







 该文介绍了如何使用PandasDataFrame进行数据访问,包括通过字典和属性方式访问列,使用.loc和.iloc进行行访问,以及元素访问和切片操作。示例代码展示了显式和隐式索引的用法,以及列和行的切片方法。
该文介绍了如何使用PandasDataFrame进行数据访问,包括通过字典和属性方式访问列,使用.loc和.iloc进行行访问,以及元素访问和切片操作。示例代码展示了显式和隐式索引的用法,以及列和行的切片方法。
内容:
·访问
·对列进行访问
·对行进行访问
·对元素进行访问
·切片
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
arr = np.random.randint(0, 100, size=7)
index = ["001", "002", "003", "004", "005", "006"]
dict_things = {
"name": Series(data=["fom", "gom", "hom", "jom", "kom", "lom"], index=index),
"number": Series(data=np.random.randint(0, 100, size=6), index=index),
"sum": Series(data=np.random.randint(0, 100, size=6), index=index)
}
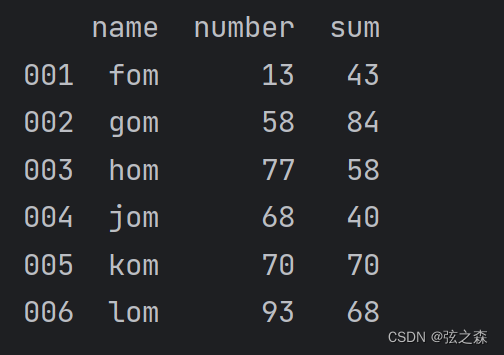
df = DataFrame(dict_things)
print(df)
print()
运行结果:
【访问】
(对列进行访问)
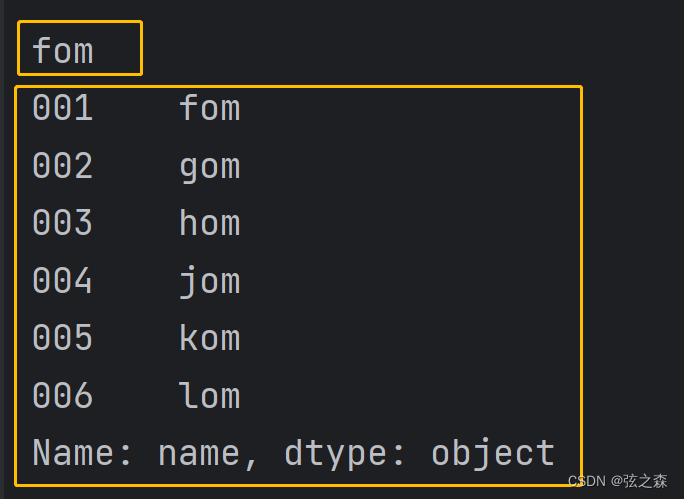
字典访问:
当用户使用字典访问时,第一个访问索引(必须出现)为列索引
# 字典访问:
# 当用户使用字典访问时,第一个访问索引(必须出现)为列索引,第二个访问索引(可以不出现)为行索引
print(df["name"]["001"])
# 属性访问:(一般不用)
print(df.name)
print()运行结果:
(对行进行访问)
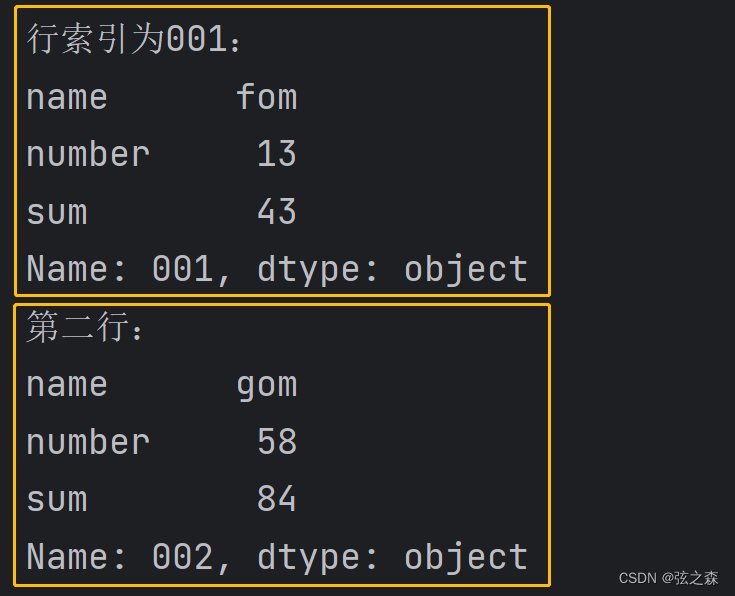
使用.loc[]加index来进行显式行索引
使用.iloc[]加整数来进行隐式行索引
同样返回一个Series,index为原来的columns:
# 显示访问行:
print("行索引为001:")
print(df.loc["001"])
# 隐式索引访问:
print("第二行:")
print(df.iloc[1])
print()运行结果:
(对元素的访问)
官方推荐的访问方式:
简介:DataFrame数 组的元素访问,和numpy数组的元素访问差不多,都是先行后列访问方法
因为访问机制是行后列,所以应该先确定(显式行/隐式行)访问,在(loc/iloc)后的中括号中传入一个列表,列表的第一个元素是(行显式索引/行隐式索引),列表的第二个元素是列索引
# 显式
print("行显式索引为003,列索引为name的元素为:")
print(df.loc["003", "name"])
# 隐式
print("行隐式索引为0,列隐式索引为2的元素为:")
print(df.iloc[0, 1])
print()运行结果:
【切片】
规则:和二维数组切片大致一样
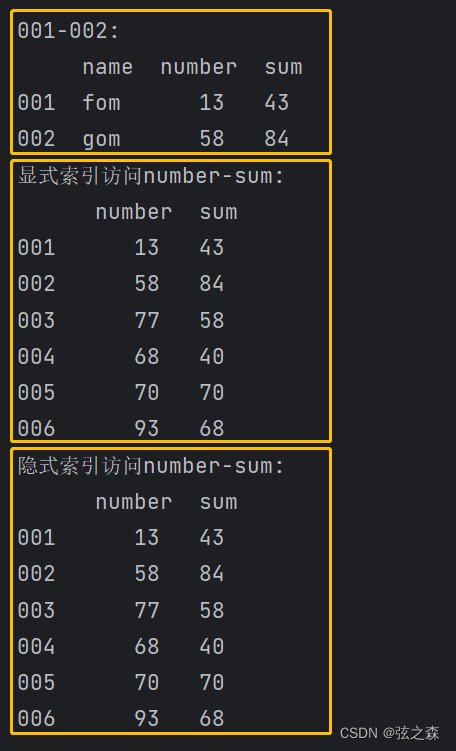
注意,在DataFrame数组中直接使用中括号时,索引是列索引,切片是行切片
print("001-002:\n", df.loc["001":"002"])
print("显式索引访问number-sum:\n", df.loc[:, "number":"sum"])
print("隐式索引访问number-sum:\n", df.iloc[:, 1:3])运行结果:


















 1786
1786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











