






 Let's view some examples.
Let's view some examples.
Normalize, output = (input - mean )/ std:
normalize = vision.Normalize(mean=(0.14,), std= (0.44))
normalized_image = normalize(rescaled_image)
print(normalized_image)the data changed from: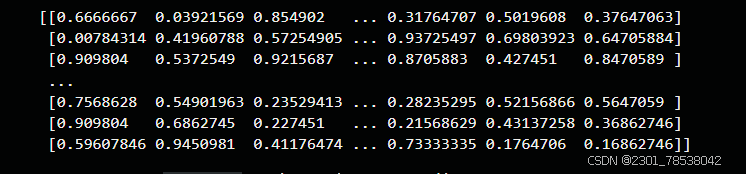 to :
to :
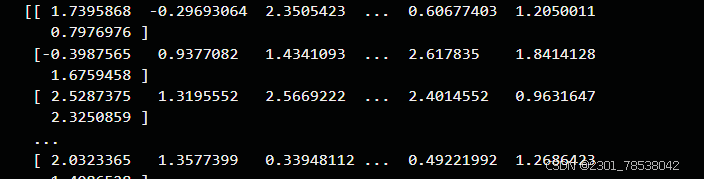 anyway, it is useful ,maybe related to kaiming normalized.
anyway, it is useful ,maybe related to kaiming normalized.
Tokenize:
def my_tokenizer(content):
return content.split()
test_dataset = test_dataset.map(text.PythonTokenizer(my_tokenizer))
print(next(test_dataset.create_tuple_iterator()))for example, if I have texts ['Welcome to Beijing']
I would split into three words(tokens), get ['Welcome' ,'to','Beijing'], which is saved as a tensor, a common type in transformer.
more concretely, we can def a vocab, for example:
vocab = text.Vocab.from_dataset(test_dataset)
print(vocab.vocab())and we get:
![]()
and we can transform the tokens to index:
test_dataset = test_dataset.map(text.lookup(vocab))
print(next(test_dataset.create_tuple_iterator()))![]()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









