






 It is a bit complex to understand what the math works in gradient and backward process. However, it is easier to capture the conception.
It is a bit complex to understand what the math works in gradient and backward process. However, it is easier to capture the conception.
After we import mindspore, we can show how gradient works to change the parameters.
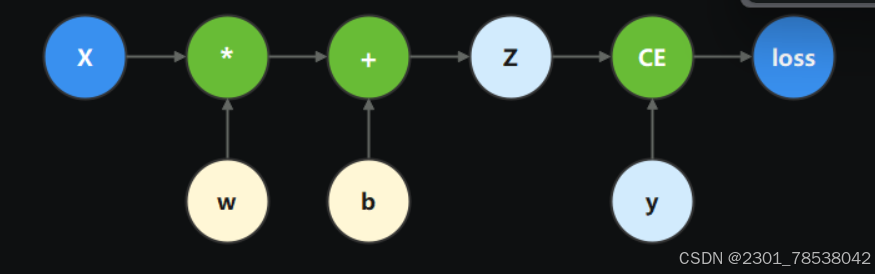 This graph shows what we have (weight w, bias b) and how they are changed according to the prediction z and the label y. x is the input.
This graph shows what we have (weight w, bias b) and how they are changed according to the prediction z and the label y. x is the input.
w = Parameter(Tensor(np.random.randn(5,3), mindspore.float32), name='w')
b = Parameter(Tensor(np.random.randn(3,),mindspore.float32),name='b')we construct calculation function, in code below binary_cross_entropy_with_logits is a loss fn that calculate binary cross entropy loss.
def function(x,y,w,b):
z = ops.matmul(x,w) + b
loss = ops.binary_cross_entropy_with_logits(z,y,ops.ones_like(z),ops.ones_like(z))
return lossloss = function(x,y,w,b)
grad_fn = mindspore.grad(function,(2,3))fucntion is the function we choose to get its gradient, and grad_position ((2,3)) is the position of weight w and bias b.
We sometimes hope to stop getting gradient.
Here we calculate gradient with z.
def function_with_logits(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss, zgrad_fn = mindspore.grad(function_with_logits,(2,3))
grads = grad_fn(x,y,w,b)
print(grads) we get something seemed like a tensor.
we get something seemed like a tensor.
we hope to erase the effect of z, (then our parameters wouldnot change since z is the only process-related tensor we used to backward and change w,b. See the graph above second most)
return loss,ops.stop_gradient(z)using the code to revise return loss,z
then our w, b unchanged after we
grad_fn = mindspore.grad(function_stop_gradient,(2,3)) #the revised function
grads = grad_fn(x,y,w,b)
print(grads) the last line is w,b
the last line is w,b
if we use auxiliary data, we get the same result just like we stop_gradient manually.
grad_fn = mindspore.grad(function_with_logits, (2,3), has_aux = True)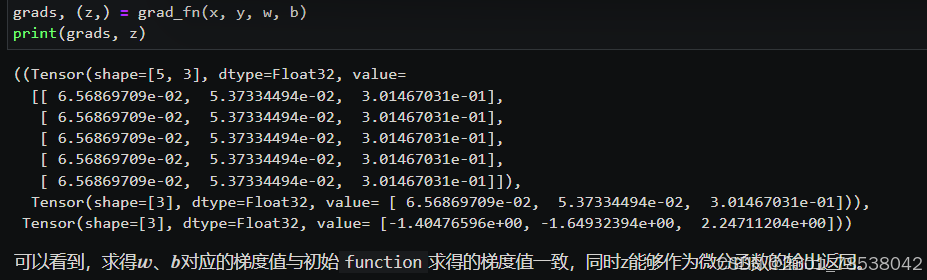
# Define model
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.w = w
self.b = b
def construct(self, x):
z = ops.matmul(x, self.w) + self.b
return z
# Instantiate model
model = Network()
# Instantiate loss function
loss_fn = nn.BCEWithLogitsLoss()
# Define forward function
def forward_fn(x, y):
z = model(x)
loss = loss_fn(z, y)
return loss
grad_fn = mindspore.value_and_grad(forward_fn, None, weights=model.trainable_params())#weights:the inner belongings of Cell, w and b None:the grad_poisition is not needed manually since it is the inner belongings in Cell too
loss, grads = grad_fn(x, y) #e.g. x = ops.ones(5, mindspore.float32)
print(grads)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









