






前言
在数据爆炸的时代,如何高效判断一个元素是否存在于海量数据中?这看似简单的问题,背后却隐藏着计算机科学中巧妙的智慧。今天,我们将走进布隆过滤器(Bloom Filter)的世界 —— 这个诞生于 1970 年的概率型数据结构,用最少的内存空间和极快的查询速度,在互联网、数据库、缓存等领域书写着 “近似完美” 的解决方案。它是如何用位数组和哈希函数构建出 “可能存在” 的魔法?又是如何在误判率和性能之间找到平衡?让我们一起揭开这个轻量级数据结构的神秘面纱。
检查用户名是否存在
直接查询数据库请求用户名是否存在。
流程图:

存在什么问题?
- 海量用户如果说查询的用户名存在或不存在,全部请求数据库,会将数据库直接打满。
检查用户名是否存在引起的问题
1. 用户名加载缓存
第一版解决方案,将数据库已有的用户名全部放到缓存里。
流程图:
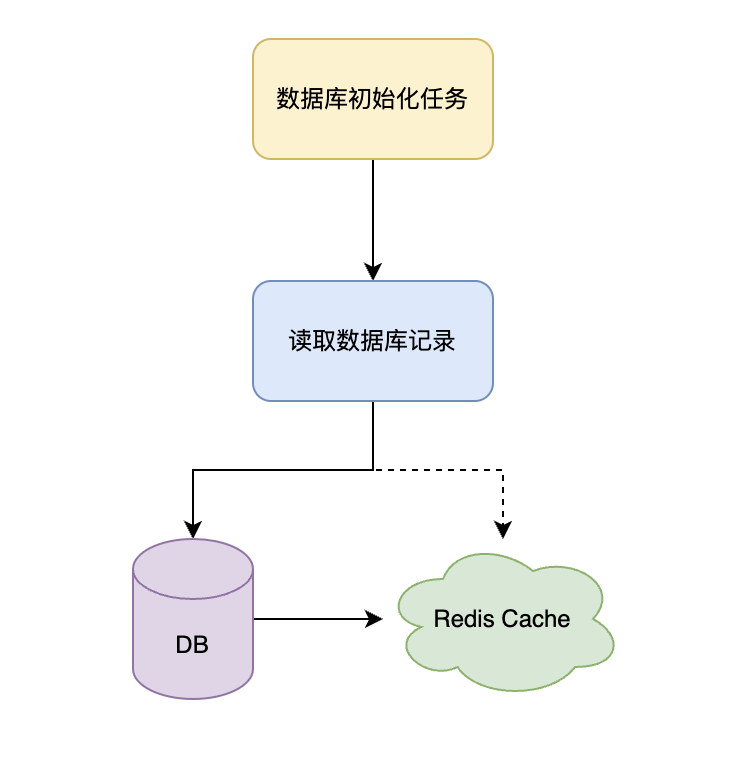
该方案问题:
- 是否要设置数据的有效期?只能设置为无无有效期,也就是永久数据。
- 如果是永久不过期数据,占用 Redis 内存太高。
2. 布隆过滤器
第二版解决方案,使用布隆过滤器。
流程图:
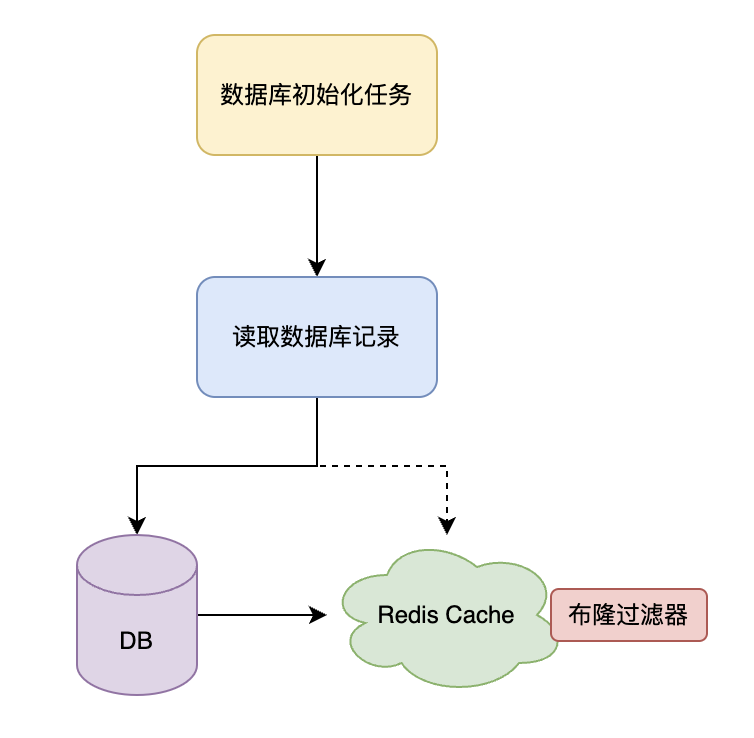
2.1. 什么是布隆过滤器
布隆过滤器是一种数据结构,用于快速判断一个元素是否存在于一个集合中。具体来说,布隆过滤器包含一个位数组和一组哈希函数。位数组的初始值全部置为 0。在插入一个元素时,将该元素经过多个哈希函数映射到位数组上的多个位置,并将这些位置的值置为 1。
1字节(Byte)=8位(Bit)
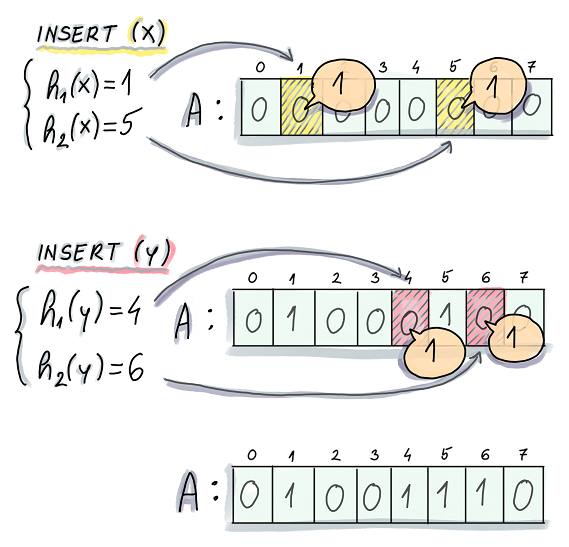
在查询一个元素是否存在时,会将该元素经过多个哈希函数映射到位数组上的多个位置,如果所有位置的值都为 1,则认为元素存在;如果存在任一位置的值为 0,则认为元素不存在。
2.2. 优缺点
优点:
- 高效地判断一个元素是否属于一个大规模集合。
- 节省内存。
缺点:
- 可能存在一定的误判。
2.3. 布隆过滤器误判理解
- 布隆过滤器要设置初始容量。容量设置越大,冲突几率越低。
- 布隆过滤器会设置预期的误判值。
2.4. 误判能否接受
布隆过滤器的误判是否能够接受?
答:可以容忍。为什么?因为用户名不是特别重要的数据,如果说我设置用户名为 aaa,系统返回我不可用,那我大可以在 aaa 的基础上再加一个a,也就是 aaaa。
2.5. 布隆过滤器流程图
初始化流程图:
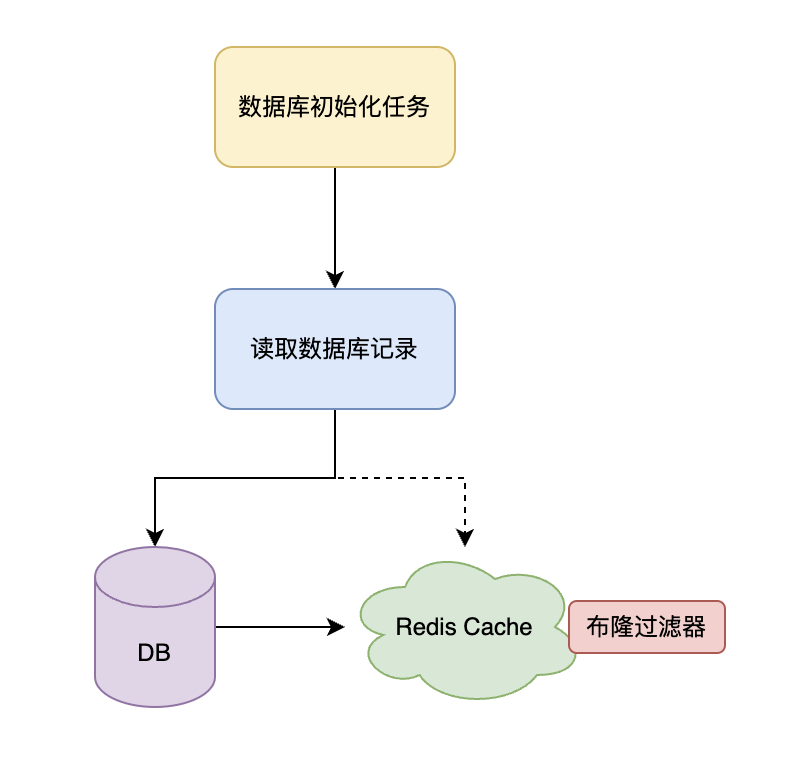
执行流程图:
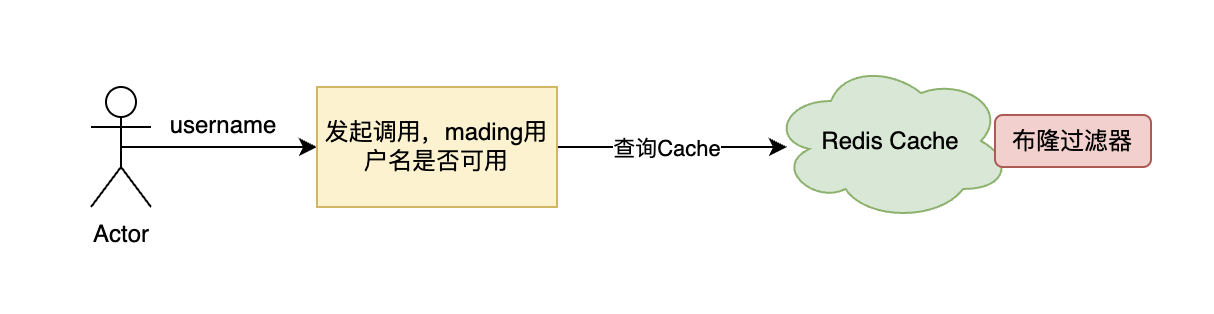
3. 代码中使用布隆过滤器
3.1. 引入 Redisson 依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
</dependency>3.2. 配置 Redis 参数
spring:
data:
redis:
host: 127.0.0.1
port: 6379
password: 1234563.3. 创建布隆过滤器实例
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 布隆过滤器配置
*/
@Configuration
public class RBloomFilterConfiguration {
/**
* 防止用户注册查询数据库的布隆过滤器
*/
@Bean
public RBloomFilter<String> userRegisterCachePenetrationBloomFilter(RedissonClient redissonClient) {
RBloomFilter<String> cachePenetrationBloomFilter = redissonClient.getBloomFilter("xxx");
cachePenetrationBloomFilter.tryInit(0, 0);
return cachePenetrationBloomFilter;
}
}tryInit 有两个核心参数:
- expectedInsertions:预估布隆过滤器存储的元素长度。
- falseProbability:运行的误判率。
错误率越低,位数组越长,布隆过滤器的内存占用越大。
错误率越低,散列 Hash 函数越多,计算耗时较长。
一个布隆过滤器占用大小的在线网站:Bloom Filter Calculator
使用布隆过滤器的两种场景:
- 初始使用:注册用户时就向容器中新增数据,就不需要任务向容器存储数据了。
- 使用过程中引入:读取数据源将目标数据刷到布隆过滤器。
3.4. 代码中使用
private final RBloomFilter<String> userRegisterCachePenetrationBloomFilter;用户注册功能
用户注册流程图:
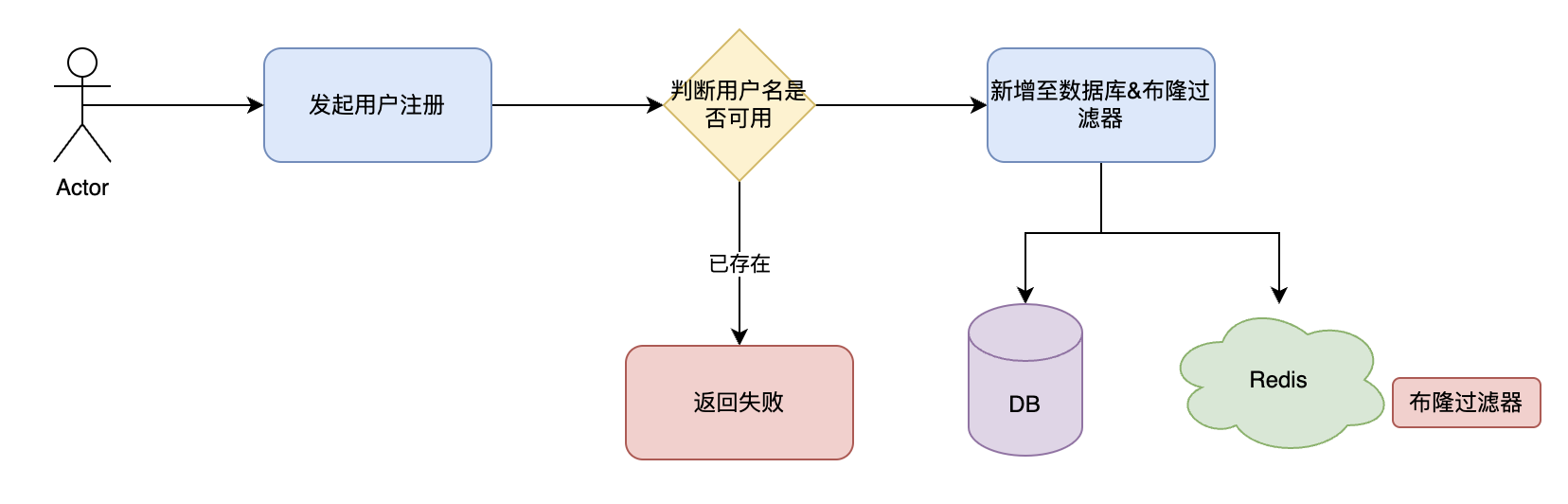
1. 如何防止用户名重复?
通过布隆过滤器把所有用户名进行加载。这样该功能就能完全隔离数据库。
数据库层面添加唯一索引。
2. 如何防止恶意请求毫秒级触发大量请求去一个未注册的用户名?
因为用户名没注册,所以布隆过滤器不存在,代表着可以触发注册流程插入数据库。但是如果恶意请求短时间海量请求,这些请求都会落到数据库,造成数据库访问压力。这里通过分布式锁,锁定用户名进行串行执行,防止恶意请求利用未注册用户名将请求打到数据库。
流程执行图:
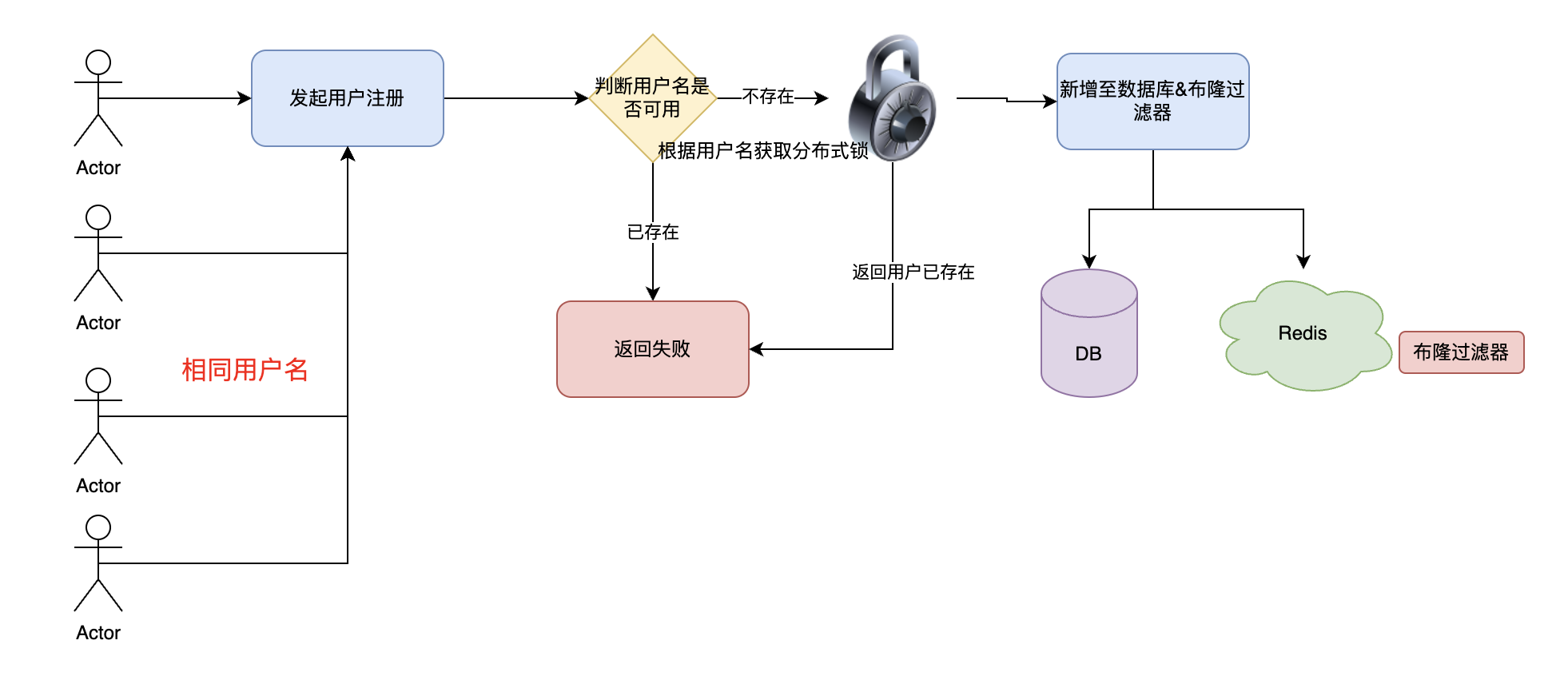
3. 如果恶意请求全部使用未注册用户名发起注册
结论:系统无法进行完全风控,只有通过类似于限流的功能进行保障系统安全。
结尾
布隆过滤器的魅力,在于它用数学的优雅化解了工程中的难题。它并非万能钥匙,却在特定场景下展现出无可替代的价值:从 Redis 缓存穿透防护到分布式系统中的去重,从垃圾邮件过滤到区块链的 Merkle 树优化,它的身影无处不在。理解它的原理,不仅能帮助我们在系统设计中做出更明智的选择,也能启发我们用概率思维解决复杂问题。
当然,布隆过滤器也有局限 —— 误判率无法根除,删除操作的难题仍需借助其他结构(如 Counting Bloom Filter)。但正是这些不完美,推动着技术的持续演进。你是否在实际项目中用过布隆过滤器?遇到过哪些有趣的问题?欢迎在评论区分享你的经验与思考!

















 167万+
167万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









