






介绍
本系列主要讲解如何利用python实现网络爬虫。
环境:pycharm 语言:python
我致力于打造普通人也能看懂的python爬虫教程 ,在这个全新的AI智能时代,互联网已经完全融入我们的生活,编程应当成为我们的必要生活技能,而不是程序员的专属,我希望能帮助大家打破信息技术的巨大鸿沟。
关于编程在当今有多么重要,请移步我的上一篇文章大数据时代的你———python网络爬虫(附顶点小说爬虫源代码)-优快云博客
本文主要讲解与python爬虫有关的库的安装与导入及网页源代码的获取与解析。(注意:我认为观看本文的读者已经了解python语言的基本语法及环境的搭建,当然,即使还未浏览pyhton语法的读者也可阅读本文,了解爬虫的基本架构和思路,我后续也将发布python基本语法的教程,帮助新手快速入门)
需要的三方库及数据的传输
首先,你需要知道的是,python如此强大的原因就是其具有大量开源的第三方库,可以帮助我们不用关注其内部实现而使用这些开源的功能,这与接口的概念类似。
网络数据的传输
实现网络爬虫的第一步是获取网页源代码,我们需要的所有信息都在其中,网页相似的html架构是我们能够实现批量提取信息的基础,高质量的爬虫都是围绕网页源代码展开提取工作。
那么,网页的源代码究竟是什么,从何而来?
首先,你需要一个浏览器。这里推荐谷歌浏览器。可能有些人认为国内禁用谷歌搜索,谷歌浏览也不能用了,事实上,搜索引擎与浏览器不是一个概念,因此,你可以使用谷歌浏览器,将搜索引擎改为百度搜索或其他。推荐谷歌的原因:首先,作为日常生活来看,它可以搭载大量插件,拓展浏览器的功能;而作为编程学习来说,谷歌浏览器自带完备的开发者功能,极大便利了我们的爬虫工作。(以下是我谷歌浏览器用插件美化过的主页)
ok,现在,打开你的浏览器,我来为大家介绍我们在点击一个网站时发生了什么。
先随便搜索一个内容,演示如下
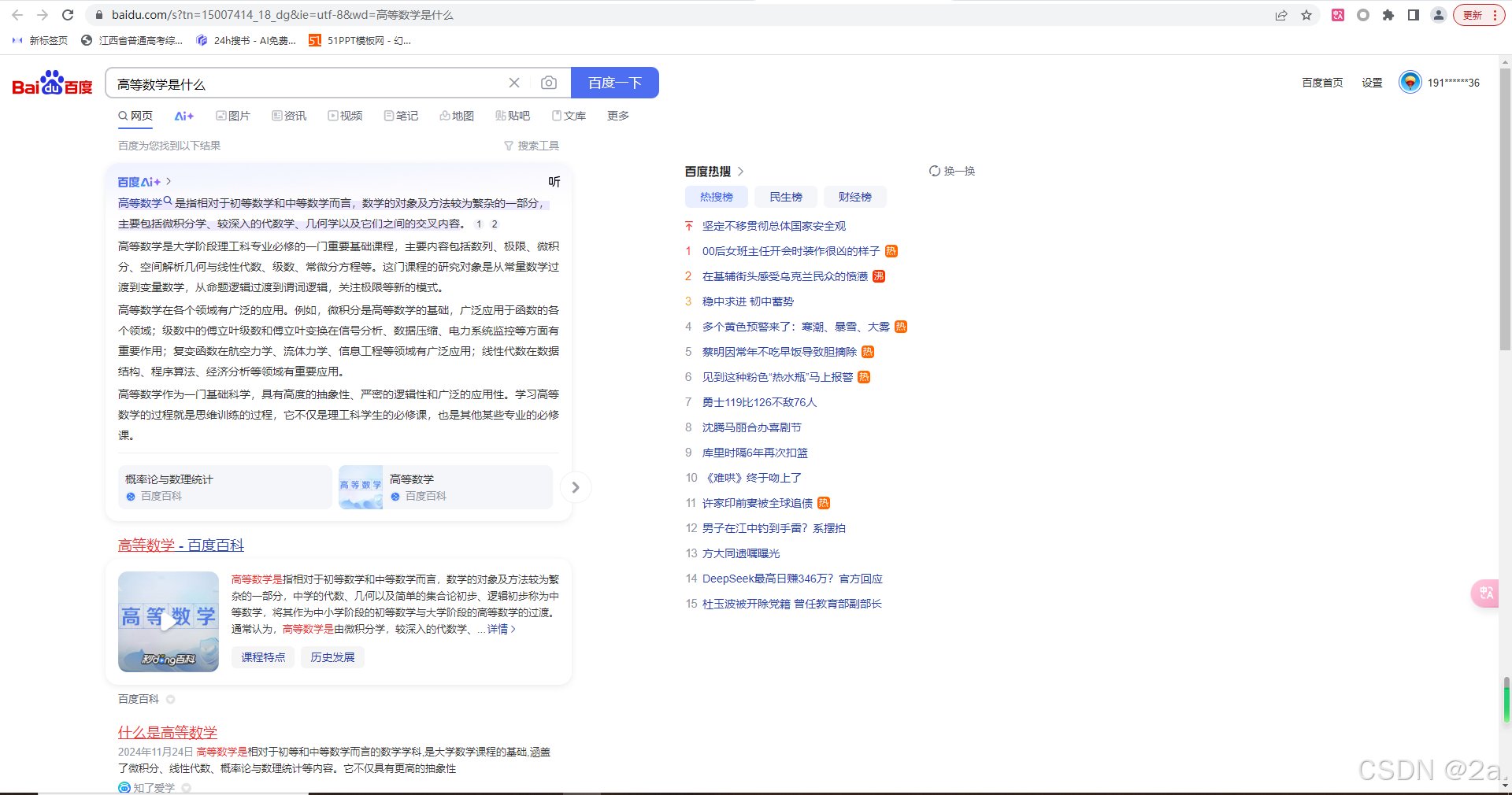
我们发现出现了很多结果,即使是普通人也应该知道,我们想看哪一个结果就点击对应的词条,我们就能进入该网站查看相关的回答,例如,我点击百度百科给出的答案
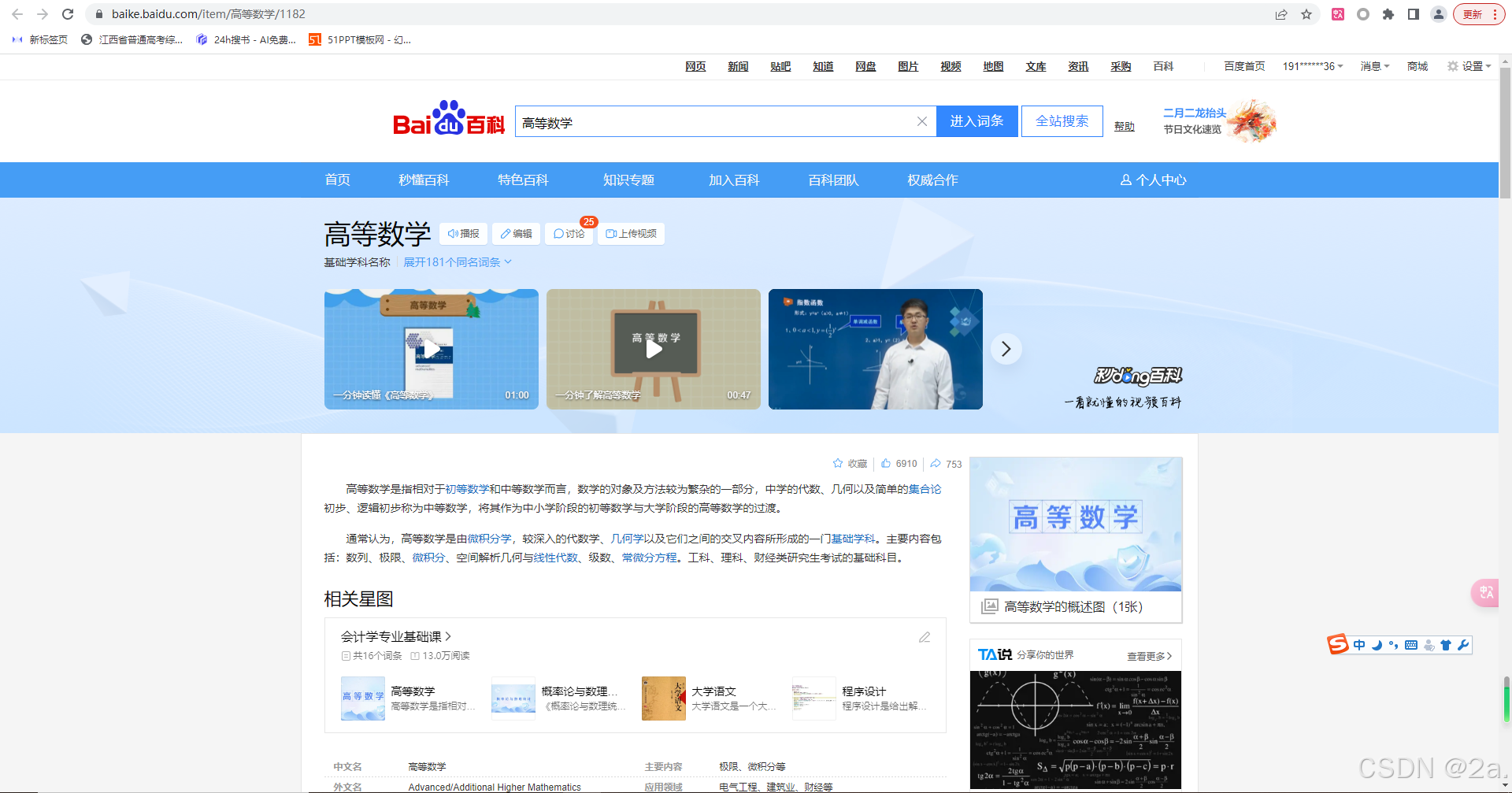
那么,在我点击这个网站到内容呈现发生了什么,难道这个内容已经发送到我的电脑,点开它就像打开本地文件夹一样简单?其实不然,网络信息的传输涉及多种技术,如网络协议,OSI七层网络模型,异步加载技术(ASYNC),html文件的解析,等等。这些技术我们后续都会学习,现在我先简单介绍网络数据的传输原理:
在你点击一个搜索结果时,其实就是点击了一个链接,也就是超文本传输协议(Hypertext Transfer Protocol,HTTP),接着,浏览器会根据这个协议向目标服务器发送一个请求获取数据,然后服务器将网页源代码返回被我们接收,浏览器将网页源代码解析呈现出来,就这么简单。可以看一个生动的例子加深理解:
浏览器:嘿,那边的服务器哥们,我想看这个网页,你只要发源代码就行,我自己会解析。
服务器:等等,我看看你有没有夹带私货(检查请求有没有危险),ok,哥们,你的请求没问题,给你源代码。
当然,内部的实现更为复杂,传输方式也多种多样如GET,POST,UDP等以及著名的三次握手,这样下去三天三夜我也写不完这篇文章,因此,这些内容我将在后续的文章呈现。
库
那么,为了获取源代码,我们不可能让浏览器帮我们请求,我们再用开发者工具把源代码复制下来,一次还行,要是我要爬一本书,成百上千页源代码,生产队的驴都造不起,这也违背了我学习爬虫的初衷:希望减少人力资源的消耗。那么,我们需要一个三方库来模拟浏览器发送请求并接收数据。
我们一般使用requests库或python自带的urllib库(注意:我的教程将使用requests库作为演示)
可以在控制台输入以下命令下载
pip install requests用如下代码导入
import requests下一文我会介绍它的用法。
创作不易,点个赞吧!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









