




1. c++ 是第三代程序设计语言
2.
3. 字母表(Alphabet) 在编译原理中定义为有限的符号集合,用于构成字符串或语言(如正则语言或上下文无关语言)
4.

5.

6. 全局变量分配在内存的静态数据区
7.

8.

9.

10.

11. S属性SDD只包含综合属性,L属性SDD可能包含继承属性

12.

13.


14.

15.

16.

17.

18.

19.

20

21

22

23

24.
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
25.

26.

27.

28. What is the function of a compiler?
- 读入源语言编写的程序
- 输出等价的目标语言编写的程序
- 通常目标程序是可执行的
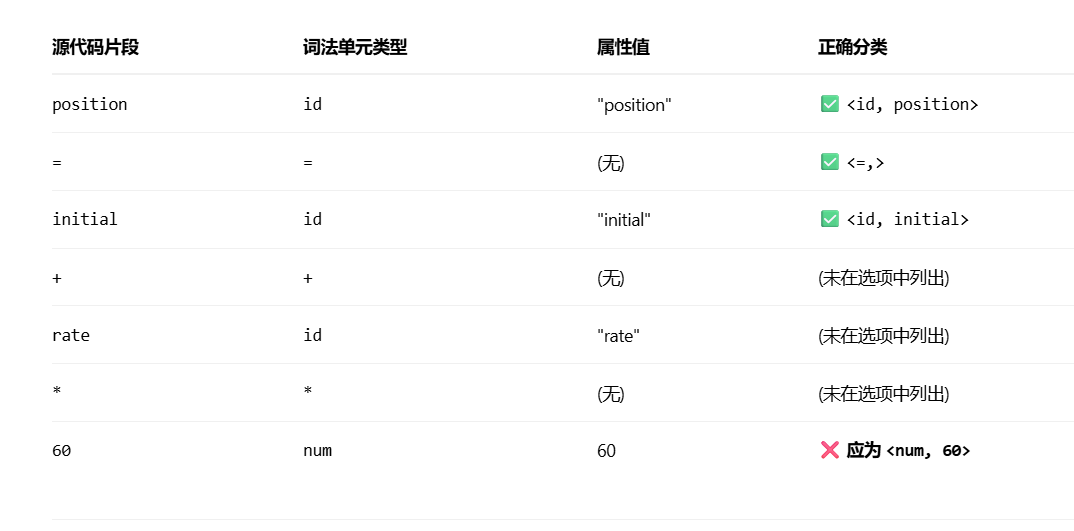
29. 什么是词法单元
- <词法单元名、属性值(可选)>
- 属性值通常用于语义分析之后的阶段
- 单元名是表示词法单位种类的抽象符号,语法分析器通过单元名即可确定词法单元序列的结构
30 要设立独立的词法分析器
- 增强编译器的可移植性
- 词法分析器可以首先完成一些简单的处理工作
- 提高编译器效率
- 相对于语法分析,词法分析过程简单,可高效实现(下推自动机 vs 又穷自动机)
- 简化编译器的设计
31 词法分析器的作用是什么
- 读入字符流,组成词素,输出词法单元序列
- 过滤空白、换行、制表符、注释等
- 将词素加到符号表中
- 在逻辑上独立于语法分析,但是通常和语法分析器处于同一趟中
32 解释词法单元的属性概念
- 一个模式匹配多个词素时,必须通过属性来传递附加的信息
- 属性值将被用于语义分析、代码生成等阶段
- 不同的目的需要不同的属性
- 属性值通常时一个结构化数据
- 如词法单元id的属性
- 词素、类型、第一次出现的位置
33 词法单元的正则定义

34 ‘banana’ 的前缀、后缀、子串、子序列
35 给出 NFA 的定义
- 一个有穷的状态集合 S
- 一个输入符号集合 ∑
- 转换函数: 对于每个状态和 中的符号,给出乡音的后继状态集合
- S 中的某个状态 S0 被指定为 开始状态/初始状态(有些定义中可以有多个开始状态)
- S 的一个子集 F 被指定为接收状态集合
36 给出 DFA 的定义
- 一个NDF被称为 DFA
- 没有符号和 e 的转换,并且对于每个状态 s 和每个输入符号 a ,有且仅有一条标号为a的离开s的边
- 可以高效判断一个串能否被一个 DFA 接受
- 每个 NFA 都有一个等价的 DFA
37 有穷自动机及其分类
-
本质和状态转换图相同,但有穷自动机只回答 YES/NO
- NFA:边上的标号没有限制,一个符号可出现在离开同一个状态的多条边上,e可以做标号
- DFA:对于每个状态及每个符号,有且只有一条边(或最多只有一条边)
-
两种自动机都识别正则语言
- 对于每个可以用正则表达式描述的语言,均可用某个 NFA 或 DFA 来识别;反之亦然
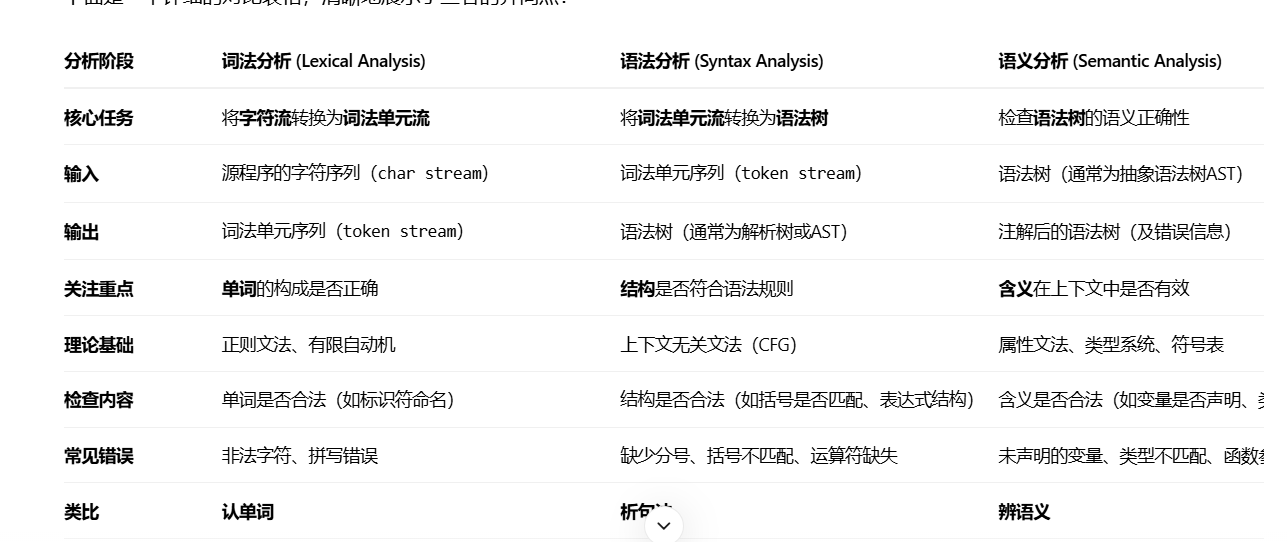
38 什么是词法分析,什么是语法分析,什么是语义分析
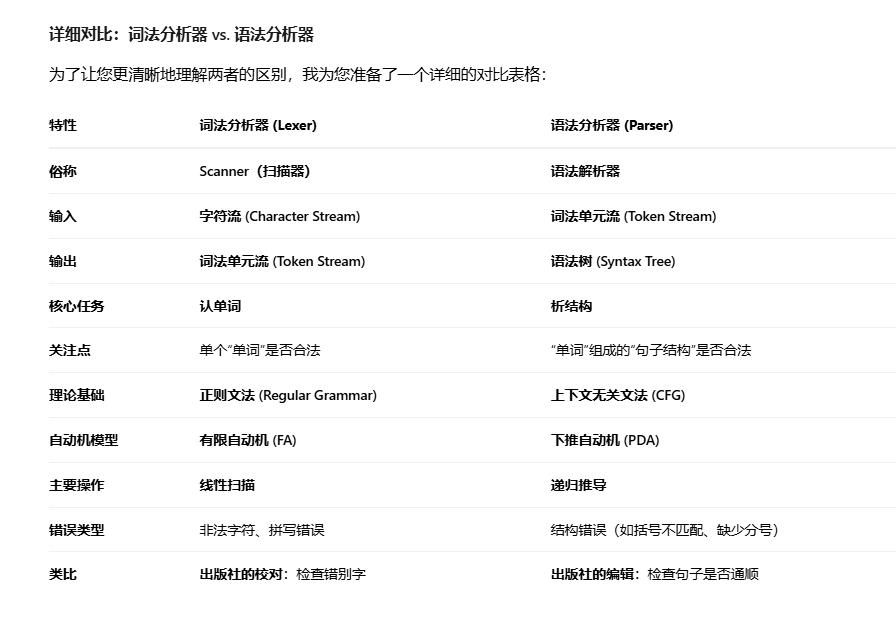
39 什么是语法分析器,什么是词法分析器
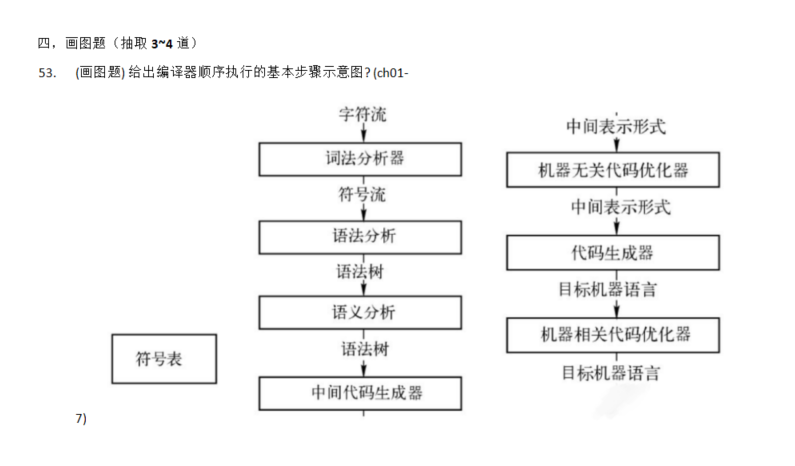
40. 编译器顺序执行的基本步骤
41 语法分析器的作用是什么
- 对于语法错误的程序,报告错误信息
- 对于语法正确的程序,生成语法分析树(简称语法树)
- 从词法分析器获得词法单元的序列,确认该序列是否可以由语言的文法生成
42 语法分析分为哪几类
-
通用语法分析器:人任意文法进行语法分析,效率低,不适合编译器
-
后两种方法:总是从左到右,逐个扫描词法单元,只能处理特定类型的文法,但足以描述程序设计语言
-
自顶向下语法分析器 (一般用于处理LL文法), 从语法分析树的根部开始构造语法分析树
-
自底向上语法分析器 (一般用于处理LR文法),从语法分析树的叶子开始构造语法分析树
43 为什么说 CFG 比正则表达式更优
- 所有的正则语言都可以使用文法描述
- 但有一些用文法描述的语言不能用正则表达式描述
44 什么是左递归、立即左递归、为什么要消除左递归
-
自顶向下的语法分析技术不能处理左递归的情况,因此需要消除左递归。但是自底向上的技术可以处理左递归。

45 什么是归约
- 一个与某产生式体相匹配的特定字串被替换为该式头部的非终结符号
- 自底向上的语法分析过程可以看成是从串 w 归约为文法开始符号 S 的过程
46 移入归约分析技术
- 移入:将下一个输入符号移入到栈顶
- 归约:将句柄归约为相应的非终结符号
- 句柄总是在栈顶
- 具体操作时弹出句柄,压入被归约到非终结符号
- 接收:宣布分析过程成功完成
- 报错:发现语法错误,调用错误恢复子程序
47 LR(k) 语法分析技术中, L, R, K的含义
- L 表示最左扫描,R 表示反向构造出最右推导
- k 表示做多向前看 k 个符号
48 LR 语法分析的优点
- 分析的文法比 LL(K)文法更多
- 对于几乎所有的程序设计语言,只要写出上下文无关文法,就能够构造出识别该语言的 LR 语法分析器
- 最通用的无回溯 移入-归约分析技术
- 由表格驱动, 虽然手工构造表格的工作量很大,但表格可以自动生成
49 简述构造 LR(0) 自动机的基本方法

50 对比 SLR, LR, LALR 的优缺点
- SLR(1) 语法分析表的分析能力较弱
- LR(1) 语法分析表的状态数量很大
- LALR(1) 是实践中常用的方法
- 状态数量和 SLR(1) 的状态数量相同
- 能够方便地处理大部分常见程序地构造
51 什么是综合属性什么是继承属性
- 综合属性
- 节点N的子节点或N本身的属性值来定义
- 节点N的属性值由N的产生式所关联的语义规则来定义
- 继承属性
- 节点N的父节点,兄弟节点,本身上的属性值来定义
- 节点N的属性值由N的父节点所关联的语义规则来定义
52 给出 SDD 的定义
- SDD 上下文无关文法和属性/规则的 结合
- 一个分析树节点和它的分支对应于一个产生式规则,而对应的语义规则确定了这些节点上的属性的取值和计算
- 对于文法符号X和属性a,我们用X.a表示分析树中某个标号为X的节点的值
53 请说明 S属性 SDD 的特点
- 每个属性都是综合属性,都是根据子构造的属性计算出父构造的属性
- 在依赖图中,总是通过子节点的属性值来计算父结点的属性值,可以和自底向上或自顶向下的语法分析过程一起计算
54 请说明 L 属性 SDD 中属性的特点和依赖图的特点

55 语法制导的翻译方案(SDT) 的定义及其基本方法
- 语法制导的翻译方案(SDT) 是在产生式体中嵌入语义动作(程序片断)的上下文无关文法
- SDT 的基本实现方法
- 建立语法分析树
- 将语义动作看作是虚拟结点
- 从左到右,深度优先地遍历分析树,在访问虚拟结点时执行相应地语义动作
56 简述后端 SDT 的定义及其构造方法
- 文法可以自底向上分析(即LR的) 且其 SDD 是 S 属性的,必然可以构造出后缀 SDT
- 后缀 SDT: 所有动作都在产生式最右端的 SDT
- 构造方法:
- 将每个语义规则看作是一个赋值语义动作
- 将所有的语义动作放在规则的最右端
57 简述 L 属性 SDD 转换为 SDT 的基本方法
- 将每个语义规则看作是一个赋值语义动作
- 将赋值语义动作放到相应产生式的适当位置
- 计算Xi继承属性的动作插入到产生体中x的左边
- 计算产生式头A综合属性的动作在产生式的最右边
58 什么是注释语法分析树,如何构造注释语法分析树
- 注释语法分析树:包含了各个节点的各属性值的语法分析树
- 对于任意的输入串,首先构造出相应的分析树
- 给各个节点(根据其文法符号) 加上相应的属性
- 按照语义规则计算这些属性的值
59抽象语法树及其表示方法
- 每个节点用一个对象表示
- 对象有多个域,叶子结点中只存放词法分析,内部节点中存放了op值和参数(通常指向其它节点)
- 每个节点代表一个语法结构,对应于运算符
- 节点的每个子节点代表其子结构,对应于运算分量
- 这些子结构按照特定的方式组成了较大的结构
- 可以忽略掉一些标点符号等非本质的东西
抽象语法树(AST) 作为一种中间表示,允许把翻译从分析中分离出来,实现先分析生成语法树,然后再基于语法树进行翻译
60 说明编译器的逻辑结构,前后端分离有什么好处
- 前端是对源语言进行分析并产生中间表示
- 处理于源语言相关的细节,与目标机器无关
- 前端后端分开的好处:不同的源语言、不同的机器可以得到不同的编译器组合
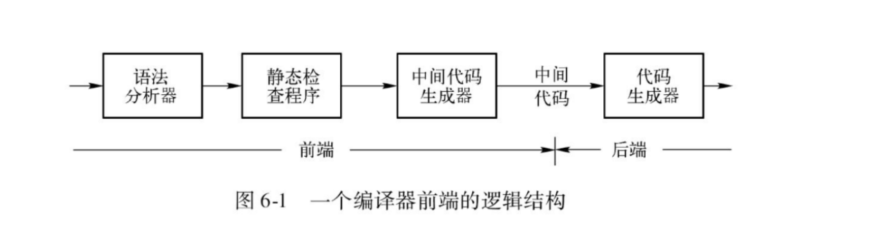
61 什么是类型检查,类型信息有哪些用途
- 利用一组规则来检查运算分量的类型和运算符的预期类型是否匹配
- 查错、确定名字需要的内存空间、计算数组元素地址、类型转换、选择正确的运算符
62 什么是隐式类型转换,什么是显式类型转换
- 编译器自动完成的转换为隐式转换,程序员用代码指定的转换为显式转换
63 运行环境包括哪些功能
- 为数据分配安排存储位置
- 确定访问变量时使用的机制
- 过程之间的连接、参数传递
- 和操作系统、输入输出设备相关的其他接口
64 什么是垃圾,为什么要垃圾回收
- 不需要再被引用或者不能被引用(不可达)的数据
- 减轻了人为出错,优化了内存管理提高内存利用率,保障程序稳定运行
65 什么是可达性,有哪些操作会对可达性产生影响
改变可达对象集合的操作
- 对象分配:返回一个指向新存储块的引用
- **参数传递/返回值:**对象引用从实参传递到形参,从返回值传递给调用者
- 引用赋值: v 的引用被复制到 u中, u 中原有引用丢失;使 u 原来指向的对象变得不可达,并递归使得更多对象变的不可达。
- 过程返回: 活动记录出栈,局部变量消失,根集变小,使一些对象变得不可达
66 简述活动记录的布局设计原则
- 调用者和被调用者之间传递的值放在被调用者活动记录的开始位置
- 固定长度的项(控制链、访问链、机器状态字段) 放在中间位置
- 早期不知道大小的项在活动记录尾部
- 栈顶指针(top_sp) 通常指向固定长度字段的末端


简述活动记录的布局设计原则
- 调用者和被调用者之间传递的值放在被调用者活动记录的开始位置
- 固定长度的项(控制链、访问链、机器状态字段) 放在中间位置
- 早期不知道大小的项在活动记录尾部
- 栈顶指针(top_sp) 通常指向固定长度字段的末端

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









