






编译过程
预处理(宏替换、头文件展开、删除注释、条件编译)xx.i
编译阶段(语法检测)xx.s
汇编()xx.o
链接()xx.exe
一、基础语法
1、变量的声明与赋值
1.1 声明
格式:
数据类型 变量名; //声明变量的语句必须以分号结尾
举例:
int width,height;
// 等同于
int width;
int height;1.2 赋值
变量声明时,就为它分配内存空间,但是不会清除内存里面原来的值。这导致声明变量以后,变量会是一个随机的值。所以,变量一定要赋值以后才能使用。
int age; //变量的声明
age = 18; //变量的赋值
变量的声明和赋值,也可以写在一行。
int age = 18;
多个相同类型变量的赋值,可以写在同一行。
int a = 1, b = 2;
int a, b;
a = 1;
b = (a = 2 * a);
int a, b, c, x, y;
a = b = c = x = y = 10; //连续赋值注意:声明变量以后,不用忘记初始化赋值!定义变量时编译器并不一定清空了这块内存,它的值可能是无效的数据,运行程序,会异常退出。
2、变量的作用域(scope)
-
变量的作用域:其定义所在的一对{ }内。
-
变量只有在其
作用域内才有效。出了作用域,变量不可以再被调用。 -
同一个作用域内,不能定义重名的变量。
-
C 语言的变量作用域主要有两种:文件作用域(file scope)和块作用域(block scope)。
文件作用域(file scope)指的是,在源码文件顶层声明的变量,从声明的位置到文件结束都有效。
块作用域(block scope)指的是由大括号( {} )组成的代码块,它形成一个单独的作用域。凡是在块作用域里面声明的变量,只在当前代码块有效,代码块外部不可见。
二、数据类型
1、整数类型
-
C语言规定了如下的几类整型:短整型(short)、整型(int)、长整型(long)、更长的整型(long long)
-
每种类型都可以被 signed 和unsigned 修饰。其中,
-
使用
signed 修饰,表示该类型的变量是带符号位的,有正负号,可以表示负值。默认是signed。 -
使用
unsigned 修饰,表示该类型的变量是不带符号位的,没有有正负号,只能表示零和正整数。
-
-
bit(位):计算机中的最小存储单位。
byte(字节):计算机中基本存储单元。
1byte = 8bit
| 类型 | 修饰符 | 占用空间 | 取值范围 |
|---|---|---|---|
| short [int] | signed | 2个字节(=16位) | -32768 ~ 32767 (-$2^{15}$ ~ $2^{15}$-1) |
| short [int] | unsigned | 2个字节(=16位) | 0 ~ 65535 (0 ~ $2^{16}$-1) |
| int | signed | 通常4个字节 | -2147483648 ~ 2147483647 (-$2^{31}$ ~ $2^{31}$-1) |
| int | unsigned | 通常4个字节 | 0 ~ 4294967295 (0 ~ $2^{32}$-1) |
| long [int] | signed | 4个或8个字节 | 4字节时:-2147483648 ~ 2147483647 (-$2^{31}$ ~ $2^{31}$-1) |
| long [int] | unsigned | 4个或8个字节 | 4字节时:-0 ~ 4294967295 (0 ~ $2^{32}$-1) |
long long int是C99新增的:
| 类型 | 修饰符 | 占用空间 | 取值范围 |
|---|---|---|---|
| long long [int] | signed | 8个字节(=64位) | -9223372036854775808~ 9223372036854775807(-$2^{63}$ ~ $2^{63}$-1) |
| long long [int] | unsigned | 8个字节(=64位) | 0 ~ 18446744073709551615(0 ~ $2^{64}$-1) |
说明:不同计算机的 int 类型的大小是不一样的。比较常见的是使用4个字节(32位)存储一个 int 类型的值,具体情况如下:
| 类型 | 16位编译器 | 32位编译器 | 64位编译器 |
|---|---|---|---|
| short int | 2字节 | 2字节 | 2字节 |
| int | 2字节 | 4字节 | 4字节 |
| unsigned int | 2字节 | 4字节 | 4字节 |
| long | 4字节 | 4字节 | 8字节 |
| unsigned long | 4字节 | 4字节 | 8字节 |
| long long | 8字节 | 8字节 | 8字节 |
说明:
最常用的整型类型为:int类型。
整数型常量,默认为int类型。
编译器将一个整数字面量指定为 int 类型,但是如果希望将其指定为 long 类型,需要在该字面量末尾加上后缀 l 或 L ,编译器会把这个字面量的类型指定为 long 。
long x = 123L; //或者写成 123l 如果希望字面量指定为long long类型,则后缀以ll或LL结尾。
long long y = 123LL;可移植类型
C 语言的整数类型(short、int、long)在不同计算机上,占用的字节宽度可能是不一样的,无法提前知道它们到底占用多少个字节。程序员有时控制准确的字节宽度,这样的话,代码可以有更好的可移植性,头文件 stdint.h 创造了一些新的类型别名。
int8_t :8位有符号整数
int16_t :16位有符号整数
int32_t :32位有符号整数
int64_t :64位有符号整数
uint8_t :8位无符号整数
uint16_t :16位无符号整数
uint32_t :32位无符号整数
uint64_t :64位无符号整数
有时候需要查看,当前系统不同整数类型的最大值和最小值,C 语言的头文件 limits.h 提供了相应的常量。比如:INT_MIN 代表 signed int 类型的最小值 -2147483648, INT_MAX 代表 signed int 类型的最大值 2147483647。
SCHAR_MIN , SCHAR_MAX :signed char 的最小值和最大值。
SHRT_MIN , SHRT_MAX :short 的最小值和最大值。
INT_MIN , INT_MAX :int 的最小值和最大值。
LONG_MIN , LONG_MAX :long 的最小值和最大值。
LLONG_MIN , LLONG_MAX :long long 的最小值和最大值。
UCHAR_MAX :unsigned char 的最大值。
USHRT_MAX :unsigned short 的最大值。
UINT_MAX :unsigned int 的最大值。
ULONG_MAX :unsigned long 的最大值。
ULLONG_MAX :unsigned long long 的最大值
2、浮点类型
浮点型变量,也称为实型变量,用来存储小数数值的。因为32位浮点数提供的精度或者数值范围还不够,C 语言又提供了另外两种更大的浮点数类型。
在C语言中,浮点型变量分为三种:单精度浮点型(float)、双精度浮点型(double)、长双精度浮点型(long double)。
| 类型 | 占用空间 | 取值范围 |
|---|---|---|
| float | 4个字节 (=32位) | $-1.410^{-45}$ ~ $-3.410^{+38}$,$1.410^{-45}$ ~ $3.410^{+38}$ |
| double | 8个字节 (=64位) | $-4.910^{-324}$ ~ $-1.710^{+308}$,$4.910^{-324}$ ~ $1.710^{+308}$ |
| long double | 12个字节(=96位) | 太大了... |
其中,
| 类型 | 16位编译器 | 32位编译器 | 64位编译器 |
|---|---|---|---|
| float | 4字节 | 4字节 | 4字节 |
| double | 8字节 | 8字节 | 8字节 |
C语言的第3种浮点类型是long double,以满足比double类型更高的精度要求。不过,C只保证long double类型至少与double类型的精度相同。
浮点型变量不能使用signed或unsigned修饰符。
最常用的浮点类型为:double 类型,因为精度比float高。
浮点型常量,默认为 double 类型。
关于后缀:
对于浮点数,编译器默认指定为 double 类型,如果希望指定为float类型,需要在小数后面添加后缀 f或F;如果希望指定为long double类型,需要在小数后面添加后缀 l或L。
float x = 3.14f;
double x = 3.14;
long double x = 3.14L;C 语言允许使用科学计数法表示浮点数,使用字母 e 来分隔小数部分和指数部分。注意,e 的前后,不能存在空格。
double x = 123.456e+3; // 123.456 x 10^3
// 等同于
double x = 123.456e3;科学计数法的小数部分如果是 0.x 或 x.0 的形式,那么 0 可以省略。
3、字符类型
C语言中,使用 char 关键字来表示字符型,用于存储一个单一字符。
字符型变量赋值时,需要用一对英文半角格式的单引号('')把字符括起来。
每个字符变量,在16位、32位或64位编译器中都是占用 1 个字节(=8位)。
表示方式:ASCII字符
char c = 'A'; //为一个char类型的变量赋值字符'A'ASCII 字符代码表:
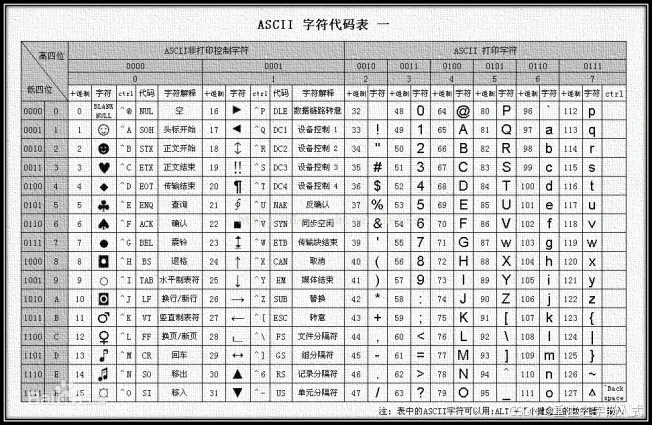
表示方式:使用转义字符
单引号本身也是一个字符,如果要表示这个字符常量,必须使用反斜杠转义。
char t = '\'';char还可以用来表示转义字符。比如:
| 字符形式 | 含义 |
|---|---|
\n | 换行符(光标移动到下行行首) |
\t | 水平制表符,光标移到下一个Tab位置 |
\' | 单引号字符 ' |
\" | 双引号字符 " |
\\ | 反斜杠字符 ’\’ |
\r | 回车符,光标移到本行开头 |
\0 | null 字符,代表没有内容。注意,这个值不等于数字0。 |
\b | 退格键,光标回退一个字符,但不删除字符 |
4、布尔类型
0表示假,非0表示真,C语言中没有bool型,只有C++才有boolean型,也称bool。C语言中一般用“0”表示“假”,用“1”表示“真”。
可以使用是 _Bool 来表示布尔值:
#include <stdio.h>
int main(){
_Bool isTrue = 1;
if(isTrue){
print("是真的呀!");
}
return 0;
}还可以引用头文件 stdbool.h,文件中定义了bool代表_Bool,并且定义了 true 代表 1 、 false 代表 0 。只要加载这个头文件,就可以使用 bool 定义布尔值类型,以及 false 和 true 表示真假。
#include <stdio.h>
#include <stdbool.h>
int main() {
bool isFlag = true;
if (isFlag)
printf("你好毒~~\n");
return 0;
}5、变量间的运算规则
在C语言编程中,经常需要对不同类型的数据进行运算,运算前需要先转换为同一类型,再运算。为了解决数据类型不一致的问题,需要对数据的类型进行转换。
5.1 隐式类型转换
系统自动将字节宽度较小的类型转换为字节宽度较大的数据类型
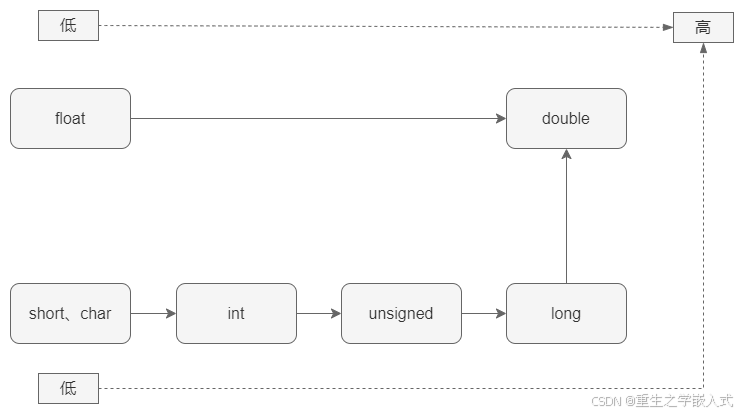
注意:最好避免无符号整数与有符号整数的混合运算。因为这时 C 语言会自动将 signed int 转为unsigned int ,可能不会得到预期的结果。
宽类型赋值给窄类型
字节宽度较大的类型,赋值给字节宽度较小的变量时,会发生类型降级,自动转为后者的类型。这时可能会发生截值(truncation),系统会自动截去多余的数据位,导致精度损失。
例如:
double pi = 3.1415926;
int i = pi; // i 的值为 3编辑器在编译时会直接把小数点后的部分舍去,而不是四舍五入。
5.2 强制类型转换
隐式类型转换中的宽类型赋值给窄类型,编译器是会产生警告的,提示程序存在潜在的隐患。如果非常明确地希望转换数据类型,就需要用到强制(或显式)类型转换。
形式: (类型名称)(变量、常量或表达式)
功能:将“变量、常量或表达式”的运算结果强制转换为“类型名称”所表示的数据类型。
注意:强制类型转换会导致精度损失。
案例:
double x = 3.14;
int y = 10;
int z = (int)x + y; //将变量x的值转换成int后,再与y相加5.3 常量
程序运行时,其值不能改变的量,即为常量。
C语言中的常量分为以下以下几种:
-
字面常量
-
#define 定义的标识符常量
-
const 修饰的常变量
-
枚举常量
定义格式:#define 符号常量名 常量值
定义格式:const 数据类型 常量名 = 常量值;
注意:#define 没有结束符,符号名一般定义时用大写字母表示。const定义的常量有详细的数据类型,而且会在编译阶段进行安全检查,在运行时才完成替换,所以会更加安全和方便。
三、进制
1、禁止分类
-
十进制(decimal)
-
数字组成:0-9
-
进位规则:满十进一
-
C 语言的整数默认都是十进制数
-
-
二进制(binary)
-
数字组成:0-1
-
进位规则:满二进一,以
0b或0B开头
int x = 0b101010; -
-
八进制(octal) : 不经常使用
-
数字组成:0-7
-
进位规则:满八进一,以数字
0开头表示
int a = 012; // 八进制,相当于十进制的10 int b = 017; // 八进制,相当于十进制的15 -
-
十六进制
-
数字组成:0-9,a-f
-
进位规则:满十六进一,以
0x或0X开头表示。此处的 a-f 不区分大小写
int a = 0x1A2B; // 十六进制,相当于十进制的6699 int b = 0X10; // 十六进制,相当于十进制的16 -
2、进制换算举例
| 十进制 | 二进制 | 八进制 | 十六进制 |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 |
| 2 | 10 | 2 | 2 |
| 3 | 11 | 3 | 3 |
| 4 | 100 | 4 | 4 |
| 5 | 101 | 5 | 5 |
| 6 | 110 | 6 | 6 |
| 7 | 111 | 7 | 7 |
| 8 | 1000 | 10 | 8 |
| 9 | 1001 | 11 | 9 |
| 10 | 1010 | 12 | a或A |
| 11 | 1011 | 13 | b或B |
| 12 | 1100 | 14 | c或C |
| 13 | 1101 | 15 | d或D |
| 14 | 1110 | 16 | e或E |
| 15 | 1111 | 17 | f或F |
| 16 | 10000 | 20 | 10 |
3、输出格式
printf() 的进制相关占位符如下(没有二进制的占位符):
-
%d :十进制整数。
-
%o :八进制整数。
-
%x :十六进制整数。
-
%#o :显示前缀 0 的八进制整数。
-
%#x :显示前缀 0x 的十六进制整数。
-
%#X :显示前缀 0X 的十六进制整数。
int x = 100;
printf("dec = %d\n", x); // 100 十进制
printf("octal = %o\n", x); // 144 八进制
printf("hex = %x\n", x); // 64 十六进制
printf("octal = %#o\n", x); // 0144
printf("hex = %#x\n", x); // 0x64
4、进制间的转换
-
计算机数据的存储使用二进制
补码形式存储,并且最高位是符号位。-
正数:
最高位是0 -
负数:
最高位是1
-
-
规定1:正数的补码与反码、原码一样,称为
三码合一 -
规定2:负数的补码与反码、原码不一样:
-
负数的
原码:把十进制转为二进制,然后最高位设置为1 -
负数的
反码:在原码的基础上,最高位(符号位)不变,其余位取反(0变1,1变0) -
负数的
补码:反码+1
-
-
例如:1个字节(8位)
25 ==> 原码 0001 1001 ==> 反码 0001 1001 -->补码 0001 1001
-25 ==>原码 1001 1001 ==> 反码1110 0110 ==>补码 1110 0111
十进制 <--> 二进制 --> 八进制 <--> 二进制 <--> 十六进制
一个字节可以存储的整数范围是多少?
//1个字节:8位
0000 0001 ~ 0111 111 ==> 1~127
1000 0001 ~ 1111 1111 ==> -127 ~ -1
0000 0000 ==>0
1000 0000 ==> -128(特殊规定)=-127-1注意:1000 000 ==> -128 特殊规定
十进制转二进制
十进制转二进制:除2取余的逆
二进制转八进制
每三位一组
111 101 001
---> 7 5 1
二进制转十六进制
每四位一组
1110 0101 0010
---> e 5 2
四、输入输出
1、输出语句
- 输出:将程序的运行结果输出到控制台或终端窗口中
- printf语法格式:
- printf("输出格式符",输出项)
printf("我今年%d岁了\n",age) //%d表示整型占位符
格式化占位符:
| 打印格式 | 对应数据类型 | 含义 |
| %c | char | 字符型,输入的数字按照ASCII码相应转换为对应的字符 |
| %hd | short int | 短整数 |
| %hu | unsigned short | 无符号短整数 |
| %d | int | 接受整数值并将它表示为有符号的十进制整数 |
| %u | unsigned int | 无符号10进制整数 |
| %ld | long | 接受长整数值并将它表示为有符号的十进制整数 |
| %f | float | 单精度浮点数 |
| %lf | double | 双精度浮点数 |
| %e,%E | double | 科学计数法表示的数,此处"e"的大小写代表在输出时用的"e"的大小写 |
| %s | char * | 字符串。输出字符串中的字符直至字符串中的空字符(字符串以'\0‘结尾,这个'\0'即空字符) |
| %p | void * | 以16进制形式输出指针 |
| %o | unsigned int | 无符号8进制整数 |
| %x,%X | unsigned int | 无符号16进制整数,x对应的是abcdef,X对应的是ABCDEF |
补充:
%zu:用于输出 sizeof() 返回值是 size_t类型
size_t类型的无符号整数。
size_t是一个无符号整数类型
2、输入语句
- 输入:接收用户输入的数据的过程
- scanf语法格式:
- scanf("格式化字符串",&变量1,&变量2,......);
- 格式化字符串用于指定输入的数据类型及其格式
- 变量1、变量2等是要读入的变量的地址
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int main() {
int a;
printf("请输入年龄:");
//scanf_s("%d", &a);
scanf("%d", &a); //&a代表变量a的内存地址
printf("5年后您的年龄是:%d", a + 5);
return 0;
}注意使用scanf输入数据时,如果报如下错误:
![]()
这个错误信息提示你的代码中使用了 scanf 函数,这个函数可能存在安全问题,你可以考虑使用 scanf_s 函数来代替,以确保代码的安全性。
解决方法有两种:
1、将scanf改为scanf_s即可
2、在代码的最上行(否则无效)加入:#define _CRT_SECURE_NO_WARNINGS
![]()
3、一般要在scanf(" %d"),%号前面打一个空格,避免缓冲区
五、运算符和流程控制
1、运算符
算数运算符
| 运算符 | 术语 | 示例 | 结果 |
| + | 加 | 10 + 5 | 15 |
| - | 减 | 10 - 5 | 5 |
| * | 乘 | 10 * 5 | 50 |
| / | 除 | 10 / 5 | 2 |
| % | 取模(取余) | 10 % 3 | 1 |
| ++a | 前自增 | a=2; b=++a; | a=3; b=3; |
| a++ | 后自增 | a=2; b=a++; | a=3; b=2; |
| --a | 前自减 | a=2; b=--a; | a=1; b=1; |
| a-- | 后自减 | a=2; b=a--; | a=1; b=2; |
赋值运算符
| 运算符 | 术语 | 示例 | 结果 |
| = | 赋值 | a=2; b=3; | a=2; b=3; |
| += | 加等于 | a=0; a+=2; 等同于 a = a + 2; | a=2; |
| -= | 减等于 | a=5; a-=3; 等同于 a = a - 3; | a=2; |
| *= | 乘等于 | a=2; a*=2; 等同于 a = a * 2; | a=4; |
| /= | 除等于 | a=4; a/=2; 等同于 a = a / 2; | a=2; |
| %= | 模等于 | a=3; a%=2; 等同于 a = a % 2; | a=1; |
比较运算符
| 运算符 | 术语 | 示例 | 结果 |
| == | 相等于 | 4 == 3 | 0 |
| != | 不等于 | 4 != 3 | 1 |
| < | 小于 | 4 < 3 | 0 |
| > | 大于 | 4 > 3 | 1 |
| <= | 小于等于 | 4 | 0 |
| >= | 大于等于 | 4 >= 1 | 1 |
逻辑运算符
| 运算符 | 术语 | 示例 | 结果 |
| ! | 非 | !a | 如果a为假,则!a为真; 如果a为真,则!a为假。 |
| && | 与 | a && b | 如果a和b都为真,则结果为真,否则为假。 |
| || | 或 | a || b | 如果a和b有一个为真,则结果为真,二者都为假时,结果为假。 |
位运算符
常见的位运算符号有&、|、^、~、>>、
| 运算符 | 术语 | 示例 | 结果 |
| & | 按位与运算 | 011 & 101 | 2个都为1才为1,结果为001 |
| | | 按位或运算 | 011 | 101 | 有1个为1就为1,结果为111 |
| ^ | 按位异或运算 | 011 ^ 101 | 不同的为1,结果为110 |
| ~ | 取反运算 | ~011 | 100 |
| << | 左移运算 | 1010 | 10100 |
| >> | 右移运算 | 1010 >> 1 | 0101 |
条件运算符
-
条件运算符格式(三元运算):
(条件表达式)? 表达式1:表达式2sizeof运算符
sizeof 运算符:sizeof(参数)
-
参数可以是
数据类型的关键字,也可以是变量名或某个具体的值。 -
返回某种数据类型或某个值占用的字节数量。
举例
// 参数为数据类型
int x = sizeof(int); //通常是 4 或 8
// 参数为变量
int i;
sizeof(i); //通常是 4 或 8
// 参数为数值
sizeof(3.14); //浮点数的字面量一律存储为double类型,故返回 8运算符的优先级
- 不同的运算符默认具备不同的优先级,符号较多不用记,现用现查就可以。
- 当无法确定谁的优先级高时,加一个小括号就解决了。
| 优先级 | 运算符 | 名称或含义 | 使用形式 | 结合方向 | 说明 |
| 1 | [] | 数组下标 | 数组名[常量表达式] | 左到右 | -- |
| () | 圆括号 | (表达式)/函数名(形参表) | -- | ||
| . | 成员选择(对象) | 对象.成员名 | -- | ||
| -> | 成员选择(指针) | 对象指针->成员名 | -- | ||
| 2 | - | 负号运算符 | -表达式 | 右到左 | 单目运算符 |
| ~ | 按位取反运算符 | ~表达式 | |||
| ++ | 自增运算符 | ++变量名/变量名++ | |||
| -- | 自减运算符 | --变量名/变量名-- | |||
| * | 取值运算符 | *指针变量 | |||
| & | 取地址运算符 | &变量名 | |||
| ! | 逻辑非运算符 | !表达式 | |||
| (类型) | 强制类型转换 | (数据类型)表达式 | -- | ||
| sizeof | 长度运算符 | sizeof(表达式) | -- | ||
| 3 | / | 除 | 表达式/表达式 | 左到右 | 双目运算符 |
| * | 乘 | 表达式*表达式 | |||
| % | 余数(取模) | 整型表达式%整型表达式 | |||
| 4 | + | 加 | 表达式+表达式 | 左到右 | 双目运算符 |
| - | 减 | 表达式-表达式 | |||
| 5 | << | 左移 | 变量 | 左到右 | 双目运算符 |
| >> | 右移 | 变量>>表达式 | |||
| 6 | > | 大于 | 表达式>表达式 | 左到右 | 双目运算符 |
| >= | 大于等于 | 表达式>=表达式 | |||
| < | 小于 | 表达式 | |||
| <= | 小于等于 | 表达式 | |||
| 7 | == | 等于 | 表达式==表达式 | 左到右 | 双目运算符 |
| != | 不等于 | 表达式!= 表达式 | |||
| 8 | & | 按位与 | 表达式&表达式 | 左到右 | 双目运算符 |
| 9 | ^ | 按位异或 | 表达式^表达式 | 左到右 | 双目运算符 |
| 10 | | | 按位或 | 表达式|表达式 | 左到右 | 双目运算符 |
| 11 | && | 逻辑与 | 表达式&&表达式 | 左到右 | 双目运算符 |
| 12 | || | 逻辑或 | 表达式||表达式 | 左到右 | 双目运算符 |
| 13 | ?: | 条件运算符 | 表达式1? 表达式2: 表达式3 | 右到左 | 三目运算符 |
| 14 | = | 赋值运算符 | 变量=表达式 | 右到左 | -- |
| /= | 除后赋值 | 变量/=表达式 | -- | ||
| *= | 乘后赋值 | 变量*=表达式 | -- | ||
| %= | 取模后赋值 | 变量%=表达式 | -- | ||
| += | 加后赋值 | 变量+=表达式 | -- | ||
| -= | 减后赋值 | 变量-=表达式 | -- | ||
| <<= | 左移后赋值 | 变量 | -- | ||
| >>= | 右移后赋值 | 变量>>=表达式 | -- | ||
| &= | 按位与后赋值 | 变量&=表达式 | -- | ||
| ^= | 按位异或后赋值 | 变量^=表达式 | -- | ||
| |= | 按位或后赋值 | 变量|=表达式 | -- | ||
| 15 | , | 逗号运算符 | 表达式,表达式,… | 左到右 | -- |
2、流程控制
顺序结构
if...else if...else if...else...
分支结构
switch(){
case xx: xxx; break;
case xx: xxx; break;
case xx: xxx; break;
default: xxx;
}
循环结构
while(){
}
do{
}while();
for(xx;xx;xx);
goto关键字
小结:
从理论上 goto语句是没有必要的,实践中没有goto语句也可以很容易的写出代码。使用goto反而容易造成程序流程的混乱,致使程序容易出错。故建议不要轻易使用。
六、数组(*)
1、数组概念
-
数组(Array),是多个
相同类型数据按一定顺序排列的集合,并使用一个名字命名,并通过编号的方式对这些数据进行统一管理。 -
数组中的概念
-
数组名
-
下标(或索引、index)
-
元素
-
数组的长度
-
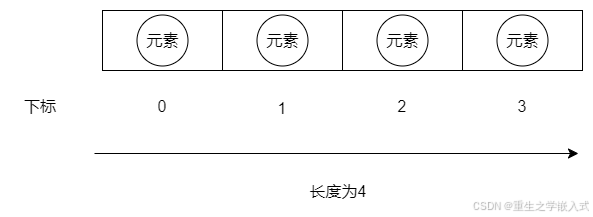
数组的特点:
-
数组中的元素在内存中是依次紧密排列的,有序的。
-
创建数组对象会在内存中开辟一整块
连续的空间。占据的空间的大小,取决于数组的长度和数组中元素的类型。 -
我们可以直接通过下标(或索引)的方式调用指定位置的元素,速度很快。
-
数组,一旦初始化完成,其长度就是确定的。数组的
长度一旦确定,就不能修改。 -
数组名中引用的是这块连续空间的首地址。
2、数组定义
数组通过变量名后加方括号表示,方括号里面是数组可以容纳的成员数量(即长度)。
int arr[10]; //数组 arr ,里面包含10个成员,每个成员都是 int 类型或
#define NUM 5
int arr[NUM];注意,声明数组时,必须给出数组的大小。
数组的字节长度:
sizeof 运算符会返回整个数组的字节长度。
int arr[5];
printf("数组的字节长度为:%zd\n",sizeof(arr)); //int占4个字节,共20字节数组的长度:
由于数组成员都是同一个类型,每个成员的字节长度都是一样的,所以数组整体的字节长度除以某个数组元素的字节长度,就可以得到数组的成员数量。
//数组中元素的个数:
int arrLen = sizeof(arr) / sizeof(arr[0]);举例:
int a[5];
printf("数组的字节长度为:%zu\n", sizeof(a)); // 20
printf("数组每个元素的字节长度为:%zu\n", sizeof(int)); // 4
printf("数组的长度为:%zu\n", sizeof(a) / sizeof(int)); // 5sizeof 返回值的数据类型是
size_t,所以 sizeof(a) / sizeof(a[0]) 的数据类型也是size_t 。在 printf() 里面的占位符,要用 %zd 或 %zu 。
注意:数组一旦声明/定义了,其长度就固定了,不能动态变化。
3、数组内存
针对于如下代码:
int arr[5] = {1,2,3,4,5};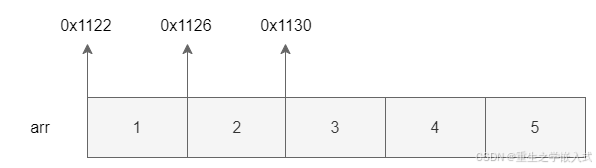
说明:
1)数组名,记录该数组的首地址 ,即 a[0]的地址,数组arr的地址为0x1122。
2)数组的各个元素是连续分布的。
4、注意事项
C 语言规定,数组变量一旦声明,数组名指向的地址就不可更改。因为声明数组时,编译器会自动为数组分配内存地址,这个地址与数组名是绑定的,不可更改。
因此,当数组定义后,再用大括号重新赋值,是不允许的。下面的代码会报错。
举例1:
int nums[4];
nums = {22, 37, 3490, 18}; // 使用大括号赋值时,必须在数组声明时赋值,否则编译时会报错。举例2:
int nums[5] = {1, 2, 3, 4, 5};
nums = {6, 7, 8, 9, 10}; // 报错举例3:
int ints[100];
ints = NULL; //报错举例4:
不能将一个数组名赋值给另外一个数组名。
int a[5] = {1, 2, 3, 4, 5};
// 写法一
int b[5] = a; // 报错
// 写法二
int b[5];
b = a; // 报错上面两种写法都会更改数组 b 的地址,导致报错。
5、变长数组
数组声明的时候,数组长度除了使用常量,也可以使用变量或表达式来指定数组的大小。这叫做变长数组(variable-length array,简称 VLA)。
方式1:
int n = 10;
int arr[n];变长数组的根本特征是数组长度只有运行时才能确定。它的好处是程序员不必在开发时,随意为数组指定一个估计的长度,程序可以在运行时为数组分配精确的长度。
任何长度需要运行时才能确定的数组,都是变长数组。比如,
int i = 10;
int a1[i];
int a2[i + 5];
int a3[i + k];注意:变长数组在C99标准中被引入,在C11标准中被标记为可选特性。某些编译器可能不支持变长数组,或者可能有特定的限制和行为。
方式2:
如果你的编译器版本不支持变长数组,还可以考虑使用动态内存分配(使用malloc()函数 )来创建动态大小的数组。
分配:
int length = 5;
int *arr = (int *)malloc(length * sizeof(int));释放:
free(arr);字符数组和字符串常量的区别
字符数组
字符数组是一个存储字符的数组,可以动态地存储和修改其内容。字符数组的定义和初始化方式如下:
char myArray[10]; // 定义一个包含10个字符的数组
char myArray2[] = "Hello"; // 定义一个字符数组并初始化为 "Hello",
//自动分配足够的空间并包含终止符 '\0'- 可修改性:字符数组的内容可以修改。
- 内存管理:字符数组的内存由程序员管理,包括分配和释放(在C++中,可以使用智能指针或其他内存管理手段)。
- 终止符:C风格字符串以空字符
'\0'结尾,表示字符串的结束。
字符串常量
字符串常量是一个字面量值,通常用于初始化字符数组或在需要字符串字面值的地方使用。字符串常量在编译时被存储在程序的只读数据段中。
const char *myString = "Hello"; // 使用字符串常量初始化指针- 不可修改性:字符串常量的内容是不可修改的。试图修改字符串常量将导致未定义行为,通常是程序崩溃。
- 内存管理:字符串常量的内存由编译器管理,程序员不需要显式地分配或释放。
- 终止符:和字符数组一样,字符串常量也以空字符
'\0'结尾。
示例代码和比较
字符数组示例
#include <stdio.h>
int main() {
char myArray[] = "Hello";
myArray[0] = 'J'; // 修改字符数组的第一个字符
printf("%s\n", myArray); // 输出 "Jello"
return 0;
}字符串常量示例
#include <stdio.h>
int main() {
const char *myString = "Hello";
// myString[0] = 'J'; // 这行代码会导致编译错误或运行时错误,因为字符串常量不可修改
printf("%s\n", myString); // 输出 "Hello"
return 0;
}注意事项
- 修改字符串常量:如前所述,试图修改字符串常量是未定义行为,可能导致程序崩溃。
- 内存占用:字符串常量存储在只读数据段,而字符数组则存储在栈或堆上,根据定义和初始化方式而定。
- 字符数组的大小:定义字符数组时,必须分配足够的空间以存储所有字符和终止符
'\0'。
七、指针(*)
使用指针进行高效访问:
- 指针可以直接访问内存中的数据,避免了复制整个数据结构的开销。
- 在处理大型数据结构时,使用指针可以显著提高性能。
野指针三种情况:
(1)指针未初始化
(2)指针越界访问
(3)指针指向空间的释放后未置为NULL
- 变量的指针。
- 浮点型指针(float*, double*):指向浮点型变量的指针。
- 字符型指针(char*):指向字符或字符串的指针。
- 数组指针与指针数组:
- 数组指针(如int (*p)[10]):指向一个包含10个整数的数组的指针。
- 指针数组(如int* arr[5]):一个数组,其元素是指向整数的指针。
- 函数指针:
- 函数指针(如int (*p)(int, int)):指向一个接收两个整数参数并返回一个整数的函数的指针。
- 特殊指针:
- 字符串常量指针(如char* ps = "abcdef";):指向字符串常量的指针,但应注意字符串常量本身是只读的。
- 指针常量(如int* const p):指针的值(即它指向的地址)不可变。
- 常量指针(如const int* p):指针指向的值(即该地址处的数据)不可变。
- 常指针常量(如const int* const p):既不可修改指向的地址,也不可修改指向地址的值。
- 多级指针:
- 二级指针(如int** p):指向指针的指针。
- 三级指针、四级指针等:以此类推,指向更高级别指针的指针。
- 其他特殊指针:
- 野指针:未初始化的指针或已经释放但未被置为NULL的指针。
- 空指针(NULL或nullptr):不指向任何有效内存地址的指针。
- 结构体和联合体的指针:
- 结构体指针(如struct A* p):指向结构体类型的指针。
- 联合体指针(如union B* q):指向联合体类型的指针。
指针表示数组
printf("%d\n",a[0][0]); //二维数组中元素a[0][0]的值
printf("%p\n",&a[0][0]); //二维数组中元素a[0][0]的值对应的地址
printf("%p\n",a[0]); //二维数组中a[0][0]的地址
printf("%p\n",a); //二维数组中a[0]的地址
printf("%p\n",&a); //二维数组a的地址指针数组和数组指针
指针数组表示存储指针的数组(是数组)
举例:
int main() {
int a, b, c, d, e;
a = 1;
b = 2;
c = 3;
d = 4;
e = 5;
int *arr[] = {&a, &b, &c, &d, &e};//定义一个int类型的指针数组
for(int i = 0;i < 5;i++){
printf("%d ",*arr[i]);
}
return 0;
}数组指针表示指向数组的指针(是指针)
#include <stdio.h>
int main(){
int a = 10;
int *p1 = a;// 指向变量的指针
int arr[10] = {1,2,3,4,5,6};
int *p2 = arr;// 指向数组的指针
} 八、函数
1、函数的分类
角度1:从定义的角度看
●库函数 (c 库实现的)
●自定义函数 (程序员自己实现的函数)
●系统调用 (操作系统实现的函数)
角度2:从参数的角度看
- 有参函数
函数有形参,可以是一个,或者多个,参数的类型随便 完全取决于函数的功能
-
无参函数
函数没有参数,在形参列表的位置写个 void 或什么都不写
角度3:从返回值的角度看
- 带返回值的函数
在定义函数的时候,必须带着返回值类型,在函数体里,必须有 return
如果没有返回值类型,默认返回整型。
注意:如果把函数的返回值类型省略了,默认返回整型
函数内,return后边的内容不会被执行
- 没返回值的函数
在定义函数的时候,函数名字前面加 void
注意:在函数的定义不能嵌套,即不能在一个函数体里定义另外一个函数,所有的函数必须是平行的
2、函数的声明
函数定义的格式:
返回值类型 函数名(数据类型1 形参1,数据类型2 形参2,…,数据类型n 形参n){ 函数体;}举例:
//计算两个整数的最大值,并返回
int getMax(int m,int n) {
return m > n ? m : n;
}声明注意事项
1、C程序中的所有函数都是互相独立的。一个函数并不从属于另一个函数,即函数不能嵌套定义。
2、同一个程序中函数不能重名,函数名用来唯一标识一个函数。即在标准的 C 语言中,并不支持函数的重载。
3、函数的调用
调用函数时,需要传入实际的参数值。如果没有参数,只要在函数名后面加上圆括号就可以了。
举例:
函数的声明
void func() {
printf("这是我的第一个函数!\n");
}函数的调用
int main() {
func();
//func(10); // 报错
//func(10,20); // 报错
return 0; //程序正常结束,默认返回0
}说明:
1、调用时,参数个数必须与函数声明里的参数个数一致,参数过多或过少都会报错。
2、函数间可以相互调用,但不能调用main函数,因为main函数是被操作系统调用的,作为程序的启动入口。反之,main() 函数可以调用其它函数。
3、函数的参数和返回值类型,会根据需要进行自动类型转换
5、关于main()
main()的作用
C 语言规定, main() 是程序的入口函数,即所有的程序一定要包含一个 main() 函数。程序总是从这个函数开始执行,如果没有该函数,程序就无法启动。
main()函数可以调用其它函数,但其它函数不能反过来调用main()函数。main()函数也不能调用自己。
main() 的一般格式
int main() {
//函数体(略)
return 0;
}C 语言约定:返回值 0 表示函数运行成功;返回其它非零整数值,表示运行失败,代码出了问题。系统根据 main() 的返回值,作为整个程序的返回值,确定程序是否运行成功。
注意,C 语言只会对 main() 函数默认添加返回值,对其它函数不会这样做,所以建议书写时保留 return 语句,以便形成统一的代码风格。
6、函数传递机制
值传递
地址传递
递归函数
总结:
1、使用递归函数大大简化了算法的编写。
2、递归调用会占用大量的系统堆栈,内存耗用多,在递归调用层次多时速度要比循环
慢的多,所以在使用递归时要慎重。3、在要求高性能的情况下尽量避免使用递归,递归调用既
花时间又耗内存。考虑使用循环迭代。
九、复合结构(结构体和共合体)
1、结构体声明
结构体必须写在函数声明上面
构建一个结构体类型的一般格式:
struct 结构体名{
数据类型1 成员名1; //分号结尾
数据类型2 成员名2;
……
数据类型n 成员名n;
}; //注意最后有一个分号typedef struct 结构体名{
数据类型1 成员名1; //分号结尾
数据类型2 成员名2;
……
数据类型n 成员名n;
}新结构类型名; 2、结构体内存
结构体内存对齐
确定变量位置:只能放在自己类型整数倍的内存地址上
最后一个补位:结构体的总大小,是最大类型的整数倍
struct num
{
double a; 8
char b; 1+3
int c; 4
char d; 1+7
}总共24位
总结:计算时小的数据类型写上面,大的数据类型写下面
3、结构体变量的赋值操作
同类型的结构体变量可以使用赋值运算符( = ),赋值给另一个变量,比如
student1 = student2; //假设student1和student2已定义为同类型的结构体变量这时会生成一个全新的副本。系统会分配一块新的内存空间,大小与原来的变量相同,把每个属性都复制过去,即原样生成了一份数据。
也就是说,结构体变量的传递机制是值传递,而非地址传递。这一点跟数组的赋值不同,使用赋值运算符复制数组,不会复制数据,只是传递地址。
举例:
struct Car {
double price;
char name[30];
} a = {.name = "Audi A6L", .price = 390000.99};
int main() {
struct Car b = a;
printf("%p\n", &a); //结构体a变量的地址 00007ff75a019020
printf("%p\n", &b); //结构体b变量的地址 000000a6201ffcd0
printf("%p\n", a.name); //结构体a变量的成员name的地址 00007ff719199028
printf("%p\n", b.name); //结构体b变量的成员name的地址 000000c2565ffd88
a.name[0] = 'B';
printf("%s\n", a.name); // Budi A6L
printf("%s\n", b.name); // Audi A6L
return 0;
}4、结构体数组
声明方式:
结构体类型 数组名[数组长度];举例:
struct Person{
char name[20];
int age;
};
struct Person pers[3]; //pers是结构体数组名5、结构体指针
结构体指针:指向结构体变量的指针 (将结构体变量的起始地址存放在指针变量中)
具体应用场景:①可以指向单一的结构体变量 ②可以用作函数的参数 ③可以指向结构体数组
定义结构体指针变量格式:
struct 结构体名 *结构体指针变量名;
//int sum;
//int *sum;struct Book {
char title[50];
char author[10];
double price;
};
struct Book *b1;结构体传参
深拷贝:复制一个副本传递
浅拷贝:传递参数为地址


















 659
659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









