







一、Series的作用及使用
1、定义
在pandas库里面Series可以看作是一个一维的数据结构,类似于带标签的数组。它可以看作是一个有序的键值对集合,存在对应索引(index)的数据值(data)。
2、作用
用于存储单一维度的数据结构,时间序列、列表或一列数据值,支持索引切片和数据运算,和DataFrame一样支持多种数据类型(整型,浮点型,字符串等)
3、Series方法携带参数
pandas.Series(data,index,dtype,name,copy)
1、data:表示数据,支持Python字典、多维数组、标量值(即只有大小,没有方向的量。也就是说,只是一个数值,如s=pd.Series(5))。
2、index:表示行标签(索引)。 返回值:Series对象。
3、name表示指定的表名
4、dtype表示表的数据类型
5、用于复制数据
4、代码书写
可以使用字典,列表方式创建
- 字典创建
import pandas as pd # 列表创建Series s1=pd.Series([1,2,3,4,5],index=['a','b','c','d','e']) print(s1) # a 1 # b 2 # c 3 # d 4 # e 5 # dtype: int64
- 列表创建
import pandas as pd # 字典创建Series s2=pd.Series({'a':1,'b':2,'c':3,'d':4,'e':5}) print(s2) # a 1 # b 2 # c 3 # d 4 # e 5 # dtype: int64
二、DataFrame的作用及使用
1、定义
在pandas库里面,DataFrame类似于一个二维的表格,像Excel表格一样,又可当作是多个Series合并在一起的样子是pandas的核心数据结构,蕴含丰富的数据处理功能,对于数据可视化功能操作给予很大帮助。
2、作用和特点
-
二维结构:
DataFrame是一个二维表格,可以被看作是一个 Excel 电子表格或 SQL 表,具有行和列。可以将其视为多个Series对象组成的字典。 -
列的数据类型: 不同的列可以包含不同的数据类型,例如整数、浮点数、字符串或 Python 对象等。
-
索引:
DataFrame可以拥有行索引和列索引,类似于 Excel 中的行号和列标。 -
大小可变:可以添加和删除列,类似于 Python 中的字典。
-
自动对齐:在进行算术运算或数据对齐操作时,
DataFrame会自动对齐索引。 -
处理缺失数据:
DataFrame可以包含缺失数据,Pandas 使用NaN(Not a Number)来表示。 -
数据操作:支持数据切片、索引、子集分割等操作。
-
时间序列支持:
DataFrame对时间序列数据有特别的支持,可以轻松地进行时间数据的切片、索引和操作。 -
丰富的数据访问功能:通过
.loc、.iloc和.query()方法,可以灵活地访问和筛选数据。 -
灵活的数据处理功能:包括数据合并、重塑、透视、分组和聚合等。
-
数据可视化:虽然
DataFrame本身不是可视化工具,但它可以与 Matplotlib 或 Seaborn 等可视化库结合使用,进行数据可视化。 -
高效的数据输入输出:可以方便地读取和写入数据,支持多种格式,如 CSV、Excel、SQL 数据库和 HDF5 格式。
-
描述性统计:提供了一系列方法来计算描述性统计数据,如
.describe()、.mean()、.sum()等。 -
灵活的数据对齐和集成:可以轻松地与其他
DataFrame或Series对象进行合并、连接或更新操作。 -
转换功能:可以对数据集中的值进行转换,例如使用
.apply()方法应用自定义函数。 -
滚动窗口和时间序列分析:支持对数据集进行滚动窗口统计和时间序列分析。
3、DataFrame方法携带参数
pandas.DataFrame(data,index,columns,dtype,copy)
1、data:表示数据,可以是ndarray数组、Series对象、列表、字典等。
2、index:表示行标签(索引)。
3、columns:列标签(索引)。
4、dtype:每一列数据的数据类型,其与Python数据类型有所不同,如object数据类型对应的是Python的字符型。详细的看最后课件中的图解。
5、copy:用于复制数据。 返回值:DataFrame。
4、代码书写
- 字典创建形式
import pandas as pd data=[[100,101,102],[90,91,92],[80,81,82]] index1=[1,2,3] value1=['语文','数学','英语'] df=pd.DataFrame(data=data,index=index1,columns=value1) # 输出结果 # 语文 数学 英语 #1 100 101 102 #2 90 91 92 #3 80 81 82
- 数组创建使用numpy库的array方法
# 数组创建Series s3=pd.Series(np.arange(5),index=['a','b','c','d','e']) print(s3) #输出 #a 0 #b 1 #c 2 #d 3 #e 4 -
字典形式创建
data_card={ '语文':[90,100,110], '数学':[100,105,110], '英语':[105,110,115] } df=pd.DataFrame(data=data_card,index=['小明','小红','王强']) print(df) # 语文 数学 英语 # 小明 90 100 105 # 小红 100 105 110 # 王强 110 110 115
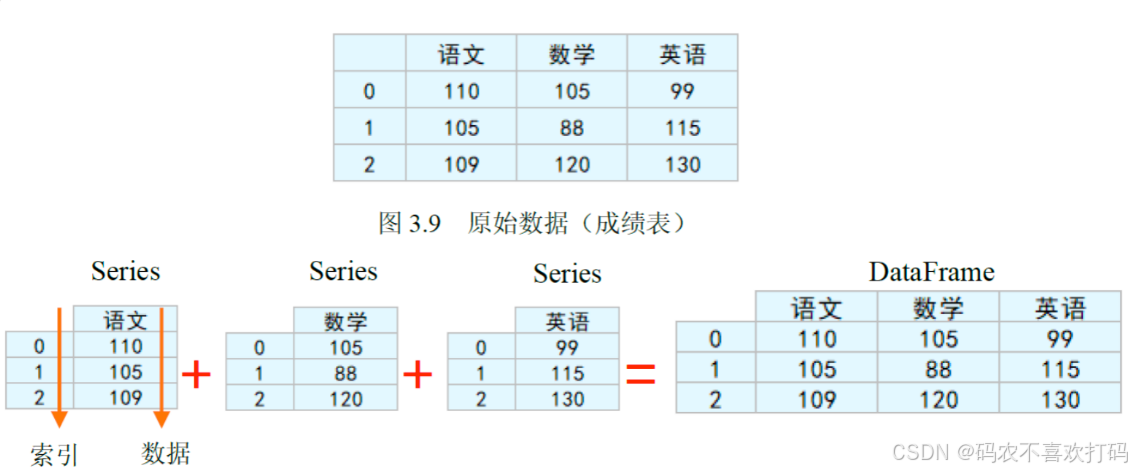
三、图解表示
四、总结
DataFrame和Series都是Pandas库的两种核心数据结构不同的是Series是单一列数据的容器,而DataFrame是多列、多维数据的核心结构,二者共同构建了Pandas灵活的数据处理能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









