







1.为什么要出现一致性Hash算法
1.1初探场景
什么是一致性Hash?
从分布式工程入手,假设我们现在正在架构一个大型互联网工程,现在我们的架构是这样的:
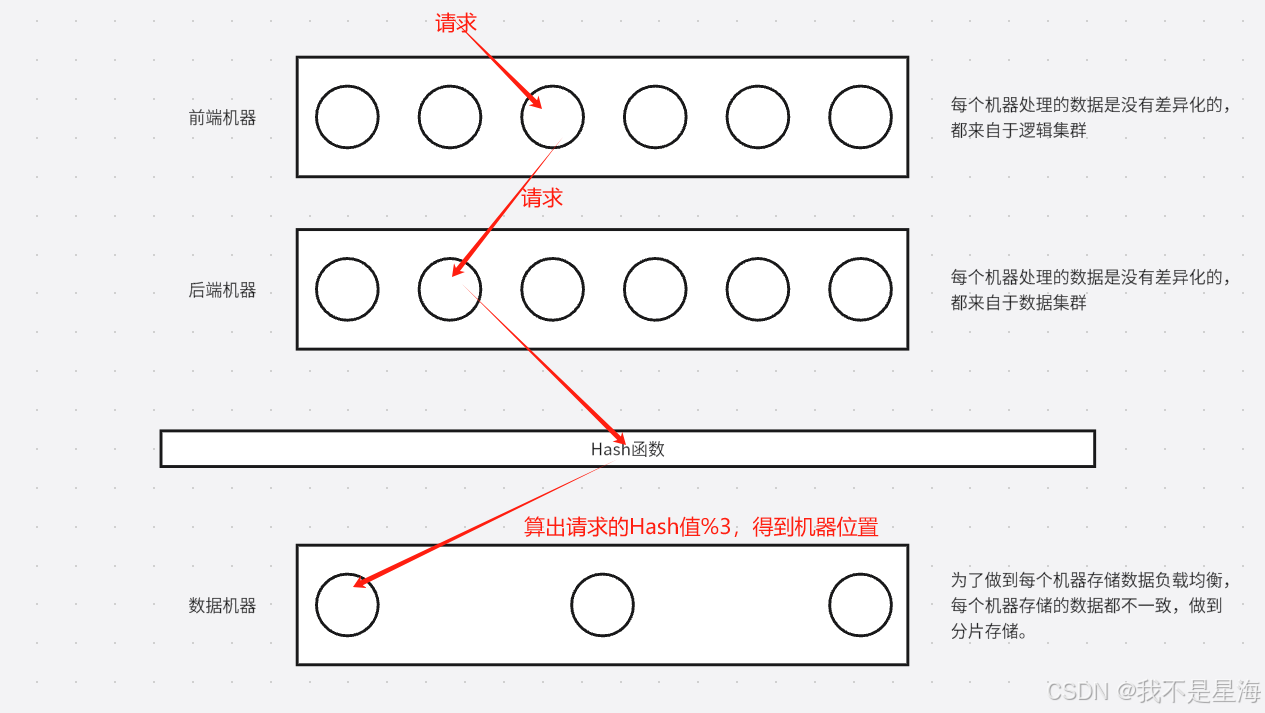
前端有一堆机器组成前端集群,后端也有一堆机器组成后端集群,数据机器现在有三台机器组成数据集群。
假设现在有一个请求打到了某一台前端机器,前端机器根据复杂均衡算法达到了后端集群的某一台机器上。
后端集群将请求根据Hash函数,打到数据集群中的某一台机器上。
Hash函数其实就是,算出请求对象的Hash值,然后对3取模,得到需要将请求对象打到哪台数据机器上,最终将查询请求打到对应的机器上。
所以这里就会引出一个问题:后端机器向数据机器发起请求的Hash分配函数应该如何设计?
1.2传统设计
假设现在使用传统设计方案,Hash函数的设计思路是:挑选出请求中的某个属性作为key,去根据key计算出对应的Hash值,再使用Hash值对3取模最终计算出请求应该打到那台数据机器上。
1.2.1Key的选择
这里很关键的一点就是:key应该如何挑选的问题。
如果我们挑选的key中有少量key是非常高频的,大量key是非常低频的,根据Hash函数中的特性,无随机性,相同的输入一定会导致相同的输出。这种设计无疑会导致Hash函数的输出会失去想要的离散性的特点。
需要理解清楚:Hash函数离散性到底是怎么来的?
Hash函数的离散性是由大量不同输入,得来的输出域离散性的特点。
这里有几个关键点:1.输入。2.大量。3.不同。
如果key被设计的不合理,很有可能导致Hash函数离散型消失,就会丧失了Hash函数原有的特性。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









