







一. 安装单机版hadoop
1. 上传并解压hadoop文件
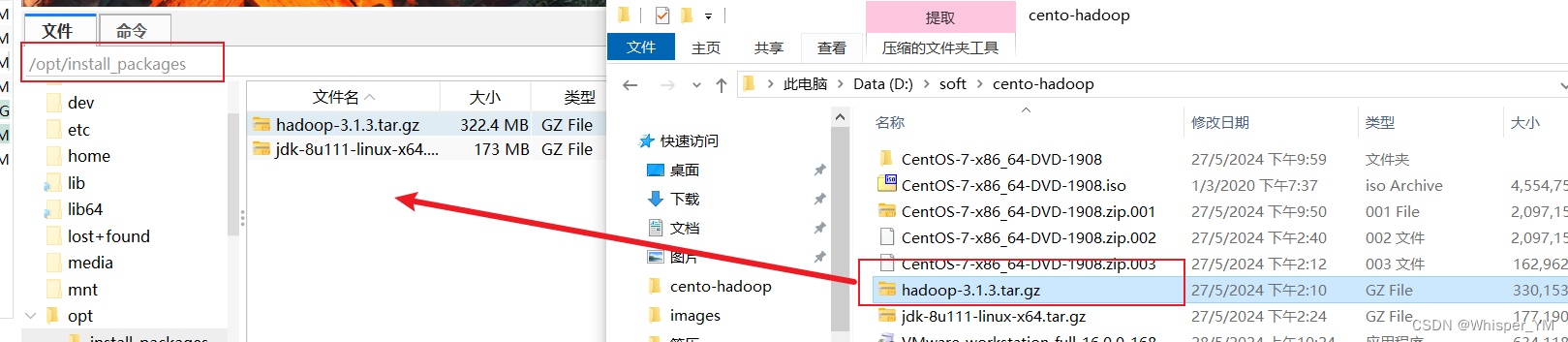
上传hadoop压缩包到install_packages并解压
tar -zxvf /opt/install_packages/hadoop-3.1.3.tar.gz -C /opt/softs/

重命名:mv /opt/softs/hadoop-3.1.3/ /opt/softs/hadoop3.1.3/

2. 配置环境变量
vim /etc/profile
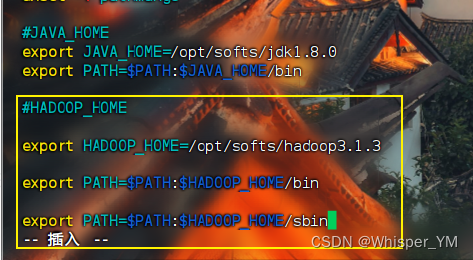
添加以下内容:
#HADOOP_HOME
export HADOOP_HOME=/opt/softs/hadoop3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
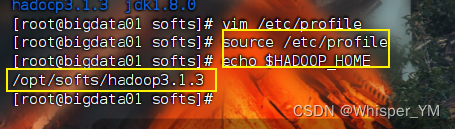
使配置文件生效:
source /etc/profile
验证:
echo $HADOOP_HOME
二. 使用jar包计算文本中单词出现的次数
1. 创建文件夹,存放待计算的文本文件
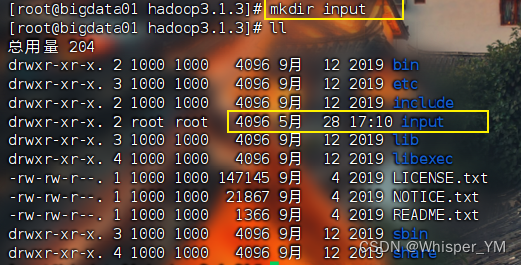
将文本文件放入input文件夹


2. 调用jar包进行计算
1)使用hadoop命令
hadoop jar /opt/softs/hadoop3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /opt/softs/hadoop3.1.3/input /opt/softs/hadoop3.1.3/output
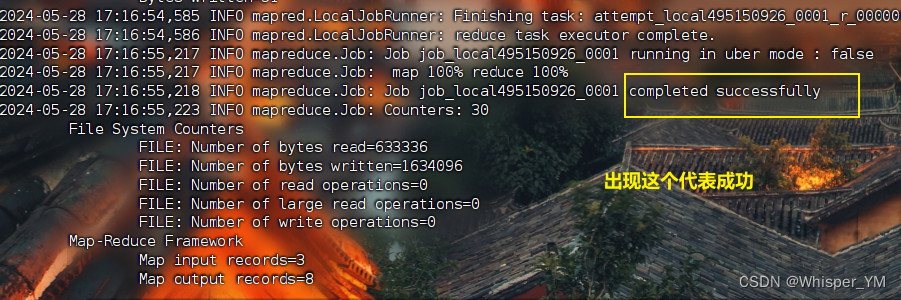
注意:output目录一定不能事先创建!!!
2)查看结果
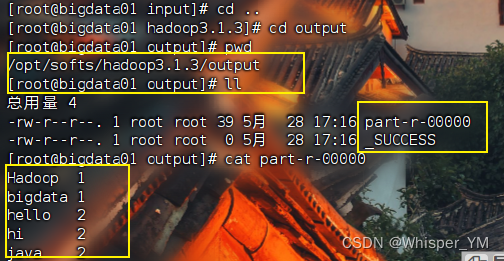


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









