







目录
一、算法简介
k-近邻(kNN,k Nearest Neignbor)算法是数据挖掘分类技术中最简单的方法之一,最初由 Cover和Hart于1968年提出,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
该算法的思想非常简单直观:如果一个样本在特征空间中的k个最近邻的样本大多数属于某一个类别,则该样本也属于这个类别。
二、算法流程
计算已知训练集中的点与当前点之间的距离
按照距离大小递增排序
选取与当前点距离最近的k个点
统计这k个点对应类别出现的频率
选取频率最高的类别作为预测结果
三、算法实战
我们用一个经典的海伦约会预测问题来详细了解实施kNN算法的基本过程。
问题引入
海伦一直使用在线约会网站寻找适合自己的约会对象。她曾交往过三种类型的人:
- 不喜欢的人
- 一般喜欢的人
- 非常喜欢的人
这些人包含以下三种特征
每年获得的飞行常客里程数
玩视频游戏所耗时间百分比
每周消费的冰淇淋公升数
该网站现在需要尽可能向海伦推荐她喜欢的人,需要我们设计一个分类器,根据用户的以上三种特征,识别出是否该向海伦推荐。
问题分析
根据问题,我们可知,样本特征个数为3,分别为飞行里程数、玩游戏耗时百分比、消费冰淇淋公升数,样本标签为三类,分别为不喜欢、一般喜欢、非常喜欢。现需要使用k近邻算法实现将一个待分类样本的三个特征值输入程序后,能够识别预测该样本的类别,并且将该类别输出。
问题解决
我们先来看一下数据集,第一二三列依次表示飞行里程数、玩游戏耗时百分比、消费冰淇淋公升数这三个特征值,第四列是这一组特征值对应的标签,didntLike、smallDoses、largeDoses依次表示不喜欢、一般喜欢、非常喜欢。
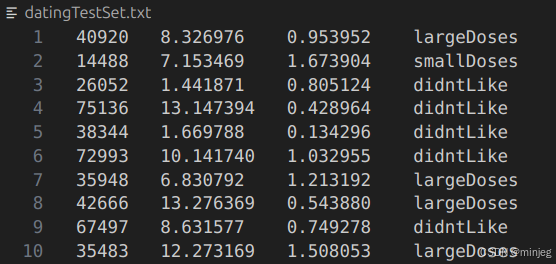
加载数据集
首先,我们要先把数据集读入内存,以遍后续操作。我们定义一个函数load_data(filepath),其中filepath为数据集的文件路径,在函数中,我们遍历该文件的每一行,依次将特征向量加入data,标签加入labels,最后返回结果。
def load_data(filepath):
data=[]
labels=[]
with open(filepath,'r') as f:
for line in f:
items=line.strip().split('\t')
data.append(list(map(float,items[:3])))
labels.append(items[-1])
return np.array(data),np.array(labels)划分数据集
然后,我们需要把数据集按照一定比例随机划分为训练集和测试集。我们定义一个函数split_dataset(data,labels,test_radio),其中data为特征向量集,labels为标签集,test_radio为测试集比例。先获取数据集的长度为num,然后使用np.random.permutation函数获得0~num-1的随机序列indexes,而后计算测试集长度test_size,我们把indexes的前text_size项作为测试集对应的索引,其余部分作为训练集对应的索引,最后依次返回训练集的特征向量集、训练集的标签集、测试集的特征向量集、测试集的标签集。
def split_dataset(data,labels,test_radio):
num=data.shape[0]
indexes=np.random.permutation(num)
test_size=int(num*test_radio)
test_indexes=indexes[:test_size]
train_indexes=indexes[test_size:]
return data[train_indexes],labels[train_indexes],data[test_indexes],labels[test_indexes]归一化特征值
我们应当认为每个特征对结果的影响力是相同的。但由于每个特征的数据范围各不相同,会导致各特征的影响力各不相同、差值较大的数据影响力较大,例如该问题中的每年飞行里程数,因此我们要对特征值进行归一化。什么是归一化?归一化就是通过一定的方法把每个特征值映射到区间[0,1]。归一化的方法有很多,在本文中,我们使用最小最大值归一化法。
我们设特征向量min(x)的每一项表示对应特征列的最小值,max(x)的每一项表示对应特征列的最大值,和
分别表示归一化前后的特征向量,那么有
。
根据以上即可编写出归一化函数normalize(train_data,test_data),返回归一化后的数据集。
def normalize(train_data,test_data):
min_vals=train_data.min(axis=0)
max_vals=train_data.max(axis=0)
ranges=max_vals-min_vals
ranges[ranges==0]=1
train_norm=(train_data-min_vals)/ranges
test_norm=(test_data-min_vals)/ranges
return train_norm,test_norm实现 kNN分类器
万事俱备后,我们可以开始实现kNN算法了。按照算法过程,我们只需计算训练集中所有点到当前点的距离,取距离最小的k个,即k近邻,然后统计这k个点中哪个类别的频率最高,并作为预测结果返回。首先我们要确定使用距离度量方法,例如欧氏距离、曼哈顿距离、闵可夫斯基距离。在本文中,我们采用欧氏距离,设特征向量,则欧氏距离
。根据以上即可编写出classify函数,返回预测结果。
def classify(train_data,train_labels,test_sample,k):
distances=np.sqrt(np.sum((train_data-test_sample)**2,axis=1))
distance_labels=list(zip(distances,train_labels))
distance_labels.sort(key=lambda x:x[0])
k_nearest=distance_labels[:k]
label_counts={}
for distance,label in k_nearest:
label_counts[label]=label_counts.get(label,0)+1
sorted_labels=sorted(label_counts.items(),key=lambda x:x[1],reverse=True)
return sorted_labels[0][0]评估模型
完成以上操作后,我们便可以开始使用测试集评估模型预测的准确率。具体的,对测试集中的每个样本,使用classify函数得到预测结果,与实际的所属类别进行对比,统计预测正确的频率。
def evaluate(train_data,train_labels,test_data,test_labels,k):
right_count=0
for i in range(len(test_data)):
if(classify(train_data,train_labels,test_data[i],k)==test_labels[i]):
right_count+=1
accuracy=100*right_count/len(test_data)
return accuracy测试模型
最后,我们进行模型的测试。不妨取k=3,测试集比例test_radio=0.1。
if __name__=="__main__":
k=3
test_radio=0.1
data,labels=load_data("datingTestSet.txt")
train_data,train_labels,test_data,test_labels=split_dataset(data,labels,test_radio)
train_norm,test_norm=normalize(train_data,test_data)
label_map={"didntLike":"不喜欢","smallDoses":"一般喜欢","largeDoses":"非常喜欢"}
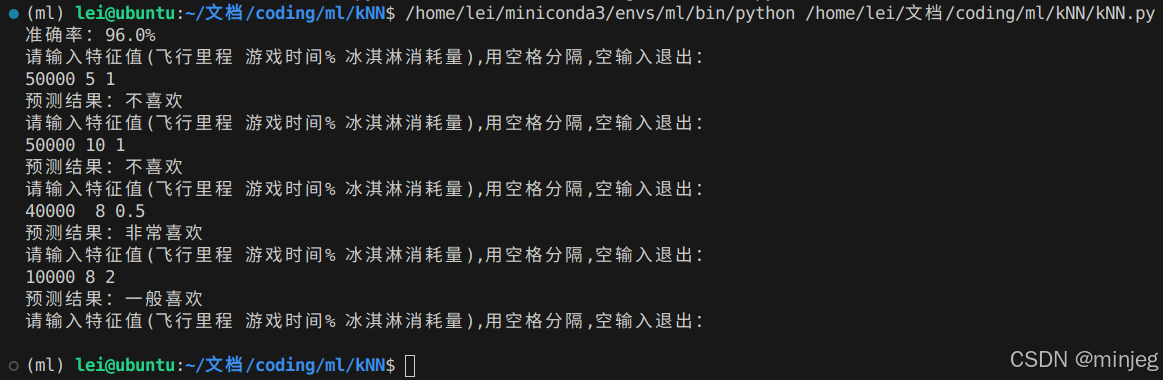
print(f"准确率:{evaluate(train_norm,train_labels,test_norm,test_labels,k)}%",)
while True:
print("请输入特征值(飞行里程 游戏时间% 冰淇淋消耗量),用空格分隔,空输入退出:")
inputs=input()
if(inputs==""):
break
features=np.array(list(map(float,inputs.split())))
if(len(features)!=3):
print("格式错误")
continue
print(f"预测结果:{label_map[classify(train_data,train_labels,features,k)]}")运行效果如图:
研究k值对准确率的影响
我们遍历所有可能的k值,依次得到它们对应的准确率,并使用matplotlib.pyplot绘制出准确率关于k的图像。由于每次划分数据集都是随机的,得到的数据仅供参考。
def try_all_k(train_data,train_labels,test_data,test_labels):
num=len(train_data)
accuracies=np.zeros(shape=num)
for k in range(num):
accuracies[k]=evaluate(train_data,train_labels,test_data,test_labels,k+1)
ks=list(range(1,num+1))
plt.plot(ks,accuracies,marker='o',linestyle='-')
plt.xlabel("k",fontsize=12)
plt.ylabel("Accuracy",fontsize=12)
plt.title("kNN Accuracy")
plt.show()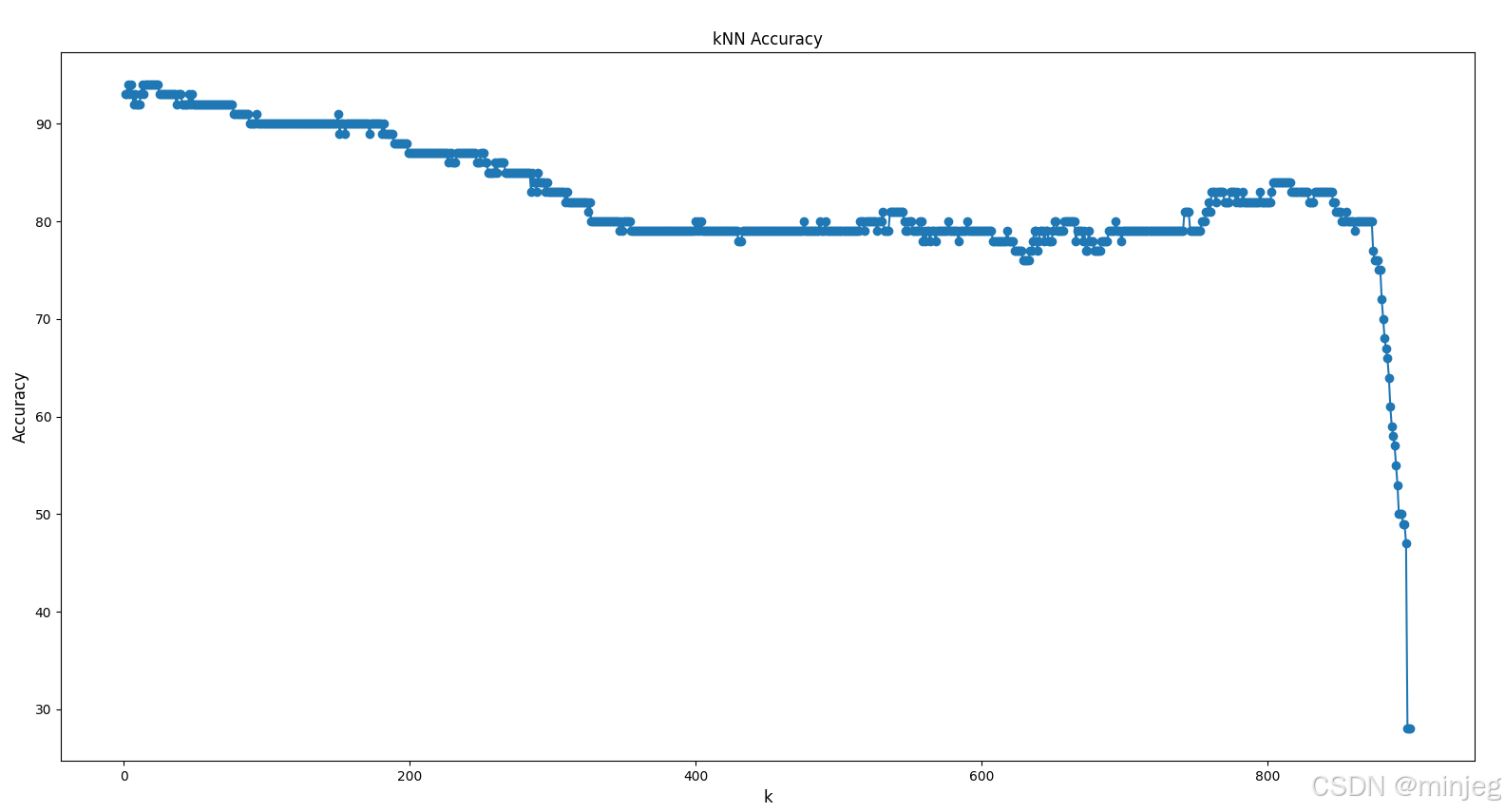
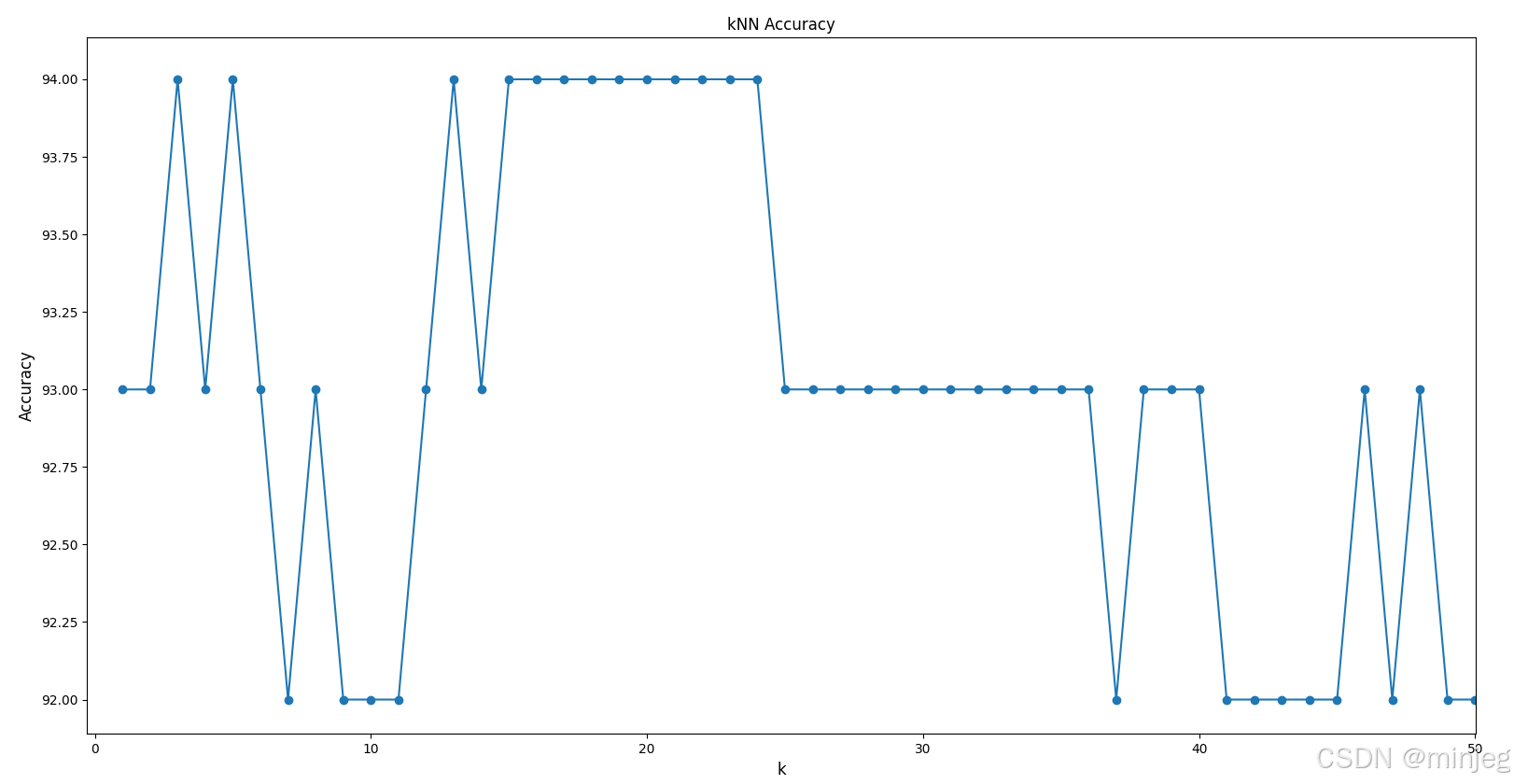
当k值较大时,模型准确率逐步下降;当k值接近训练集总数900时,模型准确率大幅下降。
完整代码
import numpy as np
import matplotlib.pyplot as plt
def load_data(filepath):
data=[]
labels=[]
with open(filepath,'r') as f:
for line in f:
items=line.strip().split('\t')
data.append(list(map(float,items[:3])))
labels.append(items[-1])
return np.array(data),np.array(labels)
def split_dataset(data,labels,test_radio):
num=data.shape[0]
indexes=np.random.permutation(num)
test_size=int(num*test_radio)
test_indexes=indexes[:test_size]
train_indexes=indexes[test_size:]
return data[train_indexes],labels[train_indexes],data[test_indexes],labels[test_indexes]
def normalize(train_data,test_data):
min_vals=train_data.min(axis=0)
max_vals=train_data.max(axis=0)
ranges=max_vals-min_vals
ranges[ranges==0]=1
train_norm=(train_data-min_vals)/ranges
test_norm=(test_data-min_vals)/ranges
return train_norm,test_norm
def classify(train_data,train_labels,test_sample,k):
distances=np.sqrt(np.sum((train_data-test_sample)**2,axis=1))
distance_labels=list(zip(distances,train_labels))
distance_labels.sort(key=lambda x:x[0])
k_nearest=distance_labels[:k]
label_counts={}
for distance,label in k_nearest:
label_counts[label]=label_counts.get(label,0)+1
sorted_labels=sorted(label_counts.items(),key=lambda x:x[1],reverse=True)
return sorted_labels[0][0]
def evaluate(train_data,train_labels,test_data,test_labels,k):
right_count=0
for i in range(len(test_data)):
if(classify(train_data,train_labels,test_data[i],k)==test_labels[i]):
right_count+=1
accuracy=100*right_count/len(test_data)
return accuracy
def try_all_k(train_data,train_labels,test_data,test_labels):
num=len(train_data)
accuracies=np.zeros(shape=num)
for k in range(num):
accuracies[k]=evaluate(train_data,train_labels,test_data,test_labels,k+1)
ks=list(range(1,num+1))
plt.plot(ks,accuracies,marker='o',linestyle='-')
plt.xlabel("k",fontsize=12)
plt.ylabel("Accuracy",fontsize=12)
plt.title("kNN Accuracy")
plt.show()
if __name__=="__main__":
k=3
test_radio=0.1
data,labels=load_data("datingTestSet.txt")
train_data,train_labels,test_data,test_labels=split_dataset(data,labels,test_radio)
train_norm,test_norm=normalize(train_data,test_data)
# try_all_k(train_norm,train_labels,test_norm,test_labels)
label_map={"didntLike":"不喜欢","smallDoses":"一般喜欢","largeDoses":"非常喜欢"}
print(f"准确率:{evaluate(train_norm,train_labels,test_norm,test_labels,k)}%",)
while True:
print("请输入特征值(飞行里程 游戏时间% 冰淇淋消耗量),用空格分隔,空输入退出:")
inputs=input()
if(inputs==""):
break
features=np.array(list(map(float,inputs.split())))
if(len(features)!=3):
print("格式错误")
continue
print(f"预测结果:{label_map[classify(train_data,train_labels,features,k)]}")
















 1418
1418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









