECR。
分布式锁
利用 SETNX key value 命令可以实现一个最简易的分布式锁(存在一些缺陷,通常不建议这样实现分布式锁)。
List(列表)
介绍
许多高级编程语言都内置了链表的实现比如 Java 中的 LinkedList,但是 C 语言并没有实现链表,所以 Redis 实现了自己的链表数据结构。Redis 的 List 的实现为一个 双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
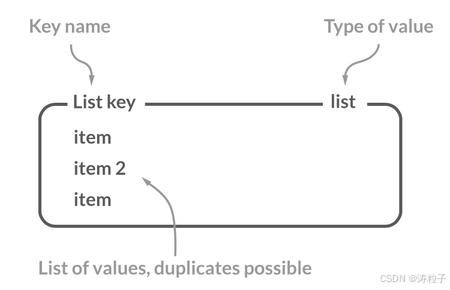
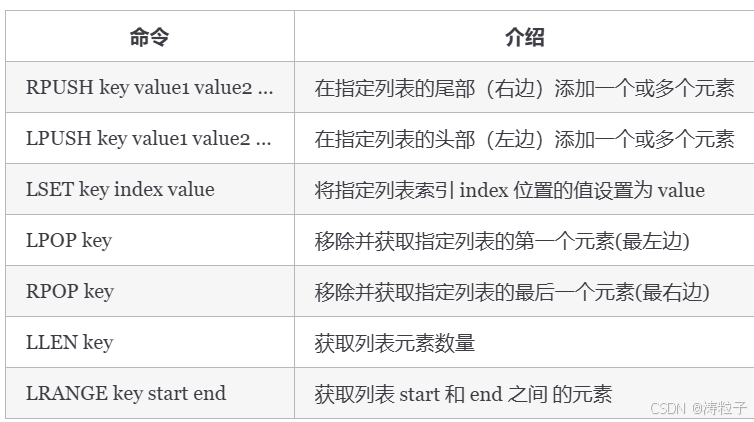
通过 RPUSH/LPOP 或者 LPUSH/RPOP实现队列:
> RPUSH myList value1
(integer) 1
> RPUSH myList value2 value3
(integer) 3
> LPOP myList
"value1"
> LRANGE myList 0 1
1) "value2"
2) "value3"
> LRANGE myList 0 -1
1) "value2"
2) "value3"通过 RPUSH/RPOP或者LPUSH/LPOP 实现栈:
> RPUSH myList2 value1 value2 value3
(integer) 3
> RPOP myList2 # 将 list的最右边的元素取出
"value3"我专门画了一个图方便大家理解 RPUSH , LPOP , lpush , RPOP 命令:

通过 LRANGE 查看对应下标范围的列表元素:
> RPUSH myList value1 value2 value3
(integer) 3
> LRANGE myList 0 1
1) "value1"
2) "value2"
> LRANGE myList 0 -1
1) "value1"
2) "value2"
3) "value3"通过 LRANGE 命令,你可以基于 List 实现分页查询,性能非常高!
通过 LLEN 查看链表长度:
> LLEN myList
(integer) 3应用场景
信息流展示
- 举例:最新文章、最新动态。
- 相关命令:
LPUSH、LRANGE。
消息队列
List 可以用来做消息队列,只是功能过于简单且存在很多缺陷,不建议这样做。
相对来说,Redis 5.0 新增加的一个数据结构 Stream 更适合做消息队列一些,只是功能依然非常简陋。和专业的消息队列相比,还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。
Hash(哈希)
介绍
Redis 中的 Hash 是一个 String 类型的 field-value(键值对) 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接修改这个对象中的某些字段的值。
Hash 类似于 JDK1.8 前的 HashMap,内部实现也差不多(数组 + 链表)。不过,Redis 的 Hash 做了更多优化。
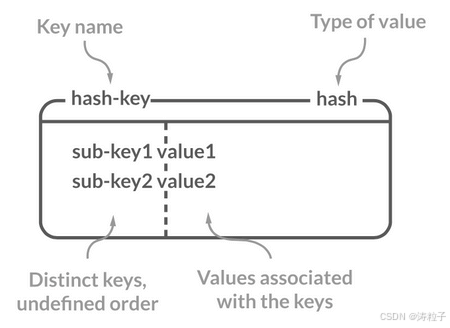
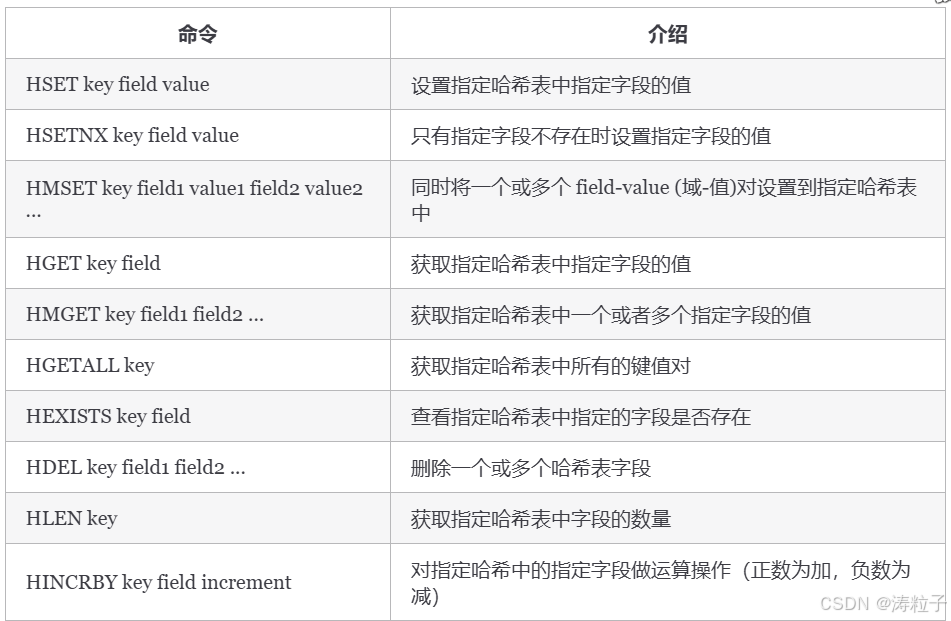
更多 Redis Hash 命令以及详细使用指南,请查看 Redis 官网对应的介绍:Commands | Docs 。
模拟对象数据存储:
HMSET userInfoKey name "guide" description "dev" age 24
OK
HEXISTS userInfoKey name # 查看 key 对应的 value中指定的字段是否存在。
(integer) 1
HGET userInfoKey name # 获取存储在哈希表中指定字段的值。
"guide"
HGET userInfoKey age
"24"
HGETALL userInfoKey # 获取在哈希表中指定 key 的所有字段和值
1) "name"
2) "guide"
3) "description"
4) "dev"
5) "age"
6) "24"
HSET userInfoKey name "GuideGeGe"
HGET userInfoKey name
"GuideGeGe"
HINCRBY userInfoKey age 2
(integer) 26应用场景
对象数据存储场景
- 举例:用户信息、商品信息、文章信息、购物车信息。
- 相关命令:
HSET(设置单个字段的值)、HMSET(设置多个字段的值)、HGET(获取单个字段的值)、HMGET(获取多个字段的值)。
Set(集合)
介绍
Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 HashSet 。当你需要存储一个列表数据,又不希望出现重复数据时,Set 是一个很好的选择,并且 Set 提供了判断某个元素是否在一个 Set 集合内的重要接口,这个也是 List 所不能提供的。
你可以基于 Set 轻易实现交集、并集、差集的操作,比如你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。这样的话,Set 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。
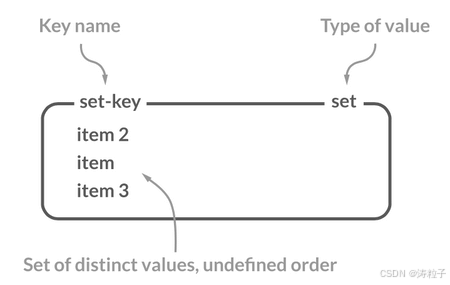
常用命令
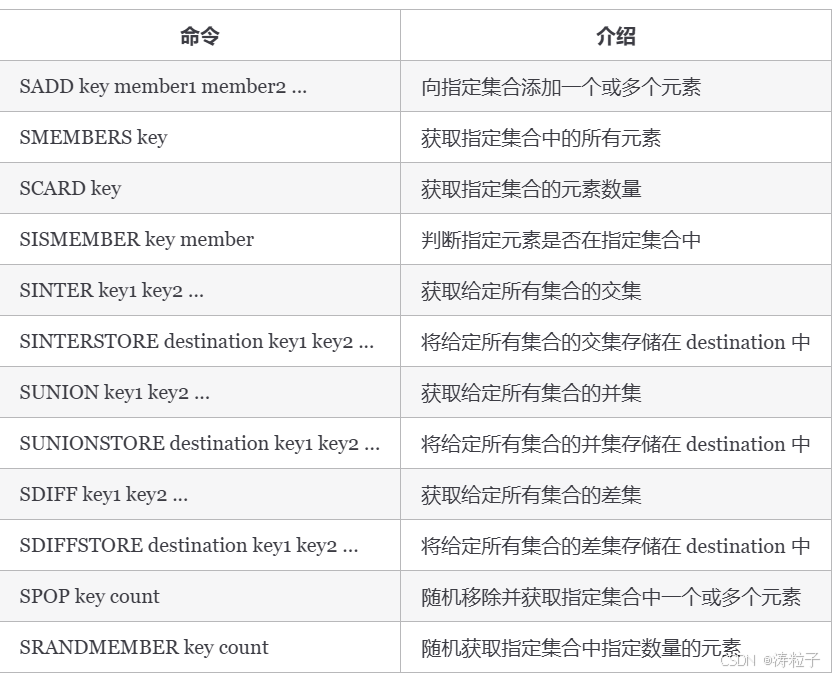
更多 Redis Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:Commands | Docs 。
基本操作:
> SADD mySet value1 value2
(integer) 2
> SADD mySet value1 # 不允许有重复元素,因此添加失败
(integer) 0
> SMEMBERS mySet
1) "value1"
2) "value2"
> SCARD mySet
(integer) 2
> SISMEMBER mySet value1
(integer) 1
> SADD mySet2 value2 value3
(integer) 2mySet:value1、value2。mySet2:value2、value3。
求交集:
> SINTERSTORE mySet3 mySet mySet2
(integer) 1
> SMEMBERS mySet3
1) "value2"求并集:
> SUNION mySet mySet2
1) "value3"
2) "value2"
3) "value1"求差集:
> SDIFF mySet mySet2 # 差集是由所有属于 mySet 但不属于 A 的元素组成的集合
1) "value1"应用场景
需要存放的数据不能重复的场景
- 举例:网站 UV 统计(数据量巨大的场景还是
HyperLogLog更适合一些)、文章点赞、动态点赞等场景。 - 相关命令:
SCARD(获取集合数量) 。 
需要获取多个数据源交集、并集和差集的场景
- 举例:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集) 等场景。
- 相关命令:
SINTER(交集)、SINTERSTORE(交集)、SUNION(并集)、SUNIONSTORE(并集)、SDIFF(差集)、SDIFFSTORE(差集)。
需要随机获取数据源中的元素的场景
- 举例:抽奖系统、随机点名等场景。
- 相关命令:
SPOP(随机获取集合中的元素并移除,适合不允许重复中奖的场景)、SRANDMEMBER(随机获取集合中的元素,适合允许重复中奖的场景)。
Sorted Set(有序集合)
介绍
Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。有点像是 Java 中 HashMap 和 TreeSet 的结合体。
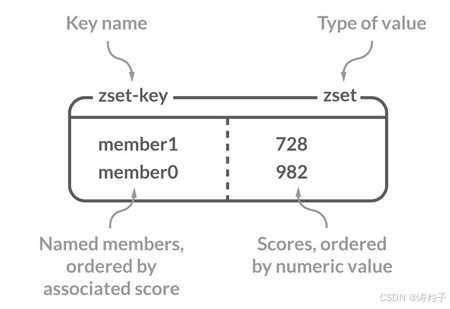
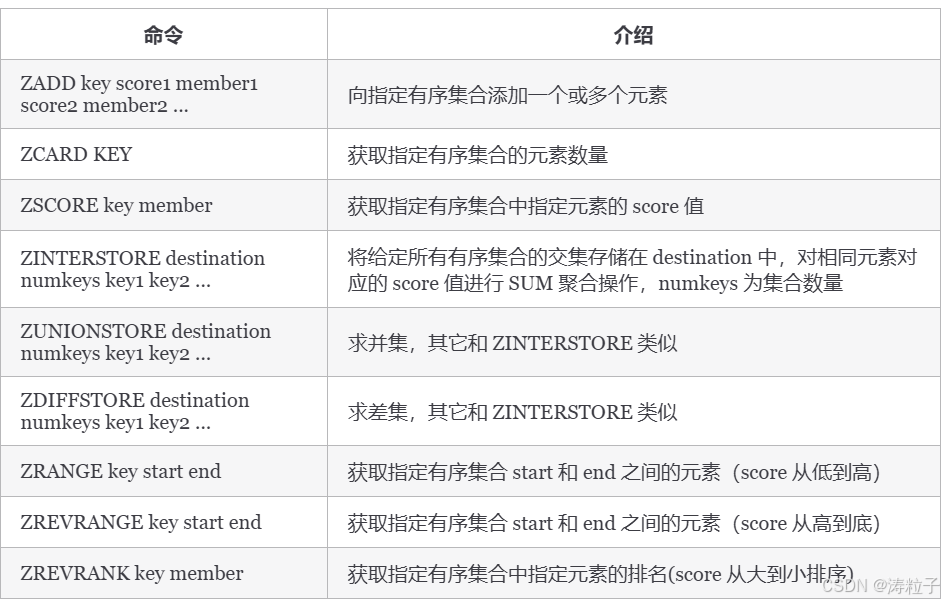
更多 Redis Sorted Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:Commands | Docs 。
基本操作:
> ZADD myZset 2.0 value1 1.0 value2
(integer) 2
> ZCARD myZset
2
> ZSCORE myZset value1
2.0
> ZRANGE myZset 0 1
1) "value2"
2) "value1"
> ZREVRANGE myZset 0 1
1) "value1"
2) "value2"
> ZADD myZset2 4.0 value2 3.0 value3
(integer) 2myZset:value1(2.0)、value2(1.0) 。myZset2:value2(4.0)、value3(3.0) 。
获取指定元素的排名:
> ZREVRANK myZset value1
0
> ZREVRANK myZset value2
1求交集:
> ZINTERSTORE myZset3 2 myZset myZset2
1
> ZRANGE myZset3 0 1 WITHSCORES
value2
5求并集:
> ZUNIONSTORE myZset4 2 myZset myZset2
3
> ZRANGE myZset4 0 2 WITHSCORES
value1
2
value3
3
value2
5求差集:
> ZDIFF 2 myZset myZset2 WITHSCORES
value1
2应用场景
需要随机获取数据源中的元素根据某个权重进行排序的场景
- 举例:各种排行榜比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
- 相关命令:
ZRANGE(从小到大排序)、ZREVRANGE(从大到小排序)、ZREVRANK(指定元素排名)。
需要存储的数据有优先级或者重要程度的场景 比如优先级任务队列。
- 举例:优先级任务队列。
- 相关命令:
ZRANGE(从小到大排序)、ZREVRANGE(从大到小排序)、ZREVRANK(指定元素排名)。
总结


















 1347
1347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









