






初始数据结构
首先要学习集合框架,当中包含了若干类,节接点组成的集合类背后是一个一个数据结构。
集合类组成集合框架。
数据结构=数据+结构,是用来描述和组织数据的。
数据库与数据结构的关系,数据库底层是由数据结构实现的。
容器对应的数据结构有很多
Collection:是一个接口,包含了大部分集合类的常用方法。
算法
时间复杂度通过大O渐进法来求
时间复杂度的算法:1.看代码,2.看思想。
1.用常数1取代运行时间中所有的加法常数。如果是常数则是O(1)
2.在修改运行次数函数中,只保留最高阶项。
3.如果最高阶项存在且不是1,则去除这个项目相乘的常数,得到的结果就是大O阶。
空间复杂度
是对一个算法在运行过程中临时占用存储空间大小的量度,空间复杂度算的是变量的个数。也使用O渐进法
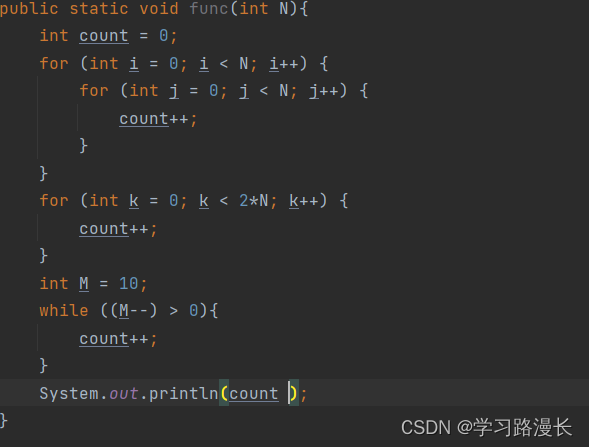
该代码的时间复杂度为O(N的平方),N代表问题的规模
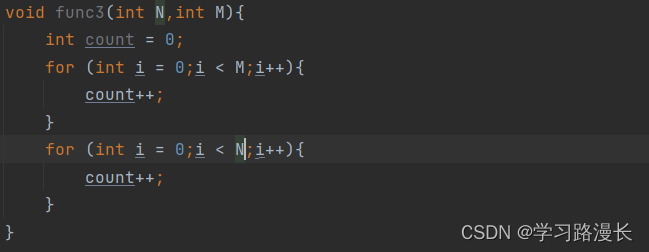
这个算法的时间复杂度为O(M+N),因为mn都是未知数。
冒泡排序
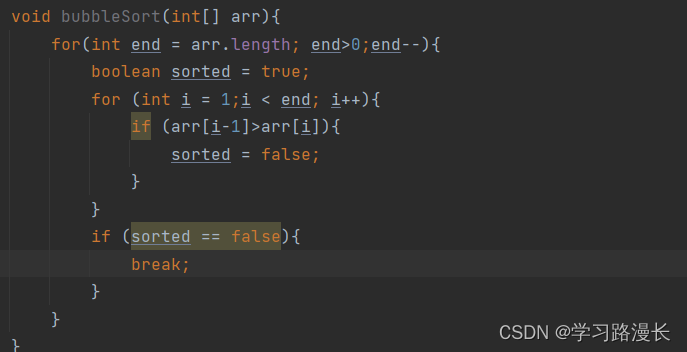
该函数的时间复杂度怎么求,假设end = 10,那么第二个for循环会执行9次,依次类推n-1,....1;
则是一个等差数列求和。
冒泡排序的空间复杂度为O(1)
二分查找的时间复杂度
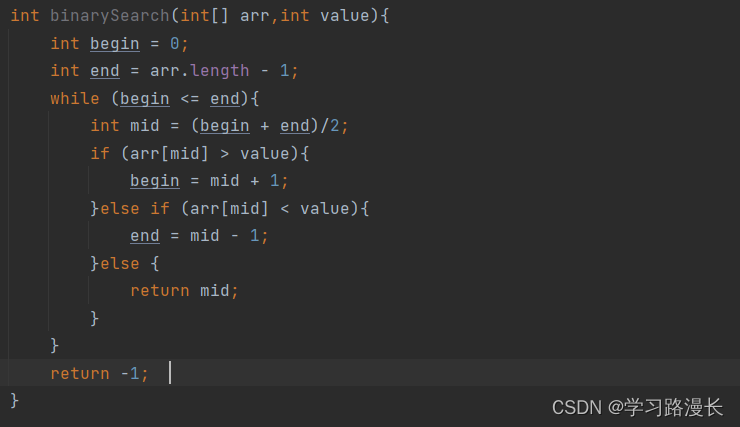
考虑时间复杂度,考虑最坏的情况,剩最后一个我才找到,我需要的那个数字,每一次去掉一半,设原来有n个数,砍了x次剩余最后一个数那么可以列出,n*二分之1的x次方 = 1,可得x等于log以2为低n的对数。
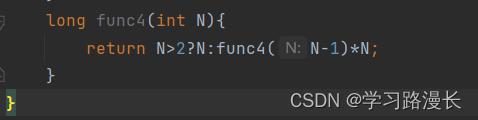
递归的时间复杂度:递归的次数*每次递归后代码的执行次数。

斐波那契数列求时间复杂度需要画图,最坏情况下是一个等比数列求和。
包装类
装箱和拆箱操作
装箱

第一个是显示装箱,第二个是自动装箱底层调用也是Valueof
把基本数据类型变成引用数据类型。
拆箱
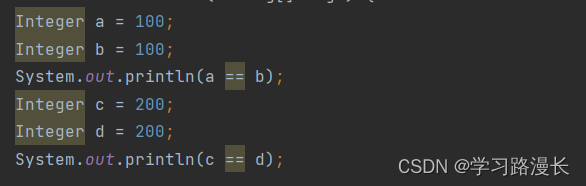
思考一下这段代码的结果
把一个基本数据类型给引用数据类型的操作叫做装箱,装箱所调用的函数是valueOf
low是-128,high是127.如果-128<=i<=127,cache数组是从下标为0到255的一个数组。
return cache(缓存)是一个数组的下标返回是一个数字
如果i不在这个范围内,就会实例化一个新对象。每次有一个新对象就要开辟空间。
所以上述代码一个为true一个为false
泛型
主要做的是把类型参数化。 意味着可以传指定的类型参数,<T>证明是一个泛型类。
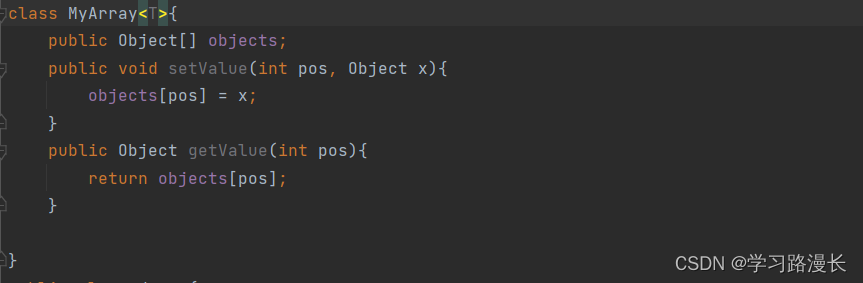
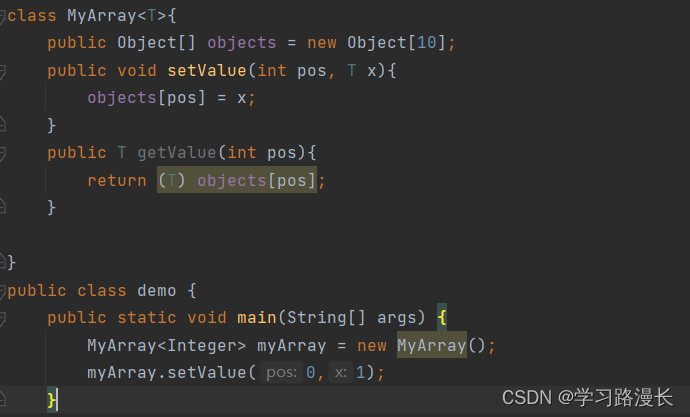
编译的时候1.每次存放数据的时候,会检查你存放的数据,是不是和你指定的类型一样。
2.此时不需要强制类型转化。
运行的时候没有泛型这个概念。运行的时候代码在JVM当中
在Java当中,数组是一种类型在new数组的时候必须是一个具体的类型,类名后面<T>代表占位符,表现当前是一个泛型类。
E表示element ,K表示key,V表示value ,N表示number,T表示type,S U V等等表示第二第三第四类型
擦除机制:在编译的过程中,将所有的T替换为Object这种机制,叫擦除机制。编译器生成的字节码在运行期间并不包含泛型的类型信息。
![]()
这样写代码总会出现下面这种问题


![]()
为什么会报错?因为Object是所有类的父类,但是Object[]不是所有数组的父类,是一种单独的类型。
![]()
最标准的写法。定义泛型数组
泛型的上界:在定义泛型类时,有时需要对传入的类型变量做一定的约束,可以通过类型边界来约束。
只接受Number的子类型或者Number作为自己的类型实参
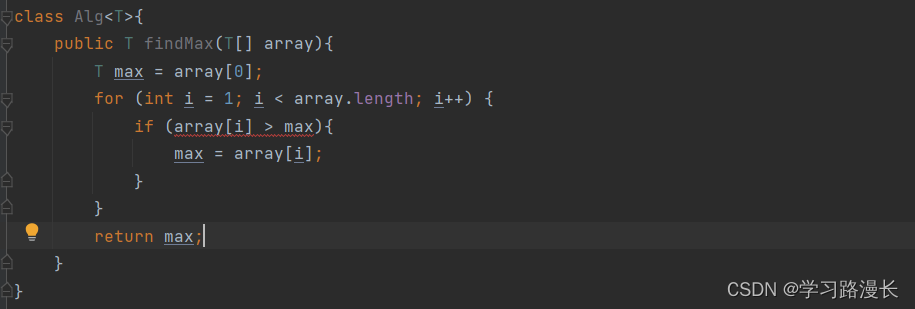
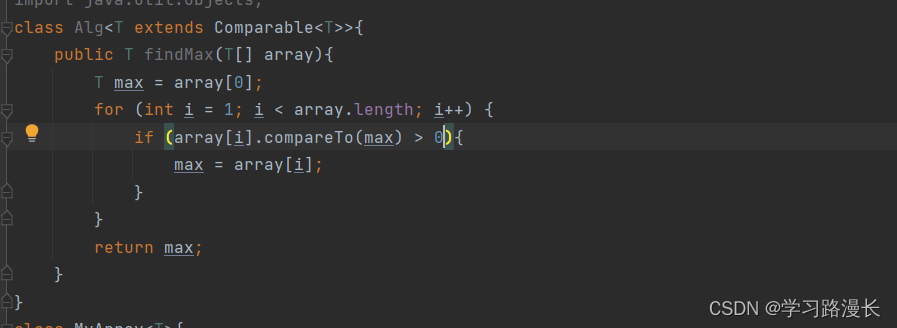
报错是因为引用数据类型不可以通过< > 来比较大小,通过实现Comparable接口来实现
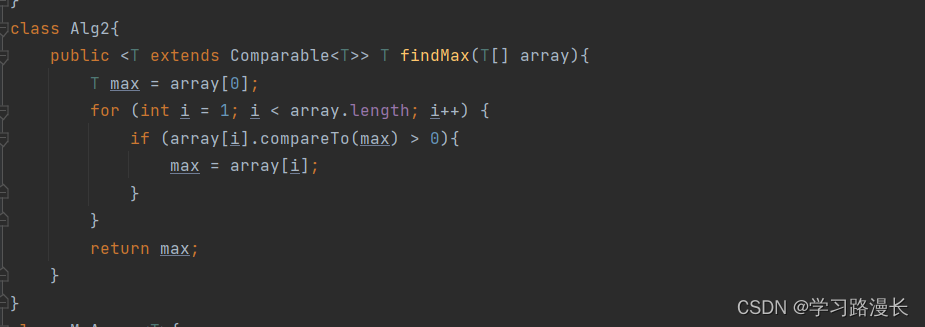
泛型方法(普通方法和静态方法)
Java数组 本身就需要一个确定的类型。
ArrayList的优点:适合查找和更新的场景
缺点:1.不方便插入和删除2.可能会浪费空间


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









