






1. 什么是布隆过滤器
布隆过滤器是一种数据结构,用于快速判断一个元素是否存在于一个集合中。它以牺牲一定的准确性为代价,换取了存储空间的极大节省和查询速度的显著提升。
具体来说,布隆过滤器包含一个位数组和一组哈希函数。位数组的初始值全部置为 0。在插入一个元素时,将该元素经过多个哈希函数映射到位数组上的多个位置,并将这些位置的值置为 1。
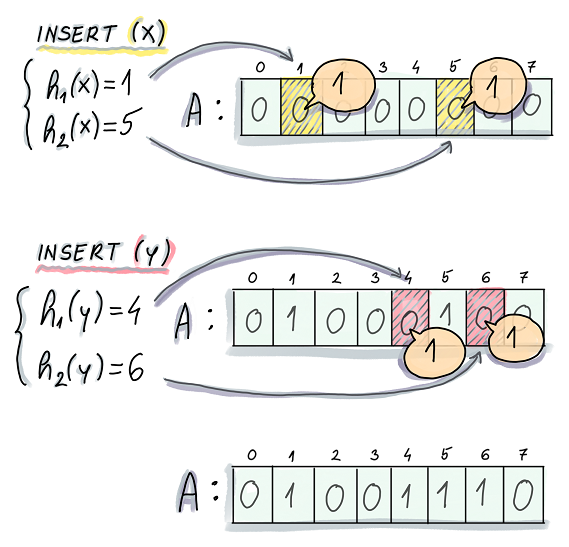
另外,网上找了一张比较炫的图,大家可以参考着看看。
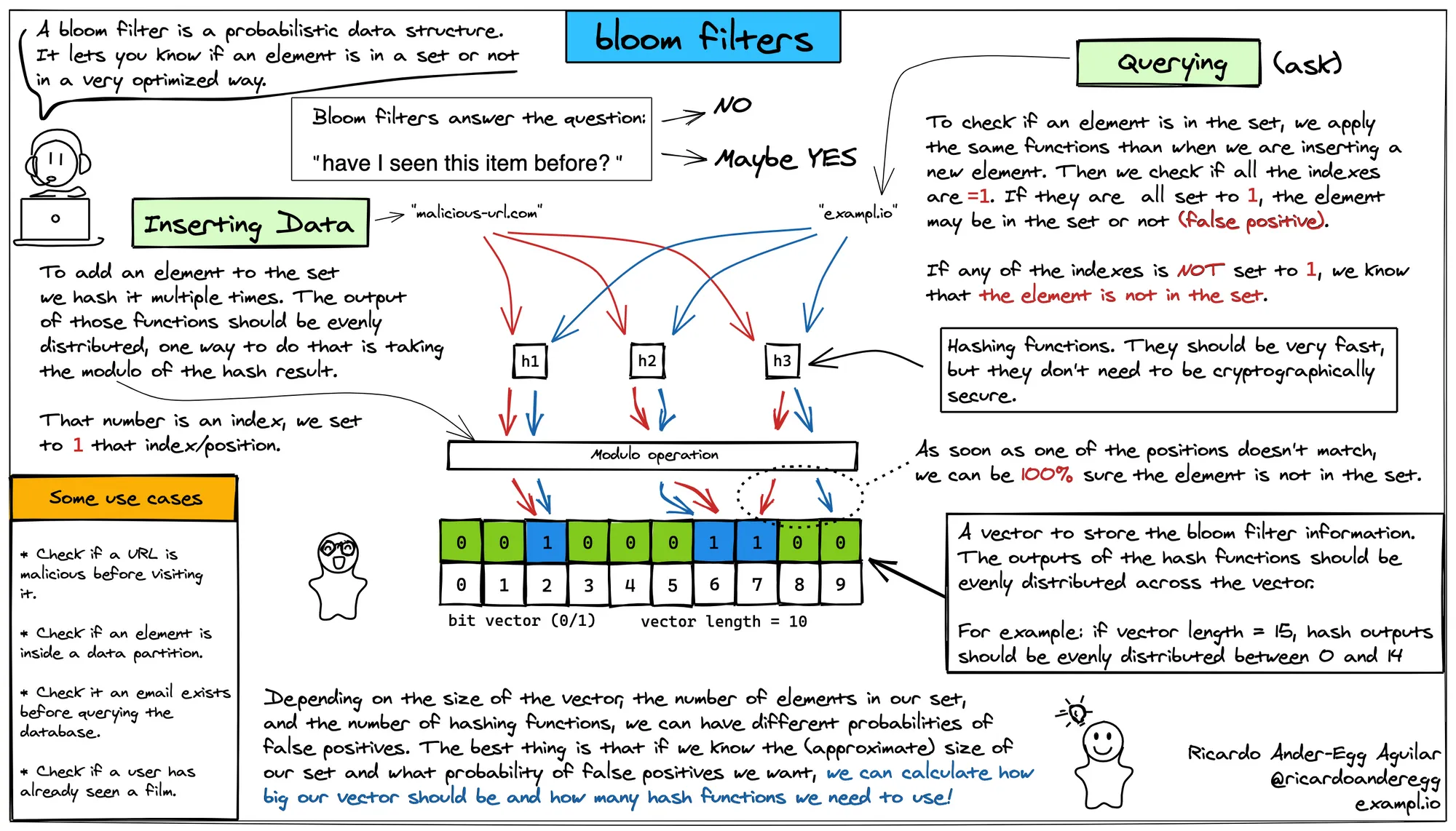
因为每个元素存储都是以位来存储,而不是字节,所以元素的占用空间非常小。
1 字节(Byte)= 8 位(Bit)在计算机科学中,数据存储的最小单位是位(Bit),而字节(Byte)则是一个常用的数据存储单位,通常由8个位组成。
在查询一个元素是否存在时,会将该元素经过多个哈希函数映射到位数组上的多个位置,如果所有位置的值都为 1,则认为元素存在;如果存在任一位置的值为 0,则认为元素不存在。
布隆过滤器的优点在于它可以高效地判断一个元素是否属于一个大规模集合,且具有极低的存储空间要求。如果存储 1亿元素,误判率设置为 0.001 也就是千分之一,仅需要占用 171M 左右的内存。
缺点在于可能会存在一定的误判率。
它在实际应用中常用于缓存场景下缓存穿透问题,对访问请求做一个快速判断机制。使用布隆过滤器能够有效减轻对底层存储系统的访问以及缓存系统的存储压力。
但是布隆过滤器本身也存在一些“弊端”,那就是不支持删除元素。因为它是一种基于哈希的数据结构,删除元素会涉及到多个哈希函数之间的冲突问题,这样会导致删除一个元素可能会影响到其他元素的正确性。
总的来说,布隆过滤器是一种非常高效的数据结构,适用于那些可以容忍一定的误判率的场合。
2. 为什么会有误判率?
布隆过滤器之所以会有误判率,是因为其设计原理决定了它的特性。
当元素被添加到布隆过滤器中时,会经过多个哈希函数的计算,生成一系列哈希值。这些哈希值会映射到位数组中的相应位置,将对应的位设置为 1。当需要查询一个元素是否存在于布隆过滤器中时,会对该元素进行相同的哈希计算,并检查对应的位是否都为 1。如果所有位都为 1,那么该元素很可能存在于布隆过滤器中;如果有任何一个位为 0,那么该元素一定不存在于布隆过滤器中。
然而,布隆过滤器存在一定的误判率,也就是在判断一个元素不存在时,可能会错误地判断该元素存在。这是由于以下原因:
- 哈希函数的冲突:布隆过滤器使用多个哈希函数对元素进行映射,但不同元素的哈希值可能会发生冲突,导致不同元素映射到位数组的相同位置。这种冲突会导致位数组中的某些位被设置为1,从而造成误判。
- 位数组的大小限制:为了减少空间占用,位数组的大小是有限的。当需要存储的元素数量增加时,位数组可能会发生碰撞,即多个元素映射到了相同的位数组位置。这也会导致误判的可能性增加。
所以,布隆过滤器无法提供确定性的元素存在性判断,而是提供了一个概率性的判断。误判率取决于布隆过滤器的参数设置,包括哈希函数的数量、位数组的大小等。通过调整这些参数,可以在一定程度上控制误判率。较低的误判率需要更大的位数组和更多的哈希函数,但也会增加空间和计算开销。
3. 如何解决误判率?
上面有说,布隆过滤器返回存在,可能是不存在的。但是返回不存在,那么就一定不存在。所以,我们通过返回不存在的方式可以一定程度上解决该问题。
if (!shortUriCreateCachePenetrationBloomFilter.contains(createShortLinkDefaultDomain + "/" + shorUri)) {
break;
}4. 占用内存大小
布隆过滤器内存占用预估参考网站:Bloom Filter Calculator sourl.cn/ZJdP9W
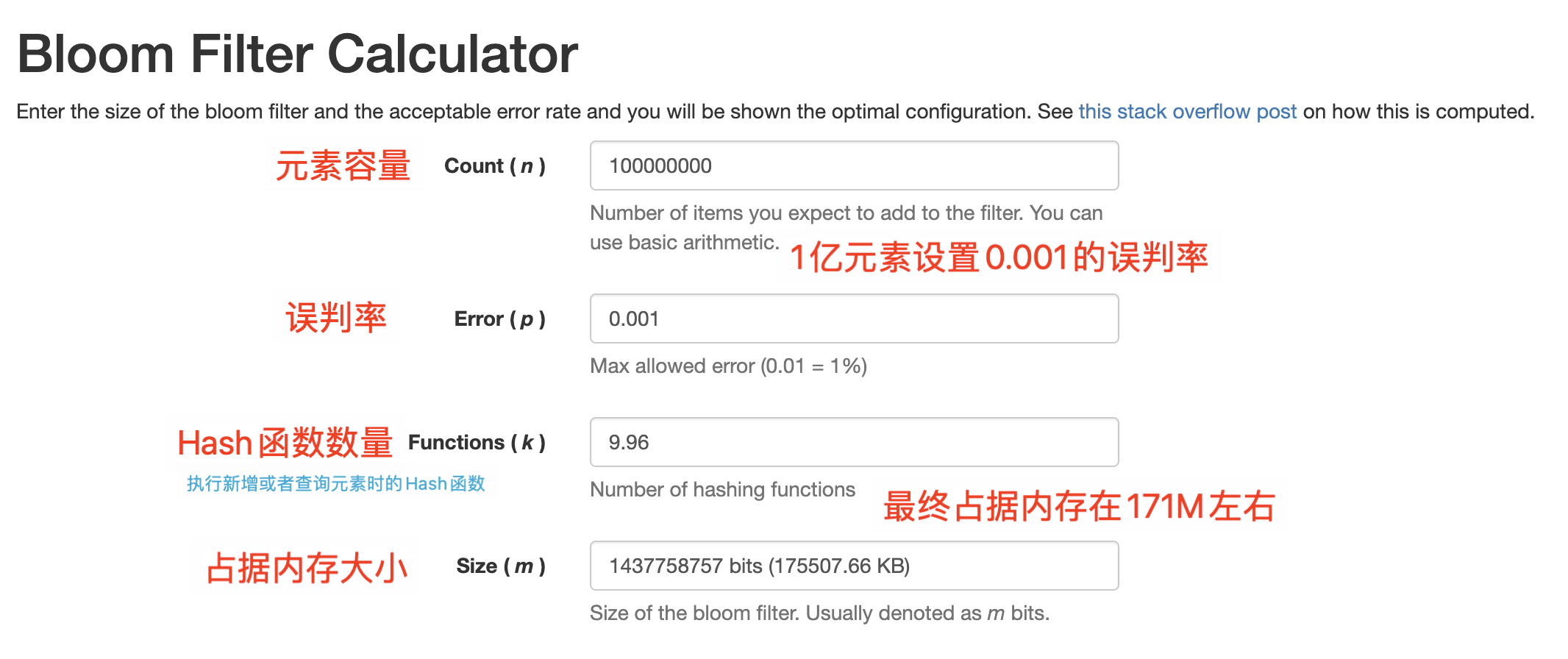
如何判断这个数据的真实性?很简单,你在设置好参数初始化布隆过滤器时,它会初始化一个位数组,这个容量是固定的且一次性申请对应容量的内存。
经过实际测试,基本与上述网站评估一致。另外和大家说个小 Tips,Redisson 布隆过滤器在 Redis 中是以字符串方式存储的,底层数据结构是 Redis 中的 BitSet(位图)。

如果布隆过滤器挂了,数据会丢失么?
这个问题本质上是错误的,为什么呢?布隆过滤器存在于 Redis 内存中,所以如果说挂,应该是整个 Redis 挂掉,而不仅仅说是布隆过滤器挂。
基于这个问题,我考虑到了两个场景,这里分别说说。
1. Redis 宕机,数据会丢失么?
如果我们没开启任何持久化机制,那么会丢失全部数据,否则只会丢失部分数据,丢失数据的多少取决于持久化配置。
Redis 提供了两套持久化机制,一个是 RDB,它会根据情况定期的 Fork 出一个子进程,生成当前数据库的全量快照;另一个是 AOF,它通过向 AOF 日志文件追加每一条执行过的指令实现。
而对于 RDB 快照,假如我们在 RDB 快照生成后宕机,那么会丢失快照生成期间全部增量数据,如果在连快照都没成功生成,那么就会丢掉全部数据。
而当我们仅开启了 AOF 时,丢失数据的多少取决于我们设置的刷盘策略:当设置为每条指令执行后都刷盘 Always,我们最多丢失一条指令;当设置为每秒刷一次盘的 Eversec 时,最多丢失一秒内的数据;当设置为非主动刷盘的 No 时,则可能丢失上次刷盘后到现在的全部数据。
所以,我们为了避免数据过多丢失,一般都会采用 AOF 方式。由于通过 AOF 恢复数据相对比较耗时,因此 Redis 在 4.0 以后允许通过 aof‐use‐rdb‐preamble 配置开启混合持久化。
当 AOF 重写时,它将会先生成当前时间的 RDB 快照,然后将其写入新的 AOF 文件,接着再把增量数据追加到这个新 AOF 文件中。如此一来,当 Redis 通过 AOF 文件恢复数据时,将会先加载 RDB,然后再重放后半部分的增量数据。这样就可以大幅度提高数据恢复的速度。
2. Redis 返回成功,但布隆过滤器持久化指令失败了,会生成重复短链接么?
上面有说,使用 AOF 极端情况下会丢失一条数据,那如果说我们像 Redis 布隆过滤器新增一条短链接记录,Redis 返回给我们成功了。但是,恰巧持久化磁盘时 Redis 宕机了。这种情况怎么办?
@Transactional(rollbackFor = Exception.class)
@Override
public ShortLinkCreateRespDTO createShortLink(ShortLinkCreateReqDTO requestParam) {
verificationWhitelist(requestParam.getOriginUrl());
String shortLinkSuffix = generateSuffix(requestParam);
String fullShortUrl = StrBuilder.create(createShortLinkDefaultDomain)
.append("/")
.append(shortLinkSuffix)
.toString();
ShortLinkDO shortLinkDO = xxx;
try {
baseMapper.insert(shortLinkDO);
shortLinkGotoMapper.insert(linkGotoDO);
} catch (DuplicateKeyException ex) {
throw new ServiceException(String.format("短链接:%s 生成重复", fullShortUrl));
}
stringRedisTemplate.opsForValue().set(
String.format(GOTO_SHORT_LINK_KEY, fullShortUrl),
requestParam.getOriginUrl(),
LinkUtil.getLinkCacheValidTime(requestParam.getValidDate()), TimeUnit.MILLISECONDS
);
// 新增到布隆过滤器
shortUriCreateCachePenetrationBloomFilter.add(fullShortUrl);
return ShortLinkCreateRespDTO.builder()
.fullShortUrl("http://" + shortLinkDO.getFullShortUrl())
.originUrl(requestParam.getOriginUrl())
.gid(requestParam.getGid())
.build();
}可能会造成什么问题呢?假设生成了 isjkd8 的短链接,本来应该判断布隆过滤器中存在的,结果变成了不存在,那么就会执行数据库的新增流程,可能就会造成一个短链接数据库有着两条记录的问题。
不过还好,我们在数据库创建了唯一索引,会直接抛异常出来,不会造成脏数据。
那细心的老板们发现问题了么?我们是不是没有针对这种操作进行处理?那下次生成这种短链接不还是会抛异常么?
为此,我们可以重构下操作异常的流程:
@Transactional(rollbackFor = Exception.class)
@Override
public ShortLinkCreateRespDTO createShortLink(ShortLinkCreateReqDTO requestParam) {
verificationWhitelist(requestParam.getOriginUrl());
String shortLinkSuffix = generateSuffix(requestParam);
String fullShortUrl = StrBuilder.create(createShortLinkDefaultDomain)
.append("/")
.append(shortLinkSuffix)
.toString();
ShortLinkDO shortLinkDO = xxx;
try {
baseMapper.insert(shortLinkDO);
shortLinkGotoMapper.insert(linkGotoDO);
} catch (DuplicateKeyException ex) {
// 首先判断是否存在布隆过滤器,如果不存在直接新增
if (!shortUriCreateCachePenetrationBloomFilter.contains(fullShortUrl)) {
shortUriCreateCachePenetrationBloomFilter.add(fullShortUrl);
}
throw new ServiceException(String.format("短链接:%s 生成重复", fullShortUrl));
}
stringRedisTemplate.opsForValue().set(
String.format(GOTO_SHORT_LINK_KEY, fullShortUrl),
requestParam.getOriginUrl(),
LinkUtil.getLinkCacheValidTime(requestParam.getValidDate()), TimeUnit.MILLISECONDS
);
// 新增到布隆过滤器
shortUriCreateCachePenetrationBloomFilter.add(fullShortUrl);
return ShortLinkCreateRespDTO.builder()
.fullShortUrl("http://" + shortLinkDO.getFullShortUrl())
.originUrl(requestParam.getOriginUrl())
.gid(requestParam.getGid())
.build();
}加上这个异常逻辑后,这个就算是比较圆满了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









