






希望当然是传播人们的意识,即人工智能是我们生活中不可或缺的一部分,我们不能忘记技术的进步,这些技术使以前无法想象的可能性成为可能。当我们目睹在制作创新和卓越技术方面的竞争激增时,这些时代确实令人振奋,使这个时代令人兴奋和鼓舞人心。
在这篇文章(八月版)中,我的目标是为AI公民提供:
- 法学硕士的组成部分
- 查特 vs 巴德 vs 克劳德 vs 克劳德 2 vs 美洲驼 2
AI Citizen是Stallion AI首席执行官Samer Obeidat首次提出的术语。人工智能公民被描述为知道自己在人工智能驱动的未来中的角色,并致力于道德和认真地利用人工智能来促进人类福祉的人。 在我看来,每个人都已经是浏览互联网的 1 级 AI 公民,无论是为了研究、构思还是内容创作。
本文中提到“AI Citizen”的目的是设定一种期望,即内容应包含恰到好处的技术剂量,以了解LLM的能力和价值。
什么是大型语言模型 (LLM)?
N欧洲网络,使计算机能够理解和生成人类语言。
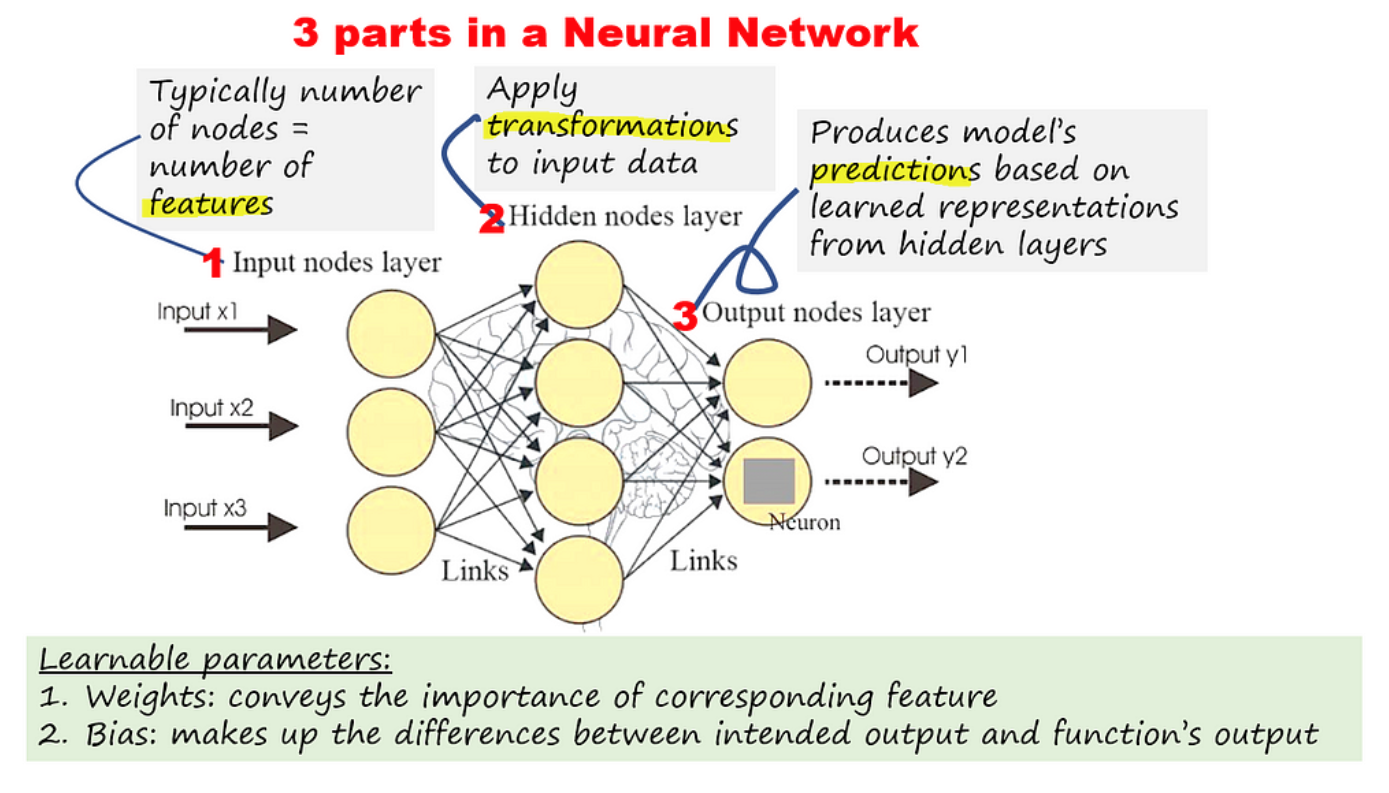
多层感知器(MLP),一个完全连接的多层神经网络。
中性网络是一种机器学习过程,称为深度学习,它在类似于人脑的分层结构中使用互连的节点或神经元。
为了直观地了解 NN 如何以简单的方式工作,想象一下训练 NN 对鹦鹉和鸡进行分类。

区分这两种动物的可识别特征
假设 3 个特征是梳子的存在、胸部的大小和柄的长度。神经网络的目标是了解每个特征的最佳权重(分布),以便最大限度地减少错误分类。下次给出照片时,该模型将预测它是鹦鹉/鸡的可能性。
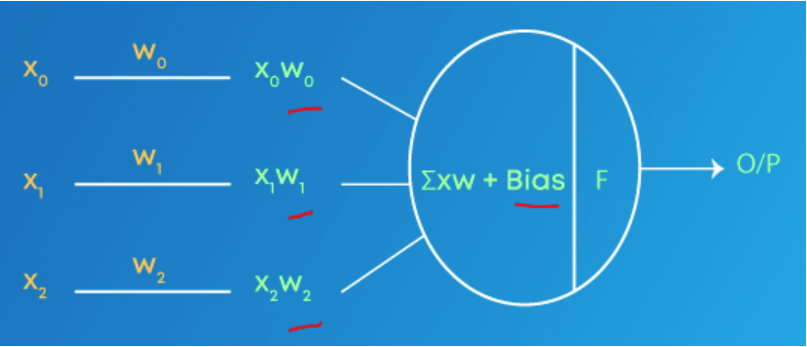
该过程可以总结如下: 1.将大量不同变化的鹦鹉和鸡的图片作为训练样本提供给神经网络(用随机权重初始化) 2。在计算每层的激活后计算输出,然后计算 误差 3.重新调整/调整权重,使误差减小 4.重复 1 到 3 直到重量稳定 ,我们有了它! x0(梳子的存在)很可能是重量最高的,因为它可能是解释差异的最重要特征。
上面的插图和描述是当今许多神经网络架构的基础。多年来,已经开发了不同的神经网络架构来执行自然语言处理 (NLP) 任务,例如翻译、情感分析、文本分类、生成和语言建模。RNN和CNN被认为是NLP任务的最新模型,直到最近,变压器作为一种新的、更强大的方法出现。
变压器、[大数据](https://www.oracle.com/my/big-data/what-is-big-data/#:~:text=What exactly is big data,especially from new data sources.)和超级计算机是使大型语言模型成功并适用于今天的原因。
RNN 是一种神经网络架构,在序列建模任务中取得了巨大成功。它们旨在处理输入序列,例如句子或时间序列数据。RNN 具有递归结构,允许它们捕获序列中不同输入之间的上下文和依赖关系。然而,RNN存在梯度消失的问题,这使得它们难以捕获长期依赖性。
另一方面,CNN是一种广泛用于图像识别任务的神经网络架构。它们旨在通过应用卷积过滤器从输入数据中提取特征。CNN已经适应了NLP任务,将单词视为图像并使用一维卷积过滤器从句子中提取特征。然而,CNN捕捉句子中不同单词之间关系的能力有限。
在LLM中要理解的3个关键字:
- 变形金刚
- 令 牌
- 参数
什么是变形金刚?
Transformer,一种围绕Vaswani等人在2017年引入的关注理念设计的架构,旨在解决RNN和CNN的缺点。这一关键发展使得通过专注于输入中最重要的部分来处理更长的序列成为可能,从而解决了早期模型中遇到的内存问题。
注意力允许模型在生成输出序列时专注于输入序列的不同部分。注意机制根据每个输入令牌与当前输出令牌的相关性为其分配权重。
什么是代币?
在语言模型中,令牌是模型训练和预测的原子单元。令牌通常是以下项之一:
- 一个单词 — 例如,短语“狗像猫”由三个单词标记组成:“狗”、“喜欢”和“猫”。
- 字符 — 例如,短语“自行车鱼”由九个字符的标记组成。(请注意,空格算作其中一个标记。
- 子词 — 其中单个单词可以是单个标记或多个标记。子词由词根、前缀或后缀组成。例如:“狗”作为两个标记(词根“狗”和复数后缀“s”
什么是参数?
参数是模型在训练期间学习的权重,用于预测序列中的下一个标记。与前面的鸡/鹦鹉示例中分配给每个特征的权重类似,在大型语言模型中,权重在训练期间进行调整,以优化模型生成相关且连贯文本的能力。
“LLM”中的术语“大”可以指模型中的参数数量,有时也可以指数据集中的单词数。
当今LLM的一个关键制胜因素是位置编码器的存在,这是一个基于单词在句子中的位置(即:上下文)给出上下文的向量。
有哪些限制和挑战?
偏见:由于语言模型是基于来自互联网的文本数据训练的,这可能会导致错误信息、社会/地理/道德偏见,甚至负面情绪。
数据隐私: 基于LLM的应用程序(如ChatGPT,Llama 2,Claude 2和BARD)中依赖开源和第三方API的用户输入可能会暴露。
内存窗口:每个大型语言模型只有一定量的内存。超过一定数量的输入令牌,它们将无法再执行所需的任务。
成本和环境影响:LLM通常需要许多专用GPU和比标准深度学习模型更多的处理能力。这些服务器成本很高,消耗大量能源,造成了相当大的碳足迹。
查特 vs 巴德 vs 克劳德 vs 克劳德 2 vs 美洲驼 2
在简要了解了LLM之后,我们可能会开始欣赏当今大多数聊天机器人或AI应用程序背后的模型。这些生成式人工智能应用程序是今年年初激发许多网民,技术和商业专业人士兴趣的应用程序。
包括本文在内的许多文章都提供了AI聊天机器人与各自的高级LLM之间的比较。
以下是雷达图中显示的摘要:

雷达图的灵感来自本文中的评分。
注意:排名基于在每个标准领域提出的 3 个问题中得分。
聊天:
- 通过OpenAI(使用>GPT3.5)
- 总冠军平衡了从创意写作到编程的所有 5 个领域。然而,一些文章和个人经验表明,ChatGPT 在算术尤其是复杂和冗长的问题上表现不佳。
吟游诗人:
- 谷歌(使用 PaLM 2)
- 根据您的风格或偏好,Bard 允许用户查看其他 2 个草稿,并有一个非常方便的“Google It”按钮,以防回退到传统的网络搜索和定性分析方法。
克劳德2:
- 作者:Anthropic AI(使用Claude 2) (注意:由于它现在仅在美国和英国可用,因此如果您居住在美国和英国境外,则需要VPN)
- 最新的,但被证明具有与ChatGPT几乎相似的功能。
骆驼2:
- 由 Meta 和 Microsoft (使用 Llama 2)
- 甚至 META 也承认它没有那么强大,但是,建议开发人员了解 LLM 的工作原理以及使用不同模型(7B、13B 或 70B)以及 Top P 和 Max Tokens 等参数生成的结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









