






目录
一、二分查找时间复杂度
1.1:二分查找的常规版代码:
public static int Binarysearch(int[] arr, int target) {
int low = 0, higth = arr.length - 1;
while (low <= higth) {
int mid = (low + higth) >>> 1;
if (target < arr[mid]) {
higth = mid - 1;
} else if (arr[mid] < target) {
low = mid + 1;
} else {
return mid;
}
}
return -1;
}
}1.2:线性查找法
public class LinearSearch {
public static int linearSearch(int[] arr, int key) {
for (int i = 0; i < arr.length; i++) {
if(arr[i]==key){
return i;
}
}
return -1;
}
}众所周知,算法能够提高我们代码的效率,第二种线性查找法就是遍历数组中的元素,然后和所要查找的元素进行比较,如果找到了返回下标,没找到返回-1,显然线性查找法的效率非常的低,特别是数组中的元素非常多的时候
1.3:那如何来比较二者的查找效率呢
第一步先假设:二者都是最差的情况(就是说找一圈之后发现没有这个元素)
第二步假设:每条语句的执行时间相同(时间为1)
1.3.1:先来分析线性查找法
数据元素的个数为n
代码 时间
int i=0 1
i < arr.length n+1 (+1的那次就是说 i 已经比arr.length大了,不满足条件跳出循环)
i++ n
arr[i]=key n
return -1 1
所以可以得到线性查找的最差执行时间为3n+3;
1.3.2:再来分析二分查找法
二分查找小细节:都是没找着的情况:0 {2,3,4,5} 7 待查项为7的执行的次数更多(待查项在右侧的情况)
二分查找的特点:
元素个数 循坏次数
4~7 3
8~15 4
16~31 5
32~63 6
``````` ``````
发现规律:第一次循环次数=log_2(4)+1=3
第二次循环次数=log_2(8)+1=4
``````
所以得出循环次数=floor(log_2(n))+1
注意:floor为向下取整函数 例如floor(log_2(7))+1=3
设循环次数为 L = floor(log_2(n))+1
代码 时间
int low = 0 1
higth = arr.length - 1 1
i<=j L+1(i 已经比j大了,不满足条件跳出循环)
int mid = (low + higth) >>> 1 L
target < arr[mid] L
arr[mid] < target L
low = mid + 1; L
return -1 1
所以可以得到二分查找的最差执行时间为5L+4=5 *(floor(log_2(n))+1 )+4;
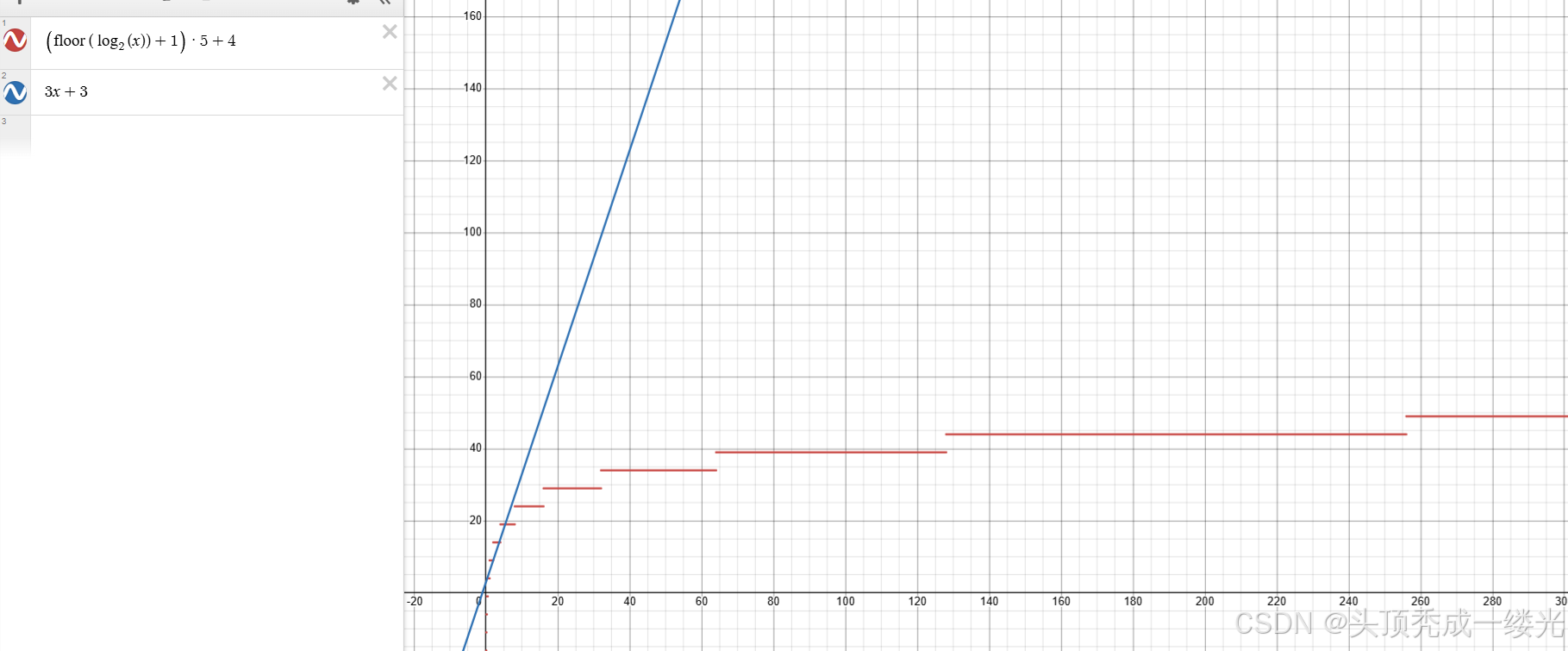
蓝色的线为线性查找,红色的线为二分查找,X坐标为数据个数,Y坐标为查询时间
二、二分查找空间复杂度
与时间复杂度类似,一般也要使用大O表示法来衡量,一个算法的执行随数据规模的增大,而增长的额外的空间成本(注意这里的额外,原始数据量我们是不算在内的,例如main函数,这样的原始数据)
代码 占用空间(字节)
int low = 0 4
higth = arr.length - 1 4
int mid = (low + higth) >>> 1; 4
注意虽然mid的值会发生改变,但是他的地址值是不变的,也就是说mid占用的空间不会变,依然是int类型的4个字节
三、二分查找的性能
3.1:时间复杂度
最坏情况:O(log(n))
最好情况:O(1):就是说要找的元素刚好在数组的中央,只需要循环一次
3.2:空间复杂度
需要常数个指针low,higth,mid,所以额外占用的空间为O(1)

















 2001
2001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









